XPath Functions
| | ||
| | ||
| | ||
There are a plethora of functions that can be used with XPath 2.0, XQuery 1.0, and XSLT 2.0.
XQuery is covered in the next chapter.
XPath functions actually apply to both XQuery (XQuery 1.0 data model) and XPath (XPath 2.0 data model) but since they are included in both, it is appropriate to describe all of these functions in the explanation of XPath expressions.
The sheer quantity and variety of functionality provided by XPath built-in functions are enormous . All the functions are included and usable by including the fn namespace at the W3C URL:
xmlns:fn="http://www.w3.org/2005/02/xpath-functions" At the time of this writing, there is a problem with demonstrating XPath functionality. According to W3C documentation, if a namespace XML document cannot be found from within something like an XSL style sheet, then that specific namespace is not yet released for general use. I have found various other namespace files for including XPath 2.0 functionality, none of which function at the time of writing this book:
xmlns:fn="http://www.w3.org/2003/11/xpath-functions" xmlns:fn="http://www.w3.org/TR/xpath-functions" xmlns:fn="http://www.w3.org/2005/xpath-functions" The other option is to demonstrate XPath 1.0, which with the introduction of XPath 2.0, is out-of-date. I dont see the point in describing software that is out-of-date.
XPath 2.0 functions are conveniently divided into various categories:
-
Accessor functions: These provide access to privately held data, privately held by other objects in other words, a function allowing access to setting and retrieving values of a property, without allowing direct access to the object containing the property. A read-only property has only one accessor function, and that allows retrieval of the property value. This is because a read-only property cannot be set.
-
Errors and tracing: Raise errors and debug using tracing during processing.
-
Constructor functions: These create an object instance from a class, or in really simplistic terms, they define a type. In other words, when declaring a variable as being of a simple data type such as a string or a number, in any programming language, one is constructing a variable. The mere definition of the variable as being of a specific type is actually a simple form of a constructor function. A constructor function constructs an iteration or copy of a variable from a definition.
-
Numeric functions: As in any programming language, a numeric function performs some kind of conversion or calculation such that a number value is returned.
-
String functions: As for number functions, but in this case a string is returned. Operations are usually performed on strings and return strings, rather than numbers , but not always.
-
URI function: A URI function operates on a URI. What is a URI? A URI is a Uniform Resource Identifier. A URI is also a type of a URL (Universal Resource Locator).
-
Boolean function: These functions produce a Boolean result, which programmatically allows for specific types of coding that result in either true or false.
-
Functions on durations, dates, and times: These functions operate on return dates, times, and durations of time.
-
QName functions: A QName is a qualified name . A QName contains a namespace URI. A QName is an optional prefix and a colon followed by a local name, or a URI plus a local element or attribute name.
-
Node functions: These functions are applied specifically to XML document nodes.
-
Sequence functions: A sequence is effectively a list of zero or more potentially repetitive items contained within a parent node. A sequence is therefore a collection. Sequence functions can be applied to a single collection as a whole, applying the same execution of a function to all elements in a collection at once.
-
Context functions: These functions apply to the meanings and thus the metadata within an XML document.
-
Other types of functions: These will not be demonstrated in this book as they are too obscure but are included at this stage so that you are aware of their existence:
-
Operators on base64Binary and hexBinary: Used for comparison of values where values do not have a decimal base (they are not decimal numbers).
-
Functions and operators on NOTATION: XML notation is a form of XML that is dialect-specific, and established for very specific applications in XML, such as MathXML and CML ( chemistry ). Specific XML dialect notations establish standards to, and apply topic regional semantics to otherwise generic XML data.
-
Now lets look at some of the details of XPath functions. The problem with demonstrating XPath functions at this point in this book is that these XPath functions are used in XQuery 75 percent of the time. Therefore, any examples will be delayed until the next chapter, which covers XQuery.
Accessor Functions
Accessor functions provide access to privately held data, privately held by other objects. In other words, a function allowing access to setting and retrieving values of a property, without allowing direct access to the object containing the property. A read-only property has only one accessor function, and that allows retrieval of the property value. This is because a read-only property cannot be set. Accessor functions are shown in Figure 10-13.

Figure 10-13: XPath accessor functions
Errors and Tracing
Error and tracing functions (see Figure 10-14) allow raising of errors and debugging using tracing.
Figure 10-14: XPath error and trace functions
Constructor Functions
Constructor functions (see Figure 10-15) are used to create an object instance from a class; constructor functions define a type. In other words, when declaring a variable as being of a simple data type, such as a string or a number in any programming language, one is constructing a variable. As already stated, the mere definition of the variable as being of a specific type is actually a simple form of a constructor function. A constructor function constructs an iteration or copy of a variable from a definition. Therefore a constructor function is actually a variable definition as well.
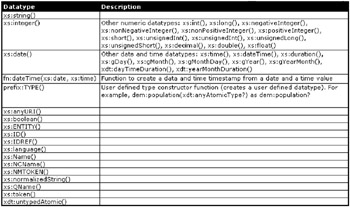
Figure 10-15: XPath constructor functions (data type definitions)
Some of the more obscure functions are omitted from Figure 10-15 , and subsequent similar figures in this chapter, in order to maintain focus on the topic of XML and databases.
An XML Schema defines most of these data types. Most essentially create specific data types from atomic types. An atomic data type or TYPE is essentially a very simple value, which when converted to a specific data type gives it the specific qualities of the data type to which it is converted.
Numeric Functions
Numeric functions in XPath (see Figure 10-16) are as in any programming language numeric functions used to perform some kind of conversion or calculation, such that a number value is returned.

