Working with Raw XML
| The XmlDataSource control gives you a great way to display XML data, but there are times when you need to interact with XML documents. There are several classes you can use for working directly with XML, and which classes you use depends upon your requirements. There are generally two ways of working with XML: in-memory or streamed from a file, and these ways will dictate which classes you use. Whether you should use in-memory or streamed XML is also a question of your requirements, and certain scenarios naturally lead to one form or another. Typical scenarios where you should use in-memory XML stores include the following:
Typical scenarios where you should not use in-memory XML stores include the following:
Streaming XMLStreaming XML is a connected scenario, where you are navigating through an XML file. You use the XmlReader class for reading, and the XmlWriter class for writing. Typical scenarios where you will be streaming XML include the following:
All of these scenarios can be achieved with the XmlReader and XmlWriter classes, both of which are simple to use, although you need to understand a bit about how XML documents are structured. This is best seen with an example. Reading XML DocumentsFor example, consider Listing 7.12, which uses the Create method to create an XmlReader over the shippers file. Like the SqlDataReader, the XmlReader uses the Read method to read nodes from the underlying data, returning false if no more nodes can be read. The Name property returns the name of the element. Listing 7.12. Using an XmlReader
What's interesting about this code fragment is that it returns more than you'd first think. shippers shipper ShipperID ShipperID CompanyName CompanyName Phone ... shipper shippers What you notice is that the element names appear twice, which is because there are two of them in the XML file: the start and end parts of the elementeach appear as separate nodes. There are also other nodes in the XML file; whitespace appears as a separate node as does the value of the element. This is what we mean when we said you must understand a bit about how XML documents are structuredthey are node-based. So everything within an XML document is a node, and you can see this in Figure 7.9, where even the white space in the document is a node. Compare this with Figure 7.10, where there are fewer nodes and no values, because the content is stored within attributes. Figure 7.9. Nodes, types, and values of the Shippers document Figure 7.10. Nodes, types, and values for Shippers Attributes document The most important point these figures show is that when navigating through documents with an XmlReader, you need to know the structure of the XML if you want to process it in an intelligent fashion. The XmlReader has plenty of methods to determine if the current node has a value, or has attributes, and what type of node it is so that you can build logic into the data reading. Writing XML DocumentsWriting XML documents is similar to reading them, in that you are dealing with nodes as they will appear in the output document. You have to remember that XML documents are hierarchical, and that nodes have a start point and an end point, and so you have to create the start and end of each node as you write the file. This is shown in Listing 7.13. Listing 7.13. Writing XML Using the XmlWriter
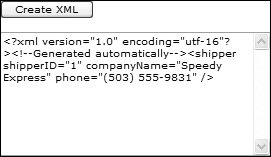
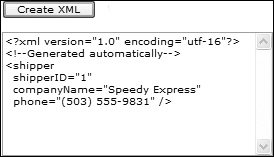
This code uses the static Create method of the XmlWriter class to create the writer (ignore the null for the moment), writing into a StringBuilder. You can also write to streams and files, but the results of this example are output of the XML to a TextBox control. The writer is then used to write content, starting with the documenteach XML must have a document element (thats the <?xml> element) that indicates this is an XML document, its version, and the encoding scheme used. Next, WriteComment is used to write a simple text comment, and then the first element, shipper, is started with WriteStateElement, which writes <shipper to the string builder. Within this element, WriteStartAttribute is used to start an attribute, WriteString to write the value of the attribute, and WriteEndAttribute to write the closing > of the attribute. Other attributes can be added in the same manner before WriteEndElement is used to close the element, and WriteEndDocument is used to end the document. The results of this can be seen in Figure 7.11. Figure 7.11. Unformatted XML If you are supplying this XML to another program, this output is perfectly acceptable, with no white space, but it is slightly hard to read. The output can automatically be formatted by creating XmlWriterSettings and passing them into the Create method of the XmlWriter in place of the null shown in earlier code. Listing 7.14 shows this in action, using the Indent property of the XmlWriterSettings to indicate that indenting should be used for child elements and using NewLineOnAttributes to add a new line before an attribute. The results of this are shown in Figure 7.12. Figure 7.12. Formatted XML Listing 7.14. Using XmlWriterSettings
