Prevention
|
| < Day Day Up > |
|
Preventing poor documentation is about discipline and having the correct set of tools and practices. The discipline is up to you, but here we can cover the techniques and tools that can make proper documentation easier to accomplish.
Too Little vs. Too Much
Before we discuss documentation techniques in detail, it is important to confront a common explanation that is given by programmers suffering from Docuphobia. They will claim that too many comments make the code confusing and more difficult to read. Therefore, they feel justified in providing very little documentation. In truth, providing excessive documentation is not optimal, but it is better than providing no documentation. Although the extra documentation requires extra time to wade through, it will often offer information that is inaccessible from the code alone. If there was no documentation, there might be no recourse for discovering the needed information. The best approach to documentation is to aim for the same goal as code design: minimal and complete. However, in cases of doubt it is better to err on the side of completeness.
Document in the Code
The majority of the documentation should be written with the code to which it is associated. This provides a locality of reference that makes it easy to find and easy to maintain. This removes a common barrier to proper documentation, which is the natural aversion to interrupt the workflow to find and fill in documentation located in some other location. There are two main approaches to documenting within the code, and you might hear many arguments about the benefits of one approach over another. Perhaps the best approach is a combination of the two approaches. Let us look at each of these approaches and discuss how they can be used together.
Self-Documenting Code
An integral approach to code documentation is to write the code so that it documents itself. In other words, the code should be naturally readable in such a way as to make it easy to understand. This is accomplished by proper naming conventions and statement formatting. The advantages of this are clear, since the code must be written anyway; it is only a minute amount of extra work to make it more readable.
For example, take this Java class:
class Bomb { Bomb(int ticksLeftToDetonation) { this.ticksLeftToDetonation = ticksLeftToDetonation; } boolean updateTime(int ticks) { assert(ticks > 0); if(isTriggered()) { explode(); } else { countdown(ticks); } return isTriggered(); } private boolean isTriggered() { return(ticksLeftToDetonation <= 0); } private void explode() { System.out.println("BOOM!"); } private void countdown(int ticks) { ticksLeftToDetonation -= ticks; } private int ticksLeftToDetonation; } In particular, let us focus on the updateTime method. First, notice that the name of the method tells us that we are going to be updating the time. Next, the name of the argument, ticks, gives us an indication that we are providing the number of ticks that we want to add to the time. We could have made this clearer, such as ticksToAdd, but since the meaning was relatively clear without the extra wording, we chose not to make the name longer.
Next, we have the assert call, which makes it evident that we expect ticks to be greater than 0. This is a language feature for checking that the state of the program is as expected. This type of functionality might be removed from the final release build for performance reasons, but in the meantime, it provides another means of detecting problems early. It also provides information to programmers reading the code about the expectation the writer had about the state of the application and any inputs and outputs. This type of language feature is available in many languages, some of which have more than one variation to further improve the self-documenting nature of the language.
Now we want to know if the bomb is triggered, which can be easily understood from the statement if(isTriggered()). This could be made slightly clearer by actually providing the implicit this variable, but since almost all programmers understand that it is implied, it can be seen as redundant. Thus, if(this.isTriggered()) is slightly clearer, but not enough to warrant the extra characters. Additionally, it might cause some programmers to think there is a reason for the distinction when there is none. Leaving this out avoids this misleading idea. Finally, the function names explode and countdown are made to be straightforward indications of what to expect from these function calls. The function explode causes the object to explode, in the example we simply print BOOM!, and the function countdown advances the bomb’s countdown timer.
Self-documenting code is useful for understanding the implementation as it is written, but it cannot help if the implementation is not available for perusal. This requires separate documentation that describes the usage of the functionality without providing implementation details. This limits the use of self-documenting code to the names available in the interface to the functionality. In most cases, this is insufficient, but we can still keep the documentation as close to the code as possible by putting in the comments. Later, the documentation can be automatically extracted into a different form if necessary.
Comments
While self-documenting code should be the goal when writing the code itself, it cannot provide all the information necessary to understand the code. This is where code comments, which do not affect the final application, come in. Comments are particularly important for answering the question of why. They are also useful for clarifying the implementation of sections of code that cannot be made self-documenting due to the constraints of the language.