Figure 10-16: XPath numeric functions
Numeric Operators
There are various numeric operators (see Figure 10-17) available for use with XPath. Many of these operators, such as numeric-add, act as options to their more commonly used symbolic representations (the plus sign: +).
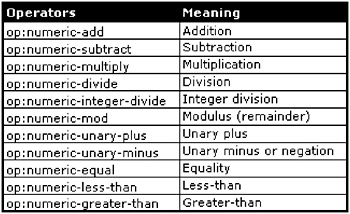
Figure 10-17: XPath numeric operators
String Functions
String functions (see Figure 10-18) are similar to number functions. However, operations are usually performed on strings and return strings rather than numbers, but not always.
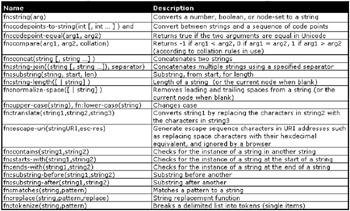
Figure 10-18: XPath string functions
URI Functions
A URI function operates on a URI. (A URI is a Uniform Resource Identifier.) A URI is also a type of a URL (Universal Resource Locator). In other words, http://www.yahoo.com is a DNS (Directory Names Service), and 216.109.112.135 is its IP address. Effectively the two make up a URL. A URL is an Internet address. So, a URI is a subset type of a URL. The difference is subtle in that a URL always refers to a remote resource on the Internet, whereas a URI can refer to a remote resource or a local resource. A local resource is not on the Internet and is locally located (on your LAN). A URI is thus not publicly accessible. For example, file:/// c:/tmp/MyFile.txt is a URI because it is located locally on my computer. Additionally, a URI does not necessarily refer to a specific network protocol because it may not be on a network, and a URL does refer to a specific network protocol.
The only function in this section is as follows :
fn:resolve-uri (relative, base) The preceding function resolves a relative URI to an absolute URI.
Boolean Functions
Boolean functions produce a Boolean result, which programmatically allows for specific types of coding in that the result produced by a Boolean function is either true or false. Figure 10-19 shows Boolean functions.

Figure 10-19: XPath Boolean functions
Boolean Operators
Specialized Boolean operators allow for testing of Boolean values, as shown in Figure 10-20.

Figure 10-20: XPath Boolean operators
Functions on Durations, Dates, and Times
These functions operate on date values of one form or another, and they usually return dates, times, and durations of time. These functions are shown in Figure 10-21.
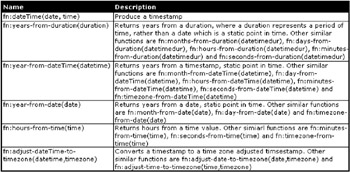
Figure 10-21: XPath duration, date, and time functions
Date, Time, and Duration Operators
There are specialized operators that operate on data, time, and duration values, as shown in Figure 10-22.
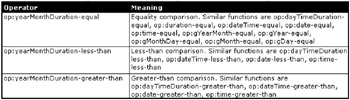
Figure 10-22: XPath duration, date, and time operators
And there are also numerous arithmetic functions that can be applied to durations, as shown in Figure 10-23.
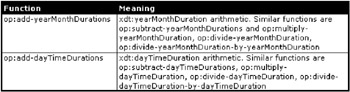
Figure 10-23: XPath duration arithmetic functions
And then arithmetic functions can be applied to dates, times, and durations, as shown in Figure 10-24.
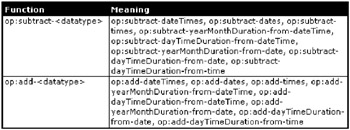
Figure 10-24: XPath duration, date, and time arithmetic functions
QName Functions
A QName is a qualified name that contains a namespace URI. A QName is an optional prefix and a colon followed by a local name, or a URI plus a local element or attribute name. QName functions are shown in Figure 10-25.

