Test configuration
|
| < Day Day Up > |
|
This section summarizes the hardware and software configurations used in the tests.
Hardware
Figure 4-3 shows the hardware used in our test configuration.
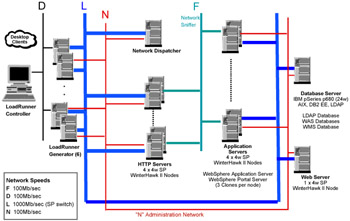
Figure 4-3: The test configuration
The configuration consisted of four HTTP servers and four application servers, with a network dispatcher in front of the HTTP servers and a database server behind the application servers.
The HTTP servers and application servers were all RS/6000® SP2 'WinterHawk II' nodes (4-way 375 MHz, POWER3II processors) with 4 GB of RAM. The database server was an IBM ~ pSeries® model p680 with 24 processors and 96 GB of RAM. In terms of machine power, the database server was more powerful than was strictly necessary for the workload level in these tests, but we have also used the same hardware setup for other WebSphere Portal tests, including scaling up to a very large cluster of thirty nodes. The LoadRunner Generators were also RS/6000 SP2 nodes of the same type as the application servers.
The network configuration was such that network traffic between the HTTP servers and the application servers was on a separate network from the traffic between the clients and the HTTP servers. This was achieved using multiple network interfaces in each of the servers. In addition, every server had a third network interface (the 'N' or Administration Network), which was used exclusively for monitoring and administration and was made separate so that administration and monitoring would not interfere with the test traffic.
The test load was created using Mercury Interactive's LoadRunner® product with virtual user generators running on RS/6000 SP2 nodes similar to the HTTP Server and Application Server nodes. Typically, four generators were used in most of our tests.
Software
See Appendix A for the details of the versions of the software products used.
Application server clones: Each application server node ran three portal clones.
WebSphere session support: WebSphere was configured to use session affinity via cookies, but session persistence was not enabled.
User database: The user database was populated with 200,000 users, configured in a hierarchy of groups.
Portal access controls: Access control to places, pages, and portlets was on the basis of group membership.
Test script
These tests used a script that consisted of these steps:
-
Access the portal default page
-
Click on the 'login' icon and receive the login form
-
Enter login details, submit the form, and receive the default logged in page
-
Visit seven more pages
-
Click logoff, and receive the Portal default page again
IDs were chosen at random from the database of 200,000 defined users.
The script had a built-in think time of ten seconds, and the HTTP servers were configured with a 'keepalive ' timeout of five seconds to ensure that, as would be the case for human users on the Internet, each new page request required the creation of a new TCP connection to the HTTP server.
Workload management in the test scripts
The way workload management operated during normal execution (that is, without interference from failover or recovery activity) of our test scripts was as follows
-
The first client request sets up a new connection to the system, which is assigned by Network Dispatcher to one of the four HTTP servers. The chosen HTTP server assigns the request to one of its HTTP server processes, and then to the particular instance of the WebSphere plug-in belonging to that process.
-
This first request does not have session affinity already established (because it is a new session), so the plug-in uses its load-balancing algorithm to select a particular clone to receive the request.
-
The response from the selected clone sets the JSESSIONID session affinity cookie that is then used in all subsequent requests in this particular user session. The session affinity cookie identifies the particular application server clone that now 'owns' the session.
-
On receipt of the page HTML, the client proceeds to retrieve all the objects comprising the page (style sheets, .gif files, .jpg files, etc). In doing this, the client opens up a second connection to the system. This is because the version of Internet Explorer being emulated in our tests normally uses two parallel connections to the HTTP server to optimize the receipt of Web pages. The number of concurrent connections between the client and the system is a feature of the browser version in use. Other browser versions can open up larger numbers of parallel connections - for example, Netscape Communicator will normally use up to four concurrent connections. Other browser versions can use more still - up to eight parallel connections from a single browser client is not uncommon.
-
Network Dispatcher assigns the second connection to one of the four HTTP servers in the system, and not necessarily to the server that handled the first connection. Even if the second connection happened to be assigned to the same server as the first one, a different HTTP server process and a different instance of the WebSphere plug-in is assigned to handle the second connection because the one handling the first connection is still occupied. If more than two concurrent connections are in use, the same mechanism applies to the additional connections.
-
Whether handled by the initial connection or by this new second connection, the presence of the session affinity cookie means that these subsequent HTTP GET requests are directed to the same portal clone that handled the first request in the session. This is true even though the requests may be handled by a different instance of the WebSphere plug-in, and possibly even a different physical HTTP server machine.
