| Now that we've seen the LWP API, we'll look at some practical examples that use it. Fetching a List of RFCs The Internet FAQ Consortium (http://www.faqs.org/) maintains a Web server that archives a large number of useful Internet documents, including Usenet FAQs and IETF RFCs. Our first example is a small command-line tool to fetch a list of RFCs by their numbers . The RFC archive at http://www.faqs.org/ follows a predictable pattern. To view RFC 1028, for example, we would fetch the URL http://www.faqs.org/rfcs/rfc1028.html . The returned HTML document is a minimally marked -up version of the original text-only RFC. The FAQ Consortium adds an image and a few links to the top and bottom. In addition, every reference to another RFC becomes a link. Figure 9.4 shows the get_rfc.pl script. It accepts one or more RFC numbers on the command line, and prints their contents to standard output. For example, to fetch RFCs 1945 and 2616, which describe HTTP versions 1.0 and 1.1, respectively, invoke get_rfc.pl like this: Figure 9.4. The get_rfc.pl script  % get_rfc.pl 1945 2616 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN"> <HTML> <HEAD> <TITLE>rfc1945 - Hypertext Transfer Protocol -- HTTP/1.0</TITLE> <LINK REV="made" HREF="mailto:rfc-admin@faqs.org";> <META name="description" content="Hypertext Transfer Protocol -- HTTP/1.0"> <META name="authors" content="T. Berners-Lee, R. Fielding & H. Frystyk"> ... The retrieved files can be saved to disk or viewed in a browser. Lines 1 “4: Load modules We turn on strict syntax checking and load the LWP module. In addition, we define a constant URL prefix to use for fetching the desired RFC. Line 5: Process command-line arguments We check that at least one RFC number is given on the command line, or die with a usage message. Lines 6 “8: Create user agent We create a new LWP::UserAgent and change its default User-Agent: field to get_rfc/1.0 . We follow this with the original default agent ID enclosed in parentheses. Lines 9 “18: Main loop For each RFC listed on the command line, we construct the appropriate URL and use it to create a new HTTP::Request GET request. We pass the request to the user agent object's request() method and examine the response. If the response's is_success() method indicates success, we print the retrieved content. Otherwise , we issue a warning using the response's status message. Mirroring a List of RFCs The next example represents a slight modification. Instead of fetching the requested RFCs and sending them to standard output, we'll mirror local copies of them as files stored in the current working directory. LWP will perform the fetch conditionally so that the remote document will be fetched only if it is more recent than the local copy. In either case, the script reports the outcome of each attempt, as shown in this example: % mirror_rfc.pl 2616 1945 11 RFC 2616: OK RFC 1945: Not Modified RFC 11: Not Found We ask the script to retrieve RFCs 2616, 1945 and 11. The status reports indicate that RFC 2616 was retrieved OK, RFC 1945 did not need to be retrieved because the local copy is current, and that RFC 11 could not be retrieved because no such file exists on the remote server (there is, in fact, no RFC 11). The code, shown in Figure 9.5, is only 15 lines long. Figure 9.5. The mirror_rfc.pl script 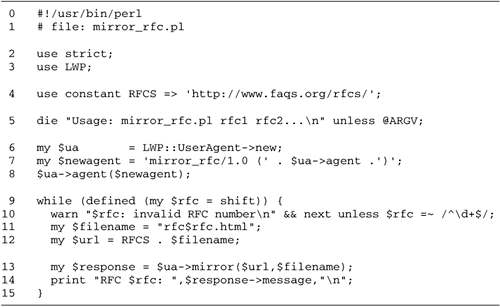 Lines 1 “8: Load modules and create user agent The setup of the LWP::UserAgent is identical to the previous example, except that we modify the usage message and the user agent ID appropriately. Lines 9 “15: Main loop We read RFC numbers from the command line. For each RFC, we construct a local filename of the form rfcXXXX.html , where XXXX is the number of the requested document. We append this to the RFC server's base URL in order to obtain the full remote URL. In contrast with the previous example, we don't need to create an HTTP::Request in order to do mirroring. We simply pass the remote URL and local filename to the agent's mirror() method, obtaining an HTTP::Response in return. We then print the status message returned by the response object's message() method. Simulating Fill-out Forms The previous two examples fetched static documents from remote Web servers. However, much of the interesting content on the Web is generated by dynamic server-side scripts such as search pages, on-line catalogs, and news updates. Server-side CGI scripts (as well as servlets and other types of dynamic content) are usually driven by fill-out HTML forms. Forms consist of a series of fields to complete: typically a mixture of text fields, pop-up menus , scrolling lists, and buttons . Each field has a name and a value. When the form is submitted, usually by clicking on a button, the names and current values of the form are bundled into a special format and sent to the server script. You can simulate the submission of a fill-out form from within LWP provided that you know what arguments the remote server is expecting and how it is expecting to receive them. Sometimes the remote Web site documents how to call its server-side scripts, but more often you have to reverse engineer the script by looking at the fill-out form's source code. For example, the Internet FAQ Consortium provides a search page at http://www.faqs.org/rfcs/ that includes, among other things, a form for searching the RFC archive with text search terms. By navigating to the page in a conventional browser and selecting the "View Source" command, I obtained the HTML source code for the page. Figure 9.6 shows an excerpt from this page, which contains the definition for the search form (it's been edited slightly to remove extraneous formatting tags). Figure 9.6. Definition of the HTML form used by the FAQ Consortium's RFC seach script  In HTML, fill-out forms start with a <FORM> tag and end with </FORM> . Between the two tags are one or more <INPUT> tags, which create simple fields like text entry fields and buttons, <SELECT> tags, which define multiple-choice fields like scrolling lists and pop-up menus, and <TEXTAREA> tags, which create large text entry fields with horizontal and vertical scrollbars. Form elements have a NAME attribute, which assigns a name to the field when it is sent to the Web server, and optionally a VALUE attribute, which assigns a default value to the field. <INPUT> tags may also have a TYPE attribute that alters the appearance of the field. For example, TYPE="text" creates a text field that the user can type in, TYPE="checkbox" creates an on/off checkbox, and TYPE="hidden" creates an element that isn't visible in the rendered HTML, but nevertheless has its name and value passed back to the server when the form is submitted. The <FORM> tag itself has two required attributes. METHOD specifies how the contents of the fill-out form are to be sent to the Web server, and may be one of GET and POST. We'll talk about the implications of the method later. ACTION specifies the URL to which the form fields are to be sent. It may be a full URL or an abbreviated form relative to the URL of the HTML page that contains the form. Occasionally, the ACTION attribute may be missing entirely, in which case the form fields should be submitted to the URL of the page in which the form is located. Strictly speaking, this is not valid HTML, but it is widely used. In the example in Figure 9.6, the RFC search form consists of two elements. A text field named "query" prompts the user for the text terms to search for, and a menu named "archive" specifies which part of the archive to search in. The various menu choices are specified using a series of <OPTION> tags, and include the values "rfcs", "rank", and "rfcindex". There is also a submission button, created using an <INPUT> tag with a TYPE attribute of "submit". However, because it has no NAME attribute, its contents are not included in the information to the server. Figure 9.7 shows what this looks like when rendered by a browser. Figure 9.7. The FAQ Consortium's fill-out form rendered by a browser 