Hack 33 Detective Case Study: Newgrounds
Hack 33 Detective Case Study: Newgrounds Learn how to gumshoe your way through a site's workflow, regardless of whether there are pop-up windows , JavaScripts, frames , or other bits of obscuring technology . In this hack, we're going to create a script to suck down the media files of Newgrounds (http://newgrounds.com), a site that specializes in odd Flash animations and similar videos . Before we can get to the code, we have to do a little bit of sleuthing to see how Newgrounds handles its operation. Anytime we prepare to suck data from a site, especially one that isn't just plain old static pages, the first thing we should keep in mind is the URL. Even though we don't have a manual to the coding prowess that went into the design, we really don't need one; we just need to pay attention, make some guesses, and get enough of what we need to script away. With Newgrounds, the first thing we need to do is find the page from which we'd normally view or download the animation through a regular browser. We'll pick a random item from the main page and check out the URL: http://newgrounds.com/portal/view.php?id=66766. You'll notice immediately the id= at the end, which tells us that files are identified as unique records [Hack #7]. That's a good, if minimal, first step. But what else can we learn from this? Well, let's start URL hacking. Instead of clicking anything else on the current web page, let's change the URL. Set the id= to 66767 or 66765 , or 1 , 2 , 3 , and so on. Do we get valid responses? In this case, yes, we do. We've now learned that IDs are sequential. It's time to return to our original web page and see what else we can find. The next thing we notice is, regardless of whether the media file is a game or movie, there's a shiny Go button for every ID. The Go button is our step in the next direction. Hovering our mouse over it, we can see OpenPortalContentWin(66766, 400, 600) for our destination: the site uses JavaScript, and passes the ID to the OpenPortalContentWin function. What of those other numbers? Without investigating, we don't yet know what they are, but we can certainly make a guess: they're probably window dimensions. 600 x 400 would fit within the smallest screen resolution (640 x 480), so it's a safe bet to expect a window of roughly that size when we click the link. Do so now. Up pops a new window, a little smaller than we expected, but well within our guess. Because we are more interested in downloads than window dimensions, we can ignore those final two numbers ; they're not important. While you were reading the preceding paragraph, the Flash animation was loading in that 600 x 400 pop up. Let's use our browser's View Source feature on this new pop-up window. If the file we want is loading, then the location from which it's loading must be in the HTML code. Remember: if the browser is showing the page, it has the HTML source; it's just a matter of finding a way to show it. In the HTML, we see the following: <EMBED src=" http://uploads.newgrounds.com/66000/66766_ganguro.swf " quality="high" WIDTH="600" HEIGHT="400" NAME="FlashContent" AllowScriptAccess="never" TYPE="application/x-shockwave-flash" PLUGINSPAGE="http://www.macromedia.com/go/getflashplayer"> </EMBED> And with barely a whimper, we're done: there's the location of the file we want to download. We know a few new things as a result of examining the source:
But the clincher is how many of these things we don't really need to know. If we know that all files must be served from http://uploads.newgrounds.com/, then we should be able to write a script that just looks for that string in the pop-up URL's source code, and we'll be ready to download. But how do we find the URL for the pop-up window, especially when it was triggered by a bit of JavaScript, not a normal HTML link? If you're using Mozilla, choose Page Info (see Figure 3-1) from either the View or contextual menus . Figure 3-1. Mozilla's Page Info with our pop-up URL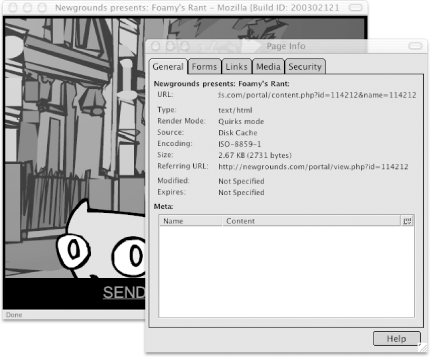 Alternatively, if your browser allows you to turn on toolbars that have been explicitly turned off, turn on the Address Bar (Safari on OS X: View
Suddenly, things aren't so easy anymore. The pop-up URL uses the ID, as we expected, but it also requires two more values: date and quality . After experimenting with changing the quality setting on various Newgrounds URLs: http://newgrounds.com/portal/content.php?id=99362&date=1054526400 &quality=a http://newgrounds.com/portal/content.php?id=99362&date=1054526400 &quality=c http://newgrounds.com/portal/content.php?id=99362&date=1054526400 &quality=1 I've yet to see it make much of a difference, so we'll safely ignore that for now. What's worrisome, however, is the date . Obviously, it's going to change from day to day, and it may even change from second to second. All we know is that if we decrease the date value arbitrarily (to 1054440000 , for instance), we don't get the content we want. In poking around and trying different IDs, we notice the date hasn't changed for the past five minutes. Experimentation-wise, this doesn't help us: making the date larger or smaller has only one effectmore error messages. We're going to have to get the date from the server each time we run our script, and then use that for downloading. It's not that big of a deal, but it's annoying nonetheless. The CodeSave the following code to a file called leechgrounds.pl : #!