-
Our test script included ten seconds of think time between completing receipt of one page response and sending the first request for the next page. We set the HTTP Server keepalive [1] value to 5 seconds to ensure that each new page requested by the script would require a new connection to the HTTP server. This reflects system behavior in the real world where keepalive values are normally set at a level that avoids tying up HTTP server connections with users who have left the site or are thinking for long periods. This normally leads to each new user page request setting up new TCP connection(s) to the Web server.
-
Despite the fact that each new page request initiates new connections to the HTTP server, the presence of the session affinity cookie means that no matter which instance of the WebSphere plug-in handles the request, in normal circumstances the request is sent to the clone that handled the previous page request for the same user.
-
Our script ended with a logoff request. This request causes the user session to be terminated, and results in the user seeing the default page for the site. Accessing this default page is done without session affinity (because the session that had been in effect for this particular user has now been terminated), so the particular plug-in that handles this request has to make a load balancing decision in order to select a clone to which the request should be sent.
-
As a result of the above, each iteration of the script requires only two 'clone-selection' decisions on the part of the plug-ins - one on the first page of the script, and one following the logoff request at the end of the script.
-
The test script consisted of eleven page requests, with ten ten-second gaps between them and one iteration of the script lasted a little over one hundred seconds.
For simplicity in the above description, given our focus on the behavior of the WebSphere plug-in, for the most part we have ignored the presence of the network dispatcher, which distributed client requests across the four HTTP server machines.
One consequence of the above behavior in this system is that in the event of a clone becoming unavailable; it takes a significant time before all the plug-ins get around to marking the unavailable clone as down.
This can be seen from the following very rough calculation:
| Comment | ||
|---|---|---|
| Number of Vusers | 1,000 | |
| Duration of script | 100 seconds | |
| Number of 'clone-selection' decisions per iteration of the script | 2 | These are the first page requested and the page delivered after logoff (the portal default page again) |
| Rate of clone-selection decisions per Vuser | One every 50 seconds | Script duration 100 seconds, two decisions per script |
| Number of clone-selection decisions per second overall | 20 | 1000 / 50 |
| Number of HTTP servers | 4 | |
| Number of plug-in instances per HTTP server | 500 | 1000 virtual users, two connections per user, four HTTP servers (100 x 2 / 4) = 500 |
| Total number of plug-in instances | 2,000 | 4 x 500 |
| Rate of clone selection decisions in each plug-in instance | 1 every 100 seconds | 1,000 plug-ins divided by overall rate of 20 decisions per second |
| Number of portal clones in the system | 12 | Three on each of the four application server machines |
| Time taken for a particular instance of the plug-in to select every clone | 1,200 seconds (20 minutes) | 12 clones x 100 seconds per decision (for round robin load balancing) |
The last number in the table applies to round robin load balancing where the plug-ins cycle in order around the list of clones. With random load balancing, the time taken for all the plug-ins to recognize the absence of a missing clone would be significantly longer because statistically some of the time one or more clones can be chosen more than once before all of them are selected. As will be seen when we describe the specific test results, this leads to some effects that may not be obvious at first sight. These relate to the rate at which workload is assigned to the missing clones when they are restarted.
In our tests, we typically shut down one application server node (and all three clones within it), and let the system stabilize for around 15 minutes. We then restarted the missing application server node. In this case, by the time the missing node was restarted, plug-ins had been discovering the absence of the clones on the missing node for 15 minutes. As a result around three quarters (15 minutes/20 minutes) -- 1,500 roughly -- of the plug-in instances would have discovered the absence of the missing clones and would have marked them as down. The other 25% (500 roughly) of the plug-ins would not have discovered same.
The plug-in instances that discovered the absence of the missing clones made those discoveries gradually over the period when the clones were down (at a rate of roughly 100 per minute - 1,500 plug-ins in 15 minutes).
The length of time each plug-in instance waits before retrying access to a missing clone is specified by the plug-in RetryInterval parameter, which we had set to 30 minutes.
As a result, those plug-ins that had marked the missing clones as down through the 15 minutes before the clones were restarted, also begin to retry access to the revived clones gradually over a period of 15 minutes beginning 30 minutes after the clones were rendered unavailable, and again do so at the rate of roughly 100 per minute.
Those instances of the plug-in (around 500) that did not discover the clones were missing during their 15 minute absence send requests to the clones as and when those clones are selected by the plug-in's load balancing algorithm. This leads to a gradual increase in workload being assigned to the newly revived clones.
The workload grows gradually back to the truly balanced workload level as the RetryIntervals expire among the plug-ins that had marked the missing clones as down. This gradual growth lasts for the same length of time as the clones had been missing and begins RetryInterval number of seconds after the clones first became unavailable (1800 seconds) in our case).
[1]keepalive is an IBM HTTP server parameter that controls the length of time the HTTP server keeps client connections open in order to support receiving HTTP GET requests for multiple objects within a page using a single TCP connection. After keepalive seconds, the HTTP server closes the connection.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 117