Parsing XML Documents in Code
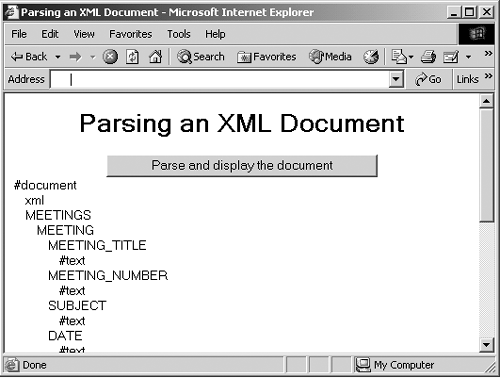
| Up to this point, I've gone after a specific element in a Web page, but there are other ways of handling documents, too. For example, you can parsethat is, read and interpretthe entire document at once. Here's an example. In this case, I'll work through this entire XML document, ch07_01.xml, displaying all its nodes in an HTML Web page. To handle this document, I'll create a function, iterateChildren , that will read and display all the children of a node. As with most parsers, this function is a recursive function, which means that it can call itself to get the children of the current node. To get the name of a node, I will use the nodeName property. To parse an entire document, then, you just have to pass the root node of the entire document to the iterateChildren function, and it'll work through the entire document, displaying all the nodes in that document: function parseDocument() { documentXML = document.all("meetingsXML").XMLDocument resultsDIV.innerHTML = iterateChildren(documentXML, "") } . . . Note that I've also passed an empty string, "" , to the iterateChildren function. I'll use this string to indent the various levels of the display, to indicate what nodes are nested inside what other nodes. In the iterateChildren function, I start by creating a new text string with the current indentation string (which is either an empty string or a string of spaces), as well as the name of the current node and a <BR> element that so the browser will skip to the next line: function parseDocument() { documentXML = document.all("meetingsXML").XMLDocument resultsDIV.innerHTML = iterateChildren(documentXML, "") } function iterateChildren(theNode, indentSpacing) { var text = indentSpacing + theNode.nodeName + "<BR>" . . . return text } . . . I can determine whether the current node has children by checking the childNodes property, which holds a node list of the children of the current node. I can determine whether the current node has any children by checking the length of this list with its length property, and if so, I call iterateChildren on all child nodes (note also that I indent this next level of the display by adding four non-breaking spaceswhich you specify with the entity reference in HTMLto the current indentation string): function iterateChildren(theNode, indentSpacing) { var text = indentSpacing + theNode.nodeName + "<BR>" if (theNode.childNodes.length > 0) { for (var loopIndex = 0; loopIndex < theNode.childNodes.length; loopIndex++) { text += iterateChildren(theNode.childNodes(loopIndex), indentSpacing + " ") } } return text } . . . And that's all it takes. Here's the whole Web page: Listing ch07_06.html <HTML> <HEAD> <TITLE> Parsing an XML Document </TITLE> <XML ID="meetingsXML" SRC="ch07_01.xml"></XML> <SCRIPT LANGUAGE="JavaScript"> function parseDocument() { documentXML = document.all("meetingsXML").XMLDocument resultsDIV.innerHTML = iterateChildren(documentXML, "") } function iterateChildren(theNode, indentSpacing) { var text = indentSpacing + theNode.nodeName + "<BR>" if (theNode.childNodes.length > 0) { for (var loopIndex = 0; loopIndex < theNode.childNodes.length; loopIndex++) { text += iterateChildren(theNode.childNodes(loopIndex), indentSpacing + " ") } } return text } </SCRIPT> </HEAD> <BODY> <CENTER> <H1> Parsing an XML Document </H1> </CENTER> <CENTER> <INPUT TYPE="BUTTON" VALUE="Parse and display the document" ONCLICK="parseDocument()"> </CENTER> <DIV ID="resultsDIV"></DIV> </BODY> </HTML> When you click the button in this page, it will read ch07_01.xml and display its structure as you see in Figure 7-4. You can see all the nodes listed there, indented as they should be. Note also the "metanames" that Internet Explorer gives to document and text nodes: #document and #text . Figure 7-4. Parsing a document in Internet Explorer. |
EAN: 2147483647
Pages: 440