CD-ROM The following is an excerpt from a handle manager class used to generate unique handles for associating with data pointers. This code, available in full on the companion CD-ROM in Source/Examples/Chapter6/why.h, shows several examples of comments that explain why a particular code statement was written:
// Desc: Handle manager for a particular class. // Input: t_Type - Type of object for which the // handles are associated. template <typename t_Type> class t_HandleManager { public: // Desc: Initialize manager. // Notes: The unique identifier is // initialized to one and // incremented by two in order // to ensure zero is never a // valid unique ID. t_HandleManager() : m_nextUniqueID(1), m_freeIndex(0) {} // Desc: Create a new handle and // associate it with a pointer. // Input: i_instance - Pointer to object // instance that handle will // represent. // Output:Unique handle that represents // the provided pointer. // Notes: This manager does not prevent // two handles from representing // the same pointer. If this is // the case make sure that all // handles associated with the // object are destroyed when the // object is deleted. t_Handle m_Create(t_Type *i_instance) { if(!i_instance) { // A handle with a unique ID of // zero is always invalid. return(t_Handle(0, 0)); } // Make a local copy of the // current free index so the stored // free index can be updated. unsigned int l_freeIndex = m_freeIndex; if(l_freeIndex >= m_handles.size()) { m_handles.resize(l_freeIndex + 1); } // If the free index points to // a handle that has a valid index // then the stored index should // be set to that index. This // happens because handle destruction // fills in this field when // if cleans out the handle. if(unsigned int l_nextFreeIndex = m_handles[l_freeIndex ].m_GetHandle().m_GetIndex()) { m_freeIndex = l_nextFreeIndex; } else { ++m_freeIndex; } m_handles[l_freeIndex] = t_HandleInstance<t_Type>( l_freeIndex, m_nextUniqueID, i_instance); // Increment the unique identifier // by two, since it is initialized // to one it will never be zero even // if it wraps around. While this // does not guarantee an absolutely // unique identifier, the chances // are miniscule that both index and // identifier will be duplicated // in any reasonable amount of time. m_nextUniqueID += 2; return(m_handles[l_freeIndex ].m_GetHandle()); } // ... } There are several comments in this code snippet that explain why a particular approach was used, and several other lines are not commented because they are relatively easy to determine their purpose. For example, when we add two to obtain the next unique identifier it is not immediately obvious why two is important. If this were not commented on, another programmer might change the two to a one. This would violate the expectations of the class and could cause strange errors to occur. Therefore, we point out that the use of two eliminates zero as a valid identifier assuming the first unique identifier is one. This important assumption is also stated when the first unique identifier is initialized to prevent another programmer from changing that value and once again breaking the assumptions that the class makes. This line of reasoning also applies to the comment about creating an invalid identifier. This is a case, however, where the code could be made self-documenting by create a static instance of an invalid identifier in the handle class and giving it the name INVALID_HANDLE.
Also, notice that simpler operations, such as creating and returning the handle, are not commented. There is little reason to comment these lines of code because they are straightforward, and other programmers can be expected to change or maintain them without much risk of causing problems elsewhere. Another example of such a straightforward line of code is the incrementing of the free index. While it is better to comment too much than too little, striving to achieve the optimal balance should be a continuing effort that will make the code clearer and the important comments more evident.
Another important use of comments is to preserve encapsulation and abstraction. This might sound odd knowing that comments do not affect the language usage directly. However, without comments there would be no way for the end user of an interface to know what functionality there is and what the proper inputs are without examining the implementation. By examining the implementation, the interface’s user can easily produce too tight of a coupling to the implementation details. This makes future changes to the implementation difficult. While some of the usage information can be transferred with good naming conventions, it is not possible to present a sufficient amount of information in that form. Therefore, the interface must be documented with comments for it to be used properly.
For example, here is the interface to a configuration class designed to read a configuration file and provide simple configuration querying:
/** Stores configuration file information * for later retrieval. */ class configuration { public: /** * Read the configuration file and * store information in class. * * @param i_filename name of * configuration file. */ explicit configuration( const std::string &i_filename); /** * Check if a named configuration value * exists in this configuration. * * @param i_name name to lookup. * @return true if name is in configuration, * false if it does not exist. */ bool has(const std::string &i_name) const; /** * Retrieve named configuration value * from this configuration. * * @param i_name name to lookup. * @return Copy of string value * associated with name, * or empty string if named * value does not exist in * this configuration. */ const string find( const std::string &i_name) const; }; CD-ROM This code is also available on the companion CD-ROM in Source/Examples/Chapter6/interface.h. If you read the description of the constructor and two methods for this class, you should notice that no implementation details are provided. This allows hiding of the implementation so that future changes can be made without worrying that existing code will break because of its reliance on the internal implementation. The documentation does provide the necessary information to pass correct information into the methods and to interpret the information that is received back from some of the methods. This eliminates the need for the user of the class to look at the implementation even if it is provided, and gives the developer the option to provide only the interface and binary libraries for the implementation.
Coding Standards
A set of coding standards, which include rules on documentation, can assist in both self-documenting code and proper commenting. With a set of rules to follow, it is easier to maintain the necessary discipline for good commenting. It also provides a consistency in the code and documentation that makes it easier to read and search.
For example, the following are some rules that would be beneficial to have in the coding standards for a project:
-
All public documentation must be formatted according to the JavaDoc specification.
-
All publicly accessible member functions, including those accessible to derived classes, must have their declaration fully documented.
-
Do not provide implementation details in the documentation except when it directly affects the use of the function.
-
All private member functions should be documented as completely as possible.
-
All argument constraints must be provided in the function’s documentation.
-
All side effects must be documented as a warning.
-
Any exceptions thrown by the function should be documented to the best of the developer’s knowledge.
This example represents a portion of the rules that could be provided as part of a coding standard. Since it is important that the programmer remember and continue to use these rules, the list should not be made excessively long. Only the rules for common occurrences should be presented here; rules for less common situations can be discussed and decided upon in code reviews and personal correspondences.
