| The complete family of XML specifications has grown so large that it's approaching, and in some cases exceeding , the complexity of the SGML specification it effectively replaced . While XML 1.0 is fairly straightforward and well supported, the complete family of XML + DTDs + Namespaces + XPath + Schemas + XLinks + XPointers + XInclude + Infoset + PSVI + XML 1.1 + Namespaces 1.1 + Kitchen Sink is beginning to show signs of the same interoperability issues that plagued SGML. Most tools support some subset of these technologies. Others support a different, intersecting subset. Few if any tools support all of it. Don't buy into the hype and rumor. Do not feel obligated to include every last member of the XML family in your application. You don't need to use all or even most of this to take advantage of XML. The only parts that are really core are XML 1.0 and Namespaces. Everything else is an option you can use or not as seems appropriate for your application. Even namespaces can be ignored in a pinch . Though I would not go so far as to write markup that was namespace malformed (e.g., that used multiple colons in element names ), you can certainly write regular XML 1.0 that ignores namespaces. Most of the different specifications have their uses. You should absolutely use any of them that help you. Just don't think you have to use all of them. As a rough first approximation , here's a list of which technologies you should consider using when. -
Well- formed XML: Well-formedness is the absolute minimum requirement for any XML-based system. This is the only thing you cannot compromise on. If a document is not well-formed, it is not XML. Do not accept or require tools that support anything less than full well- formedness checking. The RSS community has made this mistake by de facto allowing programs that accept different, non-well-formed variants of XML, and as a result they are already starting to encounter the same interoperability issues that plagued HTML. Different RSS applications can read different RSS sites. While there's a subset of sites all RSS tools can process, no tool that can handle all of them. Don't let this happen to your application. Insist on 100% pure well-formed XML. -
Namespaces: Namespaces are important whenever you expect your vocabulary to either include or be included in other XML vocabularies. They are also very important for public XML applications since, properly used, they indicate to developers who is responsible for any given document they may encounter. Namespaces can be omitted from purely local systems that you don't intend for anyone else to look at or manipulate, such as an in-house application's file format. Nonetheless, it really doesn't hurt to use namespaces, and they do make applications much more robust and extensible in the face of unexpected developments and uses. For the most part, un-namespaced applications like DocBook and XML-RPC are relics of the year or so between the release of XML 1.0 and the release of Namespaces in XML. New applications should use namespaces. (See Item 20.) -
DTDs: DTDs can be helpful. They let you know whether or not any given document adheres to many of the rules of its specification, and they also serve as a useful formal vocabulary for specifying what is and is not allowed, much like a BNF grammar does. However, there are many situations in which they are not appropriate. They tend to limit extensibility. In particular, they don't work well when documents contain lots of unanticipated markup, as in XSLT stylesheets. And since the document itself specifies the DTD it should be validated against, rather than the validating process, DTDs are not a foolproof solution for detecting invalid data. Much useful work can be done without valid documents. I prefer to use DTDs for specification and for simple error checking, but not to rely on them for more important operations. -
Infoset: The XML Information Set began its life as a common data model for XML specifications such as XPath and DOM. However, the working group soon discovered that it was too late to define such a thing. The syntax horse had left the barn. Now the Infoset is nothing more than a collection of definitions for specifications that choose to use them. Using the same names for the same things is a good thing, but don't try to make the Infoset more than this. In particular, avoid the common mistake of believing that an Infoset is somehow more real than the XML document it's derived from. The Infoset is not the true Platonic form of an XML document. XML is Unicode in angle brackets, nothing else. There are no alternate syntaxes. If you can define your processing on Unicode with angle brackets, that's all you need to do. -
PSVI: As Item 25 discusses in more detail, the Post Schema Validation Infoset is even further away from Unicode in angle brackets than the regular Infoset. The PSVI is not XML. Using it instead of XML introduces a number of interoperability and performance hurdles applications must cross to be useful. Design your applications to work with real XML documents, not ethereal information sets, post-schema or otherwise . -
XML 1.1: As Item 3 addresses in more detail, XML 1.1 is useful if and only if you are a native speaker of Amharic, Mongolian, Burmese, Cambodian, or a few other languages. All other users can and should ignore it. -
