Documents as Trees
 | ||||||||
| Chapter 3 - Transforming with Style (Stylesheets, That Is) | |
| XSLT For Dummies | |
| by Richard Wagner | |
| Hungry Minds 2002 | |
XSLT processors dont read a document like you and I do. When I read a document, I start at the top of the page and read from left to right, line by line down the page to the end. I make sense of a document by reading its words, sentences, and paragraphs in sequence. (Okay, I admit it, I love those Dr. Seuss books the best, because I can get by just looking at pictures.) In contrast, an XSLT processor does not read a document sequentially, but swallows it as a hierarchy of information. This hierarchy is best thought of as a tree, and in fact, XSLT uses tree lingo as a way to describe an XML document. Remember A solid grasp of document trees can help you realize that XSLT and XPath dont do their work by using smoke and mirrors, but actually follow a logical, understandable process. In fact, a good alternative title for this section is Read This! This Section Is Important. TreespeakA common tree, be it a maple , oak, or elm, has a certain built-in structure or hierarchy to its various parts . At the bottom layer, a root system serves as the hidden foundation, supplying water and nutrients to the rest of the tree. Connected to the roots is the trunk, the most visible part of the support system. At the next level, you have branches of all shapes and sizes, which either connect to smaller branches or else directly to leaves. These smaller branches then lead to leaves or even tinier branches, and so on. Starting at the trunk, you can locate each branch and leaf somewhere in its complex hierarchy of parts. An XML document follows this same pattern. Every XML document has its own counterpart to a trunk, an element commonly referred to as the document element . The document element encloses all the other elements inside its start and end tags. For example, doc in the snippet below is the document element because it contains all of the other elements in the document: <doc> <para>Text1</para> <para>Text2</para> </doc> As you have seen already in this chapter, an xsl:stylesheet element contains template rules and all other parts of an XSLT stylesheet, so it acts as the document element of an XSLT stylesheet. Remember Just as a tree cannot have two trunks, neither can an XML document have two document elements. A well- formed XML document can have only a single document element that contains all of the other elements. Top-level elements nested directly inside a document element are the equivalent of the first level of branches of a tree. Some of these elements (also called nodes in treespeak) contain additional elements, like smaller branches on a tree. Even a trees roots have an XML counterpart. Each document has something called a root node that contains all elements, including the document element. The root node, however, is invisible to your document, because no element or text represents the root node in the document. Table 3-2 summarizes the comparison between a real tree and an XML one.
FamilyspeakJust as a leaf cannot survive apart from a tree, a node cannot exist in isolation. Each node of a tree is related in some way to the other nodes that surround it in the document structure. The terminology used to describe these relationships comes straight from The Waltons or The Simpsons : ancestor , parent, sibling, and child. I like to call this terminology familyspeak. Using familyspeak, you can say that a tree trunk is the parent of all the branches connected directly to it. Each of these attached branches is a child of the trunk and a sibling to the others. Any given branch typically has children as well, which may be either branches or leaves. To illustrate the interrelationships of an XML document, consider a family tree expressed in XML: <!-- familytree.xml --> <family> <member firstname="Peter" surname="Selim" birth="1815"> <spouse firstname="Maja" surname="Jonsdotter"/> <member firstname="Carl" surname="Selim" birth="1845"> <spouse firstname="Joannah" surname="Lund" birth="1844"/> <member firstname="Hannah" surname="Selim"/> <member firstname="David" surname="Selim"/> <member firstname="Selma" surname="Selim"/> <member firstname="Ellen" surname="Selim"/> <member firstname="Charlie" surname="Selim" birth="1869"> <spouse firstname="Hannah" surname="Carlsdotter" birth="1865"/> <member firstname="George" surname="Selim" birth="1898"></member> <spouse firstname="Dagmar" surname="Selim" birth="1898"/> <member firstname="Paul" surname="Selim"/> <member