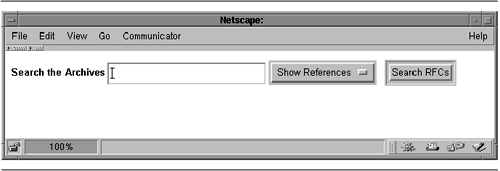 When the form is submitted, the browser bundles the current contents of the form into a "query string" using a MIME format known as application/x-www-form-urlencoded . This format consists of a series of name= value pairs, where the names and values are taken from the form elements and their current values. Each pair is separated by an ampersand ( & ) or semicolon ( ; ). For example, if we typed "MIME types" into the RFC search form's text field and selected "Search RFC Index" from the pop-up menu, the query string generated by the browser would be: query=MIME%20types&archive=rfcindex Notice that the space in "MIME types" has been turned into the string %20 . This is a hexadecimal escape for the space character (0x20 in ASCII). A number of characters are illegal in query strings, and must be escaped in this way. As we shall see, the URI::Escape module makes it easy to create escaped query strings. The way the browser sends the query string to the Web server depends on whether the form submission method is GET or POST. In the case of GET, a " ? " followed by the query string is appended directly to the end of the URL indicated by the <FORM> tag's ACTION attribute. For example: http://www.faqs.org/cgi-bin/rfcsearch?query=MIME%20types&archive=rfcindex In the case of a form that specifies the POST method, the correct action is to POST a request to the URL indicated by ACTION , and pass the query string as the request content. It is very important to send the query string to the remote server in the way specified by the <FORM> tag. Some server-side scripts are sufficiently flexible to recognize and deal with both GET and POST requests in a uniform way, but many do not. In addition to query strings of type application/x-www-form-urlencoded, some fill-out forms use a newer encoding system called multipart/form-data. We will talk about dealing with such forms in the section File Uploads Using multipart/form-data. Our next sample script is named search_rfc.pl. It invokes the server-side script located at http://www.faqs.org/cgi-bin/rfcsearch to search the RFC index for documents having some relevance to the search terms given on the command line. Here's how to search for the term "MIME types": % search_rfc.pl MIME types RFC 2503 MIME Types for Use with the ISO ILL Protocol RFC 1927 Suggested Additional MIME Types for Associating Documents search_rfc.pl works by simulating a user submission of the fill-out form shown in Figures 9.6 and 9.7. We generate a query string containing the query and archive fields, and POST it to the server-side search script. We then extract the desired information from the returned HTML document and print it out. To properly escape the query string, we use the uri_escape() function, provided by the LWP module named URI::Escape. uri_escape() replaces disallowed characters in URLs with their hexadecimal escapes . Its companion, uri_unescape() , reverses the process. Figure 9.8 shows the code for the script. Figure 9.8. The search_rfc.pl script  Lines 1 “4: Load modules We turn on strict syntax checking and load the LWP and URI::Escape modules. URI::Escape imports the uri_escape() and uri_unescape() functions automatically. Lines 5 “7: Define constants We define one constant for the URL of the remote search script, and another for the page on which the fill-out form is located. The latter is needed to properly fill out the Referer: field of the request, for reasons that we will explain momentarily. Lines 8 “10: Create user agent This code is identical to the previous examples, except for the user agent ID. Lines 11 “12: Construct query string We interpolate the command-line arguments into a string and use it as the value of the fill-out form's query field. We are interested in searching the archive's RFC index, so we use "rfcindex" as the value of the archive field. These are incorporated into a properly formatted query string and escaped using uri_escape() . Lines 13 “15: Construct request We create a new POST request on the remote search script, and use the returned request object's content() method to set the content to the query string. We also alter the request object's Referer: header so that it contains the fill-out form's URL. This is a precaution. For consistency, some server-side scripts check the Referer: field to confirm that the request came from a fill-out form located on their own server, and refuse to service requests that do not contain the proper value. Although the Internet FAQ Consortium's search script does not seem to implement such checks, we set the Referer: field here in case they decide to do so in the future. As an aside, the ease with which we are able to defeat the Referer: check illustrates why this type of check should never be relied on to protect server-side Web scripts from misuse. Lines 16 “17: Submit request We pass the request to the LWP::UserAgent's request() method, obtaining a response object. We check the response status with is_success() , and die if the method indicates a failure of some sort . Lines 18 “21: Fetch and parse content We retrieve the returned HTML document by calling the response object's content() method and assign it to a scalar variable. We now need to extract the RFC name and title from the document's HTML. This is easy to do because the document has the predictable structure shown in Figures 9.9 (screenshot) and 9.10 (HTML source). Each matching RFC is an item in an ordered list (HTML tag <OL> ) in which the RFC number is contained within an <A> tag that links to the text of the RFC, and the RFC title is contained between a pair of <STRONG> tags. Figure 9.9. RFC Index Search results 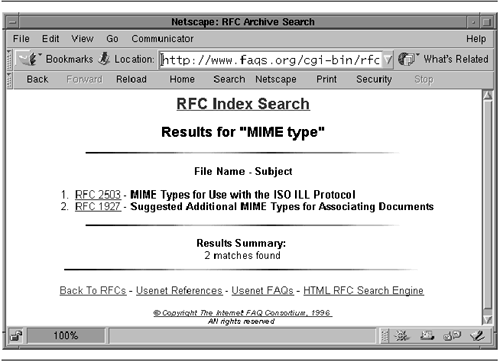 Figure 9.10. HTML code for the RFC Index Search results  We use a simple global regular expression match to find and match all lines referring to RFCs, extract the RFC name and title, and print the information to standard output. An enhancement to this script would be to provide an option to fetch the text of each RFC returned by the search. One way to do this would be to insert a call to $ua->request() for each matched RFC. Another, and more elegant, way would be to modify get_rfc.pl from Figure 9.4 so as to accept its list of RFC numbers from standard input. This would allow you to fetch the content of each RFC returned by a search by combining the two commands in a pipeline: % fetch_rfc.pl MIME type get_rfc.pl Because The Internet FAQ Consortium has not published the interface to its search script, there is no guarantee that they will not change either the form of the query string or the format of the HTML document returned in response to searches. If either of these things happen, search_rfc.pl will break. This is a chronic problem for all such Web client scripts and a compelling reason to check at each step of a complex script that the remote Web server is returning the results you expect. This script contains a subtle bug in the way it constructs its query strings. Can you find it? The bug is revealed in the next section. Using HTTP::Request::Common to Post a Fill-out Form Because submitting the field values from fill-out forms is so common, LWP provides a class named HTTP::Request::Common to make this convenient to do. When you load HTTP::Request::Common, it imports four functions named GET() , POST() , HEAD() , and PUT() , which build various types of HTTP::Request objects. We will look at the POST() function, which builds HTTP::Request objects suitable for simulating fill-out form submissions. The other three are similar. | $request = POST($url [,$form_ref] [,$header1=>$val1....]) The POST() function returns an HTTP::Request object that uses the POST method. $url is the requested URL, and may be a simple string or a URI object. The optional $form_ref argument is an array reference containing the names and values of form fields to submit as content. If you wish to add additional headers to the request, you can follow this with a list of header/value pairs. | Using