The Data Flow Task, Adapters, and Transforms
| The Data Flow Task is arguably the most important task in the IS box. It is the task you'll use for virtually all data processing in IS. Because data comes in many forms and can be quite complex, the Data Flow Task reflects that complexity. Although most tasks are fairly flat, meaning they are simple objects with simple properties, the Data Flow Task has its own object model, or collection of objects. You can even write custom components that plug in to the Data Flow Task. Data comes in different forms and is found on different media. The problem we face when trying to use that data is how to get it all into some common format and a common location so we can manipulate it. The Data Flow Task addresses these problems. By providing what are called adapters, it addresses the problem of how to access data on various types of media. The other problem, the common location problem, is addressed with buffers. Buffers are memory locations that hold data as it moves through the Data Flow Task. The shape of the buffer is described in the buffer metadata definition and reflects the data that flows out of adapters and transforms. Figure 6.2 shows a conceptual view of these different components and their relationships to each other. Figure 6.2. The Data Flow Task has an object model with adapters and transforms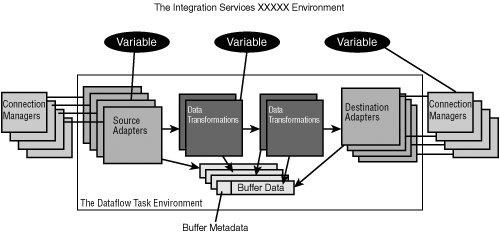 Data Flow AdaptersAdapters perform the following three functions:
Communicating with Connection ManagersThis function is rather vague because the relationship is different for different adapters. For example, the OLEDB Source Adapter uses OLEDB connection managers in a way that you'd expect. It calls the AcquireConnection method on the OLEDB connection manager and the connection manager returns an OLEDB connection object. The flat-file adapter uses connections in a different way, however. When it calls the AcquireConnection method on the Flat File Connection Manager, it gets a string containing the fully qualified filename of the flat file. The Flat File Connection Manager also does some additional work. It discovers the types and lengths of the columns in the flat file. It's factored this way because other components that need to access flat files also need that column information. If the function to discover flat-file column types and lengths was in the Flat File Source Adapter, other objects that use the Flat File Connection Manager would also have to include the same code. Factoring the functionality to the various roles helps eliminate duplicated functionality throughout the object model and componentry. Providing an Abstraction Between Different Data Access MechanismsEach of the transforms in a given Data Flow Task must have data passed to them that is both uniform and well described. This isn't something connection managers can provide. Connection managers don't know about the Data Flow Tasks buffers. It's too detailed and connection managers just aren't that specific to any given component. Also, connection managers don't actually retrieve data, they mostly just point to where the data can be found. For example, the Flat File Connection Manager can be used to point to XML files, binary files, or even other package files, but it doesn't provide a mechanism to actually retrieve data from those files. What's needed is a component that knows the details of the source systemand that knows how to get at the data there. This is what adapters do. They know the mechanics of accessing data in source and destination systems. Moving Data into or out of Data Flow BuffersSo, the adapter is capable of accessing the data on systems, but it must also discover the format or shape of that data and place the data in a common format for the transforms to operate on it. For source adapters, this involves discovering the format of the data on the source system and telling the Data Flow Task how the buffer should be structured to optimally hold the data. It also involves converting that data into a consistent and well-described form that the transforms can consume. Source adapters retrieve rows of data from the source system and place those rows into the buffer. For destination adapters, the process is essentially the same, but in reverse. So, adapters are the components that accomplish the function of converting data from/to the common buffer format into/from the storage or various other media formats. Data Flow TransformsTransforms, as their name implies, transform data. Each transform has a specific function, such as the Sort, Aggregate, or Lookup transforms. Each takes as input the output of another transform or adapter. Each has an output that is defined by the data that it releases. As this book moves into more detailed discussions, you'll see that there are classes of transforms that are defined by the way the data flows through them. For example, it's possible to have a transform that takes many inputs and has only one output. It's also possible to have a transform that doesn't release any data to its output until it has received all the data at its inputs. For this discussion, it's enough to understand that these transforms interact through outputs and inputs. One transform is not aware of any of the other transforms around it. It is only aware of its inputs and outputs. Here again, the components are isolated to eliminate dependencies and to create a more robust and predictable system. |
EAN: 2147483647
Pages: 200