/usr/bin/perl -w # # LeechGrounds - saves flash files from Newgrounds.com. # Part of the Leecharoo suite - for all those hard to leech places. # http://disobey.com/d/code/ or contact morbus@disobey.com. # # This code is free software; you can redistribute it and/or # modify it under the same terms as Perl itself. # use strict; $++; my $VERSION = "1.0"; use File::Spec::Functions; # make sure we have the modules we need, else die peacefully. eval("use LWP 5.6.9;"); die "[err] LWP 5.6.9 or greater required.\n" if $@; # our download URLs are found in this URL (which'll # be tweaked with the date and ID we care about). my $base_url = "http://newgrounds.com/portal/content.php"; my $dir = "newgrounds"; # save downloads to...? mkdir $dir; # make sure that dir exists. my $date; # date from newgrounds server. # create a final hash that contains # all the IDs we'll be downloading. my %ids; foreach (@ARGV) { next unless /\d/; # numbers only. # if it's a range, work through it. if (/(\d+)-(\d+)/) { my $start = ; my $end = ; for (my $i = $start; $i <= $end; $i++) { $ids{$i} = undef; # alive, alive! } } else { $ids{$_} = undef; } # normal number. } # create a downloader, faking the User-Agent to get past filters. my $ua = LWP::UserAgent->new(agent => 'Mozilla/4.76 [en] (Win98; U)'); # now that we have a list of IDs we want to # download, get the date value from first page. # we'll use this to get the final download URLs. print "-" x 76, "\n"; # pretty visual seperator. foreach my $id (sort {$a <=> $b} keys %ids) { # get the date first time through. unless ($date) { print "Trying to grab a date string from $id... "; my $response = [RETURN] $ua->get("http://newgrounds.com/portal/view.php?id=$id"); my $data = $response->content; $data =~ /&date=(\d+)&quality=b/; unless () { print "bah!\n"; next; } print "yes!\n"; $date = ; # store the date for later use. } # now, we can get the download URL to our Flash file. # note that we get ALL the download URLs before we # actually download. this saves us from having to # error check when we're out-of-date on long downloads. print "Determining download URL for $id... "; my $response = $ua->get("$base_url?id=$id&date=$date"); my $data = $response->content; # our content. $data =~ /uploads.newgrounds.com\/(.*swf)/; $ids{$id} = "http://uploads.newgrounds.com/"; print "done!\n"; } print "-" x 76, "\n"; # pretty! # if we're here, we have our URLs to download in # our hash, so we just run through the basics now. foreach my $id (sort {$a <=> $b} keys %ids) { # only work on IDs with URLs. next unless defined ($ids{$id}); # get URL/filename. my $url = $ids{$id}; $url =~ /([^\/]*.swf)/; my $filename = ; print "Downloading $filename... "; # and use :content_file to autosave to our directory. $ua->get($url, ':content_file' => "$dir/$filename"); print "done!\n"; # easier said than don... oh, nevermind. } Running the HackInvoke the script on the command line, passing it the IDs of Flash files to download. Specify either a space-separated list of individual IDs (e.g., perl leechgrounds.pl 67355 67354 ) or space-separated list of ranges (e.g., perl leechgrounds.pl 1-100 67455-67560 615 to download files 1 through 100, 615, and 67455 through 67560). Here, I download four Flash movies: % perl leechgrounds.pl 80376 79461 66767 66765 ----------------------------------------------------------------------- Trying to grab a date string from 66765... bah! Trying to grab a date string from 66767... bah! Trying to grab a date string from 79461... yes! Determining download URL for 79461... done! Determining download URL for 80376... done! ----------------------------------------------------------------------- Downloading 79461_011_Maid_Of_Horror.swf... done! ... etc ... If you read through the code, you'll notice that we get a list of all the download URLs immediately, as opposed to getting one final URL, then downloading, moving on to the next, and so on. By preprocessing the ID list like this, we never have to worry about the date (from the pop-up URLs) expiring, since the final downloadable URLs (from uploads.newgrounds.com) aren't limited by any date restriction. Likewise, if we can't determine a URL for the final download, we skip it under the assumption that the data has been removed from the server. Hacking the HackWe can always do better, of course. For one, we have no pretty progress bar [Hack #18], nor any checks for whether a file has already been downloaded. We also falsely assume that Newgrounds files are always .swf , which may not always be the case (though we've yet to find an exception). Finally, we don't capture any information about the file itself, such as the name, author, description, and so on. To get you started, modify the script like this: unless ($date) { # remove this line . print "Trying to grab a date string from $id... "; my $response = $ua->get("http://newgrounds.com/portal/view.php?id=$id"); my $data = $response->content; $data =~ /&date=(\d+)&quality=b/; unless () { print "bah!\n"; next; } print "yes!\n"; $date = ; # store the date for later use. # new lines for grabbing content . if ($data =~ /Presents: (.*?)<\/title>/) { print " Name: \n" if ; } if ($data =~ /Email\('.*?', '.*?', '(.*?)'\)/) { print " Author: \n" if ; } } # remove this line. |
 Address Bar) and take a look. You'll see something similar to:
Address Bar) and take a look. You'll see something similar to: EAN: 2147483647
Pages: 157