Chapter 18. Document Object Model (DOM)
| CONTENTS |
|
The Document Object Model (DOM) defines an API for accessing and manipulating XML documents as tree structures. The DOM is defined by a set of W3C Recommendations that describe a programming language-neutral object model used to store hierarchical documents in memory. The most recently completed standard, DOM Level 2, provides models for manipulating XML documents, HTML documents, and CSS stylesheets. This chapter covers only the parts of the DOM that are applicable to processing XML documents.
This chapter is based on the Document Object Model (DOM) Level 2 Core Specification, which was released on November 13, 2000. This version of the recommendation, along with any errata that have been reported, is available on the W3C web site (http://www.w3.org/TR/DOM-Level-2-Core/ ). At the time of this writing, the latest DOM Level 3 Core working draft had been released on January 14, 2002. The working draft corrects omissions and deficiencies in the Level 2 recommendation and includes some basic support for integrating validation into DOM API document manipulation. Additional modules of DOM Level 3 add support for content models (DTDs and schemas), as well as support for loading and saving XML into and out of DOM.
18.1 DOM Foundations
At its heart, the DOM is a set of APIs. Various DOM implementations use their own objects to support the interfaces defined in the DOM specification. The DOM interfaces themselves are specified in modules, making it possible for implementations to support parts of the DOM without having to support all of it. XML parsers, for instance, aren't required to provide support for the HTML-specific parts of the DOM, and modularization has provided a simple mechanism that allows software developers to identify which parts of the DOM are supported or are not supported by a particular implementation.
Successive versions of the DOM are defined as levels. The Level 1 DOM was the W3C's first release, and it focused on working with HTML and XML in a browser context. Effectively, it supported dynamic HTML and provided a base for XML document processing. Because it expected documents to exist already in a browser context, Level 1 only described an object structure and how to manipulate it, not how to load a document into that structure or reserialize a document from that structure.
Subsequent levels have added functionality. DOM Level 2, which was published as a set of specifications, one per module, includes updates for the Core and HTML modules of Level 1, as well as new modules for Views, Events, Style, Traversal, and Range. DOM Level 3 will add Abstract Schemas, Load, Save, XPath, and updates to the Core and Events modules.
Other W3C specifications have defined extensions to the DOM particular to their own needs. Mathematical Markup Language (MathML), Scalable Vector Graphics (SVG), Synchronized Multimedia Integration Language (SMIL), and SMIL Animation have all defined DOMs that provide access to details of their own vocabularies.
|

Developers using the DOM for XML processing typically rely on the Core module as the foundation for their work.
18.1.1 DOM Notation
The Document Object Model is intended to be operating system- and language- neutral; therefore, all DOM interfaces are specified using the Interface Description Language (IDL) notation defined by the Object Management Group organization (http://www.omg.org). To conform to the language of the specification, this chapter and Chapter 24 will use IDL terminology when discussing interface specifics. For example, the word "attribute" in IDL-speak refers to what would be a member variable in C++. This should not be confused with the XML term "attribute," which is a name-value pair that appears within an element's start-tag.
The language-independent IDL interface must then be translated (according to the rules set down by the OMG) into a specific language binding. Take the following interface, for example:
interface NodeList { Node item(in unsigned long index); readonly attribute unsigned long length; }; This interface would be expressed as a Java interface like this:
package org.w3c.dom; public interface NodeList { public Node item(int index); public int getLength( ); } The same interface would be described for ECMAScript this way:
Object NodeList The NodeList object has the following properties: length This read-only property is of type Number. The NodeList object has the following methods: item(index) This method returns a Node object. The index parameter is of type Number. Note: This object can also be dereferenced using square bracket notation (e.g. obj[1]). Dereferencing with an integer index is equivalent to invoking the item method with that index.
The tables in this chapter represent the information DOM presents as IDL conveying both the available features and when they became available. DOM implementations vary in their implementation of these features be sure to check the document of the implementation you choose for details on how precisely it supports the DOM interfaces.
18.1.2 DOM Strengths and Weaknesses
Like all programming tools, the DOM is better for addressing some classes of problems than others. Since the DOM object hierarchy stores references between the various nodes in a document, the entire document must be read and parsed before it is available to a DOM application. This step also demands that the entire document be stored in memory, often with a significant amount of overhead. Some early DOM implementations required many times the original document's size when stored in memory. This memory usage model makes DOM unsuitable for applications that deal with very large documents or have a need to perform some intermediate processing on a document before it has been completely parsed.
