Crawlers and Crawling
9.1 Crawlers and Crawling
Web crawlers are robots that recursively traverse information webs, fetching first one web page, then all the web pages to which that page points, then all the web pages to which those pages point, and so on. When a robot recursively follows web links, it is called a crawler or a spider because it "crawls" along the web created by HTML hyperlinks .
Internet search engines use crawlers to wander about the Web and pull back all the documents they encounter. These documents are then processed to create a searchable database, allowing users to find documents that contain particular words. With billions of web pages out there to find and bring back, these search-engine spiders necessarily are some of the most sophisticated robots. Let's look in more detail at how crawlers work.
9.1.1 Where to Start: The "Root Set"
Before you can unleash your hungry crawler, you need to give it a starting point. The initial set of URLs that a crawler starts visiting is referred to as the root set . When picking a root set, you should choose URLs from enough different places that crawling all the links will eventually get you to most of the web pages that interest you.
What's a good root set to use for crawling the web in Figure 9-1 ? As in the real Web, there is no single document that eventually links to every document. If you start with document A in Figure 9-1 , you can get to B, C, and D, then to E and F, then to J, and then to K. But there's no chain of links from A to G or from A to N.
Figure 9-1. A root set is needed to reach all pages
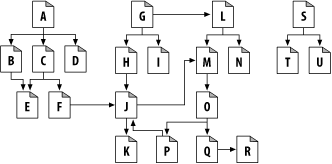
Some web pages in this web, such as S, T, and U, are nearly strandedisolated, without any links pointing at them. Perhaps these lonely pages are new, and no one has found them yet. Or perhaps they are really old or obscure.
In general, you don't need too many pages in the root set to cover a large portion of the web. In Figure 9-1 , you need only A, G, and S in the root set to reach all pages.
Typically, a good root set consists of the big, popular web sites (for example, http://www.yahoo.com ), a list of newly created pages, and a list of obscure pages that aren't often linked to. Many large-scale production crawlers, such as those used by Internet search engines, have a way for users to submit new or obscure pages into the root set. This root set grows over time and is the seed list for any fresh crawls.
9.1.2 Extracting Links and Normalizing Relative Links
As a crawler moves through the Web, it is constantly retrieving HTML pages. It needs to parse out the URL links in each page it retrieves and add them to the list of pages that need to be crawled. While a crawl is progressing, this list often expands rapidly , as the crawler discovers new links that need to be explored. [2] Crawlers need to do some simple HTML parsing to extract these links and to convert relative URLs into their absolute form. Section 2.3.1 discusses how to do this conversion.
[2] In Section 9.1.3 , we begin to discuss the need for crawlers to remember where they have been. During a crawl, this list of discovered URLs grows until the web space has been explored thoroughly and the crawler reaches a point at which it is no longer discovering new links.
9.1.3 Cycle Avoidance
When a robot crawls a web, it must be very careful not to get stuck in a loop, or cycle . Look at the crawler in Figure 9-2 :
In Figure 9-2 a, the robot fetches page A, sees that A links to B, and fetches page B.
In Figure 9-2 b, the robot fetches page B, sees that B links to C, and fetches page C.
In Figure 9-2 c, the robot fetches page C and sees that C links to A. If the robot fetches page A again, it will end up in a cycle, fetching A, B, C, A, B, C, A . . .
Figure 9-2. Crawling over a web of hyperlinks
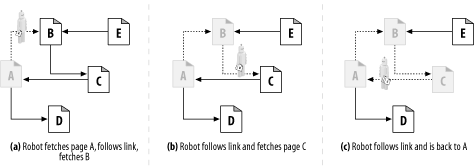
Robots must know where they've been to avoid cycles. Cycles can lead to robot traps that can either halt or slow down a robot's progress.
9.1.4 Loops and Dups
Cycles are bad for crawlers for at least three reasons:
They get the crawler into a loop where it can get stuck. A loop can cause a poorly designed crawler to spin round and round, spending all its time fetching the same pages over and over again. The crawler can burn up lots of network bandwidth and may be completely unable to fetch any other pages.
While the crawler is fetching the same pages repeatedly, the web server on the other side is getting pounded. If the crawler is well connected, it can overwhelm the web site and prevent any real users from accessing the site. Such denial of service can be grounds for legal claims.
Even if the looping isn't a problem itself, the crawler is fetching a large number of duplicate pages (often called "dups," which rhymes with "loops"). The crawler's application will be flooded with duplicate content, which may make the application useless. An example of this is an Internet search engine that returns hundreds of matches of the exact same page.
