Writing a Destination Adapter
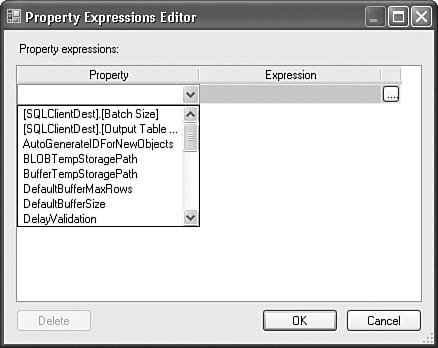
| In many ways, destination adapters are the corollary opposites of source adapters. They do everything that source adapters do, only in reverse. They convert buffer types to destination types and they extract data from the buffer and insert it into the destination medium. Many of the functions are almost identical with the exception that the direction of the operations and data movement is reversed. Therefore, the methods that are virtually identical are not covered here. With a brief look at the code, you should be able to make the short conceptual leap between writing sources and destinations. However, there are a few differences worth noting and the destination component implements error outputs. This section covers those differences. Also, this section focuses on the SQLClientDest sample solution because it contains a few more interesting elements. The differences between the SQLClientDest and the ODBCDest are minor. The Destination Adapter General ApproachAlthough the Image File Source has hard-coded component metadata, the sample destination is a little more complex and discovers the destination metadata from the destination table. This section focuses on how that is done. The ADO.NET SQL Client Destination (SQLClientDest) uses the ADO.NET SqlClient Data provider for inserting data into SQL Server data tables. Internally, the component uses two DataTable objects: one for holding the metadata for the destination table (m_metadataTable) and the other for inserting the rows from the buffer into the destination table (m_batchTable). The component first retrieves the metadata from the destination SQL Server table and then builds the batch table to match. The component also builds an INSERT statement to use for inserting the data from the buffer into the batch table. During execution, the component extracts the column data from the buffer and inserts it into the batch table. The component calls the Update method and the ADO.NET provider takes over, inserting the data from the batch table into the destination SQL Server table. The batch size, or number of rows sent at a time, is determined by the BatchSize custom property. Adding Custom PropertiesThe sample component adds a custom property for the batch size and the destination table. Figure 25.5 shows the properties in the Advanced Editor for the SQLClientDest component. Figure 25.5. Adding custom properties to the component.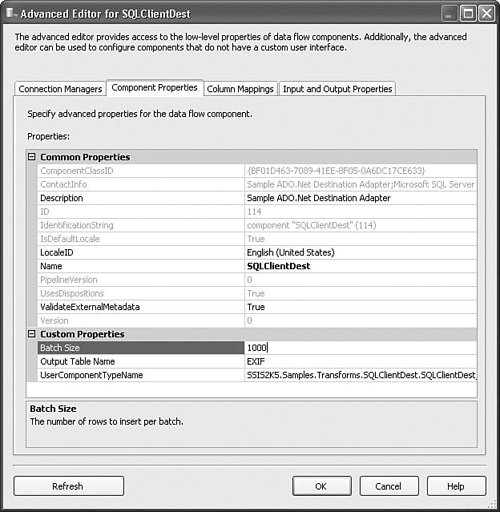 This code adds the TableName and BatchSize custom properties. // Add the TableName property and set it as expressionable IDTSCustomProperty90 propTableName = ComponentMetaData.CustomPropertyCollection.New(); propTableName.Name = TABLE_NAME; propTableName.Description = "The name of the table to insert into"; propTableName.ExpressionType = DTSCustomPropertyExpressionType.CPET_NOTIFY; // Add the batch size property and make it expressionable. IDTSCustomProperty90 propBatchSize = ComponentMetaData.CustomPropertyCollection.New(); propBatchSize.Name= BATCH_SIZE; propBatchSize.Description= "The number of rows to insert per batch."; propBatchSize.ExpressionType= DTSCustomPropertyExpressionType.CPET_NOTIFY; propBatchSize.Value= 1000; Notice also that the ExpressionType is specified. By default, the type is CPET_NONE. By setting the property ExpressionType to CPET_NOTIFY, the component has made the properties "expressionable." Figure 25.6 shows the Property Expressions Editor for a Data Flow Task containing the SQL Client Destination. Notice that the BatchSize and OutputTable properties are available. Figure 25.6. Custom properties can be made expressionable. The ReinitializeMetaData MethodMost of what you see in the ReinitializeMetaData method is similar to the Image File Source, so it isn't reviewed here. The code relating to discovering the destination table metadata, however, is interesting and generally the kind of thing that destination adapters need to do. Discovering the Destination Table MetadataFor source and destination adapters, part of the challenge is to create a mapping between the columns found on the buffer and the source or destination table. To create the mapping, one of the first things the destination must accomplish is to discover the metadata on the destination table. The SQL Client Destination uses the GetSchema method to retrieve a set of rows containing the metadata for the destination table. Each row in the rowset returned contains the information about one column in the destination table. The columns for the returned rowset have 17 columns. Table 25.2 contains the schema and indexes for the rows.
