Understanding the DataSet Class
The DataSet provides a virtual snapshot of a database and stores it as a disconnected, in-memory representation of a collection of data tables, relations, and constraints. The DataSet class allows data to be updated while being physically disconnected from the data source. By design, the DataSet has no direct knowledge of the underlying data source, but instead relies on the DataAdapter class to open this connection as needed. The DataSet represents the disconnected portion of the ADO.NET architecture, and the .NET managed provider represents the connected portion.
The DataSet class is strongly integrated with XML and can serialize to both XML and XSD files. The XML file provides a representation of the data that preserves the relational information. The XSD file represents the schema for the DataSet. The DataSet natively serializes with XML and XSD in both directions, meaning that it can both read and write XML and XSD files.
For writing purposes, the DataSet can infer its own schema and incorporate this information into the XML file that it generates, on a per-query basis. For performance reasons, it is not optimal to have the DataSet infer its own schema. In addition, this approach may lead to inaccuracies. A better approach is to have the DataSet reference and incorporate a specific XSD schema, which allows it to generate a more exact XML representation of the data.
For reading purposes, you can populate a DataSet with relational data using well- formed XML, with or without a specific XSD schema file. Typed DataSets are a special form of the DataSet that incorporate XSD schema information into strongly typed members that can be referenced from code just like a standard class attribute. As we discuss, XSD schemas are a powerful tool for validating data structures, and they improve the efficiency of working with the DataSet class.
The DataSet class is important for XML Web services, which can exchange relational data by leveraging the DataSet's ability to serialize to XML. The DataSet allows XML Web services to produce and exchange relational data as XML files that can be marshaled across the wire. Once these files reach their destination, they may be processed using standard XML-based technologies such as XSLT (for transformations) and XPATH (for queries). Alternatively, the XML data can be reassembled into a new DataSet object.
Many books highlight examples of how the DataSet class interacts with XML, but they do not provide a context as to why this is beneficial. From a pure performance standpoint, XML serialization is a processor-intensive operation that introduces an additional layer for working with data. In other words, for some operations it will be sufficient to manipulate the in-memory data tables directly, without ever needing to represent the data as XML. In short, XML serialization is a processor- intensive operation that should be used only when needed. In our opinion, there are four important scenarios where you need to use XML serialization:
-
For exchanging relational data with XML Web services over Hypertext Transfer Protocol (HTTP)
-
For validating data against a specific XSD schema
-
For generating typed DataSets
-
For persisting relational data in an XML repository
It is especially advantageous to persist complex, hierarchical data as XML, if possible, because this can eliminate the need for multiple subqueries to retrieve all of the child information ( assuming that the data is complex enough to require multiple database calls to assemble the complete data set).
Clearly, XML integration is the most important feature of the DataSet class and is the focus of our discussion. But before we go too far down this road, let's briefly review the other important features, benefits, and uses of the DataSet class.
Features of the DataSet Class
The DataSet is a disconnected, in-memory representation of a data source that preserves the schema information. The DataSet contains a collection of DataTable objects that each represent a table of data and that can originate from multiple underlying data sources. A DataTable may represent a physical database table or the contents of a query that derives information from multiple, related database tables. Each DataTable object is comprised of a collection of DataRow and DataColumn objects. The DataColumn objects represent the schema information for the table, and the DataRow objects contain the actual record data for the table.
You can create a DataSet in the following three ways:
-
Manually, by programmatically instancing the DataTable, DataRelation, and Constraint objects within the DataSet and then populating the DataTables with data
-
Automatically, by populating the DataSet from an existing relational data source using the DataAdapter object
-
Automatically, by loading the contents and schema information directly into the DataSet from XML and XSD files
Because the DataSet is disconnected, any operation will take effect against the in-memory data, not against the actual data source. The DataAdapter object provides the connection between the DataSet and the underlying data source, and it can be created and destroyed as needed without any effect on the contents of the DataSet. Once the DataSet is created and filled, it can be accessed programmatically as long as it is retained in memory. This is in contrast to the DataReader object, which requires a persistent connection to the data source.
The command methods exposed by the DataAdapter synchronize and guarantee data concurrency between the data source and the DataSet's DataTable objects. The DataAdapter object provides commands for all four types of database operations: SELECT , INSERT , UPDATE , and DELETE . For example, when the DataSet calls the Update() method on the DataAdapter, the DataAdapter analyzes the changes that have been made before they are committed. The Update() method provides this information back to the DataSet on a per-record basis. This information is encapsulated by the DataRowState enumeration value for each DataTable.DataRow object. The enumeration provides before and after values for the update and allows for more programmatic checks before the updates are actually committed.
