Parsing an XML Document
|
| To process an XML document, you need to parse it. A parser is a program that reads a file, confirms that the file has the correct format, breaks it up into the constituent elements, and lets a programmer access those elements. The Java library supplies two kinds of XML parsers:
The DOM parser is easier to use for most purposes, and we explain it first. You would consider the SAX parser if you process very long documents whose tree structures would use up a lot of memory, or if you are just interested in a few elements and you don't care about their context. The DOM parser interface is standardized by the World Wide Web Consortium (W3C). The org.w3c.dom package contains the definitions of interface types such as Document and Element. Different suppliers, such as the Apache Organization and IBM, have written DOM parsers whose classes implement these interfaces. The Sun Java API for XML Processing (JAXP) library actually makes it possible to plug in any of these parsers. But Sun also includes its own DOM parser in the Java SDK. We use the Sun parser in this chapter. To read an XML document, you need a DocumentBuilder object, which you get from a DocumentBuilderFactory, like this: DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); You can now read a document from a file: File f = . . . Document doc = builder.parse(f); Alternatively, you can use a URL: URL u = . . . Document doc = builder.parse(u); You can even specify an arbitrary input stream: InputStream in = . . . Document doc = builder.parse(in); NOTE
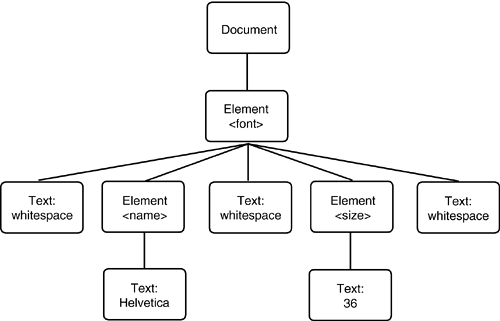
The Document object is an in-memory representation of the tree structure of the XML document. It is composed of objects whose classes implement the Node interface and its various subinterfaces. Figure 12-1 shows the inheritance hierarchy of the subinterfaces. Figure 12-1. The Node interface and its subinterfaces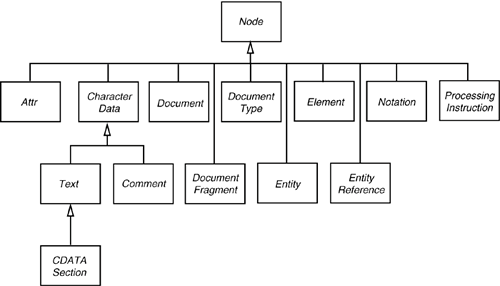 You start analyzing the contents of a document by calling the getdocumentElement method. It returns the root element. Element root = doc.getDocumentElement(); For example, if you are processing a document <?xml version="1.0"?> <font> . . . </font> then calling getdocumentElement returns the font element. The getTagName method returns the tag name of an element. In the preceding example, root.getTagName() returns the string "font". To get the element's children (which may be subelements, text, comments, or other nodes), use the getChildNodes method. That method returns a collection of type NodeList. That type was invented before the standard Java collections, and it has a different access protocol. The item method gets the item with a given index, and the getLength method gives the total count of the items. Therefore, you can enumerate all children like this: NodeList children = root.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); . . . } Be careful when analyzing the children. Suppose, for example, that you are processing the document <font> <name>Helvetica</name> <size>36</size> </font> You would expect the font element to have two children, but the parser reports five:
Figure 12-2 shows the DOM tree. Figure 12-2. A simple DOM tree
If you expect only subelements, then you can ignore the whitespace: for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); if (child instanceof Element) { Element childElement = (Element) child; . . . } } Now you look at only two elements, with tag names name and size. As you see in the next section, you can do even better if your document has a document type definition. Then the parser knows which elements don't have text nodes as children, and it can suppress the whitespace for you. When analyzing the name and size elements, you want to retrieve the text strings that they contain. Those text strings are themselves contained in child nodes of type Text. Since you know that these Text nodes are the only children, you can use the getFirstChild method without having to traverse another NodeList. Then use the getdata method to retrieve the string stored in the Text node. for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); if (child instanceof Element) { Element childElement = (Element) child; Text textNode = (Text) childElement.getFirstChild(); String text = textNode.getData().trim(); if (childElement.getTagName().equals("name")) name = text; else if (childElement.getTagName().equals("size")) size = Integer.parseInt(text); } } TIP
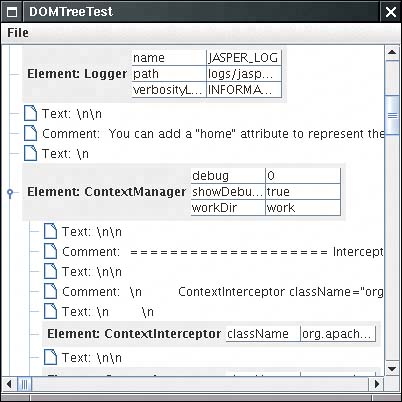
