Solution Overview
| In our solution, we'll create a conformed data warehouse that can logically accommodate the information available in each of the sales systems. Our extraction, transformation, and loading (ETL) process will transform the data from each data source into the shape needed for the data warehouse. The ETL process can be run on a weekly (or more frequent) basis to keep the information current. The budgeting information will be integrated into the warehouse, eliminating the manual process of tracking sales to budgets. Users will continue to be able to use familiar Excel spreadsheets to enter their budget figures. Business RequirementsThe high-level requirements to support the business objectives are as follows:
High-Level ArchitectureWe will use SQL Server Integration Services (SSIS) to read data from our data sources, perform any data transformations we need, and then store it in the data warehouse. Integration Services will also be used to control the sequence of events and processes, such as emptying tables, loading data in the proper order, and generating audit logs of the operations. The tasks and transforms necessary for each of these processes are stored in Integration Services packages. You develop packages using the graphic designer for SQL Server Integration Services projects in BI Development Studio. You can test and debug your packages in the development studio. Once your packages are ready, you deploy them to the Integration Services server, where they can be executed directly, or they can be invoked by a job step in a SQL Agent job. We will load the full set of dimension data into our warehouse on a daily basis. This data has the business keys from the original companies. We will use our own surrogate keys to uniquely identify the products and regions and create a uniform model across the business. A result of reloading the dimensions is the surrogate keys can change, invalidating the facts previously loaded. For this example, we will reload all the sales for each company so the new surrogate keys will be reflected in the fact table. This works if the volume of data is small enough that the processing fits within your time constraints. We show you how to properly update existing dimensions and incrementally load facts in Chapter 8, "Managing Changing Data." The cube data will remain available to users during the rebuild process through the built-in caching facilities of Analysis Services. During the loading of sales data, we will translate business keys into the new surrogate keys. We will load budget data quarterly from Excel spreadsheets from each company and perform the same business key translations as we do for sales. This will allow us to directly compare sales and budgets. We'll use the capability of Integration Services to loop through the filenames in a directory to automate the loading of the budget spreadsheets. Figure 4-1 illustrates the flow of data in our ETL process. Figure 4-1. High-level architecture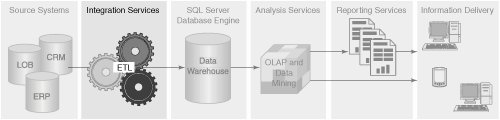 Business BenefitsThe solution will deliver the following benefits to the client:
|
EAN: 2147483647
Pages: 132
- Key #2: Improve Your Processes
- When Companies Start Using Lean Six Sigma
- Making Improvements That Last: An Illustrated Guide to DMAIC and the Lean Six Sigma Toolkit
- The Experience of Making Improvements: What Its Like to Work on Lean Six Sigma Projects
- Six Things Managers Must Do: How to Support Lean Six Sigma