However, for applications that require random access to different portions of a document at different times or applications that need to modify the structure of an XML document on the fly, DOM is one of the most mature and best-supported technologies available.
18.2 Structure of the DOM Core
The DOM Core interfaces provide generic access to all supported document content types. For example, the DOM defines a set of HTML-specific interfaces that expose specific document structures, such as tables, paragraphs, and <img> elements, directly. Besides using these specialized interfaces, you can access the same information using the generic interfaces defined in the core.
Since XML is designed as a venue for creating new, unique, structured markup languages, standards bodies cannot define application-specific interfaces in advance. Instead, the DOM Core interfaces are provided to manipulate document elements in a completely application-independent manner.
The DOM Core is further segregated into the Fundamental and Extended Interfaces. The Fundamental Interfaces are relevant to both XML and HTML documents, whereas the Extended Interfaces deal with XML-only document structures, such as entity declarations and processing instructions. All DOM Core interfaces are derived from the Node interface, which provides a generic set of interfaces for accessing a document or document fragment's structure and content.
18.2.1 Generic Versus Specific DOM Interfaces
To simplify different types of document processing and enable efficient implementation of DOM by some programming languages, there are actually two distinct methods for accessing a document tree from within the DOM Core: through the generic Node interface and through specific interfaces for each node type. Although there are several distinct types of markup that may appear within an XML document (elements, attributes, processing instructions, and so on), the relationships between these different document features can be expressed as a typical hierarchical tree structure. Elements are linked to both their predecessors and successors, as well as their parent and child nodes. Although there are many different types of nodes, the basic parent, child, and sibling relationships are common to everything in an XML document.
The generic Node interface captures the minimal set of attributes and methods that are required to express this tree structure. A given Node contains all of the tree pointers required to locate its parent node, child nodes, and siblings. The next section describes the Node interface in detail.
In addition to the generic Node interface, the DOM also defines a set of XML-specific interfaces that represent distinct document features, such as elements, attributes, processing instructions, and so on. All of the specific interfaces are derived from the generic Node interface, which means that a particular application can switch methods for accessing data within a DOM tree at will by casting between the generic Node interface and the actual specific object type it represents. Section 18.4 later in this chapter discusses the specific interfaces and their relationship to the generic Node interface.
18.3 Node and Other Generic Interfaces
The Node interface is the DOM Core class hierarchy's root. Though never instantiated directly, it is the root interface of all specific interfaces, and you can use it to extract information from any DOM object without knowing its actual type. It is possible to access a document's complete structure and content using only the methods and properties exposed by the Node interface. As shown in Table 18-1, this interface contains information about the type, location, name, and value of the corresponding underlying document data.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| DOMString | nodeName | | ||
| DOMString | nodeValue | |||
| Short | Unsigned type | | ||
| Node | parentNode | | ||
| NodeList | childNodes | | ||
| Node | firstChild | | ||
| Node | lastChild | | ||
| Node | previousSibling | | ||
| Node | nextSibling | | ||
| NamedNodeMap | attributes | | ||
| Document | ownerDocument | | | |
| DOMString | namespaceURI | | | |
| DOMString | Prefix | | ||
| DOMString | localName | | | |
| Methods | ||||
| Boolean | hasAttributes | | ||
| Node | insertBefore | |||
| Node | newChild | |||
| Node | refChild | |||
| Node | replaceChild | |||
| Node | newChild | |||
| Node | oldChild | |||
| Node | removeChild | |||
| Node | oldChild | |||
| Node | appendChild | |||
| Node | newChild | |||
| Boolean | hasChildNodes | |||
| Node | cloneNode | |||
| Boolean | Deep | |||
| Void | normalize | | ||
| Boolean | isSupported | | ||
| DOMString | Feature | | ||
| DOMString | Version | |
Since the Node interface is never instantiated directly, the nodeType attribute contains a value that indicates the given instance's specific object type. Based on the nodeType, it is possible to cast a generic Node reference safely to a specific interface for further processing. Table 18-2 shows the node type values and their corresponding DOM interfaces, and Table 18-3 shows the values they provide for nodeName, nodeValue, and attributes attributes.