You can also get the last child with the getLastChild method, and the next sibling of a node with getNextSibling. Therefore, another way of traversing a set of child nodes is for (Node childNode = element.getFirstChild(); childNode != null; childNode = childNode.getNextSibling()) { . . . } To enumerate the attributes of a node, call the getAttributes method. It returns a NamedNodeMap object that contains Node objects describing the attributes. You can traverse the nodes in a NamedNodeMap in the same way as a NodeList. Then call the getNodeName and getNodeValue methods to get the attribute names and values. NamedNodeMap attributes = element.getAttributes(); for (int i = 0; i < attributes.getLength(); i++) { Node attribute = attributes.item(i); String name = attribute.getNodeName(); String value = attribute.getNodeValue(); . . . } Alternatively, if you know the name of an attribute, you can retrieve the corresponding value directly: String unit = element.getAttribute("unit"); You have now seen how to analyze a DOM tree. The program in Example 12-1 puts these techniques to work. You can use the File -> Open menu option to read in an XML file. A DocumentBuilder object parses the XML file and produces a Document object. The program displays the Document object as a JTRee (see Figure 12-3). Figure 12-3. A parse tree of an XML document
The tree display shows clearly how child elements are surrounded by text containing whitespace and comments. For greater clarity, the program displays newline and return characters as \n and \r. (Otherwise, they would show up as hollow boxes, the default symbol for a character that Swing cannot draw in a string.) If you followed the section on trees in Chapter 6, you will recognize the techniques that this program uses to display the tree. The DOMTreeModel class implements the treeModel interface. The getroot method returns the root element of the document. The getChild method gets the node list of children and returns the item with the requested index. However, the tree model returns DOM Node objects whose toString methods aren't necessarily descriptive. Therefore, the program installs a tree cell renderer that extends the default cell renderer and sets the label text to a more descriptive form. The cell renderer displays the following:
Example 12-1. DOMTreeTest.java 1. import java.awt.*; 2. import java.awt.event.*; 3. import java.io.*; 4. import javax.swing.*; 5. import javax.swing.event.*; 6. import javax.swing.table.*; 7. import javax.swing.tree.*; 8. import javax.xml.parsers.*; 9. import org.w3c.dom.*; 10. import org.xml.sax.*; 11. 12. /** 13. This program displays an XML document as a tree. 14. */ 15. public class DOMTreeTest 16. { 17. public static void main(String[] args) 18. { 19. JFrame frame = new DOMTreeFrame(); 20. frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); 21. frame.setVisible(true); 22. } 23. } 24. 25. /** 26. This frame contains a tree that displays the contents of 27. an XML document. 28. */ 29. class DOMTreeFrame extends JFrame 30. { 31. public DOMTreeFrame() 32. { 33. setTitle("DOMTreeTest"); 34. setSize(DEFAULT_WIDTH, DEFAULT_HEIGHT); 35. 36. JMenu fileMenu = new JMenu("File"); 37. JMenuItem openItem = new JMenuItem("Open"); 38. openItem.addActionListener(new 39. ActionListener() 40. { 41. public void actionPerformed(ActionEvent event) { openFile(); } 42. }); 43. fileMenu.add(openItem); 44. 45. JMenuItem exitItem = new JMenuItem("Exit"); 46. exitItem.addActionListener(new 47. ActionListener() 48. { 49. public void actionPerformed(ActionEvent event) { System.exit(0); } 50. }); 51. fileMenu.add(exitItem); 52. 53. JMenuBar menuBar = new JMenuBar(); 54. menuBar.add(fileMenu); 55. setJMenuBar(menuBar); 56. } 57. 58. /** 59. Open a file and load the document. 60. */ 61. public void openFile() 62. { 63. JFileChooser chooser = new JFileChooser(); 64. chooser.setCurrentDirectory(new File(".")); 65. 66. chooser.setFileFilter(new 67. javax.swing.filechooser.FileFilter() 68. { 69. public boolean accept(File f) 70. { 71. return f.isDirectory() || f.getName().toLowerCase().endsWith(".xml"); 72. } 73. public String getDescription() { return "XML files"; } 74. }); 75. int r = chooser.showOpenDialog(this); 76. if (r != JFileChooser.APPROVE_OPTION) return; 77. File f = chooser.getSelectedFile(); 78. try 79. { 80. if (builder == null) 81. { 82. DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 83. builder = factory.newDocumentBuilder(); 84. } 85. 