Custom Component Concepts
| If you've just finished reading the preceding chapter about writing custom tasks, you might think there are similarities between how you write a custom task and how you write a custom data flow component, and there are. As noted in Chapter 24, "Building Custom Tasks," the setup for all the components is virtually identical with the exception of a few minor differences such as the attributes and names you use. However, after you get past the initial setup, you'll want to do a reset and clear the brain slate a bit. Implementing custom data flow components is very different from implementing custom tasks. Writing a custom task is like writing a windows application. For example, applications have "main" functions, which are the primary entry and exit points for the application. Tasks have the Execute method as the primary entry and exit point and it is called only once for the entire execution life cycle of the task. Because of the nature of data flow, data flow components have a little different life cycle and function call order than you might expect. There are two time frames when methods get called. The first is design time and the other is runtime. Some methods get called exclusively during design time, others might get called during design time and runtime, while others might get called exclusively during runtime. Still other methods might be called multiple times during execution, and sometimes which method is called depends on the component type. If this is a bit confusing, don't worry. We'll sort it out in a minute. The point is that you can't approach component development in the same way that you approach writing custom tasks or any other application for that matter. You need to keep an open mind. Understanding a little more about the architecture of the Data Flow Task, specifically those parts relating to data flow components, is useful as well. The remainder of this section provides a few insights into how the Data Flow Task interacts with components that should be helpful when writing your custom components. Design TimeRecall the discussion in Chapter 23, "Data Flow Task Internals and Tuning," that briefly touched on the Layout Subsystem and mentioned that it provides the design time behavior for components, notably adding, deleting, validating, loading, and saving components and their inputs, outputs, and columns. See Figure 23.1. The Layout Subsystem also provides the column metadata to the Buffer Subsystem and execution tree information to the Execution Engine. Therefore, when components interact with the Data Flow Task, they are interacting with the Layout Subsystem and providing information that flows throughout the Layout Subsystem to the Buffer Subsystem for creating buffers that the component will use at runtime. The ComponentMetaData ObjectFor the component writer, the first and foremost interactions with the Layout Subsystem (Layout) are usually through the ComponentMetaData object. When you drop a component onto the designer, Layout creates a new ComponentMetaData object for the component to house all the information about the component. Components store and retrieve information into and from the ComponentMetadata object. They also use the ComponentMetaData object to interact with the designer or other programmatic client through events and logging. Think metaphorically for a moment about when you get up in the morning and start your day. One of the first things you do is get dressed. The hat you wear determines the role you play at work. You might wear multiple hats. The uniform you wear represents the kind of work you do. You store information in your clothes such as your wallet or purse that identify who you are, where you live, and where you shop. The ComponentMetaData object is similar. Like the hat, components declare what role they play, whether they are source, destination, or transform through ComponentMetaData. Like the uniform, the component populates the ComponentMetaData object with columns and other metadata that represent how the component will function. Finally, like the wallet or purse, the component communicates its own ID and stores information such as connections needed and columns used in the ComponentMetaData object. Like most analogies, if you stretch it too far, it doesn't make much sense and underwear has no parallel. But hopefully, you get the point, which is that the component describes itself to the ComponentMetaData object and then the ComponentMetaData object works with the other data flow subsystems to build the buffers, execution trees, threads, and other internal structures to properly interact with the component. Data Flow Component Design LifetimeBefore plunging into the code, it's helpful to have a high-level view of what it is you are going to write. Figure 25.1 shows the design lifetime of a typical data flow component. Although not completely accurate for every operation sequence, it should give you an idea of how the user, layout, designer, and component interact. Figure 25.1. An illustration of a typical data flow component design lifetime.