| Node type | DOM interface |
|---|---|
| ATTRIBUTE_NODE | Attr |
| CDATA_SECTION_NODE | CDATASection |
| COMMENT_NODE | Comment |
| DOCUMENT_FRAGMENT_NODE | DocumentFragment |
| DOCUMENT_NODE | Document |
| DOCUMENT_TYPE_NODE | DocumentType |
| ELEMENT_NODE | Element |
| ENTITY_NODE | Entity |
| ENTITY_REFERENCE_NODE | EntityReference |
| NOTATION_NODE | Notation |
| PROCESSING_INSTRUCTION_NODE | ProcessingInstruction |
| TEXT_NODE | Text |
| Node type | nodeName | nodeValue | Attributes |
|---|---|---|---|
| ATTRIBUTE_NODE | att name | att value | null |
| CDATA_SECTION_NODE | #cdata-section | content | null |
| COMMENT_NODE | #comment | content | null |
| DOCUMENT_FRAGMENT_NODE | #document-fragment | null | null |
| DOCUMENT_NODE | #document | null | null |
| DOCUMENT_TYPE_NODE | document type name | null | null |
| ELEMENT_NODE | tag name | null | NamedNodeMap |
| ENTITY_NODE | entity name | null | null |
| ENTITY_REFERENCE_NODE | name of entity referenced | null | null |
| NOTATION_NODE | notation name | null | null |
| PROCESSING_INSTRUCTION_NODE | target | content excluding the target | null |
| TEXT_NODE | #text | content | null |
Note that the nodeValue attribute returns the contents of simple text and comment nodes, but returns nothing for elements. Retrieving the text of an element requires inspecting the text nodes it contains.
18.3.1 The NodeList Interface
The NodeList interface provides access to the ordered content of a node. Most frequently, it is used to retrieve text nodes and child elements of element nodes. See Table 18-4 for a summary of the NodeList interface.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| Long | length | | ||
| Methods | ||||
| Node | item | |||
| Long | index |
The NodeList interface is extremely basic and is generally combined with a loop to iterate over the children of a node.
18.3.2 The NamedNodeMap Interface
The NamedNodeMap interface is used for unordered collections whose contents are identified by name. In practice, this interface is used to access attributes. See Table 18-5 for a summary of the NamedNodeMap interface.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| Long | length | | ||
| Methods | ||||
| Node | getNamedItem | |||
| DOMString | name | |||
| Node | setNamedItem | |||
| Node | arg | |||
| Node | removeNamedItem | |||
| DOMString | name | |||
| Node | getNamedItemNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| Node | setNamedItemNS | | ||
| Node | arg | | ||
| Node | removeNamedItemNS | |||
| DOMString | namespaceURI | | ||
| DOMString | localName | |
18.3.3 Relating Document Structure to Nodes
Although the DOM doesn't specify an interface to cause a document to be parsed, it does specify how the document's syntax structures are encoded as DOM objects. A document is stored as a hierarchical tree structure, with each item in the tree linked to its parent, children, and siblings:
<sample bogus="value"><text_node>Test data.</text_node></sample>
Figure 18-1 shows how the preceding short sample document would be stored by a DOM parser.
Figure 18-1. Document storage and linkages
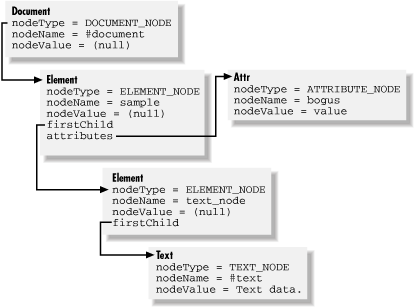
Each Node-derived object in a parsed DOM document contains references to its parent, child, and sibling nodes. These references make it possible for applications to enumerate document data using any number of standard tree-traversal algorithms. "Walking the tree" is a common approach to finding information stored in a DOM and is demonstrated in Example 18-1 at the end of this chapter.
18.4 Specific Node-Type Interfaces
Though it is possible to access the data from the original XML document using only the Node interface, the DOM Core provides a number of specific node-type interfaces that simplify common programming tasks. These specific node types can be divided into two broad types: structural nodes and content nodes.
18.4.1 Structural Nodes
Within an XML document, a number of syntax structures exist that are not formally part of the content. The following interfaces provide access to the portions of the document that are not related to character or element data.