The DataSet has the following advantages:
-
The DataSet is versatile and can perform complex operations such as sorting, filtering, and tracking updates.
-
The DataSet provides the GetChanges() method, which generates a second DataSet that contains the subset of records (from the original DataSet) that have been modified. This is especially useful when you need to send record updates across the wire and want to minimize the amount of sent data.
-
The DataSet is disconnected from the underlying data source. The DataSet allows you to work with the same records repeatedly without having to requery the data source.
-
The DataSet can be cached in memory and retrieved at any time. The DataSet is a good solution for paging through data in a DataGrid. The DataSet can be cached and rebound to the DataGrid as the page index changes. The underlying data source does not need to be requeried.
-
The DataSet can contain multiple tables of results, which it maintains as discrete objects. A DataSet can simultaneously represent data from multiple sources, for example, from different databases, from XML files, from spreadsheets, and so on. Each data source is contained in a separate DataTable object within the DataSet. Once the data resides in the DataSet, you can treat it as a homogeneous set of data ”that is, as if it had come from a single source. You can work with the tables individually or navigate between them as parent-child tables.
-
The DataSet can be bound to a wide range of ASP.NET Web controls and .NET Windows Form controls.
-
The DataSet provides excellent support for XML and will natively serialize to XML and XSD files that represent relational data.
-
The DataSet provides excellent support for XML Web services. The DataSet provides a powerful way to exchange data with other components and applications using XML representations of the DataSet contents.
The DataSet does have some disadvantages. The DataSet has higher memory and processor demands than other data objects, which can potentially lead to lower application performance. The DataSet object is not the optimal solution for straight-forward, one-time data retrieval operations. The DataReader object is a faster, more efficient solution for quick data retrievals that do not need to be cached or serialized. Similarly, the XmlReader object is a faster solution for processing the resultsets from stored procedures that natively return XML. (However, the XmlReader lacks the DataSet object's ability to natively serialize relational data to XML).
Using the DataSet Object
There are two common purposes for using the DataSet object. The first involves updating data in an underlying data source. The second involves serializing relational data to and from XML and XSD files. In the following section we discuss the first application: accessing and updating data using the DataSet object.
Updating Data Using the DataSet
The DataSet object allows you to modify a disconnected set of records and then synchronize the updates with the parent data source. This is especially useful in a Web application because updates on the client are always disconnected from the parent data source on the server. The DataSet object may hold one or more DataTable objects, each of which represents a specific database table or the results of query. The DataSet object allows you to make updates to one or more of the available DataTable objects with no special coding other than making sure you reference the correct DataTable object that you are modifying.
The DataSet object reduces the burden on the developer by managing concurrency during disconnected updates to data. The DataSet object tracks modifications to the data and also preserves the original values for reference purposes. In addition, the DataSet object tracks errors that occur during updates ”for example, errors that are caused by modifying a data field with an incorrect data type. In short, the DataSet object provides a record of updates that can be examined prior to synchronizing the updates with the parent data source.
The following is the workflow for updating a DataSet on a Web client and synchronizing the updates back to the parent data source:
-
On the server, populate a DataSet with records from the parent data source.
-
On the server, disconnect the DataSet from the parent data source and then bind it to a DataGrid. (Alternatively, you can render the data in another format that allows updates to the DataSet. For our purposes, we assume a DataGrid.)
-
On the server, assign the DataSet into the cache, using a unique cache key name. For example, use the client's session ID as the key name . The cached copy of the DataSet will be used later for reference and to avoid another round trip to the database.
-
Deliver the Web form (with the bound data) from the server to the client for display and updates.
-
On the client, modify one or more DataTables in the DataSet by adding, updating, or deleting DataRows.
-
Submit the Web form from the client back to the server.
-
On the server, retrieve the original cached DataSet.
-
On the server, copy Web client changes to the original DataSet. (This step may seem confusing, but it is required because you cannot retrieve the DataSet directly from the DataGrid Web control.)
-
On the server, examine the modified records for errors using the DataSet's HasErrors property. (The DataTable object also provides the HasErrors property.)
-
If you do not find any errors, proceed with the update by initializing a DataAdapter object and passing it the modified DataSet.
-
If you find errors, then examine the specific error messages using the DataRow object's RowError property. If the errors cannot be handled on the server, then raise the error messages back to the Web client.
These steps are specific to Web applications and are more complicated than what you would need for a Windows (desktop) application. In a desktop application, you can retrieve the DataSet directly from the DataGrid object's DataSource property:
Private dsCustomers As DataSet dsCustomers = CType(DataGrid1.DataSource, DataSet)
Unfortunately, in a Web application you must manually store the original DataSet object and then manually update the changes from the DataGrid. If the client has updated a DataGrid, then the easiest approach is to retrieve the values directly from the edited DataGrid item. Then, simply retrieve a cached copy of the original DataSet and update it directly using the edited values. We show an example of how to do this in the next section.