POST() here's how we could construct a request to the Internet FAQ Consortium's RFC index search engine: my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch', [ query => 'MIME types', archive => 'rfcindex' ] ); And here's how to do the same thing but setting the Referer: header at the same time: my $request =POST('http://www.faqs.org/cgi-bin/rfcsearch', [ query => 'MIME types', archive => 'rfcindex' ], Referer => 'http://www.faqs.org/rfcs'); Notice that the field/value pairs of the request content are contained in an array reference, but the name/value pairs of the request headers are a simple list. As an alternative, you may provide the form data as the argument to a pseudoheader field named Content:. This looks a bit cleaner when setting both request headers and form content: my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch', Content => [ query => 'MIME types', archive => 'rfcindex' ], Referer => 'http://www.faqs.org/rfcs'); POST() will take care of URI escaping the form fields and constructing the appropriate query string. Using HTTP::Request::Common, we can rewrite search_rfc.pl as shown in Figure 9.11. The new version is identical to the old except that it uses POST() to construct the fill-out form submission and to set the Referer: field of the outgoing request (lines 12 “17). Compared to the original version of the search_rfc.pl script, the new script is easier to read. More significant, however, it is less prone to bugs . The query-string generator from the earlier versions contains a bug that causes it to generate broken query strings when given a search term that contains either of the characters "&" or "=". For example, given the query string "mime&types", the original version generates the string: Figure 9.11. An improved version of search_rfc.pl  query=mime&types&archive=rfcindex The manual fix would be to replace " & " with " %26 " and " = " with " %3D " in the search terms before constructing the query string and passing it to uri_escape() . However, the POST() -based version handles this automatically, and generates the correct content: query=mime%26types&archive=rfcindex File Uploads Using multipart/form-data In addition to form elements that allow users to type in text data, HTML version 4 and higher provides an <INPUT> element of type "file". When compatible browsers render this tag, they generate a user interface element that prompts the user for a file to upload. When the form is submitted, the browser opens the file and sends it contents, allowing whole files to be uploaded to a server-side Web script. However, this feature is not very compatible with the application/x-www-form-urlencoded encoding of query strings because of the size and complexity of most uploaded files. Server scripts that support this feature use a different type of query encoding scheme called multipart/form-data . Forms that support this encoding are enclosed in a <FORM> tag with an ENCTYPE attribute that specifies this scheme. For instance: <FORM METHOD=POST ACTION="/cgi-bin/upload" ENCTYPE="multipart/form-data"> The POST method is always used with this type of encoding. multipart/form-data uses an encoding scheme that is extremely similar to the one used for multipart MIME enclosures. Each form element is given its own subpart with a Content-Disposition: of "form-data", a name containing the field name, and body data containing the value of the field. For uploaded files, the body data is the content of the file. Although conceptually simple, it's tricky to generate the multipart/form-data format correctly. Fortunately, the POST() function provided by HTTP::Request:: Common can also generate requests compatible with multipart/form-data . The key is to provide POST() with a Content_Type: header argument of "form-data": my $request = POST('http://www.faqs.org/cgi-bin/rfcsearch', Content_Type => 'form-data', Referer => 'http://www.faqs.org/rfcs', Content => [ query => 'MIME types', archive => 'rfcindex' ] ); This generates a request to the RFC search engine using the multipart/form-data encoding scheme. But don't try it: the RFC FAQ site doesn't know how to handle this scheme. To tell LWP to upload a file, the value of the corresponding form field must be an array reference containing at least one element: $fieldname => [ $file, $filename, header1=>$value.... ] The mandatory first element in the array, $file , is the path to the file to upload. The optional $filename argument is the suggested name to use for the file, and is similar to the MIME::Entity Filename argument. This is followed by any number of additional MIME headers. The one used most frequently is Content_Type:, which gives the server script the MIME type of the uploaded file. To illustrate how this works, we'll write a client for the CGI script located at http://stein.cshl.org/WWW/software/CGI/examples/file_upload.cgi. This is a script that I wrote some years ago to illustrate how CGI scripts accept and process uploaded files. The form that drives the script (Figures 9.12 and 9.14) contains a single file field named filename , and three checkboxes named count with values named "count lines" , "count words" , and "count characters" . There's also a hidden field named .cgifields with a value of "count." Figure 9.12. The form that drives the file_upload.cqi script 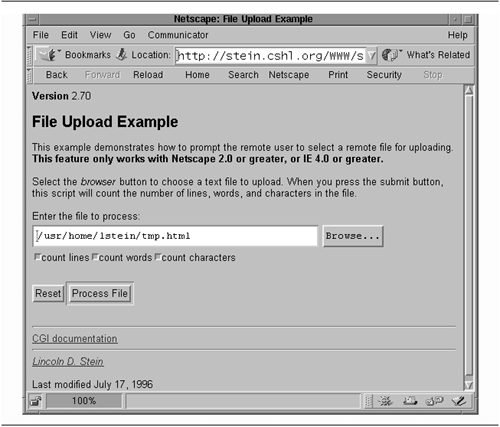 Figure 9.14. Output from file_upload.cqi script 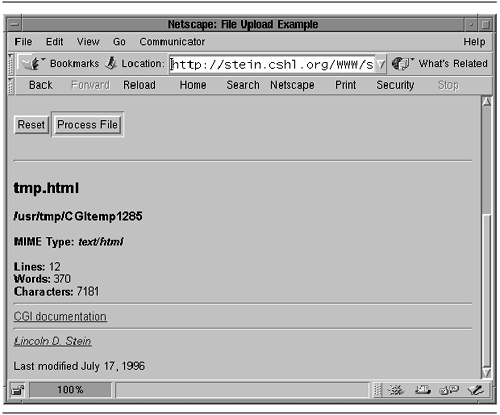 After form submission, the script reads the uploaded file and counts its lines, words, and/or characters, depending on which checkboxes are selected. It prints these statistics, along with the name of the file and its MIME type, if any (Figure 9.13). Figure 9.13. HTML source for the file_upload.cqi form  We will now develop an LWP script to drive this CGI script. remote_wc.pl reads a file from the command line or standard input and uploads it to file_upload.cgi . It parses the HTML result and prints the word count returned by the remote server: % remote_wc.pl ~/public_html/png.html lines = 20; words = 47; characters = 362 This is a pretty difficult way to perform a word count, but it does illustrate the technique! Figure 9.15 gives the code for remote_wc.pl . Figure 9.15. The remote_wc.pl script  Lines 1 “4: Load modules We turn on strict syntax checking and load the LWP and HTTP::Request::Common modules. Lines 5 “7: Process arguments We define a constant for the URL of the CGI script and recover the name of the file to upload from the command line. Lines 8 “21: Create user agent and request We create the LWP::UserAgent in the usual way. We then create the request using the POST() function, passing the URL of the CGI script as the first argument, a Content_Type argument of "form-data", and a Content argument containing the various fields used by the upload form. Notice that the count field appears three times in the Content array, once for each of the checkboxes in the form. The value of the filename field is an anonymous array containing the file path provided on the command line. We also provide values for the .cgifields hidden field and the submit button, even though it isn't clear that they are necessary (they aren't, but unless you have the documentation for the remote server script, you won't know this). Lines 22 “23: Issue request We call the user agent's request() method to issue the POST, and get a response object in return. As in earlier scripts, we check the is_success() method and die if an error occurs. Lines 24 “27: Extract results We call the response's content() method to retrieve the HTML document generated by the remote script, and perform a pattern match on it to extract the values for the line, word, and character counts (this regular expression was generated after some experimentation with sample HTML output). Before exiting, we print the extracted values to standard output. Fetching a Password-Protected Page Some Web pages are protected by username and password using HTTP authentication. LWP can handle the authentication protocol, but