18.4.1.1 DocumentType
The DocumentType interface provides access to the XML document type definition's notations, entities, internal subset, public ID, and system ID. Since a document can have only one !DOCTYPE declaration, only one DocumentType node can exist for a given document. It is accessed via the doctype attribute of the Document interface. The definition of the DocumentType interface is shown in Table 18-6.
| Type | Name | Read-only | DOM 2.0 |
|---|---|---|---|
| Attributes | |||
| NamedNodeMap | entities | | |
| DOMString | name | | |
| NamedNodeMap | notations | | |
| DOMString | publicId | | |
| DOMString | systemId | | |
Using additional fields available from DOM Level 2, it is now possible to fully reconstruct a parsed document using only the information provided with the DOM framework. No programmatic way to modify DocumentType node contents currently exists.
18.4.1.2 ProcessingInstruction
This node type provides direct access to an XML name processing instruction's contents. Though processing instructions appear in the document's text, they may also appear before or after the root element, as well as in DTDs. Table 18-7 describes the ProcessingInstruction node's attributes.
| Type | Name | Read-only | DOM 2.0 |
|---|---|---|---|
| Attributes | |||
| DOMString | data | ||
| DOMString | target | |
Though processing instructions resemble normal XML tags, remember that the only syntactically defined part is the target name, which is an XML name token. The remaining data (up to the terminating >) is free-form. See Chapter 17 for more information about uses (and potential misuses) of XML processing instructions.
18.4.1.3 Notation
XML notations formally declare the format for external unparsed entities and processing instruction targets. The list of all available notations is stored in a NamedNodeMap within the document's DOCTYPE node, which is accessed from the Document interface. The definition of the Notation interface is shown in Table 18-8.
| Type | Name | Read-only | DOM 2.0 |
|---|---|---|---|
| Attributes | |||
| DOMString | publicId | | |
| DOMString | systemId | |
18.4.1.4 Entity
The name of the Entity interface is somewhat ambiguous, but its meaning becomes clear when it is connected with the EntityReference interface, which is also part of the DOM Core. The Entity interface provides access to the entity declaration's notation name, public ID, and system ID. Parsed entity nodes have childNodes, while unparsed entities have a notationName. The definition of this interface is shown in Table 18-9.
| Type | Name | Read-only | DOM 2.0 |
|---|---|---|---|
| Attributes | |||
| DOMString | notationName | | |
| DOMString | publicId | | |
| DOMString | systemId | |
All members of this interface are read-only and cannot be modified at runtime.
18.4.2 Content Nodes
The actual data conveyed by an XML document is contained completely within the document element. The following node types map directly to the XML document's nonstructural parts, such as character data, elements, and attribute values.
18.4.2.1 Document
Each parsed document causes the creation of a single Document node in memory. (Empty Document nodes can be created through the DOMImplementation interface.) This interface provides access to the document type information and the single, top-level Element node that contains the entire body of the parsed document. It also provides access to the class factory methods that allow an application to create new content nodes that were not created by parsing a document. Table 18-10 shows all attributes and methods of the Document interface.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| DocumentType | doctype | | ||
| DOMImplementation | implementation | | ||
| Element | documentElement | | ||
| Methods | ||||
| Attr | createAttribute | |||
| DOMString | name | |||
| Attr | createAttributeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | qualifiedName | | ||
| CDATASection | createCDATASection | |||
| DOMString | data | |||
| Comment | createComment | |||
| DOMString | data | |||
| DocumentFragment | createDocumentFragment | |||
| Element | createElement | |||
| DOMString | tagName | |||
| Element | createElementNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | qualifiedName | | ||
| EntityReference | createEntityReference | |||
| DOMString | name | |||
| ProcessingInstruction | createProcessingInstruction | |||
| DOMString | target | |||
| DOMString | data | |||
| Text | createTextNode | |||
| DOMString | data | |||
| Element | getElementById | | ||
| DOMString | elementId | |||
| NodeList | getElementsByTagName | |||
| DOMString | tagname | |||
| NodeList | getElementsByTagNameNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| Node | importNode | | ||
| Node | importedNode | | ||
| Boolean | deep | |
The various create...( ) methods are important for applications that wish to modify the structure of a document that was previously parsed. Note that nodes created using one Document instance may only be inserted into the document tree belonging to the Document that created them. DOM Level 2 provides a new importNode( ) method that allows a node, and possibly its children, to be essentially copied from one document to another.
