Data Manipulation Transforms
| These are the transforms you typically think of when you think of transformations. These modify the data, changing it in fundamental ways. AggregateThe Aggregate transform provides several different aggregation operations and a Group By feature. It supports multiple simultaneous aggregations on multiple columns as well as multiple aggregations on the same column. You can configure to only have one output or multiple outputs. This transform is useful for Business Intelligence because it supports the aggregation operations needed for things like populating fact tables with fine control over the grain of the aggregations. Table 20.22 provides a profile for this component.
Setting Up the Aggregate TransformTo create a simple aggregation, select the column on which you want to operate in the Available Input Columns window. Figure 20.32 shows the aggregate from the Aggregate.dtsx sample package. After you've selected the column, select the operation in the Operation column of the lower grid. Simple aggregations such as sum and average will only output one row. More complex aggregations that use the Group By feature might output multiple rows, based on the data. Figure 20.32. The Aggregate Transformation Editor Advanced View with two outputs having two aggregation operations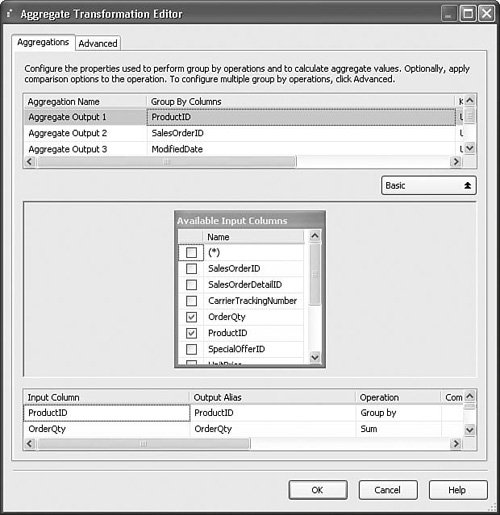 Table 20.23 shows the operations that are available in the Aggregate transform.
To create multiple outputs, click the Advanced button and select one of the empty rows in the top grid. Type in a name for the output and then select an input column from the Available Input Columns window. You can create any number of outputs this way. The sample package has an aggregate with three outputs, as shown in Figure 20.32. One output tells how many of each product have been sold by doing a sum of the order quantity in the sales order data grouped by the product ID. The second output tells the sum total for all items sold per sales order ID, and the third output tells the sum total dollar amount sold per day based on the change date using Group By. Character MapThe Character Map transform performs common character conversions typically found in multilanguage environments. Japanese has essentially two alphabets that augment the kanji character set. One, katakana, is used for things like spelling words and names from other languages that cannot be formed with kanji. The other, hiragana, is used for verb conjugations and replacing or simplifying kanji reading. Conversion between hiragana and katakana is direct because there is a hiragana character for every katakana character. Simplified Chinese is a reduced set of Chinese characters and is a subset of the traditional Chinese character set. Uppercase and lowercase are useful for English as well as other languages and the width operations are useful for character encodings found in Japan and other such countries with more complex character-based writing systems than a simple alphabet. Table 20.24 provides a profile for this component.
The operations available in the Character Map transform are noted in Table 20.25.
Setting Up the Character Map TransformTo set up the Character Map transform, select the column you want to use and then the operation to perform on it. There is also an option to either perform the conversion in place, or to create a new column with the modified value. Figure 20.33 shows the Character Map Transformation Editor from the CharacterMapCopyColumn.dtsx sample package. Figure 20.33. The Character Map Transformation Editor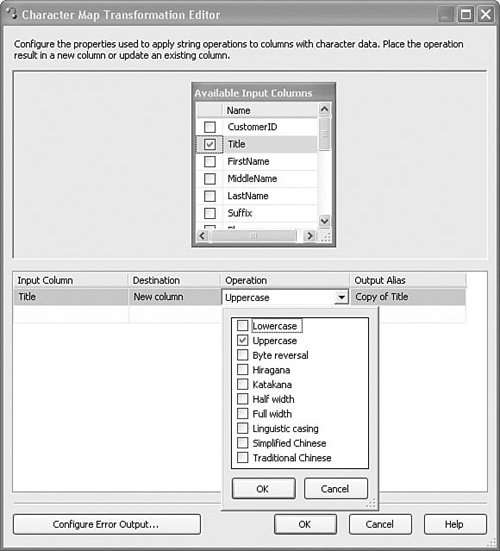 Copy ColumnThe Copy Column transform is one of the simplest around. It simply creates a clone of a column, copying the value of the source column into the cloned column. This is useful when you need to perform destructive operations on a column, but you want to retain the original column value. For example, you can copy the column and then split it into a different path with an Aggregate transform. This is more efficient than, for example, a multicast because only the columns of interest get copied. Table 20.26 provides a profile for this component.