needs to know the username and password. There are two ways to provide LWP with this information. One way is to store the username and password in the user agent's instance variables using its credentials() method. As described earlier, credentials() stores the authentication information in a hash table indexed by the Web server's hostname, port, and realm. If you store a set of passwords before making the first request, LWP::UserAgent consults this table to find a username and password to use when accessing a protected page. This is the default behavior of the get_basic_credentials() method. The other way is to ask the user for help at runtime. You do this by subclassing LWP::UserAgent and overriding the get_basic_credentials() method. When invoked, the customized get_basic_credentials() prompts the user to enter the required information. The get_url2.pl script implements this latter scheme. For unprotected pages, it acts just like the original get_url.pl script (Figure 9.1). However, when fetching a protected page, it prompts the user to enter his or her username and password. If the name and password are accepted, the URL is copied to standard output. Otherwise, the request fails with an "Authorization Required" error (status code 401): % get_url2.pl http://stein.cshl.org/private/ Enter username and password for realm "example". username: perl password: programmer <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN"> <html> <head> <title>Password Protected Page</title> <link rel="stylesheet" href="/stylesheets/default.css"> </head> ... If you wish to try this script with the URL given in the example, the username is "perl" and the password is "programmer." Figure 9.16 shows the code for get_url2.pl . Except for an odd little idiom, it's straightforward. We are going to declare a subclass of LWP::UserAgent, but we don't want to create a whole module file just to override a single method. Instead, we arrange for the script itself (package "main") to be a subclass of LWP::UserAgent, and override the get_basic_credentials() method directly in the main script file. This is a common, and handy, trick. Figure 9.16. The get_url2.pl script  Lines 1 “6: Load modules We turn on strict syntax checking and load LWP. We also load the PromptUtil module (listed in Appendix A), which provides us with the get_passwd() function for prompting the user for a password without echoing it to the screen. We set the @ISA array to make sure that the current package is a subclass of LWP::UserAgent. Lines 7 “12: Issue request, print content The main section of the script is identical to the original get_url.pl , with one exception. Instead of calling LWP::User Agent->new() to create a new user agent object, we call _PACKAGE->new() . The Perl interpreter automatically replaces the _PACKAGE_ token with the name of the current package ("main" in this case), creating the desired LWP::UserAgent subclass. Lines 13 “20: Override get_basic_credentials() method This section of the code overrides get_basic_credentials() with a custom subroutine. The subclass behaves exactly like LWP::UserAgent until it needs to fetch authentication information, at which point this subroutine is invoked. We are called with three arguments, consisting of the user agent object, the authentication realm, and the URL that has been requested. We prompt the user for a username, and then call get_passwd() to prompt and fetch the user's password. These are returned to the caller as a two-element list. An interesting characteristic of this script is that if the username and password aren't entered correctly the first time, LWP invokes the get_basic_credentials() once more and the user is prompted to try again. If the credentials still aren't accepted, the request fails with an "Authorization Required" status. This nice "second try" feature appears to be built into LWP. Parsing HTML and XML Much of the information on the Web is now stored in the form of HTML documents. So far we have dealt with HTML documents in an ad hoc manner by writing regular expressions to parse out the particular information we want from a Web page. However, LWP offers a more general solution to this. The HTML::Parser class provides flexible parsing of HTML documents, and HTML::Formatter can format HTML as text or PostScript. An added benefit of HTML::Parser is that at the throw of a switch it can handle XML (eXtensible Markup Language) as well. Because HTML was designed to display human-readable documents, it doesn't lend itself easily to automated machine processing. XML provides structured, easily parsed documents that are more software-friendly than traditional HTML. Over the next few years, HTML will gradually be replaced by XHTML, a version of HTML that follows XML's more exacting standards. HTML::Parser can handle HTML, XML, and XHTML, and in fact can be used to parse much of the more general SGML (Standard Generalized Markup Language) from which both HTML and XML derive. The XML standard and a variety of tutorials can be found at [http://www.w3.org/XML/]. In this section, we demonstrate how to use HTML::Formatter to transform HTML into nicely formatted plain text or postscript. Then we show some examples of using HTML::Parser for the more general task of extracting information from HTML files. Formatting HTML The HTML::Formatter module is the base class for a family of HTML formatters. Only two members of the family are currently implemented. HTML::FormatText takes an HTML document and produces nicely formatted plain text, and HTML::FormatPS creates postscript output. Neither subclass of HTML::Formatter handles inline images, forms, or tables. In some cases, this can be a big limitation. There are two steps to formatting an HTML file. The first step is to parse the HTML into a parse tree, using a specialized subclass of HTML::Parser named HTML::TreeBuilder. The second step is to pass this parse tree to the desired subclass of HTML::Formatter to output the formatted text. Figure 9.17 shows a script named format_html.pl that uses these modules to read an HTML file from the command line or standard input and format it. If given the ” postscript option, the script produces postscript output suitable for printing. Otherwise, it produces plain text. Figure 9.17. The format_html.pl script  Lines 1 “4: Load modules We turn on strict syntax checking and load the Getopt::Long and HTML:TreeBuilder modules. The former processes the command-line arguments, if any. We don't load any HTML::Formatter modules at this time because we don't know yet whether to produce plain text or postscript. Lines 5 “7: Process command-line options We call the GetOptions() function to parse the command-line options. This sets the global variable $PS to true if the ” postscript option is specified. Lines 8 “15: Create appropriate formatter If the user requested postscript output, we load the HTML::FormatPS module and invoke the class's new() method to create a new formatter object. Otherwise, we do the same thing with the HTML:: FormatText class. When creating an HTML::FormatPS formatter, we pass the new() method a PaperSize argument of "Letter" in order to create output compatible with the common 81/2 x 11" letter stock used in the United States. Lines 16 “18: Parse HTML We create a new HTML::TreeBuilder parser by calling the class's new() method. We then read the input HTML one line at a time using the <> operator and pass it to the parser object. When we are done, we tell the parser so by calling its eof() method. This series of operations leaves the HTML parse tree in the parser object itself, in a variable named $tree . Line 19 “20: Format and output the tree We pass the parse tree to the formatter's format() method, yielding a formatted string. We print this, and then clean up the parse tree by calling is delete() method. The HTML::Formatter API The API for HTML::Formatter and its subclasses is extremely simple. You create a new formatter with new() and perform the formatting with format() . A handful of arguments recognized by new() adjust the formatting style. | $formatter = HTML::FormatText->new([leftmargin=>$left,rightmargin=>$right]) HTML::FormatText->new() takes two optional arguments, leftmargin and rightmargin , which set the left and right page margins, respectively. The margins are measured in characters. If not specified, the left and right margins default to 3 and 72, respectively. It returns a formatter object ready for use in converting HTML to text. $formatter = HTML::FormatPS->new([option1=>$val1, option2=>$val2...]) Similarly, HTML::FormatPS->new() creates a new formatter object suitable for rendering HTML into postscript. It accepts a larger list of argument/value pairs, the most common of which are listed here: -