Once you have a reference to the modified DataSet, you can examine the DataSet for changes and errors and then update the data source. This check is useful if you have a multirow DataSet and do not know in advance which, if any, rows have been modified. The following code outlines this process:
' Look for modifications and errors ' Note: The DataSet object's HasChanges() method can return Added, Deleted, ' Detached, Modified, and Unchanged records If dsCustomers.HasChanges(DataRowState.Modified) Then If dsCustomers.HasErrors Then Dim sqlDR As DataRow For Each sqlDR In dsCustomers.Tables(0).Rows If sqlDR.HasErrors Then Err.Raise(vbObjectError + 512, , sqlDR.RowError) ' Raise error End If Next Else ' Commit the update End If End If
The DataSet class also supports the GetChanges() method, which returns a second DataSet that contains just the modified records from the original DataSet. This method is convenient for filtering modified records, but you must also check for errors in any of the DataSet's DataTable objects. After calling the GetChanges() method, you should check for DataTable errors using the DataTable object's HasErrors property. If this property returns "True," then you can use the GetErrors() method to extract an array of DataRow objects for the individual rows that have errors. If possible, you should resolve the errors within each DataRow and then call the DataTable object's AcceptChanges() method. Once all errors have been resolved, you can pass the DataSet of modified records to a DataAdapter object in order to synchronize the updates with the parent data source.
Note that the DataTable object's AcceptChanges() method only needs to be called if you will be performing successive updates on the DataTable. This method will reset the DataSet object's tracking parameters. For example, let's say you modify a DataSet and then call AcceptChanges() . If you continue to modify the DataSet, then its HasChanges property will reflect only those changes made since AcceptChanges() was last called. Similarly, the GetChanges() method will only contain records that were modified since AcceptChanges() was last called.
Sample Code for Updates Using a DataGrid Control and a DataSet Object
The sample project for this chapter provides two Web pages that illustrate how to update changes in a disconnected DataSet back to the parent data source. The pages are as follows :
-
UpdateDSWithDataGrid1.aspx: This page demonstrates how to use the DataSet and DataAdapter objects to update a data source. It uses the SQLCommandBuilder to auto-generate the update Command object.
-
UpdateDSWithDataGrid2.aspx: This page demonstrates how to use the DataSet and DataAdapter objects to update a data source. It uses a parameterized stored procedure for the update Command object.
The update process is confusing the first time you attempt it, but with practice you should quickly grow to appreciate how well it works. Let's review the update process here, using the code from UpdateDSWithDataGrid1.aspx .
Figure 3-2 shows a DataGrid that is bound to a DataSet of customers from the Northwind database. This DataSet is also stored in the server cache so that you can access the original data without another round trip to the database. Notice that the DataGrid is in Edit mode for Customer ID AROUT .
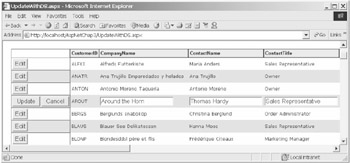
Figure 3-2: The UpdateWithDS.aspx screen
The Update button triggers the DataGrid's Update() event in the code-behind file. It is here that you implement the code for updating the parent data source:
Sub DataGrid1_Update(ByVal sender As Object, _ ByVal e As DataGridCommandEventArgs) ' Step 1: Retrieve the modified DataGridItem (row) Dim dgItem As DataGridItem dgItem = e.Item End Sub
The DataGrid1_Update() event handler tells you which data row has changed. You can then extract the user 's changes directly from the DataGridItem object ( dgItem ) and assign them to the original DataSet. First, you must retrieve a reference to the affected DataRow (in the original DataSet). The index of the affected DataRow matches the index of the DataGridItem because, in this example, the binding sequence was not affected by subsequent sorting. You can then set a reference to the affected DataRow as follows:
Dim sqlDR As DataRow sqlDR = dsCustomers.Tables(0).Rows(e.Item.ItemIndex)
The following is how you copy the CompanyName field value from the DataGrid to the affected DataRow:
' Update the DataRow using the DataGridItem Dim txtControl As System.Web.UI.WebControls.TextBox txtControl = dgItem.Controls(2).Controls(0) sqlDR("CompanyName") = txtControl.Text You may want to use another method of referencing the DataGrid item values if you are not comfortable with the syntax shown here.
