Search Engines
9.6 Search Engines
The most widespread web robots are used by Internet search engines. Internet search engines allow users to find documents about any subject all around the world.
Many of the most popular sites on the Web today are search engines. They serve as a starting point for many web users and provide the invaluable service of helping users find the information in which they are interested.
Web crawlers feed Internet search engines, by retrieving the documents that exist on the Web and allowing the search engines to create indexes of what words appear in what documents, much like the index at the back of this book. Search engines are the leading source of web robotslet's take a quick look at how they work.
9.6.1 Think Big
When the Web was in its infancy, search engines were relatively simple databases that helped users locate documents on the Web. Today, with the billions of pages accessible on the Web, search engines have become essential in helping Internet users find information. They also have become quite complex, as they have had to evolve to handle the sheer scale of the Web.
With billions of web pages and many millions of users looking for information, search engines have to deploy sophisticated crawlers to retrieve these billions of web pages, as well as sophisticated query engines to handle the query load that millions of users generate.
Think about the task of a production web crawler, having to issue billions of HTTP queries in order to retrieve the pages needed by the search index. If each request took half a second to complete (which is probably slow for some servers and fast for others [26] ), that still takes (for 1 billion documents):
[26] This depends on the resources of the server, the client robot, and the network between the two.
0.5 seconds X (1,000,000,000) / ((60 sec/day) X (60 min/hour) X (24 hour /day))
which works out to roughly 5,700 days if the requests are made sequentially! Clearly, large-scale crawlers need to be more clever, parallelizing requests and using banks of machines to complete the task. However, because of its scale, trying to crawl the entire Web still is a daunting challenge.
9.6.2 Modern Search Engine Architecture
Today's search engines build complicated local databases, called "full-text indexes," about the web pages around the world and what they contain. These indexes act as a sort of card catalog for all the documents on the Web.
Search-engine crawlers gather up web pages and bring them home, adding them to the full-text index. At the same time, search-engine users issue queries against the full-text index through web search gateways such as HotBot ( http://www.hotbot.com ) or Google ( http://www.google.com ). Because the web pages are changing all the time, and because of the amount of time it can take to crawl a large chunk of the Web, the full-text index is at best a snapshot of the Web.
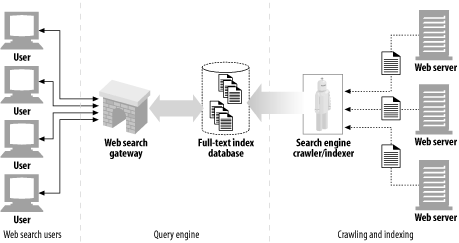
The high-level architecture of a modern search engine is shown in Figure 9-7 .
Figure 9-7. A production search engine contains cooperating crawlers and query gateways
9.6.3 Full-Text Index
A full-text index is a database that takes a word and immediately tells you all the documents that contain that word. The documents themselves do not need to be scanned after the index is created.
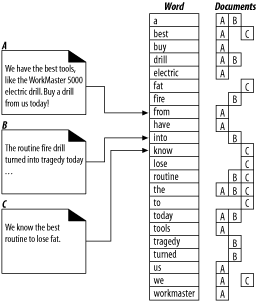
Figure 9-8 shows three documents and the corresponding full-text index. The full-text index lists the documents containing each word.
For example:
The word "a" is in documents A and B.
The word "best" is in documents A and C.
The word "drill" is in documents A and B.
The word "routine" is in documents B and C.
The word "the" is in all three documents, A, B, and C.
Figure 9-8. Three documents and a full-text index
9.6.4 Posting the Query
When a user issues a query to a web search-engine gateway, she fills out an HTML form and her browser sends the form to the gateway, using an HTTP GET or POST request. The gateway program extracts the search query and converts the web UI query into the expression used to search the full-text index. [27]
[27] The method for passing this query is dependent on the search solution being used.
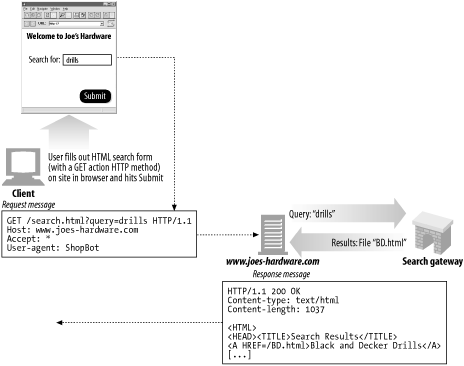
Figure 9-9 shows a simple user query to the www.joes-hardware.com site. The user types "drills" into the search box form, and the browser translates this into a GET request with the query parameter as part of the URL. [28] The Joe's Hardware web server receives the query and hands it off to its search gateway application, which returns the resulting list of documents to the web server, which in turn formats those results into an HTML page for the user.
[28] Section 2.2.6 discusses the common use of the query parameter in URLs.
Figure 9-9. Example search query request
9.6.5 Sorting and Presenting the Results
Once a search engine has used its index to determine the results of a query, the gateway application takes the results and cooks up a results page for the end user.
Since many web pages can contain any given word, search engines deploy clever algorithms to try to rank the results. For example, in Figure 9-8 , the word "best" appears in multiple documents; search engines need to know the order in which they should present the list of result documents in order to present users with the most relevant results. This is called relevancy ranking the process of scoring and ordering a list of search results.
To better aid this process, many of the larger search engines actually use census data collected during the crawl of the Web. For example, counting how many links point to a given page can help determine its popularity, and this information can be used to weight the order in which results are presented. The algorithms, tips from crawling, and other tricks used by search engines are some of their most guarded secrets.
9.6.6 Spoofing
Since users often get frustrated when they do not see what they are looking for in the first few results of a search query, the order of search results can be important in finding a site. There is a lot of incentive for webmasters to attempt to get their sites listed near the top of the results sections for the words that they think best describe their sites, particularly if the sites are commercial and are relying on users to find them and use their services.
This desire for better listing has led to a lot of gaming of the search system and has created a constant tug-of-war between search-engine implementors and those seeking to get their sites listed prominently. Many webmasters list tons of keywords (some irrelevant) and deploy fake pages, or spoofs even gateway applications that generate fake pages that may better trick the search engines' relevancy algorithms for particular words.
As a result of all this, search engine and robot implementors constantly have to tweak their relevancy algorithms to better catch these spoofs.
EAN: 2147483647
Pages: 294