Reading and writing XML using the XmlReader and XmlWriter classes is streaming-based, meaning that you have to deal with nodes in the order in which they appear in the document. If you need to deal with nodes in a more arbitrary manner, streaming is not the solution. Instead, you need to deal with an in-memory XML store. Working with XML Documents in MemoryWhen working with XML in memory, you will use one of the XPathDocument, XmlDocument, or XmlDataDocument classes. The difference between them is summed up easily:
All of these objects deal with an XML document in its entirety but don't provide a way to navigate around the nodes. For this, you use an XPathNavigator, which provides read (and write if the underlying object supports updates) access to the nodes in the document. The use of these is best seen with some examples. Using the XPathDocument ObjectThe XPathDocument is really a way of providing a read-only document to an XPathNavigator, as it only has constructors and a single methodCreateNavigator. The constructors allow the document to be created from a variety of sources, such as streams, text readers, and files, while the CreateNavigator method returns an XPathNavigator that allows you to navigate around the document. Listing 7.15 shows some examples of the movement types, using MoveToFirstChild to move to the first child of the current node; subsequent calls will move deeper into the hierarchy of nodes. MoveToFirstAttribute allows you move to the first attribute for a node, and there are equivalents for moving to the next node or attribute as well as moving to previous nodes, the first node, selecting a range of nodes with an XPath expression, and so on. Listing 7.15. Using the XPathDocument and XPathNavigator
The output of this code is as follows: Processing 'cars.xml' - editing allowed: False First child: Automobiles First child of 'Automobiles': Manufacturer Inner XML: <Car Model="A4" > <Package Trim="Sport Package" /> <Package Trim="Luxury Package" /> </Car> <Car Model="A6" > <Package Trim="Sport Package" /> <Package Trim="Luxury Package" /> </Car> <Car Model="A8" > <Package Trim="Sport Package" /> <Package Trim="Luxury Package" /> </Car> First attribute of 'Manufacturer': Make=Audi Previous: Make Reset: Automobiles You can see that you can move forward and backward through the nodes, and you can access element and attribute values as well as the entire XML for the node. The limitation of the XPathDocument is that it is readonly, so for updates you need to consider the XmlDocument. Using the XmlDocument ObjectIn use, XmlDocument can be similar to the XPathDocument in that you use an XPathNavigator to move through the document, but because the XPathDocument is read-write, you can use additional methods on the navigator to create new content, as seen in Listing 7.16. Listing 7.16. Creating Nodes with an XmlDocument
Here a new manufacturer is created using the PrependChildElement method, which adds a new element, and CreateAttribute is used to create attributes on the new element. The output of this code is as follows: <Automobiles> <Manufacturer Make="Ferrari" WebSite="http://www.ferrari.com/"> <Car Model="F430" /> </Manufacturer> <Manufacturer Make="Audi" WebSite="http://www.audi.com/"> <Car Model="A4" > <Package Trim="Sport Package" /> <Package Trim="Luxury Package" /> The XPathNavigator offers many methods for creating content within the document it is navigating over, including appending elements, inserting before and after, replacing existing elements, and changing values of existing elements. What is interesting about this method of working with XML documents is that it offers great flexibility; you can work with existing content, add nodes individually, or, in conjunction with XmlReaders and XmlWriters, add content in bulk. Using the XmlDataDocument ObjectMany ASP.NET developers also sit in the database developer camp, having to do database design and administration. While knowledge of XML is also widespread, the use of the XML APIs described in this chapter isn't, and often the DataSet is used, because it has ReadXML and WriteXML methods to surface the relational data in XML form. For the developer experienced with XML but not relational data, the XmlDataDocument is the solution. It is a subclass of the XmlDocument and provides one really important additional property, DataSet, which returns the XML data as a DataSet object. Before the DataSet can be exposed from the XML, a schema must be used so that the DataSet knows the structure of the underlying XML. Listing 7.17 shows this in action. First an XmlDataDocument is created, and the DataSet property is used to read the schema. The DataSet property is then used as the source for a grid, and because the DataSet property is simply just another view on the XML data, rows can be added to the DataSet and they are visible in the XML, as seen in Figure 7.13. Figure 7.13. Using the XmlDataDocument's DataSet Listing 7.17. Using the XmlDataDocument
|



EAN: 2147483647
Pages: 147