The GetSchema method discovers the catalog name from the connection manager and then builds the restrictions array to only retrieve the schema for the destination table columns. private void CreateSchemaTable(string strTableName) { try { // Create the table to hold the table metadata m_metaDataTable = new DataTable(); // Get the InitialCatalog string initialCatalog = ""; IDTSConnectionManager90 cm = GetConnectionManager(); Get the catalog name from the connection manager host properties. The ConnectionManagerHost is a host similar to the Taskhost and all connection managers have one with a properties provider containing all the property values of the connection manager. // What you really have here is a ConnectionManagerHost which implements // IDTSPropertiesProvider90 from which you can get the extended properties. if (cm is IDTSPropertiesProvider90) { IDTSPropertiesProvider90 pp = (IDTSPropertiesProvider90)cm; initialCatalog = pp.Properties["InitialCatalog"].GetValue(cm).ToString(); } Next, you specify the catalog, table name, and that you only want column schema information. // Build the restrictions. We just want to get column information for the table. string[] restrictions = new string[4] { initialCatalog, null, strTableName, null }; // Get the schema. m_metaDataTable = m_conn.GetSchema("Columns", restrictions); } } Creating the External Metadata ColumnsNow that the component has built the metadata table, it can start to create the ExternalMetaData Columns. ExternalMetaData Columns are useful for validating the component when there is no connection available, but they also are used to represent the source or destination table when creating mappings. For each row in the metadata table, there should be a new column created, as follows. The following code has been abbreviated from the source to save space. This code shows the crucial logic for converting the metadata rows to ExternalMetaData Columns. // Every row of the table describes one column // Now set up the ExternalMetadata Columns m_countMetaDataColumns = m_metaDataTable.Rows.Count; for (int iColumn = 0; iColumn < m_countMetaDataColumns; iColumn++) { // Create a new column IDTSExternalMetadataColumn90 inputcolNewMain = inputMain.ExternalMetadataColumnCollection.NewAt(iColumn); // Point to the row describing this column DataRow rowCurr = m_metaDataTable.Rows[iColumn]; // Get the name inputcolNewMain.Name = rowCurr["COLUMN_NAME"].ToString(); int CodePage = 0; TRanslateSqlTypeToDts is a special method to convert the SQL Client data types to Integration Services buffer types. // Convert the type to a pipeline type DataType dtstype = DataType.DT_EMPTY; TranslateSqlTypeToDts(rowCurr["DATA_TYPE"].ToString(), ref dtstype); Set the length and other type-related properties: // Set the length where the type does not determine the length int Length = 0; // Create input columns with the ideal type for conversion inputcolNewMain.CodePage = CodePage; inputcolNewMain.DataType = dtstype; inputcolNewMain.Length = Length; inputcolNewMain.Precision = Precision; inputcolNewMain.Scale = Scale; } The PreExecute MethodThe PreExecute method is where the batch table and INSERT statement are created and the columns are mapped. Creating the Batch TableThe batch table is the location where rows are inserted and temporarily held until the SQL Adapter sends off a batch of rows to the destination. The logic for creating the batch table is found in the CreateBatchTable method, as follows: // Get a table to hold the rows temporarily until it contains BatchSize rows // Then we'll update the destination in bigger batches. private void CreateBatchTable(string strTableName) { // Get the Schema into m_metaDataTable; CreateSchemaTable(strTableName); // Create new data table m_batchTable = new DataTable(); // Build the table MetaData. int countColumns = m_metaDataTable.Rows.Count; In this step, you precreate the number of columns you need so that you can place the columns in the correct order. If each column is added in the order found in the metadata table, the columns will not be in the correct order when inserting the data with the query. // Preload with columns DataColumn[] columns = new DataColumn[countColumns]; for (int iColumn = 0; iColumn < countColumns; iColumn++) { // Point to the row describing this column DataRow rowCurr = m_metaDataTable.Rows[iColumn]; The ORDINAL_POSITION string