So far we've accounted for a little over 300 of the more than 90,000 Unicode characters . Many thousands are still unaccounted for. Outside the ranges defined in XHTML and SGML, standard entity names don't exist. You should either use an editor that can produce the characters you need in the appropriate character set or you should use character references. Most of the 90,000-plus Unicode characters are either Han ideographs, Hangul syllables, or rarely used characters. However, we do list a few of the most useful blocks later in this chapter. Others can be found online at http://www.unicode.org/ charts / or in The Unicode Standard 4.0 by the Unicode Consortium (Addison Wesley).
In the tables that follow, the upper lefthand corner contains the character's hexadecimal Unicode value, and the upper righthand corner contains the character's decimal Unicode value. You can use either value to form a character reference so as to use these characters in element content and attribute values, even without an editor or fonts that support them.
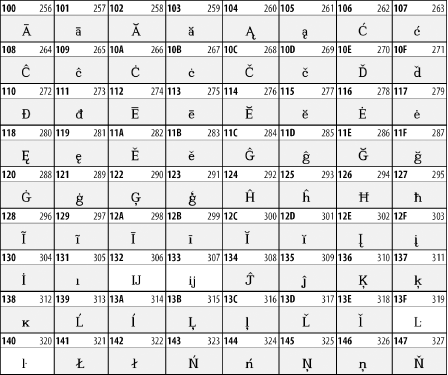
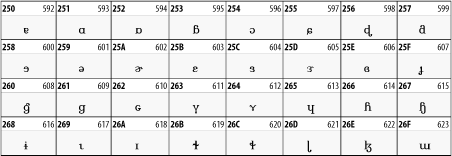
27.3.1 Latin Extended-A
The128 characters in the Latin Extended-A block of Unicode are used in conjunction with the normal ASCII and Latin-1 characters. They cover most European Latin letters missing from Latin-1. The block includes various characters you'll find in the upper halves of the other ISO-8859 Latin character sets, including ISO-8859-2, ISO-8859-3, ISO-8859-4, and ISO-8859-9. When combined with ASCII and Latin-1, this block lets you write Afrikaans, Basque, Breton, Catalan, Croatian, Czech, Esperanto, Estonian, French, Frisian, Greenlandic, Hungarian, Latvian, Lithuanian, Maltese, Polish, Provenal, Rhaeto-Romanic, Romanian, Romany, Sami, Slovak, Slovenian, Sorbian, Turkish, and Welsh. See Table 27-7.
Table 27-7. Unicode's Latin Extended-A block
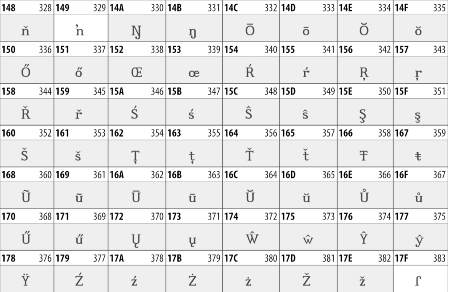
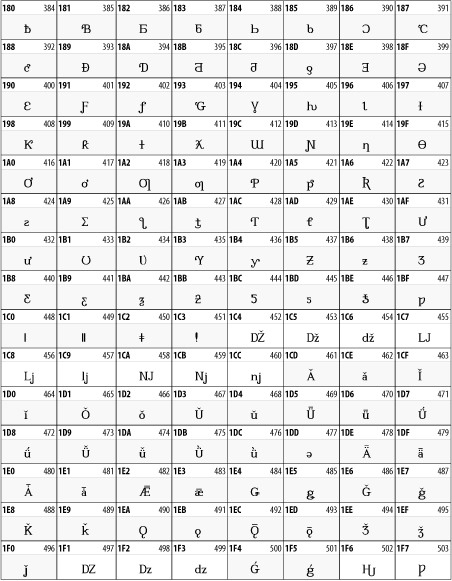
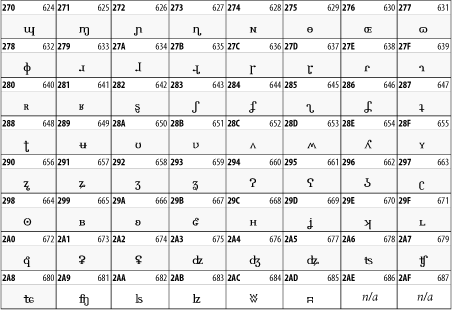
27.3.2 Latin Extended-B
The Latin Extended-B block of Unicode is used in conjunction with the normal ASCII and Latin-1 characters. It mostly contains characters used for transcription of non-European languages not traditionally written in a Roman script. For instance, it's used for the Pinyin transcription of Chinese and for many African languages. See Table 27-8.
Table 27-8. The Latin Extended-B block of Unicode
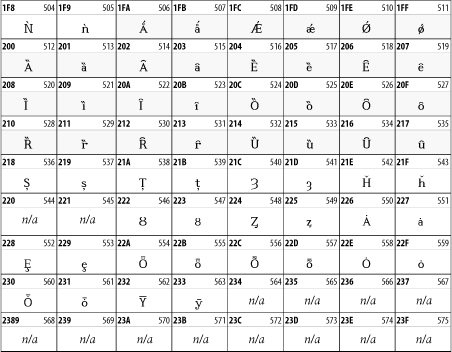
27.3.3 IPA Extensions
Linguists use the International Phonetic Alphabetic (IPA) to identify uniquely and unambiguously particular sounds of various spoken languages. Besides the symbols listed in this block, the IPA requires use of ASCII, various other extended Latin characters, the combining diacritical marks in Table 27-11, and a few Greek letters. The block, shown in Table 27-9, only contains the characters not used in more traditional alphabets.
Table 27-9. The IPA Extensions block of Unicode
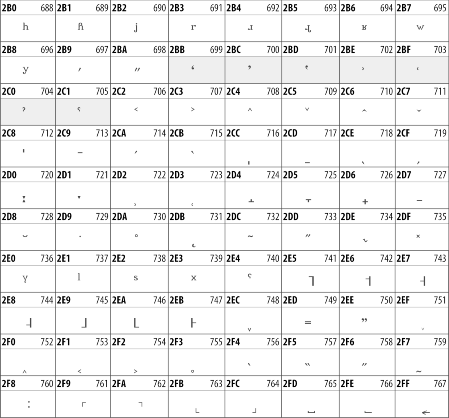
27.3.4 Spacing Modifier Letters
The Spacing Modifier Letters block, shown in Table 27-10, includes characters from multiple languages and scripts that modify the preceding or following character, generally by changing its pronunciation.
Table 27-10. The Spacing Modifier Letters block of Unicode
27.3.5 Combining Diacritical Marks
The Combining Diacritical Marks block contains characters that are not used on their own, such as the accent grave and circumflex. Instead, they are merged with the preceding character to form a single glyph. For example, to write the character