Besides the various node-creation methods, some methods can locate specific XML elements or lists of elements. The getElementsByTagName( ) and getElementsByTagNameNS( ) methods return a list of all XML elements with the name, and possibly namespace, specified. The getElementById( ) method returns the single element with the given ID attribute.
18.4.2.2 DocumentFragment
Applications that allow real-time editing of XML documents sometimes need to temporarily park document nodes outside the hierarchy of the parsed document. A visual editor that wants to provide clipboard functionality is one example. When the time comes to implement the cut function, it is possible to move the cut nodes temporarily to a DocumentFragment node without deleting them, rather than having to leave them in place within the live document. Then when they need to be pasted back into the document, they can be moved back. The DocumentFragment interface, derived from Node, has no interface-specific attributes or methods.
18.4.2.3 Element
Element nodes are the most frequently encountered node type in a typical XML document. These nodes are parents for the Text, Comment, EntityReference, ProcessingInstruction, CDATASection, and child Element nodes that comprise the document's body. They also allow access to the Attr objects that contain the element's attributes. Table 18-11 shows all attributes and methods supported by the Element interface.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| DOMString | tagName | | ||
| Methods | ||||
| DOMString | getAttribute | |||
| DOMString | name | |||
| Attr | getAttributeNode | |||
| DOMString | name | |||
| Attr | getAttributeNodeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| DOMString | getAttributeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| NodeList | getElementsByTagName | |||
| DOMString | name | |||
| NodeList | getElementsByTagNameNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| Boolean | hasAttribute | | ||
| DOMString | name | | ||
| Boolean | hasAttributeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| Void | removeAttribute | |||
| DOMString | name | |||
| Attr | removeAttributeNode | |||
| Attr | oldAttr | |||
| Attr | removeAttributeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | localName | | ||
| Void | setAttribute | |||
| DOMString | name | |||
| Attr | setAttributeNode | |||
| Attr | newAttr | |||
| Attr | setAttributeNodeNS | |||
| Attr | newAttr | |||
| Attr | setAttributeNS | | ||
| DOMString | namespaceURI | | ||
| DOMString | qualifiedName | | ||
| DOMString | value | |
18.4.2.4 Attr
Since XML attributes may contain either text values or entity references, the DOM stores element attribute values as Node subtrees. The following XML fragment shows an element with two attributes:
<!ENTITY bookcase_pic SYSTEM "bookcase.gif" NDATA gif> <!ELEMENT picture EMPTY> <!ATTLIST picture src ENTITY #REQUIRED alt CDATA #IMPLIED> . . . <picture src="bookcase_pic" alt="3/4 view of bookcase"/>
The first attribute contains a reference to an unparsed entity; the second contains a simple string. Since the DOM framework stores element attributes as instances of the Attr interface, a few parsers make the contents of attributes available as actual subtrees of Node objects. In this example, the src attribute would contain an EntityReference object instance. Note that the nodeValue of the Attr node gives the flattened text value from the Attr node's children. Table 18-12 shows the attributes and methods supported by the Attr interface.
| Type | Name | Read-only | DOM 2.0 |
|---|---|---|---|
| Attributes | |||
| DOMString | name | | |
| Element | ownerElement | | |
| Boolean | specified | | |
| DOMString | value |
Besides the attribute name and value, the Attr interface exposes the specified flag that indicates whether this particular attribute instance was included explicitly in the XML document or inherited from the !ATTLIST declaration of the DTD. There is also a back pointer to the Element node that owns this attribute object.
18.4.2.5 CharacterData
Several types of data within a DOM node tree represent blocks of character data that do not include markup. CharacterData is an abstract interface that supports common text-manipulation methods that are used by the concrete interfaces Comment, Text, and CDATASection. Table 18-13 shows the attributes and methods supported by the CharacterData interface.
| Type | Name | Read-only | DOM 2.0 | |
|---|---|---|---|---|
| Attributes | ||||
| DOMString | data | |||
| Unsigned long | length | | ||
| Methods | ||||
| Void | appendData | |||
| DOMString | arg | |||
| Void | deleteData | |||
| Unsigned long | offset | |||
| Unsigned long | count | |||
| Void | insertData | |||
| Unsigned long | offset | |||
| DOMString | arg | |||
| Void | replaceData | |||
| Unsigned long | offset | |||
| Unsigned long | count | |||
| DOMString | arg |
18.4.2.6 Comment
DOM parsers are not required to make the contents of XML comments available after parsing, and relying on comment data in your application is poor programming practice at best. If your application requires access to metadata that should not be part of the basic XML document, consider using processing instructions instead. The Comment interface, derived from CharacterData, has no interface-specific attributes or methods.