9.1.5 Trails of Breadcrumbs
Unfortunately, keeping track of where you've been isn't always so easy. At the time of this writing, there are billions of distinct web pages on the Internet, not counting content generated from dynamic gateways.
If you are going to crawl a big chunk of the world's web content, you need to be prepared to visit billions of URLs. Keeping track of which URLs have been visited can be quite challenging. Because of the huge number of URLs, you need to use sophisticated data structures to quickly determine which URLs you've visited. The data structures need to be efficient in speed and memory use.
Speed is important because hundreds of millions of URLs require fast search structures. Exhaustive searching of URL lists is out of the question. At the very least, a robot will need to use a search tree or hash table to be able to quickly determine whether a URL has been visited.
Hundreds of millions of URLs take up a lot of space, too. If the average URL is 40 characters long, and a web robot crawls 500 million URLs (just a small portion of the Web), a search data structure could require 20 GB or more of memory just to hold the URLs (40 bytes per URL X 500 million URLs = 20 GB)!
Here are some useful techniques that large-scale web crawlers use to manage where they visit:
Trees and hash tables
Sophisticated robots might use a search tree or a hash table to keep track of visited URLs. These are software data structures that make URL lookup much faster.
Lossy presence bit maps
To minimize space, some large-scale crawlers use lossy data structures such as presence bit arrays. Each URL is converted into a fixed size number by a hash function, and this number has an associated "presence bit" in an array. When a URL is crawled, the corresponding presence bit is set. If the presence bit is already set, the crawler assumes the URL has already been crawled. [3]
[3] Because there are a potentially infinite number of URLs and only a finite number of bits in the presence bit array, there is potential for collisiontwo URLs can map to the same presence bit. When this happens, the crawler mistakenly concludes that a page has been crawled when it hasn't. In practice, this situation can be made very unlikely by using a large number of presence bits. The penalty for collision is that a page will be omitted from a crawl.
Checkpoints
Be sure to save the list of visited URLs to disk, in case the robot program crashes.
Partitioning
As the Web grows, it may become impractical to complete a crawl with a single robot on a single computer. That computer may not have enough memory, disk space, computing power, or network bandwidth to complete a crawl.
Some large-scale web robots use "farms" of robots, each a separate computer, working in tandem. Each robot is assigned a particular "slice" of URLs, for which it is responsible. Together, the robots work to crawl the Web. The individual robots may need to communicate to pass URLs back and forth, to cover for malfunctioning peers, or to otherwise coordinate their efforts.
A good reference book for implementing huge data structures is Managing Gigabytes: Compressing and Indexing Documents and Images , by Witten, et. al (Morgan Kaufmann). This book is full of tricks and techniques for managing large amounts of data.
9.1.6 Aliases and Robot Cycles
Even with the right data structures, it is sometimes difficult to tell if you have visited a page before, because of URL "aliasing." Two URLs are aliases if the URLs look different but really refer to the same resource.
Table 9-1 illustrates a few simple ways that different URLs can point to the same resource.
Table 9-1. Different URLs that alias to the same documents | |||
|
| First URL | Second URL | When aliased |
| a | http://www.foo.com/bar.html | http://www.foo.com:80/bar.html | Port is 80 by default |
| b | http://www.foo.com/~fred | http://www.foo.com/%7Ffred | %7F is same as ~ |
| c | http://www.foo.com/x.html#early | http://www.foo.com/x.html#middle | Tags don't change the page |
| d | http://www.foo.com/readme.htm | http://www.foo.com/README.HTM | Case-insensitive server |
| e | http://www.foo.com/ | http://www.foo.com/index.html | Default page is index.html |
| f | http://www.foo.com/index.html | http://209.231.87.45/index.html | www.foo.com has this IP address |
9.1.7 Canonicalizing URLs
Most web robots try to eliminate the obvious aliases up front by "canonicalizing" URLs into a standard form. A robot might first convert every URL into a canonical form, by:
1. Adding ":80" to the hostname, if the port isn't specified
2. Converting all %xx escaped characters into their character equivalents
3. Removing # tags
These steps can eliminate the aliasing problems shown in Table 9-1 a-c. But, without knowing information about the particular web server, the robot doesn't have any good way of avoiding the duplicates from Table 9-1 d-f:
The robot would need to know whether the web server was case-insensitive to avoid the alias in Table 9-1 d.
The robot would need to know the web server's index-page configuration for this directory to know whether the URLs in Table 9-1 e were aliases.