PaperSize sets the page height and width appropriately for printing. Acceptable values are A3, A4, A5, B4, B5, Letter, Legal, Executive, Tabloid, Statement, Folio, 10x14, and Quarto. United States users take note! The default PaperSize is the European A4. You should change this to Letter if you wish to print on common 81/2 x 11" paper. -
LeftMargin, RightMargin, TopMargin , and BottomMargin control the page margins. All are given in point units. -
FontFamily sets the font family to use in the output. Recognized values are Courier, Helvetica, and Times, the default. -
FontScale allows you to increase or decrease the font size by some factor. For example, a value of 1.5 will scale the font size up by 50 percent. | Once a formatter is created, you can use it as many times as you like to format HTML::TreeBuilder objects. | $text = $formatter->format($tree) Pass an HTML parse tree to the format() method. The returned value is a scalar variable, which you can then print, save to disk, or send to a print spooler. | The HTML::TreeBuilder API The basic API for HTML::TreeBuilder is also straightforward. You create a new HTML::TreeBuilder object by calling the class's new() method, then parse a document using parse() or parse_file() , and when you're done, destroy the object using delete() . | $tree = HTML::TreeBuilder->new The new() method takes no arguments. It returns a new, empty HTML::TreeBuilder object. $result = $tree->parse_file($file) The parse_file() method accepts a filename or filehandle and parses its contents, storing the parse tree directly in the HTML::TreeBuilder object. If the parse was successful, the result is a copy of the tree object; if something went wrong (check $! for the error message), the result is undef . | For example, we can parse an HTML file directly like this: $tree->parse_file('rfc2010.html') or die "Couldn't parse: $!"; and parse from a filehandle like this: open (F,'rfc2010.html') or die "Couldn't open: $!"; $tree->parse_file(\*F); | $result = $tree->parse($data) With the parse() method, you can parse an HTML file in chunks of arbitrary size. $data is a scalar that contains the HTML text to process. Typically you will call parse() multiple times, each time with the next section of the document to process. We will see later how to take advantage of this feature to begin HTML parsing while the file is downloading. If something goes wrong during parsing, parse() returns undef . If parse() is successful, it will return a copy of the HTML::TreeBuilder object, undef otherwise. $tree->eof Call this method when using parse() . It tells HTML::TreeBuilder that no more data is coming and allows it to finish the parse. | Figure 9.16 is a good example of using parse() and eof() to parse the HTML file on standard input one line at a time. | $tree->delete When you are finished with an HTML::TreeBuilder tree, call its delete() method to clean up. Unlike other Perl objects, which are automatically destroyed when they go out of scope, you must be careful to call delete() explicitly when working with HTML::TreeBuilder objects or risk memory leaks. The HTML::Element POD documentation explains why this is so. | Many scripts combine HTML::TreeBuilder object creation with file parsing using this idom: $tree = HTML::TreeBuilder->new->parse_file('rfc2010.html'); However, the HTML::TreeBuilder object created this way will never be deleted, and will leak memory. If you are parsing files in a loop, always create the HTML::TreeBuilder object, call its parse_file() method, and then call its delete() method. The parse tree returned by HTML::TreeBuilder is actually a very feature-rich object. You can recursively descend through its nodes to extract information from the HTML file, extract hypertext links, modify selected HTML elements, and then convert the whole thing back into printable HTML. However, the same functionality is also available in a more flexible form in the HTML::Parser class, which we cover later in this chapter. For details, see the HTML::TreeBuilder and HTML::Element POD documentation. Returning Formatted HTML from the get_url.pl Script We'll now rewrite get_url.pl a third time in order to take advantage of the formatting features offered by HTML::FormatText. When the new script, imaginatively christened get_url3.pl, detects an HTML document, it automatically converts it into formatted text. The interesting feature of this script is that we combine LWP::UserAgent's request callback mechanism with the HTML::TreeBuilder parse() method to begin the parse as the HTML document is downloading. When we parallelize downloading and parsing, the script executes significantly faster. Figure 9.18 shows the code. Figure 9.18. The get_url3.pl script  Lines 1 “6: Load modules We bring in LWP, PromptUtil, HTML::FormatText, and the HTML::TreeBuilder modules. Lines 7 “11: Set up request We set up the HTTP::Request as we did in earlier iterations of this script. Again, when required, we prompt the user for authentication information so the script is made a subclass of LWP::UserAgent so that we can override the get_basic_credentials() method. Lines 12 “14: Send the request We send the request using the agent's request() , method. However, instead of allowing LWP to leave the returned content in the HTTP::Response object for retrieval, we give request() a second argument containing a reference to the process_document() subroutine. This subroutine is responsible for parsing incoming HTML documents. process_document() leaves the HTML parse tree, if any, in the global variable $html_tree , which we declare here. After the request() is finished, we check the status of the returned HTTP::Response object and die with an explanatory error message if the request failed for some reason. Lines 15 “20: Format and print the HTML If the requested document is HTML, then process_document() has parsed it and left the tree in $html_tree . We check to see whether the tree is nonempty . If so, we call its eof() method to tell the parser to finish, and pass the tree to a newly created HTML::FormatText object to create a formatted string that we immediately print. We are now done with the parse tree, so we call its delete() method. As we shall see, process_document() prints all non-HTML documents immediately, so there's no need to take further action for non-HTML documents. Lines 21 “29: The process_document () subroutine LWP::UserAgent invokes call-backs with three arguments consisting of the downloaded data, the current HTTP::Response object, and an LWP::Protocol object. We call the response object's content_type() method to get the MIME type of the incoming document. If the type is text/html , then we pass the data to the parse tree's parse() method. If necessary, we create the HTML::TreeBuilder first, using the = operator so that the call to HTML::TreeBuilder->new() is executed only if the $html_tree variable is undefined. If the content type is something other than text/html , then we immediately print the data. This is a significant improvement to earlier versions of get_url.pl because it means that non-HTML data starts to appear on standard output as soon as it arrives from the remote server. Lines 30 “38: The get_basic_credentials() subroutine This is the same subroutine we looked at in