Next, you use a SqlDataAdapter object to update the data source with the changes. Using the SqlCommandBuilder object, you are able to auto-generate the update Command object that the DataAdapter uses. The SqlCommandBuilder object must be initialized with the stored procedure that is used to originally select the data, which in this example is called GetAllCustomerDetails :
sqlConn = New _ SqlConnection(ConfigurationSettings.AppSettings("ConnectionString")) sqlAdapt = New SqlDataAdapter(New SqlCommand("GetAllCustomerDetails", sqlConn)) sqlCB = New SqlCommandBuilder(sqlAdapt) The final step is to execute the update using the DataAdapter's Update() method. You simply need to pass in the modified DataSet, and the update will execute. It is not efficient to pass in the entire original DataSet when you know that only one row has changed. For efficiency, you extract the subset of modified records from the original DataSet into a second DataSet using the GetChanges() method. It is the second DataSet that actually gets updated to the data source:
If dsCustomers.HasChanges(DataRowState.Modified) Then If Not dsCustomers.HasErrors Then ' Extract the modified records Dim dsChanges As DataSet dsChanges = dsCustomers.GetChanges() ' Commit the update sqlAdapt.Update(dsChanges) End If End If
Note that the GetChanges() method will accept a DataRowState modifier to return a specific kind of updated record, such as a deleted record. Without a modifier, this method returns all added, deleted, detached, and modified records.
For the full code listing, please see UpdateDSWithDataGrid1.aspx in the sample project.
Integrating the DataSet Object with XML
The DataSet object is strongly integrated with XML and can serialize its relational data to XML and XSD files. The benefit of this is that different applications can share relational data using self-describing XML files, even if they are written in different languages and are potentially running on different platforms. The XML and XSD files combine to document the relational structures in the data and to document the data types of each field. Web service components that deliver XML data files benefit greatly from using the DataSet object because there is little coding involved for serializing data to XML. Table 3-8 summarizes the XML-related methods that the DataSet class supports for reading and writing XML and XSD content.
| METHOD | DESCRIPTION |
|---|---|
| GetXml() | This method returns the XML representation of the data stored in the DataSet as a string, without an XML schema. This method is equivalent to calling the WriteXml() method while setting XmlWriteMode to IgnoreSchema. |
| GetXmlSchema() | This method returns the XML schema that represents the data stored in the DataSet as a string. |
| ReadXml() | (Overloaded.) This method reads XML data and schema information into the DataSet. This method reads from a filestream, from a file, or from objects derived from the TextWriter and XmlWriter classes. It optionally includes an enumeration called XmlReadMode that provides the following options: IgnoreSchema : This ignores inline schema information and uses the DataSet's current schema. This will cause exceptions if the incoming data does not match the DataSet's current schema. InferSchema : This ignores inline schema information and infers the schema as it reads the data into the DataSet. ReadSchema : This reads inline schema information and loads data into the DataSet. DiffGram : This reads the DiffGram into the DataSet and applies the changes contained in the DiffGram. Fragment : This reads XML documents into the DataSet, including those generated from SQL Server using the FOR XML clause. This mode reads schema information from the inline namespaces that are in the document. Auto : This applies the most appropriate mode: InferSchema , ReadSchema , or DiffGram |
| ReadXmlSchema() | This method reads an XML schema into the DataSet. |
| WriteXml() | (Overloaded.) This method writes out the XML representation of the data stored in the DataSet. This method writes out to a filestream, to a file, or to objects derived from the TextWriter and XmlWriter classes. It optionally includes an enumeration called XmlWriteMode that provides the following options: IgnoreSchema : This writes the current contents of the DataSet as XML without schema information. WriteSchema : This writes the current contents of the DataSet as XML with inline schema information. DiffGram : This writes the current DataSet in DiffGram format, which includes original and current values. |
| WriteXmlSchema() | This method writes the DataSet structure as an XML schema. This method writes out to a filestream, to a file, or to objects derived from the TextWriter and XmlWriter classes. |
| InferXmlSchema() | This method infers the schema for a file or TextReader that has been loaded into the DataSet. |
Generating XML from a DataSet
Let's jump right into an example. Listing 3-3 shows how to generate an XML document from a populated DataSet and then query the XML directly using an XPATH statement. This example simulates a scenario where a Web service generates an XML file of relational data and delivers it to a consumer. The consumer resides on a non-Microsoft platform and cannot work with the ADO.NET DataSet object. Instead, the consumer uses XPATH queries on the XML document to drill down into the data. You can find the code for this example in ExecSPReturnXSD.aspx within the sample project that accompanies this chapter.