Setting Up the Copy Column TransformTo set up the Copy Column transform, simply select the column you want to copy and, if you want, change the name of the output column. Figure 20.34 shows the editor for the Copy Column transform in the CharacterMapCopyColumn.dtsx sample package. Figure 20.34. The Copy Column Transformation Editor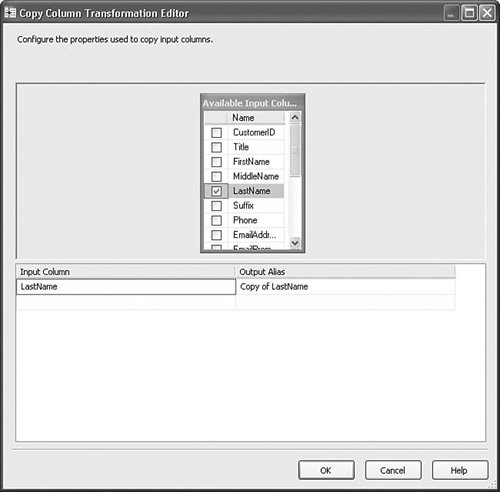 Data ConversionThe Data Conversion transform performs type casting similar to the CAST function in T-SQL. Because the Data Flow Task is very type specific, it is often necessary to convert a column type from the type provided at the source to the type required at the destination. A good example of this is data retrieved from Excel files. If you use the Import/Export Wizard to export data from an Excel file, the Data Flow Task will likely contain a Data Conversion transform because Excel supports so few data types. Table 20.27 provides the profile for this component.
Setting Up the Data Conversion TransformTo set up the Data Conversion transform, select the columns with types you want to convert and in the bottom grid, select the type to which you want to convert the column. You can also change the name of the output column in the Output Alias column of the grid. If you change the output column name to be the same as the corresponding input column name, it overwrites the column. Otherwise, a new column is created with the new name. Figure 20.35 shows the Data Conversion Transformation Editor. Figure 20.35. The Data Conversion Transformation Editor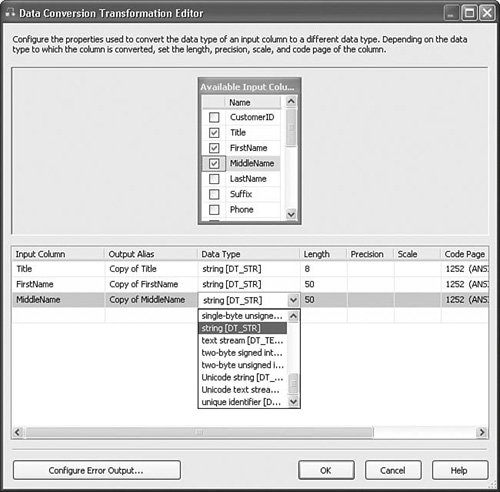 OLE DB CommandThe OLE DB Command transform is useful when you want to drive behavior with tables. For example, you could execute a stored procedure for every row in the input set. Table 20.28 provides the profile for this component.