86. Document doc = builder.parse(f); 87. JTree tree = new JTree(new DOMTreeModel(doc)); 88. tree.setCellRenderer(new DOMTreeCellRenderer()); 89. 90. setContentPane(new JScrollPane(tree)); 91. validate(); 92. } 93. catch (IOException e) 94. { 95. JOptionPane.showMessageDialog(this, e); 96. } 97. catch (ParserConfigurationException e) 98. { 99. JOptionPane.showMessageDialog(this, e); 100. } 101. catch (SAXException e) 102. { 103. JOptionPane.showMessageDialog(this, e); 104. } 105. } 106. 107. private DocumentBuilder builder; 108. private static final int DEFAULT_WIDTH = 400; 109. private static final int DEFAULT_HEIGHT = 400; 110. } 111. 112. /** 113. This tree model describes the tree structure of an XML document. 114. */ 115. class DOMTreeModel implements TreeModel 116. { 117. /** 118. Constructs a document tree model. 119. @param doc the document 120. */ 121. public DOMTreeModel(Document doc) { this.doc = doc; } 122. 123. public Object getRoot() { return doc.getDocumentElement(); } 124. 125. public int getChildCount(Object parent) 126. { 127. Node node = (Node) parent; 128. NodeList list = node.getChildNodes(); 129. return list.getLength(); 130. } 131. 132. public Object getChild(Object parent, int index) 133. { 134. Node node = (Node) parent; 135. NodeList list = node.getChildNodes(); 136. return list.item(index); 137. } 138. 139. public int getIndexOfChild(Object parent, Object child) 140. { 141. Node node = (Node) parent; 142. NodeList list = node.getChildNodes(); 143. for (int i = 0; i < list.getLength(); i++) 144. if (getChild(node, i) == child) 145. return i; 146. return -1; 147. } 148. 149. public boolean isLeaf(Object node) { return getChildCount(node) == 0; } 150. public void valueForPathChanged(TreePath path, Object newValue) {} 151. public void addTreeModelListener(TreeModelListener l) {} 152. public void removeTreeModelListener(TreeModelListener l) {} 153. 154. private Document doc; 155. } 156. 157. /** 158. This class renders an XML node. 159. */ 160. class DOMTreeCellRenderer extends DefaultTreeCellRenderer 161. { 162. public Component getTreeCellRendererComponent(JTree tree, Object value, 163. boolean selected, boolean expanded, boolean leaf, int row, boolean hasFocus) 164. { 165. Node node = (Node) value; 166. if (node instanceof Element) return elementPanel((Element) node); 167. 168. super.getTreeCellRendererComponent(tree, value, 169. selected, expanded, leaf, row, hasFocus); 170. if (node instanceof CharacterData) 171. setText(characterString((CharacterData) node)); 172. else 173. setText(node.getClass() + ": " + node.toString()); 174. return this; 175. } 176. 177. public static JPanel elementPanel(Element e) 178. { 179. JPanel panel = new JPanel(); 180. panel.add(new JLabel("Element: " + e.getTagName())); 181. panel.add(new JTable(new AttributeTableModel(e.getAttributes()))); 182. return panel; 183. } 184. 185. public static String characterString(CharacterData node) 186. { 187. StringBuilder builder = new StringBuilder(node.getData()); 188. for (int i = 0; i < builder.length(); i++) 189. { 190. if (builder.charAt(i) == '\r') 191. { 192. builder.replace(i, i + 1, "\\r"); 193. i++; 194. } 195. else if (builder.charAt(i) == '\n') 196. { 197. builder.replace(i, i + 1, "\\n"); 198. i++; 199. } 200. else if (builder.charAt(i) == '\t') 201. { 202. builder.replace(i, i + 1, "\\t"); 203. i++; 204. } 205. } 206. if (node instanceof CDATASection) 207. builder.insert(0, "CDATASection: "); 208. else if (node instanceof Text) 209. builder.insert(0, "Text: "); 210. else if (node instanceof Comment) 211. builder.insert(0, "Comment: "); 212. 213. return builder.toString(); 214. } 215. } 216. 217. /** 218. This table model describes the attributes of an XML element. 219. */ 220. class AttributeTableModel extends AbstractTableModel 221. { 222. /** 223. Constructs an attribute table model. 224. @param map the named node map 225. */ 226. public AttributeTableModel(NamedNodeMap map) { this.map = map; } 227. 228. public int getRowCount() { return map.getLength(); } 229. public int getColumnCount() { return 2; } 230. public Object getValueAt(int r, int c) 231. { 232. return c == 0 ? map.item(r).getNodeName() : map.item(r).getNodeValue(); 233. } 234. 235. private NamedNodeMap map; 236. } javax.xml.parsers.DocumentBuilderFactory 1.4
javax.xml.parsers.DocumentBuilder 1.4
org.w3c.dom.Document 1.4
org.w3c.dom.Element 1.4
org.w3c.dom.Node 1.4
org.w3c.dom.CharacterData 1.4
org.w3c.dom.NodeList 1.4
org.w3c.dom.NamedNodeMap 1.4
|
|
EAN: 2147483647
Pages: 156