get_url2.pl . This script does not check for the case in which the response does not provide a content type. Strictly speaking it should do so, as the HTTP specification allows (but strongly discourages) Web servers to omit this field. Run the script with the -w switch to detect and report this case. Useful enhancements to get_url3.pl might include using HTML::FormatPS for printing support, or adapting the script to use external viewers to display non-HTML MIME types the way we did in the pop_fetch.pl script of Chapter 8. The HTML::Parser Module HTML::Parser is a powerful but complex module that allows you to parse HTML and XML documents. Part of the complexity is inherent in the structure of HTML itself, and part of it is due to the fact that there are two distinct APIs for HTML::Parser, one used by version 2.2X of the module and the other used in the current 3.X series. HTML and XML are organized around a hierarchical series of markup tags. Tags are enclosed by angle brackets and have a name and a series of attributes. For example, this tag <img src="/icons/arrow.gif" alt="arrow"> has the name img and the two attributes src and alt . In HTML, tags can be paired or unpaired. Paired tags enclose some content, which can be plain text or can contain other tags. For example, this fragment of HTML <p>Oh dear, now the <strong>bird</strong> is gone!</p> consists of a paragraph section, starting with the <p> tag and ending with its mate, the </p> tag. Between the two is a line of text, a portion of which is itself enclosed in a pair of <strong> tags (indicating strongly emphatic text). HTML and XML both constrain which tags can occur within others. For example, a <title> section, which designates some text as the title of a document, can occur only in the <head> section of an HTML document, which in turn must occur in an <html> section. See Figure 9.19 for a very minimal HTML document. Figure 9.19. A skeletal HTML document  In addition to tags, an HTML document may contain comments, which are ignored by rendering programs. Comments begin with the characters <!-- and end with --> as in: <!-- ignore this --> HTML files may also contain markup declarations, contained within the characters <! and > . These provide meta-information to validators and parsers. The only HTML declaration you are likely to see is the <!DOCTYPE ...> declaration at the top of the file that indicates the version of HTML the document is (or claims to be) using. See the top of Figure 9.19 for an example. Because the "<" and ">" symbols have special significance, all occurrences of these characters in proper HTML have to be escaped to the "character entities" < and > , respectively. The ampersand has to be escaped as well, to & . Many other character entities are used to represent nonstandard symbols such as the copyright sign or the German umlaut. XML syntax is a stricter and regularized version of HTMLs. Instead of allowing both paired and unpaired tags, XML requires all tags to be paired. Tag and attribute names are case sensitive (HTML's are not), and all attribute values must be enclosed by double quotes. If an element is empty, meaning that there is nothing between the start and end tags, XML allows you to abbreviate this as an "empty element" tag. This is a start tag that begins with < tagname and ends with /> . As an illustration of this, consider these two XML fragments , both of which have exactly the same meaning: <img src="/icons/arrow.gif" alt="arrow"></img> <img src="/icons/arrow.gif" alt="arrow" /> Using HTML::Parser HTML::Parser is event driven. It parses through an HTML document, starting at the top and traversing the tags and subtags in order until it reaches the end. To use it, you install handlers for events that you are interested in processing, such as encountering a start tag. Your handler will be called each time the desired event occurs. Before we get heavily into the HTML::Parser, we'll look at a basic example. The print_links.pl script parses the HTML document presented to it on the command line or standard input, extracts all the links and images, and prints out their URLs. In the following example, we use get_url2.pl to fetch the Google search engine's home page and pipe its output to print_links.pl : % get_url2.pl http://www.google.com print_links.pl img: images/title_homepage2.gif link: advanced_search.html link: preferences.html link: link_NPD.html link: jobs.html link: http://directory.google.com link: adv/intro.html link: websearch_programs.html link: buttons.html link: about.html Figure 9.20 shows the code for print_links.pl. Figure 9.20. The print_links.pl script  Lines 1 “3: Load modules After turning on strict syntax checking, we load HTML:: Parser. This is the only module we need. Lines 4 “5: Create and initialize the parser object We create a new HTML::Parser object by calling its new() method. For reasons explained in the next section, we tell new() to use the version 3 API by passing it the api_version argument. After creating the parser, we configure it by calling its handler() method to install a handler for start tag events. The start argument points to a reference to our print_link() subroutine; this subroutine is invoked every time the parser encounters a start tag. The third argument to handler() tells HTML:: Parser what arguments to pass to our handler when it is called. We request that the parser pass print_link() the name of the tag ( tagname ) and a hash reference containing the tag's attributes ( attr ). Lines 6 “7: Parse standard input We now call the parser's parse() method, passing it lines read via the <> function. When we reach the end of file, we call the parser's eof() method to tell it to finish up. The parse() and eof() methods behave identically to the HTML::TreeBuilder methods we looked at earlier. Lines 8 “15: The print_link() callback Most of the program logic occurs in print_link() . This subroutine is called during the parse every time the parser encounters a start tag. As we specified when we installed the handler, the parser passes the subroutine the name of the tag and a hash reference containing the tag's attributes. Both the tag name and all the attribute names are automatically transformed to lowercase letters , making it easier to deal with the rampant variations in case used in most HTML. We are interested only in hypertext links, the <a> tag, and inline images, the <img> tag. If the tag name is "a", we print a line labeled "link:" followed by the contents of the href attribute. If, on the other hand, the tag name is "img", we print "img:" followed by the contents of the src attribute. For any other tag, we do nothing. The HTML::Parser API HTML::Parser has two APIs. In the earlier API, which was used through version 2 of the module, you install handlers for various events by subclassing the module and overriding methods named start() , end() , and text() . In the current API, introduced in version 3.0 of the module, you call handler() to install event callbacks as we did in Figure 9.20. You may still see code that uses the older API, and HTML::Parser goes to pains to maintain compatibility with the older API. In this section, however, we highlight only the most useful parts of the version 3 API. See the HTML::Parser POD documentation for more information on how to control the module's many options. To create a new parser, call HTML::Parser->new() . | $parser = HTML::Parser->new(@options) The new() method creates a new HTML::Parser. @options is a series of option/value pairs that change various parser settings. The most used option is api_version , which can be "2" to create a version 2 parser, or "3" to create a version 3 parser. For backward compatibility, if you do not specify any options new() creates a version 2 parser. | Once the parser is created, you will call handler() one or more times to install handlers. | $parser->handler($event => \&handler, $args) The handler() method installs a handler for a parse event. $event is the name of the event, &handler contains a reference to the callback subroutine to handle it, and $args is a string telling HTML::Parser what information about the event the subroutine wishes to receive. | The event name is one of start, end, text, comment, declaration, process , or default . The first three events are the most common. A start event is generated whenever the parser encounters a start tag, such as <strong> . An end event is triggered when the parser encounters an end tag, such as </strong> . text events are generated for the text between tags. The comment event is generated for HTML comments. declaration and process events apply primarily to XML elements. Last, the default event is a catchall for anything that is not explicitly handled elsewhere. $args is a string containing a comma-delimited list of information that you want the parser to pass to the handler. The information will be passed as subroutine arguments in the exact order that they appear in the $args list. There are many possible arguments. Here are some of the most useful: -