| |
Imports System.Data Imports System.Xml Sub QueryProductList() Dim objDB As Apress.Database Dim strConn, strJSScript As String Dim arrParams() As String Dim sqlDS As DataSet Try ' Retrieve the connection string strConn = ConfigurationSettings.AppSettings("ConnectionString") ' Step 1: Instance a new Database object strConn = ConfigurationSettings.AppSettings("ConnectionString") objDB = New Apress.Database(strConn) ' Step 2: Load Products into DataSet [ProductList] arrParams = New String() {} sqlDS = objDB.ExecSPReturnDS("ProductList", arrParams) ' Step 3: Load the DataSet XML into an XmlDataDocument sqlDS.EnforceConstraints = False Dim xmlDataDoc As XmlDataDocument = New XmlDataDocument(sqlDS) xmlDataDoc.Normalize() ' Step 4: Use XPATH to query all nodes where UnitsOnOrder > 70 Dim objXmlNode As XmlNode Dim objXmlParentNode As XmlNode Dim strProductID As String Dim objXmlNodes As XmlNodeList = _ xmlDataDoc.SelectNodes("//UnitsOnOrder[.>70]") ' Step 5: Iterate through the XmlNodeList returned from the XPATH query Dim enmNodes As IEnumerator = objXmlNodes.GetEnumerator While enmNodes.MoveNext objXmlNode = CType(enmNodes.Current, XmlNode) objXmlParentNode = objXmlNode.ParentNode strProductID = objXmlParentNode.Item("ProductID").InnerText Response.Write("Product ID: "& strProductID & "has "& _ objXmlNode.InnerText & "units on order." & "<BR>") End While Response.Write("("& objXmlNodes.Count & "Products matched)") Catch err As Exception ' Error handling code goes here Finally objDB = Nothing End Try End Sub | |
In Steps 1 and 2, Listing 3-3 populates a DataSet object with the available products in the Northwind database. (We have created a new stored procedure for this purpose called ProductList , which simply returns all of the records in the Products table.) In Step 3, the DataSet object gets loaded into an XmlDataDocument object, which maps the relational data into an XML document. There is a lot of complexity in this transformation that is completely taken care of for you. Listing 3-4 shows the schema file that represents the resultset. It was generated using the DataSet object's GetXmlSchema() method.
| |
<?xml version="1.0" encoding=" utf-16"?> <xs:schema id=" NewDataSet" targetNamespace=" urn:products-schema" xmlns:mstns=" urn:products-schema" xmlns=" urn:products-schema" xmlns:xs=http://www.w3.org/2001/XMLSchema xmlns:msdata=" urn:schemas-microsoft-com:xml-msdata" attributeFormDefault=" qualified" elementFormDefault=" qualified"> <xs:element name=" NewDataSet" msdata:IsDataSet=" true"> <xs:complexType> <xs:choice maxOccurs=" unbounded"> <xs:element name=" Table"> <xs:complexType> <xs:sequence> <xs:element name=" ProductID" type=" xs:int" minOccurs="0" /> <xs:element name=" ProductName" type=" xs:string" minOccurs="0" /> <xs:element name=" SupplierID" type=" xs:int" minOccurs="0" /> <xs:element name=" CategoryID" type=" xs:int" minOccurs="0" /> <xs:element name=" QuantityPerUnit" type=" xs:string" minOccurs="0" /> <xs:element name=" UnitPrice" type=" xs:decimal" minOccurs="0" /> <xs:element name=" UnitsInStock" type=" xs:short" minOccurs="0" /> <xs:element name=" UnitsOnOrder" type=" xs:short" minOccurs="0" /> <xs:element name=" ReorderLevel" type=" xs:short" minOccurs="0" /> <xs:element name=" Discontinued" type=" xs:boolean" minOccurs="0" /> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
| |
The schema file provides you with two important types of information. First, the resultset contains a sequence of fixed elements (or fields) that represent a product record. This set of elements starts with the ProductID field and ends with the Discontinued field. The sequence of elements is contained within a Table element. Second, you know the data type for each element, which allows you to validate the record fields should you need to add additional records.
To retrieve the actual XML, you can call the XmlDataDocument object's InnerXML() method. This is a portion of the first record in the XML file:
<NewDataSet> <Table> <ProductID>1</ProductID> <ProductName>Chai</ProductName> <UnitsOnOrder>0</UnitsOnOrder> <Discontinued>false</Discontinued> </Table> </NewDataSet>
In Step 4, we execute an XPATH query directly against the XmlDataDocument to retrieve all nodes where the UnitsOnOrder field value is greater than 70. You accomplish this using the XmlDataDocument object's SelectNodes() method. Finally, in Step 5 you iterate through the returned list of nodes using the standard enumerator interface. The output is as follows:
Product ID: 64 has 80 units on order. Product ID: 66 has 100 units on order. (2 Products matched)
Listing 3-3 is short, but it clearly demonstrates the powerful functionality that the DataSet and XmlDataDocument objects have with very little code.