Schemas: Like DTDs, schemas can be helpful for specification of a language. They're also useful for input checking through validation, more so than DTDs because the process doing the validation gets to choose which schema to apply. (See Item 37.) However, the W3C XML Schema Language is not the only one available and often is not the best choice. (See Item 24.) Furthermore, even if you do choose to write schemas in the W3C XML Schema Language, you must be careful not to assume documents are valid or actually adhere to the schema. Do not capriciously reject invalid documents. Documents often contain useful information, despite being invalid, especially if the part that makes the document invalid has little to do with the information you're trying to extract. In many cases, processes can avoid the overhead of full-fledged schema validation by simply requesting the information they want from a document, perhaps by using XPath (see Item 35), and then attempting to convert it to the form they need. If the conversion succeeds without error, the document is valid enough for that process's current needs. -
Simple XLinks: Simple XLinks are a reasonably straightforward syntax for basic blue underlined things you click on to jump to another page. They can also be used for unidirectional links with other semantics. RDDL (see Item 42) uses them like this. If this is all your application requires, you should use simple XLinks. However, many applications need something more sophisticated that requires them to invent their own vocabulary for linking, and many more don't need links at all. XLink is one of the easier W3C specifications to ignore. -
Extended XLinks: Extended XLinks provide multidirectional, multiended connections between resources in which both the link ends and link connections can be annotated in a variety of ways and in which the links are not necessarily part of the resources they connect. If that sounds like gibberish to you, you're not alone. Extended XLinks have really failed to catch fire. I suspect someone, somewhere is using them for something, but I don't know who; and tool support is almost nonexistent. Almost every developer whose application needs linking beyond what simple XLinks provide has invented a custom syntax and semantics. You should probably do the same. Extended XLinks can be safely ignored. -
XPointer: XPointer is a URL fragment identifier syntax for XML documents based on XPath. It's referenced by a few other specifications including XLink and XInclude. However, it has some severe human-factor problems that have stymied its development. The largest part of XPointer, the xpointer() scheme, did not become a recommendation before the working group's charter expired , and it now seems likely that the W3C has neither the will nor the inclination to continue its development. If you need some means of pointing into an XML document, I suggest sticking with pure XPath instead. -
XInclude: XInclude is a very useful technology for building large documents like books out of smaller documents like chapters. However, it does not normally need to be considered in application design. Instead, each document is normally validated and processed after the inclusions are resolved. Its use (or nonuse) is pretty much transparent to other tools in the processing chain. (See Item 30.) -
SVG: SVG is wonderful when you need to include two-dimensional line art in a document. If you're doing this, use it. If you're not, ignore it. -
MathML: MathML is useful when you're including equations in documents. If you're doing that, use it. If you're not, ignore it. -
RDF and OWL: There seems to be a lot more smoke than fire in the efforts to apply machine-readable semantics to XML through technologies like the Resource Description Framework (RDF) and the Web Ontology Language (OWL). However, despite the tremendous amount of brain power that has been applied to these specifications, I've yet to see any concrete results. There are a few RDF-savvy applications in the world, such as RSS 1.0 and MusicBrainz, but these don't seem to do anything that couldn't be done much more simply with plain- vanilla XML with appropriately chosen tag names. (See Item 27.) It's not clear what, if anything, RDF and its family bring to the party. I'm beginning to suspect there's no there there. Until it's demonstrated that RDF enables anything useful that can't be accomplished with plain-vanilla XML, I suggest you simply ignore these. -
CSS: CSS is useful for displaying XML documents in web browsers. Any XML document that will be shown to people in a web browser can benefit from a CSS stylesheet. However, it's inadequate for any other use, including high-quality printing. The vast majority of XML documents are not displayed in web browsers and have nothing to gain from CSS. -
XSLT and XSL-FO: XSLT and XSL-FO have the advantage of being completely separate from the documents they process. It's rare to even mention them in an application specification whether you intend to use them or not. Whether or not an XSLT stylesheet will be applied to an XML document makes little difference to the document itself. It does not change the markup or design of the application in any way. If anything, the only common effect is indirect: Because you know you can always apply XSLT processing to a document to generate XSL-FO output, you can leave out all presentational information from the vocabularies you design. -
