Data Stores and Data Access
The term data store usually meant a database of some kind. Databases were usually file-based , often using fixed-width records written to disk “ rather like text files. A database program or data access technology read the files into buffers as tables, and applied rules defined in other files to connect the records from different tables together. As technologies matured, relational databases evolved to provide better storage methods , such as variable-length records and more efficient access techniques.
However, the basic storage medium was still the database “ a specialist program that managed the data and exposed it to clients . Obvious examples are Oracle, Informix, Sybase, DB2, and Microsoft's own SQL Server. All are enterprise-oriented applications for storing and managing data in a relational way.
At the same time, desktop database applications matured and became more powerful. In general, this type of program provides its own interface for working with the data. For example, Microsoft Access can be used to build forms and queries that can access and display data in very powerful ways. They often allow the data to be separated from the interface over the network, so that it can reside on a central server. But, again, we're still talking about relational databases.
Moving to a Distributed Environment
In recent years , the requirements and mode of operation of most businesses have changed. Without consciously realizing it, we've moved away from relying on a central relational database to store all the data that a company produces and needs to access. Now, data is stored in email servers, directory services, Office documents, and other places “ as well as the traditional relational database.
The move to a more distributed computing paradigm means that the central data store, running on a huge computer in an air-conditioned IT department, is often only a part of the whole corporate data environment. Modern data access technologies need to be able to work with a whole range of different types of data store, as shown in Figure 8-1.
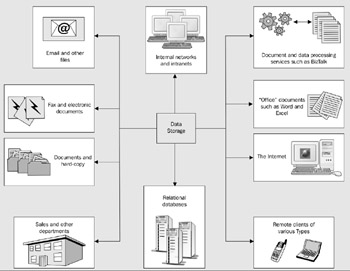
Figure 8-1:
You can see that the range of storage techniques has become quite quite wide. It's easy to see why the term database is no longer appropriate for describing the many different ways that data is often stored today. Distributed computing means that we have to be able to extract data in a suitable format, move it around across a range of different types of network, and change the format of the data to suit many different types of client device.
The next section explores one of the areas where data storage and management is changing completely “ the growth in the use of XML .
XML “ A Data Format for the Future?
One of the most far-reaching of the new ideas in computing is the evolution of XML. The World Wide Web Consortium ( W3C ) issued proposals for XML some three years ago (at the time of writing), and these have matured into standards that are being adopted by almost every sector of the industry.
XML scores when it comes to storing and transferring data “ it is an accepted industry standard, and it is just plain text. The former means that we have a way of transferring and exposing information in a format that is independent of platform, operating system, and application. Compare this to, for example, the MIME-encoded recordsets that Internet Explorer's Remote Data Service ( RDS ) uses. Instead, XML means that you don't need a specific object to handle the data. Any manufacturer can build one that will work with XML data, and developers can use one that suits their platform, operating system, programming language, or application.
XML is just plain text, and so you no longer have to worry about how to store and transport it. It can be sent as a text file over the Internet using HTTP (which is effectively a 7-bit only transport protocol). You don't have to encode it into a MIME or UU-encoded form. You can also write it to a disk as a text file, or store it in a database as text. OK, so it often produces a bigger file than the equivalent binary representation, but compression and the availability of large cheap disk drives generally compensate for this.
Applications have already started exposing data as XML in many ways. For example, Microsoft SQL Server 2000 includes features that allow you to extract data directly as XML documents, and update the source data using XML documents. Databases such as Oracle 8i and 9i are designed to manipulate XML directly, and the most recent office applications like Word and Excel will save their data in XML format either automatically or on demand.
XML is already directly ingrained into many applications. ASP.NET uses XML format configuration files, and web services expose their interface and data using an implementation of XML called the Simple Object Access Protocol ( SOAP ).
Other XML Technologies
As well as being a standard in itself, XML has also spawned other standards that are designed to interoperate with it. Two common examples are XML Schemas , which define the structure and content of XML documents, and the Extensible Stylesheet Language for Transformation ( XSLT ), which is used to perform transformations of the data into new formats.
XML schemas also provide a way for data to be expressed in specific XML formats that can be understood globally, or within specific industries such as pharmaceuticals or accountancy applications. There are also several server applications that can transform and communicate XML data between applications that expect different specific formats (or, in fact, other non-XML data formats). In the Microsoft world, this is BizTalk Server, and there are others such as Oasis and Rosetta for other platforms.
Just Another Data Access Technology?
To quote a colleague of mine, "Another year, another Microsoft data access technology". We've just got used to ActiveX Data Objects ( ADO ), and it's all-change time again. Is this some fiendish plan on Microsoft's behalf to keep us on our toes, or is there a reason why the technology that seemed to work fine in previous versions of ASP is no longer suitable?