firstname="Pearl" surname="Rohden" birth="1897"/> <member firstname="Frances" surname="Lambert" birth="1903"/> <member firstname="Gladys" surname="Carlson" birth="1906"></member> <spouse firstname="Hilmer" surname="Carlson" birth="1906"/> <member firstname="Patricia" surname="Gustafson"> <spouse firstname="Lauren" surname="Gustafson"/> </member> <member firstname="Wayne" surname="Carlson"/> <member firstname="Janet" surname="Olsen"/> <member firstname="Linda" surname="Zatkalik"/> <member firstname="Eunice" surname="Shafer"> </member> </member> </member> </member> </family> This family tree has a parent element called family , which serves as the container for everything in that family. Peter Selim is the oldest recorded ancestor of this family, which is demonstrated by the <member firstname= "Peter" surname="Selim" birth="1815"> being the first member element of this family tree and serving as the ancestor for all the rest of the member elements. Peter had a spouse named Maja and one son named Carl. Carl and his wife Joannah had five children, one of whom had children himself, and so on, down the family tree. So, for example, Eunice Shafer, the last child element on the tree had a parent named Gladys Carlson, and Eunices siblings were Patricia, Wayne, Janet, and Linda. Peter Selim is a distant ancestor to Eunice. Each of these family relationshipsfrom Peter to Euniceare interconnected . You find out later in this book that traversing this tree through these interrelationships is an important part of XSLT. Nodes ˜R usNow that youve got treespeak and familyspeak down, you can take a closer look at what a node is. In a general sense, a node is a point in a larger system. A leaf seems like an obvious node in a tree. However, in XML, each part of an XML document structure is a node, be it the trunk, branch, or leaf. Also, to make matters slightly more complicated, even attributes of a these parts are considered nodes. In fact, there are actually six different node types: element, attribute, namespace, processing instruction, comment, and text. The XML snippet below contains several of these node types: <?xml version="1.0" encoding="UTF-8"?> <film name="Braveheart"> <!-- Last modified 2/01 --> <storyline>William Wallace unites the 13th Century Scots in their battle to overthrow English rule.</storyline> </film> This snippet can be expressed as a tree structure, as shown in Figure 3-4. 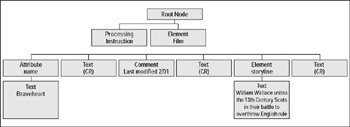 Figure 3-4: Node hierarchy of the family tree XML file. Youll notice one difference between the tree structure shown in Figure 3-4 and the XML codethe additional text nodes. These text nodes actually represent the hidden text in between the various elements. Although no actual text is between the film element and the comment or between the comment and the storyline element, invisible carriage return characters are present to start a new code line. These characters are considered part of the XML document by default, so theyre not added to the document tree. (In Chapter 13 you find out how to tweak some of these whitespace settings.) Tip An XML document tree is often called a Document Object Model (or DOM). Although this may sound like technospeak, a DOM is only the exercise of looking at a document in a tree-like manner. Technical Stuff Because the XSLT processor reads the document as a tree, it has the entire tree available throughout the transformation process. This tree-like approach is much different than simpler XML parsers, such as the Simple API for XML (SAX), which reads an XML document sequentially and therefore deals with elements one at a time. Working with treesYou need a solid understanding of document trees so that you know how XSLT works to get information from the XML source document and to output it in the result document. But, fortunately, you never actually have to worry about the mechanics of traversing the document tree (a practice sometimes called tree walking ). Many other programming languages make use of tree structures to describe hierarchical information. Yet working with trees can be a complex task if you have to write the code to actually walk through the tree, making sure every nook and cranny in it is found. Certainly one of the tremendous benefits of XSLT is that it removes the burden of tree walking by doing all this hard stuff for you. You get to say, I want all the nodes that match this pattern, and XSLT then goes off to handle the request. You dont need to concern yourself with the implementation details of this process.
| |||||||||||||||||||||||
If you may any questions please contact us: flylib@qtcs.net