6.1 Why Do Backups?
| only for RuBoard - do not distribute or recompile |
6.1 Why Do Backups ?
Backup is a tedious , costly, and usually thankless task in an Information Technology department. Yet there are few who would risk the company s data (and their own job security) by instituting a policy of not backing up.
Storage Area Networks impose new demands on the backup and restore process, yet they also offer new possibilities that may make backup and restore operations simpler and more efficient than ever before.
This chapter reviews the rationale, principles, and building blocks of backup and restore. It then shows how backup and restore operations fit into the world of the SAN.
6.1.1 What s a Backup?
Backup describes an operation that makes a copy of vital data at an optimal time. The term backup also describes the collection of copied data, stored safely in case a restore is needed. Data is copied from primary storage, typically disk drives , to secondary storage, typically tape.
Tape has been the backup medium of choice for about 40 years , owing to its relatively low cost, relatively high density, physical compactness, and ease of transport to storage facilities. This is still true today, despite several drawbacks: inherent slowness in writing to tape, proneness to tape errors, and the limited shelf life of tape.
In the 1960s, the mainframe operator probably wouldn t have had the luxury of using the shop s complete string of tape drives (Figure 6-1). He or she might have been allocated two or three drives to get all the data from the disks. Hanging tapes to do the backup could take up a significant part of the shift.
Figure 6-1. The Bad Old Days: Mainframe Backup
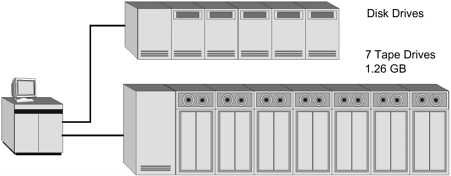
Although the equipment is now smaller, the principle hasn t changed. The object is still to copy disk data to tape. The tape drives hold more, but the disk drives can be much larger in capacity (Figure 6-2).
Figure 6-2. The Bad New Days: Server Backup

In the 1990s and up through today, the system administrator has the same concern: getting all the data on backup media in a relatively short amount of time. Granted, the tape drives are smaller, the tapes are smaller, the tape capacities are higher. However, the disk drives are much larger and there can be many servers (hundreds, potentially thousands) in an enterprise. Forty years since the 1960s and the operator is still changing tapes.
Ideally, the backup is a full backup, a complete snapshot of company data. But full backups take time, and have traditionally required that the system be unavailable to users. As company data grows, full backups take longer and longer to complete. In classic data processing, the company was idle late at night, and therefore full backup was a traditional activity for third-shift computer operators.
Here is a summary of the contemporary 10-tape method. Your workgroup or department may use something quite similar to it. This is taken directly from HP advice to users of DDS (DAT) tape.
There are many systematic methods for regularly backing up data. One of the more common ones is the ten-tape cycle method. It is easy to implement. It also keeps more than one historical copy of the data so that losing one tape does not mean you have lost your data. Assuming a tape life of 100 backup and restore passes per tape, using this method you should have to replace your tapes only once a year.
The method involves maintaining a daily, weekly, and monthly backup. Every three months the monthly tapes are recycled. The advantages of this method are:
Simplicity. It is very easy to recover data.
Easy access. Data backed up any time during the past two months can be easily found and restored.
If all the data you wish to back up will fit onto a single tape, you will need ten backup tapes. (Naturally, you will also want extra tapes for archival storage or file transfers.)
If you require more than one tape per backup, you will need ten sets of tapes, with each set composed of the smallest number of tapes that will hold a full backup.
Before making a backup, label each of the ten tapes as follows :
Daily Sets
Weekly Sets
Monthly Sets
Monday
Friday 1
Month 1
Tuesday
Friday 2
Month 2
Wednesday
Friday 3
Month 3
Thursday
If you need more than one tape to perform a full daily backup, record the tape number (for example, Tape 1 of 2 ).
On Monday, Tuesday, Wednesday, and Thursday, make a full backup to the tape labeled for that day.
On the first, second, and third Friday of the month, make a full backup to the tape labeled for that day.
On the fourth Friday of the month, perform the backup on the tape labeled for that month.
At the end of the fourth month, recycle the monthly tapes. In other words, start again with the tape labeled Month 1.
For extra security, place each of the Friday and monthly tapes in a fireproof safe, or store them away from the site.
No, that s not a misprint. The above procedure specifies full backups on all cycles. An interesting approach if you don t have a world of data to back up, but do have a world of time to do it in.
An incremental backup copies only what data has changed since yesterday ( strictly speaking, since the last backup). This is usually a much smaller amount of data than a full backup, and so requires less time. However, the reduced time needed to back up data may be overtaken by the enterprise s need for more time for active processing. The result is a smaller backup window.
Incremental backups have spawned a number of complex backup strategies: multiple tape sets, dailies, weeklies, monthlies, etc. With the company s last full backup and a number of incremental backups, company data can be fully restored.
Incremental backups are not superior , in terms of organization and bookkeeping, but at least they require less processing time. Here is a six-tape method, requiring only one full backup per week:
Before making a backup, label each of the six tapes as follows:
Daily Sets
Weekly Sets
Monday
Friday 1
Tuesday
Friday 2
Wednesday
Thursday
If you need more than one tape to perform a daily backup, record the tape number (for example, Tape 1 of 2 ).
Begin by making a full backup of the system on the tape Friday 1.