Setting Up the ComponentThe setup for this component can be a little tricky. It doesn't have its own custom editor and it requires an input with columns that you'll likely map as parameters to the OLE DB Command (SQL Query). You must first create a connection to the database that the transform will work against. Select that connection manager in the Connection Manager column. Next, type in the SqlCommand that you want to execute for every row in the SqlCommand property on the Component Properties tab, as shown in Figure 20.36. Figure 20.36. Setting the SQL query to be executed every row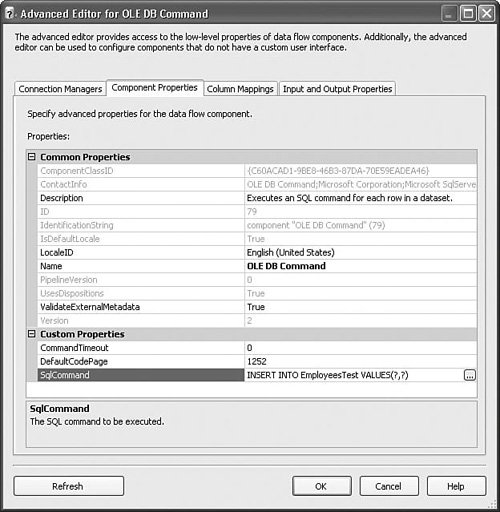 Notice that the query has two question mark parameter markers. Go to the Column Mappings tab and click the Refresh button. The Input and Destination columns should be updated to have a destination column for each parameter marker. Drag the input columns to the parameter destination columns, as shown in Figure 20.37. Figure 20.37. Creating the parameter mappings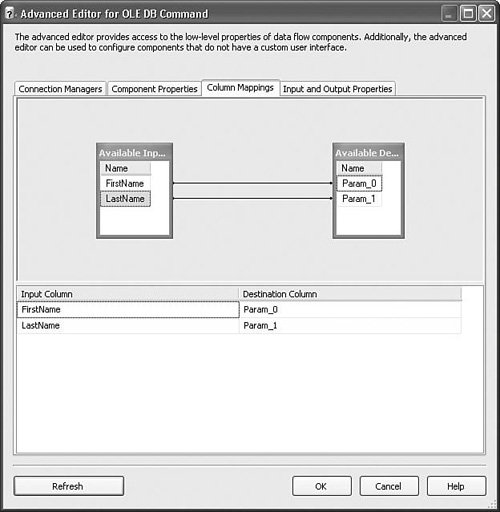 If there is still an error message in the editor after creating the mappings, click the Refresh button again and it should go away. SortThe Sort transform provides a way to order rows on one or more columns. It also provides a way to remove duplicate rows. The sort is an important transform because it is used to prepare flows for other transforms, such as the Merge and Merge Join transform. Table 20.29 provides the profile for this component.
Setting Up the Sort TransformThe Sort Transformation Editor provides a list of columns that you can sort on as well as those you want to pass through the transform. Figure 20.38 shows the Sort Transformation Editor in the Merge.dtsx sample package. Figure 20.38. The Sort Transformation Editor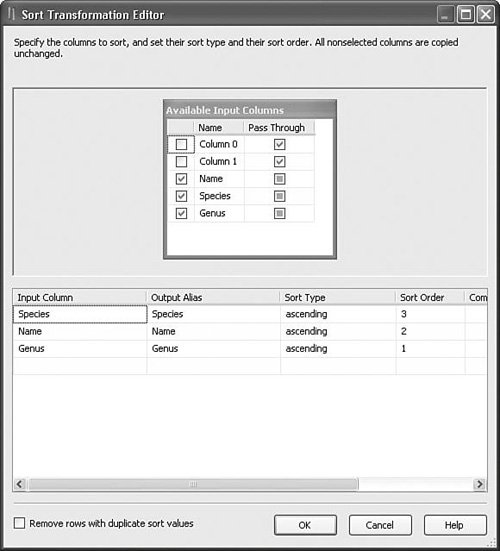 In Figure 20.38, the rows are sorted by Genus, Name, and Species columns, all in ascending order. If you want to remove duplicates, select the Remove Rows with Duplicate Sort Values check box at the bottom of the editor. The Sort transform determines duplicates by comparing only the sorted rows. If differences exist in the rows on nonsorted columns, they will still be removed if their sorted column values match. |
EAN: 2147483647
Pages: 200