tagname the name of the tag -
text the full text that triggered the event, including the markup delimiters -
dtext decoded text, with markup removed and entities translated -
attr a reference to a hash containing the tag attributes and values -
self a copy of the HTML::Parser object itself -
"string" the literal string (single or double quotes required!) For example, this call causes the get_text() handler to be invoked every time the parser processes some content text. The argument passed to the handler will be a three-element list that contains the parser object, the literal string "TEXT", and the decoded content text: $parser->handler('text'=>\&get_text, "self,'TEXT',dtext"); -
tagname is most useful in conjunction with start and end events. Tags are automatically downcased, so that <UL> , <ul> , and <Ul> are all given to the handler as "ul". In the case of end tags, the "/" is suppressed, so that an end handler receives "ul" when a </ul> tag is encountered . -
dtext is used most often in conjunction with text events. It returns the nontag content of the document, with all character entities translated to their proper values. -
The attr hash reference is useful only with start events. If requested for other events, the hash reference will be empty. Passing handler() a second argument of undef removes the handler for the specified event, restoring the default behavior. An empty string causes the event to be ignored entirely. | $parser->handler($event =>\@array, $args) Instead of having a subroutine invoked every time the parser triggers an event, you can have the parser fill an array with the information that would have been passed to it, then examine the array at your leisure after the parse is finished. To do this, use an array reference as the second argument to handler() . When the parse is done, the array will contain one element for each occurrence of the specified event, and each element will be an anonymous array containing the information specified by $args . | Once initialized , you trigger the parse with parse_file() or parse() . | $result = $parser->parse_file($file) $result = $parser->parse($data) $parser->eof The parse_file(), parse() , and eof() methods work exactly as they do for HTML::TreeBuilder. A handler that wishes to terminate parsing early can call the parser object's eof() method. | Two methods are commonly used to tweak the parser. | $bool = $parser->unbroken_text([$bool]) When processing chunks of content text, HTML::Parser ordinarily passes them to the text handler one chunk at a time, breaking text at word boundaries. If unbroken_text() is set to a true value, this behavior changes so that all the text between two tags is passed to the handler in a single operation. This can make some pattern matches easier. $bool = $parser->xml_mode([$bool]) The xml_mode() method puts the parser into a mode compatible with XML documents. This has two major effects. First, it allows the empty element construct, <tagname/> . When the parser encounters a tag like this one, it generates two events, a start event and an end event. Second, XML mode disables the automatic conversion of tag and attribute names into lowercase. This is because XML, unlike HTML, is case sensitive. | search_rfc.pl Using HTML::Parser We'll now rewrite search_rfc.pl (Figures 9.8 and 9.10) to use HTML::Parser. Instead of using an ad hoc pattern match to find the RFC names in the search response document, we'll install handlers to detect the appropriate parts of the document, extract the needed information, and print the results. Recall that the matching RFCs are in an ordered list ( <OL> ) section and have the following format: <OL> <LI><A HREF="ref1">rfc name 1</A> - <STRONG>description 1</STRONG> <LI><A HREF="ref2">rfc name 2</A> - <STRONG>description 2</STRONG> ... </OL> We want the parser to extract and print the text located within <A> and <STRONG> elements, but only those located within an <OL> section. The text from other parts of the document, even those in other <A> and <STRONG> elements, are to be ignored. The strategy that we will adopt is to have the start handler detect when an <OL> tag has been encountered, and to install a text handler to intercept and print the content of any subsequent <A> and <STRONG> elements. An end handler will detect the </OL> tag, and remove the text handler, so that other text is not printed. Figure 9.21 shows this new version, named search_rfc3.pl . Figure 9.21. The search_rfc3.pl script  Lines 1 “5: Load modules In addition to the LWP and HTTP::Request::Common modules, we load HTML::Parser. Lines 6 “18: Set up search We create an LWP::UserAgent and a new HTTP::Request in the same way as in the previous incarnation of this script. Lines 19 “20: Create HTML::Parser We create a new version 3 HTML::Parser object, and install a handler for the start event. The handler will be the start() subroutine, and it will receive a copy of the parser object and the name of the tag. Lines 21 “22: Issue request and parse We call the user agent's request() method to process the request. As in the print_links.pl script (Figure 9.20), we use a code reference as the second argument to request() so that we can begin processing incoming data as soon as it arrives. In this case, the code reference is an anonymous subroutine that invokes the parser's parse() method. After the request is finished, we call the parser's eof() method to have it finish up. Line 23: Warn of error conditions If the response object's is_success() method returns false, we die with an error message. Otherwise, we do nothing: The parser callbacks are responsible for extracting and printing the relevant information from the document. Lines 24 “31: The start() subroutine The start() subroutine is the callback for the start event. It is called whenever the parser encounters a start tag. We begin by recovering the parser object and the tag name from the stack. We need to remember the tag later when we are processing text, so we stash it in the parser object under the key last-tag. (The HTML::Parser POD documentation informs us that the parser is a blessed hash reference, and specifically invites us to store information there in this manner.) If the tag is anything other than "ol", we do nothing and just return. Otherwise, we install two new handlers. One is a handler for the text event. It will be passed the parser object and the decoded text. The other is a handler for the end event. Like start() , it will be passed the parser object and the name of the end tag. Lines 32 “38: The end() subroutine The end() subroutine is the handler for the end event. It begins by resetting the last_tag key in the parser object. If the end tag isn't equal to "ol", we just return, doing nothing. Otherwise, we set both the text and the end handlers to undef , disabling them. Lines 39 “45: The extract() subroutine extract() is the handler for the text event, and is the place where the results from the search are extracted and printed. We get a