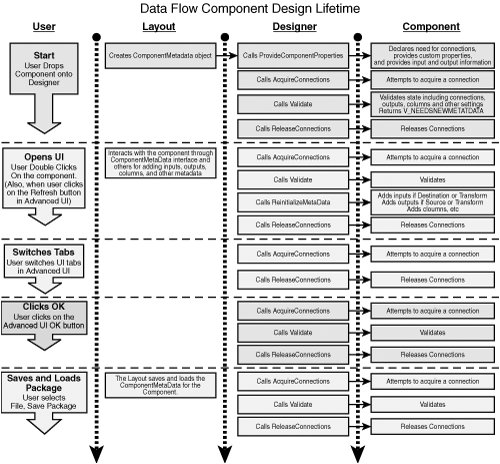 Ceaseless ValidationFigure 25.1 illustrates a few interesting and helpful points. One thing to notice is that Validate gets called a lot. So do the AcquireConnections and ReleaseConnections calls. Just about every time you do something with the component in the designer, you get the validation sandwich. AcquireConnections and ReleaseConnections are the bread and the Validate call is the meat, or cheese if you are a vegetarian, or lettuce if you're vegan. This makes sense when you think about it because just about everything that happens in the data flow is related in some way to external data. Tip Remember this point when trying to troubleshoot packages that take a long time to open. Anything that a component does in Validate will happen at least once, probably multiple times, when opening a package. Also, problems with packages that take a long time to open can typically be traced back to the connection managers when attempting to acquire a connection from a slow or disconnected server. Providing Component PropertiesAlso, notice that ProvideComponentProperties is where you declare the need for connections and publish custom component properties. ProvideComponentProperties is only called once when the component is first dropped onto the designer. From the package writer perspective, this isn't all that interesting. However, from your perspective as a component writer, you should keep this in mindespecially if you ever add a new custom property or connection to your component. For example, if there are existing packages with your custom component in them, and you add a new custom property, the components in the old packages will not show you the new custom properties because ProvideComponentProperties is only called once for the entire lifetime of the component within a package. You'll have to delete the old component and add a new one anytime you change anything affected by the code in ProvideComponentProperties. Work Done for the ComponentNotice also that the designer is doing a lot of work for the component. This is important to keep in mind when you write code that builds packages. Your custom code must do everything that the designer does when setting up a package. Notice that the layout persists the component, instead of the component handling the task. This simplifies the component somewhat and eliminates some of the coding the custom component writers must do. It also makes it possible for the layout to do some validation on the component XML. Finally, when an adapter is added to a data flow, ReinitializeMetaData must be called after ProvideComponentProperties to ensure that the metadata for the source and destinations is correctly established. RuntimeAs mentioned previously, during runtime or package execution, the Data Flow Task manages the data in buffers and "moves" the buffers around or, more accurately, does some pointer magic to make buffers always look fresh to the components. At some point, the Execution Engine needs to present the buffers to the components so that the components can read the data and process it according to their functionality. For example, sources need to receive a buffer that they can fill with data. Destinations need to receive a buffer that they can read and send to the destination medium. Transforms need to read and write to buffers. The way the Execution Engine provides access to the buffers is through two methods, PrimeOutput and ProcessInput. There are more than just these two methods on the runtime interface, which are covered in a bit, but these two methods are extremely important because it is inside them where the real data-processing work happens in the Data Flow Task. The PrimeOutput MethodPrimeOutput is the method the Execution Engine uses for providing a buffer to sources and transforms and is only called on components with asynchronous outputs. Synchronous outputs don't need a PrimeOutput call because they don't generate new buffers. They only fill buffers that are provided to them on their ProcessInput calls. Destinations don't receive PrimeOutput calls because they don't have outputs and they don't send data to buffers; they send it to their respective media. PrimeOutput is only called once on asynchronous outputs at the beginning of the Data Flow Task execution. The component then holds onto a reference to the buffer and stuffs it with data until it runs out. After the component runs out of data, it sets the buffer's end-of-file flag to tell the Execution Engine that the component has completed processing. Again, for synchronous outputs, the end-of-rowset flag isn't necessary because the Execution Engine already knows how many buffers are arriving at the synchronous input of the output. Figure 25.2 illustrates two views of buffers. One is how the component views the buffer it is passed in PrimeOutput. The component never gets another call to PrimeOutput so it holds onto the buffer reference and continues adding rows to the buffer until it is done. To the component, it would seem that the buffer is huge. In fact, even if the component processes billions of rows, it only receives one buffer. However, the Execution Engine has a different view, which is the second part of Figure 25.2. When the component attempts to insert a row of data into the buffer and if the buffer is full, the Execution Engine "flips" the buffer with a fresh (empty) buffer. The former buffer is then available for processing by another component; however, it is rarely moved. When the downstream component is ready to process a new buffer, the Execution Engine calls the component's ProcessInput method and passes the pointer to the next available processed buffer. Figure 25.2. Components only see one buffer.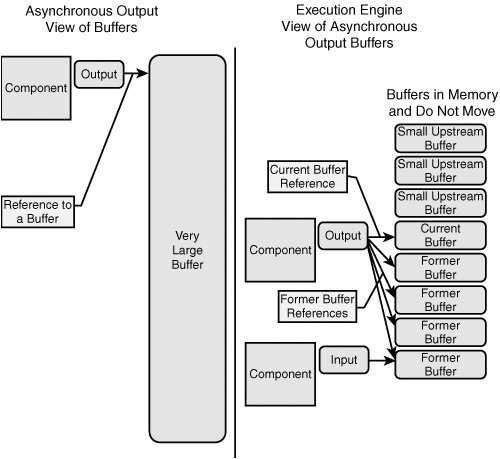 The ProcessInput MethodProcessInput is the method the Execution Engine uses for providing buffers to transform and destination inputs. ProcessInput is called for every buffer on an input and is called until the buffers on the input run out or the data flow terminates because of errors or exceptions. It can be a bit confusing as to which types of components get which calls and on what locations, so the various possibilities are captured in Table 25.1.
This has been a short overview of how components interact with the Data Flow Task environment. Hopefully, this gives you some perspective going into the development process. Now, take a look at the sample components that have been provided. |
EAN: 2147483647
Pages: 200