XQuery: Like XSLT, XQuery is a language for processing XML. Also like XSLT, the needs of XQuery really don't affect application design to any significant extent any more than the needs of C# or Python do. XQuery is simply another language with which you can process XML documents in a variety of applications. It does not become a part of the applications themselves . If you like the XQuery language, use it to process XML, but don't feel you have to learn it or use it if you don't want to. To some extent the different specifications do depend on each other. Figure 28-1 charts the dependencies. It's normally possible to ignore any functionality that's above the layer you care about. In some cases, it's even possible to ignore the lower layers . For example, although XPath 2.0 is built on the PSVI, and XSLT 2.0 is built on XPath 2.0, XSLT 2.0 still works on documents that don't have a schema. Its functionality will just be somewhat more limited. (You won't be able to take advantage of schema type information in your stylesheets.) Figure 28-1. Dependencies between XML Specifications 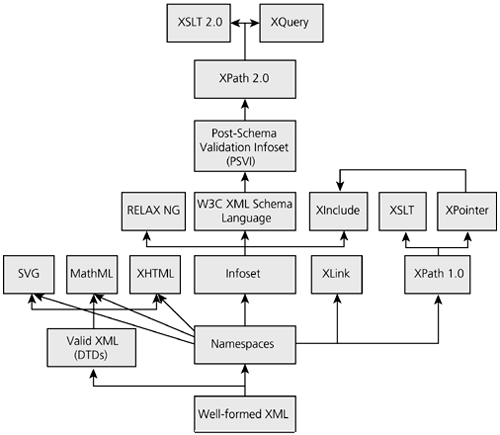 Never feel obligated to use specifications that don't fit your needs. Item 24 suggests that you consider schema languages other than the W3C's official choice. The same applies in other domains as well. Some developers are still doing very effective work with DSSSL instead of XSLT and XSL-FO. The W3C's own XHTML working group rejected XLink in favor of a simpler, homegrown linking syntax. Going your own way does mean you'll have to develop processing tools and techniques that you could otherwise borrow from existing work. You certainly shouldn't reject standard vocabularies purely out of a Not-Invented-Here syndrome. However, sometimes the extra overhead of a technology that does more than you need can cost more than designing a simpler technology yourself from scratch. The ultimate evaluation needs to be made on a case-by-case basis that fits both the requirements of the problem and the skills of the available developers. For example, let's once again revisit the question of a bank account statement. What technologies would it be built on, and what would it ignore? Well-formed XML is where you start, but it's probably not where you stop. Almost by default the bank statement should have a namespace, especially since we earlier established that it would be useful to merge in some basic HTML for the narrative parts of the statements, and maybe even some SVG if the statements contain logos or other art. The next question is whether the application needs a schema and, if so, in what language you should write it. Some schema would be useful to document the agreed-upon format. The W3C XML Schema Language is probably a good fit here. Further validation of the content would require extensive mathematics and verification against a remote database, so there's not a lot of reason to add additional schema languages to this task. A 3GL like Java is more appropriate. On the other hand, although I would write a schema for documentation purposes, I would not ship it with every instance of this format using an xsi:schemaLocation attribute. Instead, I'd place all the information in the instance document and leave off the schema itself. This will make client-side processing much simpler. Any recipient who really does care about the schema can always load and apply it separately, but most recipients won't need to do this, so why bother them with it? Documents will be mostly machine processed and contain ASCII text, so there's likely no real need for entity references, and thus a DTD would probably only duplicate what the schema already says. XSLT and XSL-FO could be used to generate and print the statements mailed to account holders, but this need not be part of the application's design. There's little call for hypertext in such printed documents, so there's no need to use XLink. What little may be necessary if the statements are available online (e.g., a link to the bank's privacy policy) can probably be handled by embedding XHTML. XHTML also works well for the legal notice on the back page as discussed in Item 23. Unnecessary and really not worth considering are RDF, OWL, the PSVI, and other more advanced specifications that seem far more interesting to computer scientists than to working programmers. None of these fit into the problem, so leave them out. XSLT, XPath, XQuery, DOM, SAX, and other means of reading and processing XML documents can all be used. However, they do not need to be specially considered when designing or documenting the format. These are tools used for processing, not something built into the specification itself. Of course, this is just one application. Your own applications will have different purposes and different needs. Pick the XML tools and technologies that help you get your job done, and ignore the rest, even if that means you aren't using the latest hyped release from the W3C. You know what you need better than some W3C committee does.  |