The robot would need to know if the web server was configured to do virtual hosting (covered in Chapter 5 ) to know if the URLs in Table 9-1 f were aliases, even if it knew the hostname and IP address referred to the same physical computer.
URL canonicalization can eliminate the basic syntactic aliases, but robots will encounter other URL aliases that can't be eliminated through converting URLs to standard forms.
9.1.8 Filesystem Link Cycles
Symbolic links on a filesystem can cause a particularly insidious kind of cycle, because they can create an illusion of an infinitely deep directory hierarchy where none exists. Symbolic link cycles usually are the result of an accidental mistake by the server administrator, but they also can be created by "evil webmasters" as a malicious trap for robots.
Figure 9-3 shows two filesystems. In Figure 9-3 a, subdir is a normal directory. In Figure 9-3 b, subdir is a symbolic link pointing back to / . In both figures, assume the file /index.html contains a hyperlink to the file subdir/index.html .
Figure 9-3. Symbolic link cycles
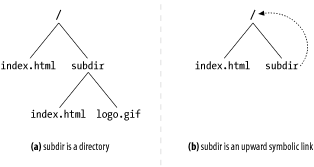
Using Figure 9-3 a's filesystem, a web crawler may take the following actions:
1. GET http://www.foo.com/index.html
Get /index.html , find link to subdir/index.html .
2. GET http://www.foo.com/subdir/index.html
Get subdir/index.html , find link to subdir/logo.gif .
3. GET http://www.foo.com/subdir/logo.gif
Get subdir/logo.gif , no more links, all done.
But in Figure 9-3 b's filesystem, the following might happen:
1. GET http://www.foo.com/index.html
Get /index.html , find link to subdir/index.html .
2. GET http://www.foo.com/subdir/index.html
Get subdir/index.html , but get back same index.html .
3. GET http://www.foo.com/subdir/subdir/index.html
Get subdir/subdir/index.html .
4. GET http://www.foo.com/subdir/subdir/subdir/index.html
Get subdir/subdir/subdir/index.html .
The problem with Figure 9-3 b is that subdir/ is a cycle back to / , but because the URLs look different, the robot doesn't know from the URL alone that the documents are identical. The unsuspecting robot runs the risk of getting into a loop. Without some kind of loop detection, this cycle will continue, often until the length of the URL exceeds the robot's or the server's limits.
9.1.9 Dynamic Virtual Web Spaces
It's possible for malicious webmasters to intentionally create sophisticated crawler loops to trap innocent, unsuspecting robots. In particular, it's easy to publish a URL that looks like a normal file but really is a gateway application. This application can whip up HTML on the fly that contains links to imaginary URLs on the same server. When these imaginary URLs are requested , the nasty server fabricates a new HTML page with new imaginary URLs.
The malicious web server can take the poor robot on an Alice-in-Wonderland journey through an infinite virtual web space, even if the web server doesn't really contain any files. Even worse , it can make it very difficult for the robot to detect the cycle, because the URLs and HTML can look very different each time. Figure 9-4 shows an example of a malicious web server generating bogus content.
Figure 9-4. Malicious dynamic web space example
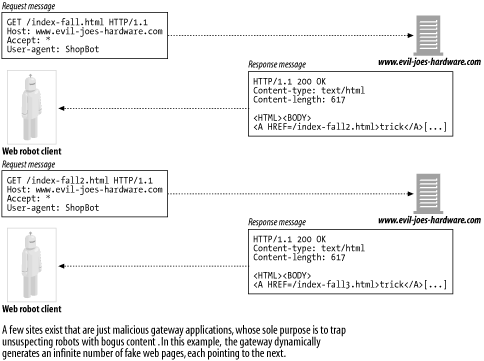
More commonly, well-intentioned webmasters may unwittingly create a crawler trap through symbolic links or dynamic content. For example, consider a CGI-based calendaring program that generates a monthly calendar and a link to the next month. A real user would not keep requesting the next -month link forever, but a robot that is unaware of the dynamic nature of the content might keep requesting these resources indefinitely. [4]
[4] This is a real example mentioned on http://www.searchtools.com/robots/robot-checklist.html for the calendaring site at http://cgi.umbc.edu/cgi-bin/WebEvent/webevent.cgi . As a result of dynamic content like this, many robots refuse to crawl pages that have the substring "cgi" anywhere in the URL.
9.1.10 Avoiding Loops and Dups
There is no foolproof way to avoid all cycles. In practice, well-designed robots need to include a set of heuristics to try to avoid cycles.