DataSet Validation Using XSD Schemas
An XSD schema file describes the structure of a relational data set and the data types that it contains. XSD schema files serve two important purposes. First, they fully describe a data set, which is essential when you deliver an XML file to an outside consumer. Second, they serve as an excellent validation tool, especially when you are adding additional records to a data set and need to verify that you are using the correct data types.
Let's consider an example. Listing 3-5 shows how to use an XSD schema to validate new DataRow records in a DataSet object.
| |
Imports System.Data Imports System.Data.SqlClient Imports System.Xml Imports System.IO Sub ValidateSchema() ' Purpose: Demonstrate how to validate a DataSet using an XSD Schema Dim objDB As Apress.Database Dim strConn, strJSScript As String Dim arrParams() As String Dim sqlDS As DataSet Try ' Step 1: Instance a new Database object strConn = ConfigurationSettings.AppSettings("ConnectionString") objDB = New Apress.Database(strConn) ' Step 2: Load Products into DataSet [ProductList] arrParams = New String() {} sqlDS = objDB.ExecSPReturnDS("ProductList", arrParams) ' Step 3: Write out the DataSet Schema to an XSD file Dim xsdFile As File If xsdFile.Exists("c:\temp\products.xsd") Then _ xsdFile.Delete("c:\temp\products.xsd") Dim sw As StreamWriter sw = New StreamWriter("c:\temp\products.xsd") sqlDS.Namespace = "urn:products-schema" ' Assign a namespace sw.Write(sqlDS.GetXmlSchema) sw.Close() ' Step 4: Read the XSD file into a StreamReader object Dim myStreamReader As StreamReader = New _ StreamReader("c:\temp\products.xsd") ' Step 5: Create a blank DataSet and load the XSD schema file Dim sqlDS2 As DataSet = New DataSet() sqlDS2.ReadXmlSchema(myStreamReader) ' Step 6A: Manually add a product correctly (required fields only) Dim dr As DataRow = sqlDS2.Tables(0).NewRow dr("ProductID") = 200 dr("ProductName") = "Red Hot Salsa" dr("Discontinued") = False sqlDS2.Tables(0).Rows.Add(dr) ' Step 6B: Manually add a product incorrectly (Set ProductID to a string) dr = sqlDS2.Tables(0).NewRow dr("ProductID") = "XJ8" ' expected type is Int32: this assignment will fail dr("ProductName") = "Red Hot Salsa" dr("Discontinued") = False sqlDS2.Tables(0).Rows.Add(dr) Catch sqlError As SqlException ' Error handling code goes here Response.Write(sqlError.Message) Finally objDB = Nothing End Try End Sub | |
In Steps 1 and 2, a DataSet object gets populated with the available products in the Northwind database, using the ProductList stored procedure created for the previous example. In Steps 3 and 4, the XSD schema information is written out to a file called products.xsd . The schema is generated using the DataSet object's GetXmlSchema() method. Notice that the code provides a target name-space called urn:products-schema to uniquely identify this schema. In Step 5, an empty DataSet object is created and is loaded with the XSD schema file that was just generated. Step 6A demonstrates how to add a valid new product record. Step 6B attempts to add a new record that is invalid. The ProductID field has an Int32 data type, but in Step 6B, the field gets assigned a string value. The following SqlException error gets raised when Step 6B attempts to execute:
Couldn't store <XJ8> in ProductID Column. Expected type is Int32.
Extended Validation Using the XmlValidatingReader Class
There are different variations on how you can perform validation using an XSD schema file. The System.Xml.Schema namespace provides a class called XmlValidatingReader that validates an XML file against one or more XSD namespaces. In this example, there are actually three schema namespaces that are used in the construction of the XML file:
-
urn:products-schema
-
http://www.w3.org/2001/XMLSchema
-
urn:schemas-microsoft-com:xml-msdata
The first namespace, urn:products-schema , is the custom namespace created to represent the Products table. The second namespace (ending in XMLSchema ) is a standard namespace that must be included in all XSD schema files. Finally, the third namespace is Microsoft specific and describes the NewDataSet element, among other things.
The XmlValidatingReader class is not straightforward to use because it provides a large number of properties that can be set in many different combinations. We will not discuss the class in any detail here because we would require an entire chapter to do the subject justice . Suffice it to say that the .NET Framework provides a large number of classes for working with XML and XSD, including classes that will validate well-formed XML documents against multiple XSD schemas.
| Note | You can read more about the XmlValidatingReader class, and XSD validation in general, using .NET, at http://msdn.microsoft.com/library/en-us/cpguide/html/cpconvalidationofxmlwithxmlvalidatingreader.asp . |
Now let's turn our attention to typed DataSets, which represent another interesting example of XML integration with the DataSet object.