18.4.2.7 EntityReference
If an XML document contains references to general entities within the body of its elements, the DOM-compliant parser may pass these references along as EntityReference nodes. This behavior is not guaranteed because the parser is free to expand any entity or character reference included with the actual Unicode character sequence it represents. The EntityReference interface, derived from Node, has no interface-specific attributes or methods.
18.4.2.8 Text
The character data of an XML document is stored within Text nodes. Text nodes are children of either Element or Attr nodes. After parsing, every contiguous block of character data from the original XML document is translated directly into a single Text node. Once the document has been parsed, however, it is possible that the client application may insert, delete, and split Text nodes so that Text nodes may be side by side within the document tree. Table 18-14 describes the Text interface.
| Type | Name | DOM 2.0 | ||
|---|---|---|---|---|
| Methods | ||||
| Text | splitText | |||
| Unsigned long | offset |
The splitText method provides a way to split a single Text node into two nodes at a given point. This split would be useful if an editing application wished to insert additional markup nodes into an existing island of character data. After the split, it is possible to insert additional nodes into the resulting gap.
18.4.2.9 CDATASection
CDATA sections provide a simplified way to include characters that would normally be considered markup in an XML document. These sections are stored within a DOM document tree as CDATASection nodes. The CDATASection interface, derived from Text, has no interface-specific attributes or methods.
18.5 The DOMImplementation Interface
This interface could be considered the highest level interface in the DOM. It exposes the hasFeature( ) method, which allows a programmer using a given DOM implementation to detect if specific features are available. In DOM Level 2, it also provides facilities for creating new DocumentType nodes, which can then be used to create new Document instances. Table 18-15 describes the DomImplementation interface.
| Type | Name | DOM 2.0 | ||
|---|---|---|---|---|
| Methods | ||||
| Document | createDocument | | ||
| DOMString | namespaceURI | | ||
| DOMString | qualifiedName | | ||
| DocumentType | doctype | | ||
| DocumentType | createDocumentType | | ||
| DOMString | qualifiedName | | ||
| DOMString | publicId | | ||
| DOMString | systemId | | ||
| Boolean | hasFeature | |||
| DOMString | feature | |||
| DOMString | version |
18.6 Parsing a Document with DOM
Though the DOM standard doesn't specify an actual interface for parsing a document, most implementations provide a simple parsing interface that accepts a reference to an XML document file, stream, or URI. After this interface successfully parses and validates the document (if it is a validating parser), it generally provides a mechanism for getting a reference to the Document interface's instance for the parsed document. The following code fragment shows how to parse a document using the Apache Xerces XML DOM parser:
// create a new parser DOMParser dp = new DOMParser( ); // parse the document and get the DOM Document interface dp.parse("http://www.w3.org/TR/2000/REC-xml-20001006.xml"); Document doc = dp.getDocument( );
|
18.7 A Simple DOM Application
Example 18-1 illustrates how you might use the interfaces discussed in this chapter in a typical programming situation. This application takes a document that uses the furniture.dtd sample DTD from Chapter 20 and validates that the parts list included in the document matches the actual parts used within the document.