is a string index into the ordinal position of the column in the source table. It is a 1-based index but the columns collection is 0-based, so the code subtracts one to correct the off-by-one index. // Build the columns array in the order found in the table. // Makes it easier on the user and the programmer. columns[Convert.ToInt16(rowCurr["ORDINAL_POSITION"])-1] = new DataColumn( rowCurr["COLUMN_NAME"].ToString(), GetSqlDbTypeFromName(rowCurr["DATA_TYPE"].ToString()).GetType()); } Now, all the columns have been added in the correct order; the code adds them to the batch table. m_batchTable.Columns.AddRange(columns); } Generating the INSERT StatementTo insert data into the batch table, the code dynamically creates an INSERT statement from the columns in the metadata table by adding parameters for each column. for (int i = 0; i < m_countMetaDataColumns; i++) { sb.Append("@p" + i.ToString() + ", "); // Point to the row describing this column DataRow rowCurr = m_metaDataTable.Rows[i]; // Get the length for character types string strLen = rowCurr["CHARACTER_MAXIMUM_LENGTH"].ToString(); int len = strLen.Length == 0 ? 0 : Convert.ToInt32( strLen ); // Set the parameter with name, type and length. cmd.Parameters.Add("@p" + i.ToString(), GetSqlDbTypeFromName(rowCurr["DATA_TYPE"].ToString()), len, m_batchTable.Columns[i].ColumnName); } // Add the closing parenthesis // Remove the last comma sb.Remove(sb.Length - 2, 2); sb.Append(" )"); The completed INSERT statement looks similar to the following: INSERT INTO TableName VALUES( @p0, @p1, @p3 ) Mapping the ColumnsThe code that maps the ExternalMetaData columns to the buffer columns is perhaps the most complex in the SQL Client Destination and requires some explanation. Discovering Which Input Columns Map to External ColumnsIt's important to remember all through this discussion that input columns represent buffer columns and external columns represent destination table columns. When a user edits the component in the Advanced Editor, the two sets of columns visible in the editor represent those to column collections. When creating or deleting a mapping between two columns in the Advanced Editor, the user is selecting which input columns should flow to each table column. Another way of thinking about it is the user is specifying which buffer column should flow to which ExternalMetaData Column. ExternalMetaData Columns unfortunately do not have the name or ID of the buffer column. In fact, they don't even contain the ID of the input column. To discover which buffer (input) column should flow to a given table (ExternalMetaData) column, it is necessary to work backward from the input ID of the input column to the ExternalMetaData Column ID to the ExternalMetaData Column name to the Destination Table column name. When it is all done, the component will have established which column on the destination table maps to which column on the input buffer. Take a look at the following code to see how this is done: // Get the input and the external column collection IDTSInput90 input = ComponentMetaData.InputCollection[0]; IDTSExternalMetadataColumnCollection90 externalcols = input.ExternalMetadataColumnCollection; This hash table makes it possible to retrieve the ID for an ExternalMetaData Column by name to get its ID. Later the code uses this hash to match the column name on the batch table to the ExternalMetaData Column name and then get the ExternalMetaData Column ID to match with the input column that references the ExternalMetaData Column and then get the LineageID from the input column. The LineageID can then be used to retrieve the buffer column index. // Make a hash table for the names of the external columns and contains the ID int cExternalCol = externalcols.Count; System.Collections.Hashtable hashExternalNameToID = new System.Collections.Hashtable(cExternalCol); // Build a mapping between the external column name and its ID for (int iExternalCol = 0; iExternalCol < cExternalCol; iExternalCol++) { IDTSExternalMetadataColumn90 externalcol = externalcols[iExternalCol]; hashExternalNameToID.Add(externalcol.Name, externalcol.ID); } // Get the input columns collection and make a hash table to map the external // ID that it references to the lineage ID of the column IDTSInputColumnCollection90 inputcols = input.InputColumnCollection; int cInputCol = inputcols.Count; System.Collections.Hashtable