XPath Expression Syntax
| | ||
| | ||
| | ||
XPath utilizes expressions based on paths through an XML document, similar to the paths used to navigate the directories of an operating system like DOS or UNIX. Some simple path expressions are demonstrated shortly.
At this point I will be using the demographics XML database document as described in Appendix B (also available online as a download). Essentially the downloadable XML document is large, and I will use a small portion of that document, accessible from the relational database structure using the following query:
select co.country as country, p.year, l.language, o.occupation from country co join population p on(co.country_id=p.country_id) join populationbylanguage pl on(pl.population_id=p.population_id) join populationbyoccupation po on (po.population_id=p.population_id) join language l on(pl.language_id=l.language_id) join occupation o on(po.occupation_id=o.occupation_id) where co.country in('Bangladesh'); I decided which country to use by selecting the country with the smallest number of rows when joining both occupations and languages:
select country, count(country) from( select co.country as country, p.year, l.language, o.occupation from country co join population p on(co.country_id=p.country_id) join populationbylanguage pl on(pl.population_id=p.population_id) join populationbyoccupation po on (po.population_id=p.population_id) join language l on(pl.language_id=l.language_id) join occupation o on(po.occupation_id=o.occupation_id) ) group by country order by count(country); This is the result of the preceding query:
COUNTRY COUNT(COUNTRY) ---------------- -------------- Bangladesh 21 Bulgaria 28 Bolivia 40 Singapore 50 Hungary 63 Malaysia 64 Panama 72 Canada 111 Nepal 152 South Africa 216 Australia 225 Finland 386 Zambia 600 The preceding query result indicates that Bangladesh has the fewest rows, where both multiple languages and multiple occupations are available in the data. A small dataset is required because we dont want examples and graphics in this book printed over multiple pages. That is simply too difficult to follow.
Now you execute the preceding query again to display the actual data:
select co.country as country, p.year, l.language, o.occupation from country co join population p on(co.country_id=p.country_id) join populationbylanguage pl on(pl.population_id=p.population_id) join populationbyoccupation po on (po.population_id=p.population_id) join language l on(pl.language_id=l.language_id) join occupation o on(po.occupation_id=o.occupation_id) where co.country in('Bangladesh'); The data is also all in the single year of 1974:
COUNTRY YEAR LANGUAGE OCCUPATION ---------------- ---------- ---------------- ---------------- Bangladesh 1974 Urdu Professional Bangladesh 1974 Bengali Professional Bangladesh 1974 Others Professional Bangladesh 1974 Urdu Management Bangladesh 1974 Bengali Management Bangladesh 1974 Others Management Bangladesh 1974 Urdu Clerical Bangladesh 1974 Bengali Clerical Bangladesh 1974 Others Clerical Bangladesh 1974 Urdu Sales Bangladesh 1974 Bengali Sales Bangladesh 1974 Others Sales Bangladesh 1974 Urdu Agriculture Bangladesh 1974 Bengali Agriculture Bangladesh 1974 Others Agriculture Bangladesh 1974 Urdu Labor Bangladesh 1974 Bengali Labor Bangladesh 1974 Others Labor Bangladesh 1974 Urdu Service Bangladesh 1974 Bengali Service Bangladesh 1974 Others Service Figure 10-2 shows the data from the preceding result, in a browser, in the XML document version of the demographics database.