Generally, the more autonomous a crawler is (less human oversight), the more likely it is to get into trouble. There is a bit of a trade-off that robot implementors need to makethese heuristics can help avoid problems, but they also are somewhat "lossy," because you can end up skipping valid content that looks suspect.
Some techniques that robots use to behave better in a web full of robot dangers are:
Canonicalizing URLs
Avoid syntactic aliases by converting URLs into standard form.
Breadth-first crawling
Crawlers have a large set of potential URLs to crawl at any one time. By scheduling the URLs to visit in a breadth-first manner, across web sites, you can minimize the impact of cycles. Even if you hit a robot trap, you still can fetch hundreds of thousands of pages from other web sites before returning to fetch a page from the cycle. If you operate depth-first, diving head-first into a single site, you may hit a cycle and never escape to other sites. [5]
[5] Breadth-first crawling is a good idea in general, so as to more evenly disperse requests and not overwhelm any one server. This can help keep the resources that a robot uses on a server to a minimum.
Throttling [6]
Limit the number of pages the robot can fetch from a web site in a period of time. If the robot hits a cycle and continually tries to access aliases from a site, you can cap the total number of duplicates generated and the total number of accesses to the server by throttling.
Limit URL size
The robot may refuse to crawl URLs beyond a certain length (1KB is common). If a cycle causes the URL to grow in size, a length limit will eventually stop the cycle. Some web servers fail when given long URLs, and robots caught in a URL-increasing cycle can cause some web servers to crash. This may make webmasters misinterpret the robot as a denial-of-service attacker.
As a caution, this technique can certainly lead to missed content. Many sites today use URLs to help manage user state (for example, storing user IDs in the URLs referenced in a page). URL size can be a tricky way to limit a crawl; however, it can provide a great flag for a user to inspect what is happening on a particular site, by logging an error whenever requested URLs reach a certain size.
URL/site blacklist
Maintain a list of known sites and URLs that correspond to robot cycles and traps, and avoid them like the plague. As new problems are found, add them to the blacklist.
This requires human action. However, most large-scale crawlers in production today have some form of a blacklist, used to avoid certain sites because of inherent problems or something malicious in the sites. The blacklist also can be used to avoid certain sites that have made a fuss about being crawled. [7]
[7] Section 9.4 discusses how sites can avoid being crawled, but some users refuse to use this simple control mechanism and become quite irate when their sites are crawled.
Pattern detection
Cycles caused by filesystem symlinks and similar misconfigurations tend to follow patterns; for example, the URL may grow with components duplicated . Some robots view URLs with repeating components as potential cycles and refuse to crawl URLs with more than two or three repeated components .
Not all repetition is immediate (e.g., "/subdir/subdir/subdir..."). It's possible to have cycles of period 2 or other intervals, such as "/subdir/images/subdir/images/subdir/images/...". Some robots look for repeating patterns of a few different periods.
Content fingerprinting
Fingerprinting is a more direct way of detecting duplicates that is used by some of the more sophisticated web crawlers. Robots using content fingerprinting take the bytes in the content of the page and compute a checksum . This checksum is a compact representation of the content of the page. If a robot ever fetches a page whose checksum it has seen before, the page's links are not crawledif the robot has seen the page's content before, it has already initiated the crawling of the page's links.
The checksum function must be chosen so that the odds of two different pages having the same checksum are small. Message digest functions such as MD5 are popular for fingerprinting.
Because some web servers dynamically modify pages on the fly, robots sometimes omit certain parts of the web page content, such as embedded links, from the checksum calculation. Still, dynamic server-side includes that customize arbitrary page content (adding dates, access counters, etc.) may prevent duplicate detection.
Human monitoring
The Web is a wild place. Your brave robot eventually will stumble into a problem that none of your techniques will catch. All production-quality robots must be designed with diagnostics and logging, so human beings can easily monitor the robot's progress and be warned quickly if something unusual is happening. In some cases, angry net citizens will highlight the problem for you by sending you nasty email.
Good spider heuristics for crawling datasets as vast as the Web are always works in progress. Rules are built over time and adapted as new types of resources are added to the Web. Good rules are always evolving.
Many smaller, more customized crawlers skirt some of these issues, as the resources (servers, network bandwidth, etc.) that are impacted by an errant crawler are manageable, or possibly even are under the control of the person performing the crawl (such as on an intranet site). These crawlers rely on more human monitoring to prevent problems.
EAN: 2147483647
Pages: 294