Serviceguard
| Serviceguard is actually a whole suite of products. However, they are all based on the standard Serviceguard high-availability product. The Extended Campus Cluster, Metrocluster, and Continentalcluster products are actually utilities on top of Serviceguard that allow you to expand the distances between the nodes in a cluster or connect multiple clusters. Key BenefitsServiceguard products are high availability. As such, they focus on reducing the amount of downtime taken from a failure of one type or another. The key benefits include:
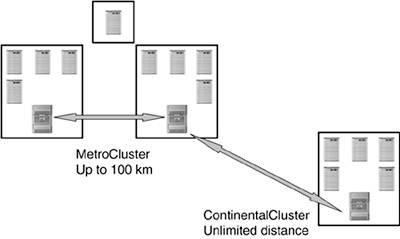
The most obvious benefit of using one or more of the Serviceguard products is they can maximize uptime by dramatically reducing the amount of downtime you take from an unexpected failure. This is because you have automation that will detect a failure and start migrating the workload in as little as five seconds. There is no way you could do this manually. In addition, a major design principle of these products is ensuring data integrity. A great deal of effort has gone into building features that will ensure that failures will not lead to data corruption. The second benefit has been available all along, but has recently become more interesting to customers. This is the fact that you can use the Serviceguard product to proactively migrate applications in response to performance issues or resource contention. The third benefit is one that people sometimes don't consider, but we find that most customers just love it. This is the ability to manually migrate an application over to a failover node so that the application can remain running while the primary system is down for maintenance. This effectively reduces the downtime for maintenance windows from hours to minutes. The last benefit is that these products can work for system failures, application failures, natural disasters, and human errors. The last of these is the most common. System failures are handled by the standard Serviceguard heartbeat mechanisms. If a node stops talking to the cluster, it will automatically be taken out of the cluster and its packages will be started on an alternate server. You can also implement application monitors that watch for process failures. You can even create application monitors that run dummy transactions into the application to verify that it is responding. If any of these monitors detect that the application is not working correctly, a failover will be initiated to bring the application back on line. For natural disasters, you can implement Metroclusters or Continentalclusters. These will guard against different levels of disaster. The Metrocluster will guard against most localized disasters, such as weather, power outages, or even terrorist attacks. If you have truly mission-critical applications that must be brought back on line quickly even in the event of a catastrophic failure, you can use Continentalclusters to spread the cluster out to unlimited distances. This would cover you for disasters that take out whole citiesthings like hurricanes or the U.S. East Coast power outage that occurred in 2003. Key TradeoffsThere are a few tradeoffs of high availability in general. These include:
The first is the most significant one, of course. True high availability requires redundant hardware on each system, redundant network and storage infrastructure, and extra systems to take over in case there are multiple failures in any of these areas and the applications need to be failed over to a redundant server. All of this adds cost over and above what would be required to run the application in a non-high-availability environment. In addition, the cost escalates quickly with the need for more availability as you approach disaster tolerance. The data-replication hardware, software, and network infrastructure will add to those costs. We will discuss below the key question of "How much high availability is enough" when we discuss the sweet-spot configurations for high-availability and disaster-tolerant clusters. About 40% of the failures in production environments are related to failures in the application software itself. Some software failures are very easy to detect in a generic fashion. A simple example is where the software processes fail to run. However, most software failures don't result in the processes stopping. Application hangs or memory leaks are examples that would not be obvious from outside the application. Detection of these types of problems requires that you provide a way to monitor the application. A number of high-availability reference architectures and toolkits provide this type of monitoring for major ISV applications. Most customers will also have custom applications. The key here is that you will want to have application monitors for any applications that you consider mission-critical. A good example of a monitor would be a process that periodically runs a dummy query transaction into the application to verify that it is responding to requests. The last item above is the fact that to provide true high availability, you will want to create a hardware and software infrastructure with lots of redundancy. The goal is to remove all single points of failure at every level of the architecture. This means providing dual network interfaces, each connected to a separate network. You will want dual I/O cards, connected to separate storage area network infrastructures. These types of precautions ensure that a single card failure will not have an impact on the availability of the applications. It would actually take multiple failures of the same type to require Serviceguard to rehost the application. For example, both network cards would have to fail on a node before a failover would be required. This is a very nice high-availability feature, but, as we mentioned above, it has a cost. In addition, you will need to provide a failover environment capable of hosting the applications. The failover environment will need to have sufficient resources to satisfy the load on the production application when a failover occurs. In these days of trying to increase the utilization of our production environments, this requires that we have significant amounts of spare capacity laying around waiting for a failover to occur. We described in Part 2 of this book how to use Utility Pricing solutions to provide spare capacity for these environments but still allow you to increase your utilization. Sweet SpotsThe key question for Serviceguard is this: How much high availability are you willing to pay for? The cost of redundant hardware and software can be