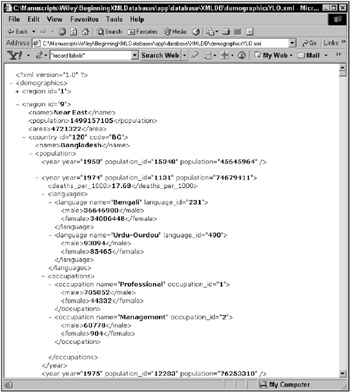
Figure 10-2: Isolating a dataset in the demographics XML document
The following is the XML fragment for the country of Bangladesh, including root node, languages, occupations, and cities. And excluding all years other than 1974 (a manageable fragment):
<?xml version="1.0"?> <demographics> <region id="9"> <name>Near East</name> <population>1499157105</population> <area>4721322</area> <country id="120" code="BG"> <name>Bangladesh</name> <population> <year year="1974" population_id="1131" population="74679411"> <deaths_per_1000>17.68</deaths_per_1000> <languages> <language name="Bengali" language_id="231"> <male>36646900</male> <female>34006448</female> </language> <language name="Urdu-Ourdou" language_id="490"> <male>93094</male> <female>85465</female> </language> </languages> <occupations> <occupation name="Professional" occupation_id="1"> <male>705852</male> <female>44332</female> </occupation> <occupation name="Management" occupation_id="2"> <male>60778</male> <female>904</female> </occupation> <occupation name="Clerical" occupation_id="3"> <male>412490</male> <female>4500</female> </occupation> <occupation name="Sales" occupation_id="4"> <male>1846066</male> <female>22548</female> </occupation> <occupation name="Agriculture" occupation_id="5"> <male>30458150</male> <female>1217616</female> </occupation> <occupation name="Labor" occupation_id="6"> <male>4281968</male> <female>212378</female> </occupation> <occupation name="Service" occupation_id="7"> <male>593566</male> <female>178736</female> </occupation> </occupations> </year> </population> <area>133911</area> <currency fxcode="BDT" rate="0">Taka</currency> <city id="312"> <name>Chittagong</name> <population>4150000</population> </city> <city id="313"> <name>Khulna</name> <population>1525000</population> </city> <city id="270"> <name>Dacca</name> <population>12750000</population> </city> </country> </region> </demographics> So now lets begin with the XPath demonstration process.
Simple Expressions to Find Nodes
XPath uses what is called a path expression to pull nodes from an XML document. A path expression is quite literally an expression, expressed as a path, through a hierarchical structure. The term expression is appropriate because the path is a pattern that is matched to the structure of an XML document. This finds all paths that match to the expression. The most basic XPath expressions are as shown in Figure 10-3.
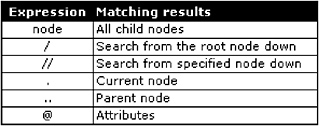
Figure 10-3: Basic XPath expressions
The script that follows is an XSL (eXtensible Style Sheet) script. This script is applied to the Bangladesh demographics XML document fragment shown previously:
<HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl"><BODY> <TABLE CELLPADDING="5" CELLSPACING="1" BORDER="1"> <TH BGCOLOR="silver">City</TH> <xsl:for-each select=" demographics/region/country/city "> <TR> <TD><xsl:value-of select=" . "/></TD> </TR> </xsl:for-each> </TABLE></BODY></HTML> When executing the preceding script, it must be included into the XML document fragment as follows:
<?xml version="1.0"?> <?xml:stylesheet type="text/xsl" href="fig1004.xsl" ?> < demographics > < region id="9"> <name>Near East</name> <population>1499157105</population> <area>4721322</area> < country id="120" code="BG"> <name>Bangladesh</name> ... < city id="312"> <name>Chittagong</name> <population>4150000</population> </city> < city id="313"> <name>Khulna</name> <population>1525000</population> </city> <city id="270"> <name>Dacca</name> <population>12750000</population> </city> </country> </region> </demographics> Applying the XSL script to the XML document fragment searches for all city elements within the structure demographics/region/country/city, retrieving all the child elements for all city elements. The result is shown in Figure 10-4.
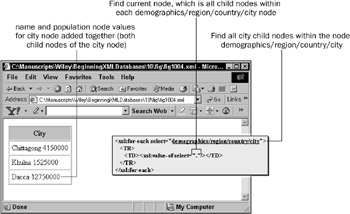
Figure 10-4: Using XPath basic expressions
Figure 10-5 shows slightly different results because different expressions are used. //city/name will find all city/name nodes, anywhere in the XML structure, regardless of country, or otherwise . The @ character is used to find an attribute value, as in 312 extracted from the node <city id=312>. The periods, or ../population expression finds the parent node, this finds the population node in the parent of the node //city/name (or the sibling of the name node, within the city node).
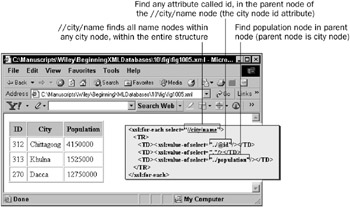
Figure 10-5: Using XPath basic expressions
Find Specific Values Using Predicates
So far you have retrieved nodes from XML regardless of the values of nodes or their attributes. Predicates are the equivalent of SQL filters, or WHERE clauses. So, a predicate can be used to qualify which nodes are retrieved based on the values contained within those nodes. Predicate syntax is very simple applied to a specific node within an XPath expression, and enclosed in square brackets as follows:
... [predicate] ... In general, a predicate is a filter, requiring an operator to mathematically filter specific results. Thus the syntax changes slightly to:
... [node operator value] ... where operator can be operators such as = , > , and so on.