In fact, there are several reasons why we really need to move on from ADO to a new technology. We'll examine these next, then later on take a high-level view of the changes that are involved in moving from ADO to the new .NET Framework data access techniques.
.NET Means Disconnected Data
You've seen a bit about how relational databases have evolved over recent years. However, it's not just the data store that has evolved “ it's the whole computing environment. Most of the relational databases still in use today were designed to provide a solid foundation for the client-server world. Here, each client connects to the database server over some kind of permanent network connection, and remains connected for the duration of their session.
For example, with Microsoft Access, the client opens a Form window (often defined within their client- side interface program). This form fetches and caches some or all of the data that is required to populate the controls on the form from the server-side database program, and displays it on the client. The user can manipulate the data, and save changes back to the central database over their dedicated connection.
For this to work, the server-side database has to create explicit connections for each client, and maintain these while the client is connected. As long as the database software and the hardware it is running on are powerful enough for the anticipated number of clients, and the network has the bandwidth and stability to cope with the anticipated number of client connections, it all works very well.
But when this is moved to the disconnected world of the Internet, it falls apart very quickly. The concept of a stable and wide- band connection is hard enough to imagine, and the need to keep this connection permanently open can quickly cause problems to appear. It's not so bad if you are operating in a limited- user scenario, but for a public web site, it's obviously not going to work out.
In fact, there are several aspects to being disconnected. The nature of the HTTP protocol that is used on the Web means that connections between client and server are only made during the transfer of data or content. They aren't kept open after a page has been loaded or a recordset has been fetched .
On top of this, there is often a need to use the data extracted from a data store while not even connected to the Internet at all. Maybe while the user is traveling with a laptop computer, or the client is on a dialup connection and needs to disconnect while working with the data then reconnect again later.
This means that we need to use data access technologies where the client can access, download, and cache the data required, then disconnect from the database server or data store. Once the clients are ready, they then need to be able to reconnect and update the original data store with the changes.
Disconnected Data in N- Tier Applications
Another aspect of working with disconnected data arises when you move from a client-server model into the world of n -tier applications. A distributed environment implies that the client and the server are separate, connected by a network. To build applications that work well in this environment, you can use a design strategy that introduces more granular differentiation between the layers , or tiers , of an application.
As Figure 8-2 shows, it's usual to create components that perform the data access in an application (the data tier ), rather than having the ASP code hit the data store directly. There is often a series of rules (usually called business rules ) that have to be followed, and these can be implemented within components.
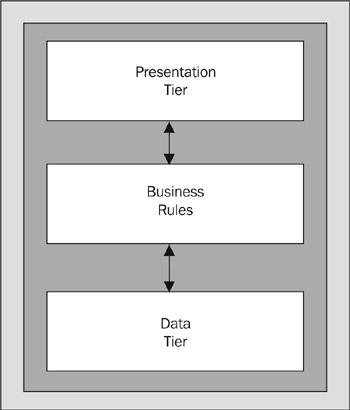
Figure 8-2:
They might be part of the components that perform the data access, or they might be separate “ forming the business tier (or application logic tier). There may also be a separate set of components within the client application (the presentation tier ) that perform specific tasks for managing, formatting, or presenting the data.
The benefits of designing applications along these lines are many, such as reusability of components, easier testing, and faster development.
Let's take a look at how this influences the process of handling data.Within an n -tier application, the data must be passed between the tiers as each client request is processed . So, the data tier connects to the data store to extract the data, perhaps performs some processing upon it, and then passes it to the next tier. At this point, the data tier will usually disconnect from the data store, allowing another instance (another client or a different application) to use the connection.
By disconnecting the retrieved data from the data store at the earliest possible moment, we improve the efficiency of the application and allow it to handle more concurrent users. However, it again demonstrates the need for data access technologies that can handle disconnected data in a useful and easily manageable way “ particularly when we need to update the original data in the data store.
The Evolution of ADO
Pre-ADO data access technologies, such as Data Access Objects ( DAO ) and Remote Data Objects ( RDO ) were designed to provide open data access methods for the client-server world “ and are very successful in that environment. For example, if you build Visual Basic applications to access SQL Server over your local network, they work well.
However, with the advent of ASP 1.0, it was obvious that something new was needed. It used only active scripting (such as VBScript and JScript) within the pages, and for these a simplified ActiveX or COM-based technology was required. The answer was ADO 1.0, included with the original ASP installation. ADO allows you to connect to a database to extract recordsets, and perform updates using the database tables, SQL statements, or stored procedures within the database.