Avoiding Duplication
Duplicating information for the purposes of documentation is both tedious and error prone. It also leads to difficulties in maintaining the documentation. This can be demoralizing to the point of discouraging the programmer from writing any documentation. As we will discuss shortly, the majority of this duplication is unnecessary with the modern tools available.
CD-ROM For example, suppose you have the following Java function, also found on the companion CD-ROM in Source/JavaExamples/com/crm/ppt/examples/chapter6/DuplicationExample.java.
/** * public float computeAverage(float values[]); * * Compute the average of an array of values. * * @param values array of float values that * must not be null or zero length * @return floating point sum of values * divided by length */ public float computeAverage(float values[]) { // Set sum to zero. float sum = 0.0f; // Start at index zero and increment // it by one until the index is not // less than the length of the // values array. for(int index = 0; index < values.length; ++index) { // Add the value at the current index // to the sum. sum += values[index]; } // Return the sum divided by the length // of the values array. return(sum / values.length); } First, notice that the function name and signature are repeated in the interface documentation comment. Perhaps this was done automatically by a template created for your editor, or maybe you used cut-and-paste to copy the code line into the comment. Either way, this is not a good practice to follow. If another programmer comes along to change the function, he must also modify the comment. This is tedious and error prone, often leading to just ignoring the comment update and thus making the resulting documentation incorrect.
Notice also the commenting within the body of the function. These comments are only saying what is happening, which can already be easily deduced from the code. If even an operator is changed, the comment must also be updated or become incorrect. This can become really confusing during debugging as the programmer attempting to correct the code cannot determine if the original programmer meant to perform the operation in the code or the operation in the comment.
Instead of this redundant commenting, what the commenting should look like is:
/** Compute the average of an array of values. */ public float /** Average. */ computeAverage_( float values[] /** Must not be null or zero length. */ ) { float sum = 0.0f; for(int index = 0; index < values.length; ++index) { sum += values[index]; } return (sum / values.length); } You can see here that the code is used as part of the documentation, particularly the variable names. Maintaining a style of commenting that uses the code as part of the documentation reduces ambiguity and maintenance errors, as well as saving the redundant cut-and-paste or typing of the information the first time around. Unfortunately, the tools currently available do not support this style if you want to generate external documentation from the code and comments. There is still a need to repeat the argument names in the interface comments. However, much of the documentation can be derived directly from the code itself and paired with the comments to form complete external documentation with the help of a documentation generator. This means that with modern tools you can lean more toward the second style of commenting than the first.
Automation
Several steps in the documentation process should be automated. In fact, you should strive to automate as much of it as possible to encourage proper documentation, and focus the effort on the portion that cannot be automated because the information only exists in the programmer’s mind.
First, automate the extraction of documentation from the comments contained within the code. The majority of languages have one or more applications that can accomplish this task. For example, Java has JavaDoc as a standard documentation tool, and the freely available Doxygen serves a similar purpose for C++. Both of these, along with many of the freely available tools, require the comments to follow a format for documentation to be extracted. If you have a large code base that is not commented in any of these styles, there are commercially available applications that can still extract decent documentation from the existing comments.
The true benefit of these applications is their understanding of the language that is being documented. This allows the generator to create browsing and search information not only based on the comments but also on the structure of the code itself. Most of these tools also offer several different output forms, among which HTML is the most useful (Figure 6.1). By adding the documentation generation to your build process, the resulting documentation can be placed on a server accessible to the team and updated with every build. This gives each member of the team ready access to the documentation through a Web browser that is available on almost every computer these days.
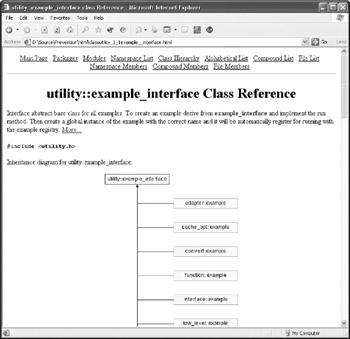
Figure 6.1: Example of HTML documentation generated by Doxygen from the code and associated comments.
Another automation step that should be added to the build is documentation error checking. While the conceptual aspect of the documentation cannot be verified, semantic errors such as misnamed or missing parameters can be checked. The resulting list of errors should be added to the available documentation and, if possible, mailed to the code owner for timely correction.
On a more individual level, automating the process of writing the comments that will form the documentation can be done with most modern editors. Some of them contain a certain built-in amount of knowledge for creating comments associated with language constructs. Whether or not this functionality exists in your editor of choice, you can still take advantage of code creation features and auto-completion to create your own shortcuts for generating the structure of the documentation comments. This leaves you with only the unique information to fill in for each new comment.
Maintenance
For the documentation to be useful, it must be correct. A common failing is for the documentation to be correct at the beginning of the project when the code is first written, only to degrade as functionality is changed and refactored without the necessary updates to the documentation. With every code change, you must check the corresponding documentation to determine if it requires updating. If so, it must be done immediately to avoid the problems of out-of-sync code and documentation. This is where providing the majority of your documentation within the code itself helps tremendously. With the documentation close by, it is much more likely to be updated to maintain consistency than if another application must be launched and more files searched.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 121