Predicate tests can be performed against text or attribute values:
... [text='value'] ... or
... [@attribute=value] ... A predicate can also be the collection subscript of a child node. This syntax will find the second node in a collection of two or more child nodes:
... [node[2]] ... Next you examine the details of XPath operator syntax.
XPath Operators
The table in Figure 10-6 shows the various operators available to XPath expressions and their meanings and uses.
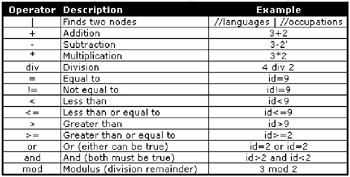
Figure 10-6: Available XPath operators
So if you go back to using XPath predicates, the following example will find the first city node within the country of Bangladesh:
demographics/region/country[name='Bangladesh']/city[1]"/> This example finds all cities with a population over 10,000,000 people:
demographics/region/country/city[population>10000000]"/> And this example finds the second city, in the country of Bangladesh, in the region with id attribute of 9 :
demographics/region[@id=9]/country[name='Bangladesh']/city[2]"/> Figure 10-7 shows the browser results of the preceding three examples.
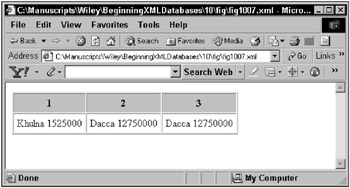
Figure 10-7: Using XPath predicates
Context functions such as last() and position() can also be used in XPath predicate expressions. Context functions are discussed later on in this chapter.
Use Wildcards to Find Unknown Nodes
A wildcard is like a wildcard in poker in that it can mean more than one thing. In most programming languages there are two wildcards: one for matching strings and one for matching a single character. In XPath expressions only a string wildcard is allowed. Essentially, a wildcard character is the * (star or asterisk character) and applies to node names or attribute names .
There is also a node() function that can find nodes of any kind which will be covered later on under functions.
In Figure 10-8 the for loop finds all language nodes within all languages nodes (language collections), and then specifies a predicate that all language nodes found must have at least 1 attribute indicated by the [@*] predicate part of the XPath expression.
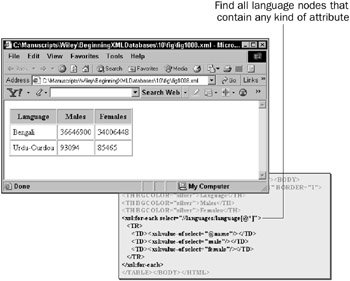
Figure 10-8: Using wildcards in XPath
In Figure 10-9, the for loop finds all nodes that have an id attribute, regardless of the content and type of the node. Thus, all regions , countries , and cities are found.
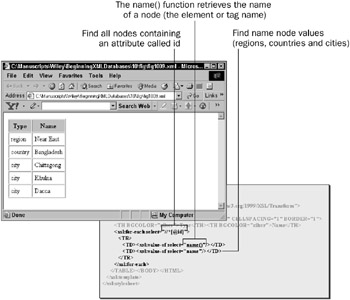
Figure 10-9: Using wildcards in XPath
Expressions on Multiple Paths
A multiple path expression allows you to retrieve two sets of data at once. In other words, it looks for one path, then another, and then merges them together and returns them. The operator is used to merge multiple XPath expression results. This operator is sometimes known, in various programming languages, as the pipe or concatenation operator. Concatenation is perhaps appropriate in this case because two separate datasets are concatenated (added together). The result shown in Figure 10-10 is a concatenation of two XPath expression searches, returning both the languages and occupations collections node contents.
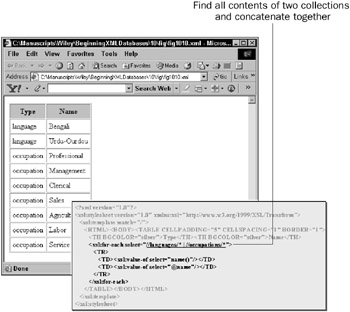
Figure 10-10: Concatenating two expression results in XPath
| | ||
| | ||
| | ||
EAN: 2147483647
Pages: 183