significant. However, if you focus on a few of these key sweet-spot configurations, you can get a great deal of high availability for a reasonable cost. The first sweet spot is also one of the most common Serviceguard configurations, a two-node active-active cluster. In this configuration, you have two nodes running normal application loads and each workload is configured to fail over to the other server. The fact that both nodes are running applications means that you would need to have the two servers whether you do the high availability or not. Therefore, the added cost of making this high availability is relatively small. You would need to set up redundant links to network and I/O, and you would probably want to provision more resources for the cases when both workloads need to run on the same system. You should consider Instant Capacity for the excess resource requirements. Sweet Spot #1: Serviceguard In a Two-Node Active-Active Cluster The incremental cost for high availability when configuring two existing nodes in an active-active cluster is relatively low. Another thing to consider is whether you are willing to accept a performance impact on your production applications when there is a failure situation. Since most systems run at a low level of utilization most of the time anyway, you may be able to rely on the available resources on the target systems to handle the new workload without a significant performance impact. However, if this is not acceptable, a nice sweet spot configuration is the rolling failover cluster. This is where you have four or five systems in a cluster where one of them is always idle. When a failure occurs on any of the other systems, the workloads running there can fail over onto the idle system and there will be no performance impact on any of the workloads. The only time you would have a potential for a performance impact would be when multiple systems or workloads failed at the same time. Two things to consider here are that this should happen very rarely and that if you use workload management the available resources on all the other nodes in the cluster should be sufficient to minimize the performance impact. Another thing to consider is that multiple failures at the same time may constitute a disaster and you may want to fail over to the disaster-tolerance site if you have one. Sweet Spot #2: Serviceguard Allows You to Create n+1 Clusters to Minimize the Performance Impact of a Failover An n+1 cluster is a low-cost solution that would ensure that there is no performance impact unless you have multiple failures at the same time. In the third sweet spot, if you have multiple datacenters in the same city, using Metrocluster will reduce the likelihood that a localized major failure, such as a power outage or fire, will take down your entire cluster. This requires that you use SAN storage and utilize the storage array's data replication, but you should probably be doing that anyway. Sweet Spot #3: Metrocluster Provides a Reasonable Cost Disaster-Tolerance Solution Metrocluster can provide disaster tolerance for all but the most significant of disasters. For your truly mission-critical workloads, you should take advantage of Continentalcluster also. This allows you to run two separate clusters in different parts of the country or different countries and allow one of the clusters to take over for the other in the case where most or all of a datacenter is taken out for whatever reason. The additional cost of this could be minimized by running other workloads on the systems in the disaster-tolerance site. The development or test workloads could be shut down or, if you have workload management, their resources could be minimized upon a failover. Sweet Spot #4: Continentalcluster Handles Truly Mission-Critical Workloads If a major disaster that took out an entire cluster would open the company up to a risk of going out of business, it's just not worth the risk. You can reduce the cost here by picking only truly mission-critical workloads and by running development or test workloads on your disaster-tolerance systems during normal operations. Putting these last three sweet spots together, you get a configuration like that in Figure 14-1. Figure 14-1. Combining Metrocluster and Continentalcluster
In this configuration you have a three-datacenter Metrocluster with at least two sites in different suburbs of the same city. Should a serious disaster take out both of these sites, Continentalcluster will allow the mission-critical production workloads from this cluster to fail over to a disaster-tolerance site in a different city. Also, we could configure the Metrocluster as an n+1 cluster at each of the primary sites and the disaster-tolerance site as an n+2 cluster to minimize any potential performance impacts of either of these failovers. This configuration would provide us with the following benefits:
Tips You should test your high-availability or disaster-tolerance solution at least monthly. It would be a shame to go to the expense and trouble of setting up a high-availability or disaster-tolerant configuration only to have it fail when you finally need it. One way to do this would be to schedule routine maintenance on each of your systems once a month and activate the failover before you do it. This will ensure that the workload will successfully make it over to the failover node and backand it will also give you a convenient maintenance window for doing hardware or software maintenance each month. This will also minimize your downtime during the maintenance windows because you can do this maintenance while the production workload is running on the failover node. Serviceguard has a feature called Service Management. This was originally intended to be used to monitor the normal running of the application processes and other services required by the application on the system. If those processes exit, the service manager will attempt to restart themif that fails, it will failover the package. This feature can also be used to provide a way for you to control the failover of a package. You simply create a script or process that monitors the status of the workload and exits if the workload is having problemsany problem that you want to test for. This can be whether the performance of the workload is acceptable, whether there is access to some other system or resource that is required by the workload, or even whether the workload is responding to a synthetic request you send it. When this monitor exits, Serviceguard will initiate a failover of the package to the failover node. |
EAN: 2147483647
Pages: 197