Figure 10-25: XPath qualified name (QName) functions
Node Functions
Node functions are applied specifically to XML document nodes.
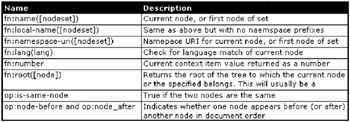
Figure 10-26: XPath node functions
Sequence Functions
A sequence is a list of zero or more potentially repetitive items, contained within a parent node. A sequence is therefore a collection. Sequence functions can be applied to a single collection as a whole, which means applying the same execution of a function to all elements in a collection at once. Figure 10-27 shows sequence functions.
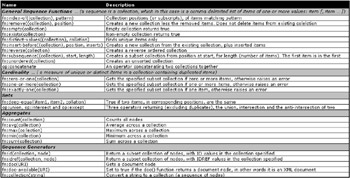
Figure 10-27: XPath sequence functions
The following XSL script uses the XML document shown in Figure 10-2 to apply two XPath functions:
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:fn="http://www.w3.org/2005/xpath-functions" xmlns:xdt="http://www.w3.org/2005/xpath-datatypes"> <xsl:template match="/"> <HTML><BODY> Sum of all male entries =<xsl:value-of select= "sum(//year[@year=1974]/occupations/occupation/male)"/> <BR/> Count of male entries = <xsl:value-of select= "count(//year[@year=1974]/occupations/occupation/male)"/> </BODY></HTML> </xsl:template> </xsl:stylesheet> The result of the preceding script is shown in Figure 10-28.
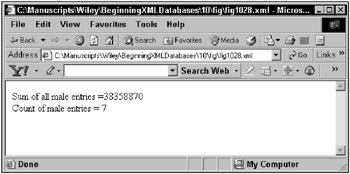
Figure 10-28: XPath sequence functions by example
Context Functions
These functions apply to the meanings, and thus the metadata within an XML document. Figure 10-29 shows context functions.
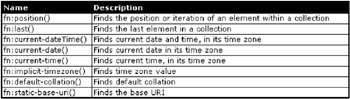
Figure 10-29: XPath context functions
Once again, using the same small dataset, as shown in Figure 10-2, the following XSL script is applied to the XML data, including use of the last() and position() XPath context functions:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <HTML><BODY> Last male entry = <xsl:value-of select="//year[@year=1974]/occupations/occ upation[last()]/male"/> <BR/> First female entry = <xsl:value-of select="//year[@year=1974]/occupations/ occupation[position()=1]/female"/> </BODY></HTML> </xsl:template> </xsl:stylesheet> Figure 10-30 shows the result of applying the preceding XSL script to the data shown in Figure 10-2.
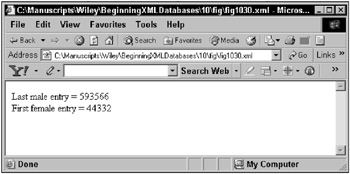
Figure 10-30: Using some simple XPath context functions
| |
The following query executes against the demographics relational database used in this book (see Appendix B). This query finds cities with all their populations, regardless of where the cities are located in the world:
SELECT r.REGION, co.COUNTRY, ci.CITY, ci.POPULATION FROM REGION r JOIN COUNTRY co ON (co.REGION_ID = r.REGION_ID) JOIN CITY ci ON (ci.COUNTRY_ID = co.COUNTRY_ID) ORDER BY ci.CITY; This is a partial result of the preceding query (you will use the demographics.xml XML document for this example):
REGION COUNTRY CITY POPULATION ---------------- ---------------- ---------------- ---------- Africa Ivory Coast Abidjan 4000000 Central America Mexico Acapulco 0 Africa Ghana Accra 2550000 Near East Turkey Adana 1300000 Africa Ethiopia Addis Ababa 0 Africa Ethiopia Addis Abeba 3000000 ... Using the query and the data shown as a guide, create an XPath expression in an XSL style sheet, parsed against the XML document form of the demographics database. Produce the same result using the XML data, XSL, and a browser. This is how:
-
This is a very simple task. Create an HTML framework as follows:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <BODY> <TABLE CELLPADDING="5" CELLSPACING="1" BORDER="1"> <TH BGCOLOR="silver">City</TH> ... </TABLE></BODY></HTML> -
Now add in a for loop containing an XPath expression to find cities:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl"><BODY> <TABLE CELLPADDING="5" CELLSPACING="1" BORDER="1"> <TH BGCOLOR="silver">City</TH> <xsl:for-each select="demographics/region/country/city"> ... </xsl:for-each> </TABLE></BODY></HTML> -
Perhaps sort the results based on the name of the city:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl"><BODY> <TABLE CELLPADDING="5" CELLSPACING="1" BORDER="1"> <TH BGCOLOR="silver">City</TH> <xsl:for-each select="demographics/region/country/city" order-by="name"> ... </xsl:for-each> </TABLE></BODY></HTML> -
And now add in the simple detail to get the actual values:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl"><BODY> <TABLE CELLPADDING="5" CELLSPACING="1" BORDER="1"> <TH BGCOLOR="silver">City</TH> <xsl:for-each select="demographics/region/country/city" order-by="name"> <TR> <TD><xsl:value-of select="."/></TD> </TR> </xsl:for-each> </TABLE></BODY></HTML> -
The result looks like that shown in Figure 10-31.
Figure 10-31: Try It Out simple XPath expression syntax
How It Works
You created a simple XPath expression to selectively read data from an XML document. That same reading of data was accomplished as a simple relational database SQL statement, executed against tables in a database. This demonstrates that XPath expression syntax allows you to pull data from an XML data source as you would pull data from an XML document. In other words, the two different methods perform the same function.
| |
This chapter has addressed the XML expression language XPath, which is used to parse and extract information from XML documents. Other tools such as XQuery and XPointer are based on XPath, and so XPath is fundamental to understanding information presented in the next few chapters.
| | ||
| | ||
| | ||
EAN: 2147483647
Pages: 183