Example 18-1. Parts checker application
/** * PartsCheck.java * * DOM Usage example from the O'Reilly _XML in a Nutshell_ book. * */ // we'll use the Apache Software Foundation's Xerces parser. import org.apache.xerces.parsers.*; import org.apache.xerces.framework.*; // import the DOM and SAX interfaces import org.w3c.dom.*; import org.xml.sax.*; // get the necessary java support classes import java.io.*; import java.util.*; /** * This class is designed to check the parts list of an XML document that * represents a piece of furniture for validity. It uses the DOM to * analyze the actual furniture description and then check it against the * parts list that is embedded in the document. */ public class PartsCheck { // static constants public static final String FURNITURE_NS = "http://namespaces.oreilly.com/furniture/"; // contains the true part count, keyed by part number HashMap m_hmTruePartsList = new HashMap( ); /** * The main function that allows this class to be invoked from the command * line. Check each document provided on the command line for validity. */ public static void main(String[] args) { PartsCheck pc = new PartsCheck( ); try { for (int i = 0; i < args.length; i++) { pc.validatePartsList(args[i]); } } catch (Exception e) { System.err.println(e); } } /** * Given a system identifier for an XML document, this function compares * the actual parts used to the declared parts list within the document. It * prints warnings to standard error if the lists don't agree. */ public void validatePartsList(String strXMLSysID) throws IOException, SAXException { // create a new parser DOMParser dp = new DOMParser( ); // parse the document and get the DOM Document interface dp.parse(strXMLSysID); Document doc = dp.getDocument( ); // get an accurate parts list count countParts(doc.getDocumentElement( ), 1); // compare it to the parts list in the document reconcilePartsList(doc); } /** * Updates the true parts list by adding the count to the current count * for the part number given. */ private void recordPart(String strPartNum, int cCount) { if (!m_hmTruePartsList.containsKey(strPartNum)) { // this part isn't listed yet m_hmTruePartsList.put(strPartNum, new Integer(cCount)); } else { // update the count Integer cUpdate = (Integer)m_hmTruePartsList.get(strPartNum); m_hmTruePartsList.put(strPartNum, new Integer(cUpdate.intValue( ) + cCount)); } } /** * Counts the parts referenced by and below the given node. */ private void countParts(Node nd, int cRepeat) { // start the local repeat count at 1 int cLocalRepeat = 1; // make sure we should process this element if (FURNITURE_NS.equals(nd.getNamespaceURI( ))) { Node ndTemp; if ((ndTemp = nd.getAttributes( ).getNamedItem("repeat")) != null) { // this node specifies a repeat count for its children cLocalRepeat = Integer.parseInt(ndTemp.getNodeValue( )); } if ((ndTemp = nd.getAttributes( ).getNamedItem("part_num")) != null) { // start the count at 1 int cCount = 1; String strPartNum = ndTemp.getNodeValue( ); if ((ndTemp = nd.getAttributes( ).getNamedItem("count")) != null) { // more than one part needed by this node cCount = Integer.parseInt(ndTemp.getNodeValue( )); } // multiply the local count by the repeat passed in from the parent cCount *= cRepeat; // add the new parts count to the total recordPart(strPartNum, cCount); } } // now process the children NodeList nl = nd.getChildNodes( ); Node ndCur; for (int i = 0; i < nl.getLength( ); i++) { ndCur = nl.item(i); if (ndCur.getNodeType( ) == Node.ELEMENT_NODE) { // recursively count the parts for the child, using the local repeat countParts(ndCur, cLocalRepeat); } } } /** * This method reconciles the true parts list against the list in the document. */ private void reconcilePartsList(Document doc) { Iterator iReal = m_hmTruePartsList.keySet().iterator( ); String strPartNum; int cReal; Node ndCheck; // loop through all of the parts in the true parts list while (iReal.hasNext( )) { strPartNum = (String)iReal.next( ); cReal = ((Integer)m_hmTruePartsList.get(strPartNum)).intValue( ); // find the part list element in the document ndCheck = doc.getElementById(strPartNum); if (ndCheck == null) { // this part isn't even listed! System.err.println("missing <part_name> element for part #" + strPartNum + " (count " + cReal + ")"); } else { Node ndTemp; if ((ndTemp = ndCheck.getAttributes( ).getNamedItem("count")) != null) { int cCheck = Integer.parseInt(ndTemp.getNodeValue( )); if (cCheck != cReal) { // counts don't agree System.err.println("<part_name> element for part #" + strPartNum + " is incorrect: true part count = " + cReal + " (count in document is " + cCheck + ")"); } } else { // they didn't provide a count for this part! System.err.println("missing count attribute for part #" + strPartNum + " (count " + cReal + ")"); } } } } } When this application is run over the bookcase.xml sample document from Chapter 20, it generates the following output:
missing count attribute for part #HC (count 8) <part_name> element for part #A is incorrect: true part count = 2 (count in document is 1)
To compile and use this sample application, download and install the Xerces Java Parser from the Apache-XML project (http://xml.apache.org/xerces-j). The code was compiled and tested with Sun's JDK Version 1.3.1.
| CONTENTS |
EAN: 2147483647
Pages: 28