hashReferenceIDToLineageID = new System.Collections.Hashtable(cInputCol); // Build a mapping between external columns and input buffer columns IDs for (int iInputCol = 0; iInputCol < cInputCol; iInputCol++) { IDTSInputColumn90 inputcol = inputcols[iInputCol]; if (inputcol.ExternalMetadataColumnID > 0) hashReferenceIDToLineageID.Add(inputcol.ExternalMetadataColumnID, inputcol.LineageID); } Now that you have a way to discover which LineageID is connected to which ExternalMetaData Column name, you can get the buffer index from the column name on the batch table. // Loop over all columns in the batchTable for (int iRSCol = 0; iRSCol < cBTCol; iRSCol++) { // Get the name for the column at the current index string strRSColName = m_batchTable.Columns[iRSCol].ColumnName; // Find the ID of the external column from the name // ExternalMetaData is driven from the destination table. // This should not fail unless ExternalMetadata is corrupt. int idExternal = (int)hashExternalNameToID[strRSColName]; // Find the ExternalMetadata column that points to this ID try { int linid = (int)hashReferenceIDToLineageID[idExternal]; // Get the index in the buffer of this column int idx = (int)BufferManager.FindColumnByLineageID(input.Buffer, linid); This is the mapping array. The array is in order of the columns found in the batch table and the values are the indexes into the buffer for those columns. In the ProcessInput method, the component can now simply loop through this collection for each batch table column and find the index into the buffer for transferring the buffer data into the columns of the batch table using the INSERT statement shown earlier. m_idxColumn[iRSCol] = idx; } } The ProcessInput MethodThe PreExecute method built the mapping array that maps the column to the buffer index. The ProcessInput method has a pretty simple job. Get each of the rows from the buffers passed into the method and pass the column values from the buffer row into the parameters for the INSERT statement. Getting Data from the Input Bufferfor (; iCol < cCols; iCol++) { // Which buffer column is this ? int idxCol = m_idxColumn[iCol]; // Set the parameter value for the insert. m_sqlAdapter.InsertCommand.Parameters[iCol].Value = buffer[idxCol]; } There is some more code in the sample project for handling blobs and so forth, but this is the essential code that extracts data out of the buffer using the buffer index array built in the PreExecute method. Inserting the DataThe following statement performs the insert. The Update method gives ADO.NET an opportunity to send the batch of rows. m_sqlAdapter.InsertCommand.ExecuteNonQuery(); m_sqlAdapter.Update(m_batchTable); Handling Error RowsIf a row fails to correctly insert, there will be an exception. Depending on the Error Disposition settings the user has selected, you might want to either ignore the error, redirect the error row, or fail the component. catch (Exception e) { if (m_rowdisp == DTSRowDisposition.RD_FailComponent) throw e; if (m_rowdisp == DTSRowDisposition.RD_IgnoreFailure) continue; if (m_rowdisp == DTSRowDisposition.RD_RedirectRow) { buffer.DirectErrorRow(errorOutputID, 100, iCol); } } Incrementing Pipeline Performance CountersA commonly missed detail of custom components is updating the performance counters. The following code shows how easy it is to add support for the performance counters with methods provided on the ComponentMetaData interface. finally { // Update the number of rows we inserted ComponentMetaData.IncrementPipelinePerfCounter(DTS_PIPELINE_ CTR_ROWSWRITTEN, uiRowsWritten); // Update the number of blob bytes we wrote ComponentMetaData.IncrementPipelinePerfCounter(DTS_PIPELINE _CTR_BLOBBYTESWRITTEN, uiBlobBytesWritten); } The SQL Client Destination code has more code than you see here. This discussion has focused on those sections of code that might be difficult to understand or that cover new ground. As always, stepping through the code in the debugger is the best way to understand it completely. Writing a destination is not difficult, even one that dynamically discovers and maps columns as this one does. You can convert the sample destinations into your own. Adapting the code to the specific ADO.NET provider and the ADO.NET ODBC SQL Client shows how to use this same SQL Client Destination code for a different provider with little effort. |
EAN: 2147483647
Pages: 200