On Monday, Tuesday, Wednesday, and Thursday, make an incremental backup to the tape labeled for that day.
If you need to restore all data, use the previous Friday s tape, and the incremental tapes made before the data loss. For example, if you need to restore on a Wednes-day morning, use the previous Friday s full backup, plus the incremental backups for Monday and Tuesday.
On Friday, make a full backup of the system on the tape Friday 2. On each Friday, alternate between Friday 1 and Friday 2.
On the fourth Friday of the month, perform the backup on the a Friday tape or on a monthly tape labeled for that month.
On every Monday, start reusing the daily tapes.
It s difficult to find a data center that doesn t use a combination or variation of the above methods, no matter what the size of the business or the quantity of data involved.
6.1.2 What s a Restore?
Restore describes an operation that copies backed-up data from secondary storage to a primary storage device.
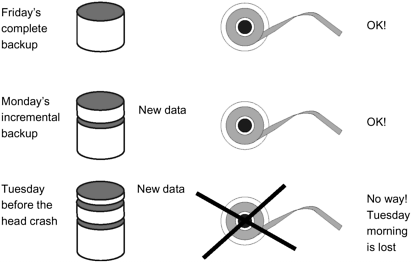
Computing equipment is not perfect, and primary storage can fail. Data can also be lost for other reasons, as described below. So when data is lost, a restore will bring back the last, best copy of company data. A combination of full and incremental backups will restore most, if not all, company data.
Transactions entered between the time of the last incremental backup and the failure of primary storage are lost. So while backup and restore operations are valuable , they are less than perfect. In 24/7 operations, and highly active online transaction processing environments, there remains the possibility of loss of recently entered data.
While the situation in Figure 6-3 is inconvenient, it is usually not disastrous for most sites. However, it poses a severe problem for high-intensity data processing operations. Imagine an online bookstore processing a theoretical one million book orders per hour (OK, 100,000 if you like). Even a loss of ten minutes worth of transactions can be very damaging .
Figure 6-3. Inability to Restore Today s Data
It is no surprise that companies with heavy demands on primary storage use high-availability disk arrays, with redundant power supplies , redundant controllers, redundant fans, embedded RAID technology, and hot spares (disk drives).
Another protection against unrestorable increments is fast disk-to-disk copies (Figure 6-4). Transfers to tape are still done, but secondary disks (also called target volumes ) are used as part of the strategy.
Figure 6-4. Disk-to-disk Copies
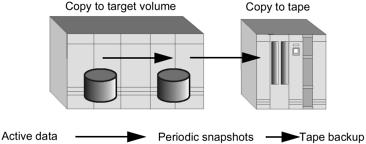
The scenario in Figure 6-4 uses a high-end disk array, and it is likely to be seen frequently in SAN configurations. The active data is copied from disk to disk (from source volumes to target volumes), at high speed and with virtually no disruption. Once the snapshot is taken, the target volume can be copied to tape with no disruption to the source volume.
In an ideal world, restores should never take place, and backup data should be quietly archived in a vault, never to be used again. The backup is like a fire extinguisher or a first aid kit. It is valuable in an emergency, but we would hope that that emergency will never happen.
6.1.3 Loss of Data
Now about that emergency. It is not a perfect world, and there is always a risk of loss of data. Experience indicates that the vast majority of losses derive from unexpected failures of media, unexpected failures of hardware, and accidental deletion by human beings. Deliberate destruction of data is far more rare.
In the world of software development, many a programmer has accidentally deleted or overwritten the most recent source code for an important program. Even in the world of desktop applications, critical documents or even a complete small business accounting system can disappear with a careless click of the mouse on the OK button.
Modern enterprise servers and mainframes serve a large number of users and have the capacity to hold massive amounts of data in embedded or attached storage. Such quantities and concentrations of data increase the enterprise s exposure to loss of data.
Big enterprises have more people accessing more data more hours per day than small enterprises . The concept of managing gigabytes of data has given way to the concept of terabytes, and petabytes are on the horizon.
Data loss for reasons other than hardware failure is less frequent but certainly can happen. The first is the deliberate destruction of data. It is still relatively easy to deliberately delete an enterprise s critical files. A clever perpetrator can trigger the destruction to happen at a time when he or she is offsite, when business is at a seasonal peak, or both.
The Internet provides new opportunities for data loss, or at least to impede the efficient delivery of data. There are frequent national news reports about people hacking into government and commercial Web sites, usually with the goal of vandalism or disruption of Internet operations. What is not well reported by image-conscious corporations is the theft or destruction of data.
In the old days, it was bad enough to lose the customer master file, containing hundreds of customer records. In modern times, hackers can steal data, destroy data, or deface a site visited by millions of customers daily. This can have consequences ranging from temporary loss of millions of dollars (per hour!) to major embarrassment for a corporation or a government agency. The loss of Web page data can undermine the public s confidence in a company s ability to handle orders, deliver merchandise, and protect customer credit card information.
Lastly, catastrophes (both man-made and natural) can create disastrous data losses. A five-alarm fire will ruin a company s day. A hurricane or earthquake can ruin everyone s day in a whole region.
The economics of such data losses are severe. On a global plane, a company may serve customers around the world, and the quick restoration of data and computer operations is vital to meeting customer needs. On a local plane, employees need their livelihoods in order to rebuild after a disaster, so the company has an obligation to restore operations as quickly as possible, keeping the employees working and reestablishing a normal state of affairs.
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 88