Typed DataSets
A typed DataSet is a class that inherits from the DataSet object and incorporates a specific XSD schema. A typed DataSet is essentially a special compilation of the DataSet object that is bound to a specific structure, represented by the XSD schema. As such, all the DataSet methods, events, and properties are available in the typed DataSet object. Additionally, a typed DataSet provides strongly typed methods, events, and properties for the schema information.
You have already seen how to generate an XSD file programmatically. Visual Studio .NET provides another option for generating these files. You can use the Visual Studio Component Designer tool to generate an XSD schema from a database table or stored procedure with the following steps:
-
In the ASP.NET application, add a DataSet item to the Components directory. You will see a new .xsd file in the Components directory.
-
Open the Server Explorer and add a data connection to your database.
-
Drag and drop the table or stored procedure from the Server Explorer to the DataSet form. The Component Designer will populate the XSD schema into the .xsd file.
Once you save the .xsd file, the XSD schema becomes automatically recognized as a valid data type that you can reference programmatically. The AspNetChap3 sample project provide an example, which includes the dsCustOrderHist typed DataSet. This has been generated and stored in the dsCustOrderHist.xsd file.
Keep in mind that a typed DataSet is not automatically a populated DataSet object. By creating a typed DataSet you have actually generated a new class that forms the shell of a schema-specific, populated DataSet. For example, you can use the DataAdapter Fill() method to write data to the typed DataSet in the same way as you would to an untyped DataSet. This is an example showing how you can fill the custom dsCustOrderHist typed DataSet created earlier:
' Create a new Typed DataSet object Dim sqlDS As New dsCustOrderHist () Try Dim sqlAdapt As SqlDataAdapter = New SqlDataAdapter(sqlCmd) m_sqlConn.Open() sqlAdapt.Fill(sqlDS, "CustOrderHist") m_sqlConn.Close() Finally End Try
A typed DataSet object allows access to tables and columns by name, instead of using collection-based methods, as shown in this code:
sqlDS = objDB.ExecSPReturnDS("CustOrderHist", arrParams) 'Read the row values by name For Each myRow In sqlDS1.CustOrderHist.Rows strResults = strResults & (myRow.ProductName.ToString) & ""& _ (myRow.Total.ToString) & vbCrLf Next myRow For a regular DataSet, the line inside the For...Next loop would have read as follows:
strResults = strResults & (myRow("ProductName")) & ""&_ (myRow("Total")) & vbCrLf This may not seem like a huge difference until you consider that typed DataSet properties, such as ProductName , show up in Visual Studio's IntelliSense viewer. For untyped DataSets the developer must manually type the name of the field index. In this case, simple spelling errors in the field name can cause runtime errors. So, not only does a typed DataSet improve the readability of code, but it makes it easier to write and allows the Visual Studio .NET code editor to catch exceptions related to invalid casting at compilation time rather than at runtime.
| Note | Although you do not have to include the table name when calling the Fill() method for an untyped DataSet, you must include the table name defined in the XSD schema when filling a typed DataSet. If the table name is not included, then the filled DataSet will contain two tables, one with the generic name of "Table" that contains all the data and the second empty table defined with the name in the XSD schema ("CustOrderHist" in our sample). |
The DiffGram Format
A DiffGram is simply a specialized XML format that tracks original and current data values in a DataSet. Microsoft outlines the DiffGram format in this schema:
urn:schemas-microsoft-com:xml-diffgram-v1
DataSets can both generate DiffGrams and load them. For example, if you modify data in a DataSet, you can then generate a DiffGram that records the original and current (modified) values. The DiffGram can be loaded into another DataSet, which can then re-create the original and current values, as well as the row order and any row-level errors due to updates. One thing a DiffGram does not do is preserve schema information. You will need to transport this information in a separate file. Note that Web service methods that return DataSets will automatically use the DiffGram format.
The sole purpose of the DiffGram format is to provide an XML format for transporting DataSet update information. DiffGrams carry a large footprint because they include multiple XML records for each actual data record. You may never need to use DiffGrams directly, and in fact, you should use them sparingly. Because Web service methods automatically use the DiffGram format, you should never return DataSets directly from Web services unless you specifically need to do so.
| Note | You can read more about the DataSet and XML, including DiffGrams, at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconxmldataset.asp . |
Using the DataView Class
The DataView class deserves special mention because it is useful for optimizing data access code. The DataView class holds a customized and optimized view of a DataSet. The DataView does not carry the high overhead of the DataSet object because it does not preserve the same level of information. Yet you can still use it for complex operations such as sorting, filtering, searching, editing, and navigating. For example, if you need to bind a subset of a DataSet to a grid, then the DataView object can capture the exact subset. You can then bind the DataView object, as opposed to the entire DataSet object.