However, ADO 1.0 was really only an evolution of the existing technologies, and offered no solution for the disconnected problem. You opened a recordset while you had a connection to the data store, worked with the recordset (maybe updating it or just displaying the contents), then closed it and destroyed the connection. Once the connection was gone, there was no easy way to reconnect the recordset to the original data.
To some extent, the disconnected issue was addressed in ADO 2.0. A new recordset object allowed you to disconnect it from the data store, work with the contents, then reconnect and flush the changes back to the data store. This worked well with relational databases such as SQL Server, but was not always an ideal solution. It didn't provide the capabilities to store relationships and other details about the data “ basically all you stored was the rowset containing the values.
Another technique that came along with ADO 2.0 was the provision of a Data Source Object ( DSO ) and Remote Data Services ( RDS ) that could be used in a client program such as Internet Explorer to cache data on a client. A recordset can be encoded as a special MIME type and passed over HTTP to the client where it is cached. The client can disconnect and then reconnect later and flush changes back to the data store. However, despite offering several useful features such as client-side data binding, this nonstandard technique never really caught on “ mainly due to the reliance on specific clients and concerns over security.
To get around all these limitations, the .NET Framework data access classes have been designed from the ground up to provide a reliable and efficient disconnected environment for working with data from a whole range of data stores.
.NET Means XML Data
As you saw earlier in this chapter, the computing world is moving ever more towards the adoption of XML as the fundamental data storage and transfer format. ADO 1.0 and 2.0 had no support for XML “ it wasn't around as anything other than vague proposals at that time. In fact, at Microsoft, it was left to the Internet Explorer team to come up with the first tools for working with XML “ the MSXML parser that shipped with IE 5 and other applications.
Later, MSXML became part of the ADO team's responsibilities and surfaced in ADO 2.1 and later as an integral part of Microsoft Data Access Components ( MDAC ). Along with it, the DSO used for remote data management and caching had XML support added. Methods were also added to the integral ADO objects.
The Recordset object gained methods that allowed it to load and save the content as XML. However, it was never anything more than an add-on, and the MSXML parser remained distinct from the core ADO objects.
Now, to bring data access up to date in the growing world of XML data, .NET includes a whole series of objects that are specifically designed to manage and manipulate XML data. This includes native support for XML formatted data within objects like the Dataset , as well as a whole range of objects that integrate a new XML parsing engine within the framework as a whole.
.NET Means Managed Code
As mentioned before, the .NET Framework is not a new operating system. It's a series of classes and a managed runtime environment within which code can be executed. The framework looks after all the complexities of garbage collection, caching, memory management and so on “ but only as long as you use managed code. Once you step outside this cozy environment, the efficiency of your applications reduces (the execution has to move across the process boundaries into unmanaged code and back).
The existing ADO libraries are all unmanaged code, and so we need a new technology that runs within the .NET Framework. While Microsoft could just have added managed code wrappers to the existing ADO libraries, this would not have provided an ideal or efficient solution.
Instead, the data access classes within .NET have been designed from the ground up as managed code. They are integral to the framework and so provide maximum efficiency. They also include a series of objects that are specifically designed to work with MS SQL Server, using the native Tabular Data Stream ( TDS ) interface for maximum performance. Alternatively, managed code OLEDB, ODBC and Oracle providers are included with the framework to allow connections to all kinds of other data stores.
.NET Means a New Programming Model
One of the main benefits of moving to .NET is the ability to get away from the mish-mash of HTML content and script code that traditional ASP always seems to involve. Instead, there is a whole new structured programming model and approach to follow. You should use server controls (and user controls) to create output that is automatically tailored to each client, and react to events that these controls raise on the server.
Write in proper languages, and not script. Instead of VBScript, you can use Visual Basic, C#, as well as a compiled version of the JScript language. And, if you prefer, you can use C++, COBOL, Active Perl, or any one of the myriad other languages that are available or under development for the .NET platform.
This move to a structured programming model with server controls and event handlers provides improvements over existing data handling techniques using traditional ADO. For example, in ADO you need to iterate through a recordset to display the contents. However, the .NET Framework provides extremely useful server controls such as the DataGrid , which look after displaying the data themselves “ all they need is a data source such as a set of records (a rowset ).
So, instead of using Recordset -specific methods like MoveNext to iterate through a rowset, and access each field in turn , you just bind the rowset to the server control. It carries out all the tasks required to present that data, and even makes it available for editing. Yet, if required, you can still access data as a read-only and forward-only rowset using the new DataReader object instead. Overall, the .NET data access classes provide a series of objects that are better suited to working with data using server controls, as well as manipulating it directly with code.
EAN: 2147483647
Pages: 243