copy of the parser object and the decoded text on the subroutine call stack. After stripping whitespace from the text, we examine the value of the last_tag key stored in the parser object. If the last tag is "a", then we are in the <A> section that contains the name of the RFC. We print the text, followed by a tab. If the last tag is "strong", then we are in the section of the document that contains the title of the RFC. We print that, followed by a newline. The new version of search_rfc.pl is more than twice as long as the original, but it adds no new features, so what good is it? In this case, a full-blown parse of the search results document is overkill. However, there will be cases when you need to parse a complex HTML document and regular expressions will become too cumbersome to use. In these cases, HTML::Parser is a life saver. Extracting Images from a Remote URL To tie all the elements of this chapter together, our last example is an application that mirrors all the images in an HTML document at a specified URL. Given a list of one or more URLs on the command line, mirror_images.pl retrieves each document, parses it to find all inline images, and then fetches the images to the current directory using the mirror() method. To keep the mirrored images up to date, this script can be run repeatedly. As the script runs, it prints the local name for the image. For example, here's what happened when I pointed the script at http://www.yahoo.com/: % mirror_images.pl http://www.yahoo.com m5v2.gif: OK messengerpromo.gif: OK sm.gif: OK Running it again immediately gives three "Not Modified" messages. Figure 9.22 gives the complete code listing for the script. Figure 9.22. The mirror_images.pl script  Lines 1 “7: Load modules We turn on strict syntax checking and load the LWP, PromptUtil, HTTP::Cookies, HTML::Parser, and URI modules. The last module is used for its ability to resolve relative URLs into absolute URLs. Lines 8 “11: Create the user agent We again use the trick of subclassing LWP::User Agent to override the get_basic_credentials() method. The agent is stored in a variable named $agent . Some of the remote sites we contact might require HTTP cookies, so we initialize an HTTP::Cookies object on a file in our home directory and pass it to the agent's cookie_jar() method. This allows the script to exchange cookies with the remote sites automatically. Lines 12 “15: Create the request and the parser We enter a loop in which we shift URLs off the command line and process them. For each URL, we create a new GET request using HTTP::Request->new() , and an HTML::Parser object to parse the document as it comes in. We install the subroutine start() as the parse handler for the start event. This handler will receive a copy of the parser object, the name of the start tag, and a hash reference containing the tag's attributes and their values. Lines 16 “24: Issue the request We call the agent's request() method to issue the request, returning a response object. As in the last example, we provide request() with a code reference as the second argument, causing the agent to pass the incoming data to this subroutine as it arrives. In this case, the code reference is an anonymous subroutine. We first check that the MIME type of the response is text/html . If it isn't, we die with an error message. This doesn't cause the script as a whole to die, but does abort processing of the current URL and leaves the error message in a special X-Died: field of the response header. Otherwise, the incoming document is parseable as an HTML file. Our handler is going to need two pieces of extra information: the base URL of the current response for use in resolving relative URLs, and the user agent object so that we can issue requests for inline images. We use the same technique as in Figure 9.21, and stash this information into the parser's hash reference. Lines 25 “27: Warn of error conditions After the request has finished, we check the response for the existence of the X-Died: header and, if it exists, issue a warning. Likewise, we print the response's status message if the is_success() method returns false. Lines 28 “37: The start() handler The start() subroutine is invoked by the parser to handle start tags. As called for by the argument list passed to handler() , the subroutine receives a copy of the parser object, the name of the current tag, and a hash reference containing tag attributes. We check whether we are processing an <IMG> tag. If not, we return without taking further action. We then check that the tag's src attribute is defined, and if so, copy it to a local variable. The src attribute contains the URL of the inline image, and may be an absolute URL like http://www. yahoo.com/images/messengerpromo.gif , or a relative one like images/messengerpromo.gif . To fetch image source data, we must resolve relative URLs into absolute URLs so that we can request them via the LWP user agent. We must also construct a local filename for our copy of the image. Absolutizing relative URLs is an easy task thanks to the URI module. The URI->new_abs() method constructs a complete URL given a relative URL and a base. We obtain the base URL of the document containing the image by retrieving the "base" key from the parser hash where we stashed it earlier. This is passed to new_abs() along with the URL of the image (line 33), obtaining an absolute URL. If the URL was already absolute, calling new_abs() doesn't hurt. The method detects this fact and passes the URL through unchanged. Constructing the local filename is a matter of extracting the filename part of the path (line 34), using a pattern match to extract the rightmost component of the image URL. We now call the user agent's mirror() method to copy the remote image to our local filesystem and print the status message. Notice how we obtain a copy of the user agent from the parser hash reference. This avoids having to create a new user agent. Lines 38 “46: The get_basic_credentials() method This is identical to earlier versions. There is a slight flaw in mirror_images.pl as it is now written. All images are mirrored to the same directory, and no attempt is made to detect image name clashes between sites, or even within the same site when the image paths are flattened (as might occur, for example, when mirroring remote images named /images/whats_new.gif and /news/hot_news/whats_new.gif ). To make the script fully general, you might want to save each image in a separate subdirectory named after the remote hostname and the path of the image within the site. We can do this relatively painlessly by combining the URI host() and path() methods with the dirname () and mkpath() functions imported from the File::Path and File::Basename modules. The relevant section of start() would now look like this: ... use File::Path 'mkpath'; use File::Basename 'dirname'; ... sub start { ... my $remote_name = URI->new_abs($url,$parser->{base}); my $local_name = $remote_name->host . $remote_name->path; mkpath(dirname($local_name),0,0711); ... } For the image URL http://www.yahoo. com/images/whats_new.gif , this will mirror the file into the subdirectory http://www.yahoo.com/images . Summary The LWP module allows you to write scripts that act as World Wide Web clients. You can retrieve Web pages, simulate the submission of fill-out forms, and easily negotiate more obscure aspects of the HTTP protocol, such as cookies and user authentication. The HTML-Formatter and HTML-Parser modules enhance LWP by giving you the ability to format and parse HTML files. These modules allow you to transform HTML into text or postscript for printing, and to extract interesting information from HTML files without resorting to error-prone regular expressions. As an added benefit, HTML::Parser can parse XML. There's more to LWP than can be covered in a single book chapter. A good way to learn more about the package is to examine the lwp-request , lwp-download , and lwp-rget scripts, and other examples that come with the package.  | 