You can create a DataView either by referencing the DefaultView property of a DataTable or by using the DataView constructor. This is how you establish a reference to the DefaultView:
Dim sqlDV As DataView Dim sqlDS As DataSet ' Assume that the DataSet object is populated sqlDV = sqlDS.Tables(0).DefaultView
The constructor for the DataView can be empty, or it can accept a DataTable along with filter criteria, sort criteria, and a row state filter:
myView = New DataView(Table As System.Data.DataTable, RowFilter As String, _ Sort As String, RowState As System.Data.DataViewRowState)
You can create multiple, distinct DataViews for the same DataTable. This is helpful if you need to represent data from the same DataTable source in different ways.
As an example, let's look at the code from ExecSPReturnDS.aspx in the sample project (specifically, the GetDVBindDG() method). Listing 3-6 retrieves the CustOrderHist dataset, which contains the total number of products ordered by each customer. Let's say you are only interested in seeing customers who ordered more than 15 products. You can use a DataView to create a filtered view of the CustOrderHist dataset.
| |
Dim myView As DataView Try objDB = New Apress.Database(strConn) arrParams = New String() {"@CustomerID", SqlDbType.Char, "ALFKI"} sqlDS = objDB.ExecSPReturnDS("CustOrderHist", arrParams) myView = New DataView(sqlDS.Tables(0), "Total>15", "Total", _ DataViewRowState.CurrentRows) ' Bind the DataView to the DataGrid DataGrid1.DataSource = myView DataGrid1.DataBind() Finally End Try | |
You can make changes to the DataView using the AddNew() and Delete() methods. The RowState filter property tracks changes to the DataView and lets you create yet another filtered view of the data. For example, this is how you filter the DataView to show new or deleted rows only:
' Set the RowStateFilter to display only Added and Deleted rows. myView.RowStateFilter = DataViewRowState.Added Or DataViewRowState.Deleted
You can also cache the DataView in memory, which makes it an excellent alternative to the DataSet for situations where you need to hold the data in memory but want to use as little memory as possible.
Using the SqlException Class
Data access programming is vulnerable to exceptions because there are many factors that can cause issues, including database errors, improperly formatted queries, and timeouts. The .NET Framework provides specialized exception classes for handling and interpreting data access errors. The SQL Server .NET Managed Provider provides the SqlException class, which specifically handles SQL errors. This class is derived from the standard Exception class and provides a similar interface.
The SqlException object actually exposes a collection of one or more SQL errors, each of which is encapsulated by a SqlError object. You can reference the collection directly, as a SqlErrorCollection object, or indirectly, via the SqlException object's Errors property.
Listing 3-7 comes from ShowSQLExceptions.aspx and shows how you can trap for, and iterate through, a collection of SQL errors.
| |
Sub CreateSqlException() Try ' Execute data access code Catch err As SqlException ' SQL Error handling code goes here Dim i As Integer Dim sqlErr As SqlError For i = 0 To err.Errors.Count - 1 sqlErr = err.Errors(i) Response.Write("Error #" & sqlErr.Number & ": "& _ err.Message & "<BR>") Next i If m_sqlconn.State = ConnectionState.Open Then m_sqlconn.Close() Catch err2 As Exception ' Standard exception handler here Finally m_sqlconn = Nothing objDB = Nothing End Try End Sub | |
For example, if you call a nonexistent stored procedure, you will get the following exception:
Error #2812: Could not find stored procedure 'ProductList2'.
It is interesting to note the effect of a SQL error on the state of the connection to the database. Every error is associated with a severity level, and the SqlConnection object will automatically close if an error is raised with a severity level of 20 or greater. Be sure to always check the connection state in your error handler and to close it if it is still open. We prefer this approach to evaluating the severity level because open SQL connections may cause downstream exceptions that are difficult or impossible to handle. Finally, notice Listing 3-7 includes a second, standard exception handler. The SqlException handler will trap only SQL errors, so to be safe you should always include a handler for the standard Exception class. This will trap all exceptions that the SqlException handler does not.
The SqlException class provides other properties not covered here, including a Source property. This will provide the detailed call stack that led to the error. This information is useful for developers but bewildering for end users, so our approach is to write the source information to a private application event log and suppress it from the end user's view. In closing, make sure you always implement the provider-specific exception class in your data access code. The OleDbException class holds errors for OLE DB data sources just as the SqlException class holds errors for SQL Server data sources.
EAN: 2147483647
Pages: 91