Hack65.Speech Synthesize Your Podcast Introduction
Hack 65. Speech Synthesize Your Podcast Introduction
Placing a small introductory segment with the name of your podcast and the episode number or date at the beginning of the show is becoming standard. Learn how to use free or cheap speech synthesis tools to do this. Playback devices such as the iPod Shuffle, which have no screen, make it difficult to recognize what podcast you are listening to. Songs have different introductions that you can clue in on immediately; but a podcast has the same introductory material at the beginning of every show. This leaves listeners having to fast forward through the introduction to get to the show so that they can see if they have listened to it already. One solution is to place a few seconds of identifying material at the front of the show, with the name of your show and the episode number or date. To do that, podcasters have used both their voice and speech synthesis to record the segment. This hack shows how to get synthesized speech on demand on Macintosh, Windows, and the Web. 9.6.1. Speech Synthesis on MacintoshMac OS X has had speech synthesis built in from the start. The easiest way to invoke it is to select a piece of text in a document and then select the Start Speaking Text command from the Speech item in the Services menu (shown in Figure 9-7). The Services menu is that strange section of the application menu that nobody ever seems to use. In this case, I used TextEdit, the text editor that comes with the system, to write my introduction. Then I selected it and ran the Start Speaking Text command. You'll hear a slight delay the first time. Then you will hear the synthesized voice. To record this, use the System Audio sound source in Audio Hijack Pro. To change the timbre of the voice, use the Speech panel in System Preferences, as shown in Figure 9-8. You have 22 different voices to choose from, ranging from male and female voices to computer-sounding synthetic voices to voices that are fanciful in nature. Figure 9-7. The Speech service on Mac OS X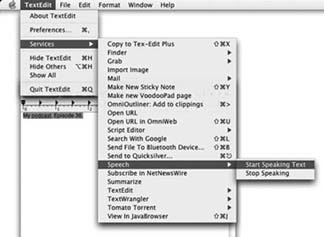 Figure 9-8. Choosing a default voice on Mac OS X Apple has gone a step further and embedded speech synthesis verbs into its AppleScript language. Open the Script Editor application (/Applications/ AppleScript) and type in this code: say "My podcast. Episode 36." Then press Run and you'll hear the synthesized sound. You can have the speech synthesizer speak any string you want. You even can specify the voice if you want: say "My podcast. Episode 36." using "Agnes" If you don't specify the voice, you will get the system default voice that you set in the Speech System Preferences panel. In addition, you can have the system save the speech output to a sound file, like this: say myString using "Agnes" saving to ":Users:jherr:Desktop:foo.aif" Outputting the sound to the file takes much less time than it would take the system to play the file and record it in Audio Hijack Pro [Hack #50]. If you are going to edit your podcast in a program such as GarageBand, Logic Express, or Pro Tools, you should have the speech synthesizer save it to a file. Then you can just drag-and-drop it into your project where you want it. Certain commands allow you to control your Macintosh through speech with AppleScript, or through the Speech preferences panel. Although we don't cover that in this hack, it's still neat and is worth playing with. Cepstral Text-to-Speech (http://cepstral.com/) has several speech synthesizer voices for both Windows and Macintosh. These voices are relatively inexpensive at around $30 apiece. The quality of the sound is far superior to the MacinTalk sounds you get with the Macintosh built-in voices. 9.6.2. Speech Synthesis on WindowsTo get your Windows machine to talk to you, use the Speech control panel, as shown in Figure 9-9. Figure 9-9. Setting the default voice on Windows XP Type the text you want the synthesizer to say into the "Use the following text to preview the voice" text box. Then press the Preview button to hear the voice. You can alter the type of voice by clicking the first drop-down menu and selecting from one of the three available voices. You can speed up or slow down the speech by using the slider at the bottom of the dialog. Recording the voice is a little trickier. I was able to use Total Recorder Pro to grab the output stream of the voice synthesizer by clicking the Audio Output button on this dialog, selecting "Use this audio output device," and then selecting Playback through Total Recorder in the drop-down menu. Total Recorder [Hack #50] saved the speech in the output file to the location I wanted in the format I specified. 9.6.2.1 Speech synthesis from code.Microsoft is supporting both speech synthesis and speech control through its speech APIs. You can download the SDK at http://microsoft.com/speech. Click the link for the Microsoft Speech Application Software Development Kit 1.1 Beta (or a more recent version), follow the instructions, and get a huge download. Once you have downloaded this monster, you unpack it into C:\SpeechSDK. Within that folder is the Redistributable Installers\Speech Add-in for Microsoft Internet Explorer folder. That contains the speech extension for Internet Explorer. Launch the setup.exe program in that folder to install the speech extensions. With that installed, you should be able to write small web pages that synthesize voice on your computer. This code sample, which I found on the Web, drives the engine from a web page: <html xmlns:salt="http://www.saltforum.org/2002/SALT"> <object CLASS> </object> <?import namespace="salt" implementation="#speech-add-in"/> <salt:prompt ></salt:prompt> <body> <h2>SALT: Speak Field Contents</h2> <input type="text" name="iptext" value="Type some text here" size="40"> <input type="button" name="speak" value="Speak" onClick="dospeak( ) "> </body> <script> function dospeak( ) { var pfield=document.getElementById("iptext"); var pprompt=document.getElementById("prompter"); pprompt.Start(pfield.value); } </script> </html> Save this file anywhere on your drive as speech.html. Then view it (Figure 9-10) with Internet Explorer. It will not work properly in Firefox or any other non-IE browser. Figure 9-10. A simple Speech Application Language Tags (SALT)enabled web page The object definition at the top of the page creates a new control for the speech add-in. Then there is a text field where you type the text to be spoken, and a button labeled Speak that you click to activate the synthesizer. This calls the dospeak JavaScript function, which in turn calls Start on the speech engine with the value of the text field. Type your text into the text field and then press the Speak button to have the synthesizer say your words. The output will go out the sound driver set in the Speech control panel. You can use Total Recorder to capture the sound to a file. The Speech SDK also contains APIs that you can use from any of the .NET languages to drive the speech engine. A good example is AutoCast (http://autocastsoftware.com/), which reads RSS feeds and then uses the Speech API to turn the text into speech [Hack #6] that is stored as MP3 files for a podcast aggregator. Full source code for AutoCast is included on the site. 9.6.2.2 Windows voice synthesis programs.VoiceMX Studio 4 (http://www.tanseon.com/), $19.95, is a text-to-voice application for Windows that has a much smoother voice than the Windows API driver does. VoiceMX Studio 4 is pictured in Figure 9-11. Type the text you want read into the text field and then hit the SPEAK button to play it, or the FILENAME button to save the output directly to a .wav file. 9.6.3. Speech Synthesis on the WebGood-quality text-to-speech is one of the Holy Grails of computer science. IBM has an ongoing research program in this field with a demo that is available on the Web (http://www.research.ibm.com/tts/coredemo.shtml), as shown in Figure 9-12. Figure 9-11. VoiceMX Studio 4 Figure 9-12. The text-to-speech page at IBM Research To have the system synthesize some speech for you, type your sentence into the box and press the SPEAK button. You will get a file of the audio in response that you can save to your local drive and use in your podcast. You have four different voices to choose from. In my opinion, all of them sound better than Macintosh and Windows voice drivers. The result is a lot smoother and more natural. You are limited in terms of the number of times per day you can access the site. But I didn't see anything on fair use of the generated audio. Lucent Technologies' Bell Labs also offers a demo of its speech synthesis system (http://www.bell-labs.com/project/tts/voices.html), as shown in Figure 9-13. Figure 9-13. The text-to-speech page at Lucent When you press the Synthesize button, you will receive an audio file in the format you specify. You can save this to a file on your disk and use it in your podcast by opening it in your mixing or editing application. The footer on the bottom of that page says that this engine is restricted to "noncommercial" uses, though there is no definition of what that means. 9.6.4. See Also
|
EAN: 2147483647
Pages: 144