Section 8.4. Planning, Implementing, and Maintaining Server Availability
8.4. Planning, Implementing, and Maintaining Server AvailabilityEvery server deployment should be planned, implemented, and maintained with availability in mind. Availability refers to the server's ability to withstand hardware, application, or service outage. No server, application or service should be deployed in the enterprise without planning the deployment to meet a specific availability goal. Availability goals will differ depending on how critical the server, application, or service is to the organization:
As you can see, there's a huge difference in uptime expectations between 99 percent availability and 99.9 percent high availability. There's also a huge difference in planning, implementation, and maintenance. To meet a 99 percent availability goal, you'll need to:
To meet a 99.9 percent high-availability goal, you'll need to:
8.4.1. Planning Network Traffic Monitoring and Identifying System BottlenecksAs discussed in the exam overview, Exam 70-293 builds on the areas of study from the previous exams. With regard to server availability planning and server maintenance, you are expected to know how to monitor network traffic and identify system bottlenecks. In "Monitoring Network Traffic" in Chapter 5, I discussed the key tools used for monitoring network traffic, including Task Manager's Networking tab, the Performance console's Network Interface performance object, and Network Monitor. As part of availability planning, you should determine current network traffic levels and how new servers and services added to the network could possibly impact network traffic levels. As part of long-term planning and maintaining server availability, you should routinely and periodically monitor network traffic. In "Monitoring and Optimizing a Server Environment for Performance" in Chapter 2, I discussed how to use monitoring tools to identify system bottlenecks. Memory, processor, disk, and network bottlenecks can adversely affect system performance. As discussed in Chapter 2, the primary tool for detecting system bottlenecks is System Monitor. Use System Monitor to view real-time performance data or to log performance data for later review. 8.4.2. Planning Services for High AvailabilityWindows Server 2003 includes built-in functionality to support three high-availability software solutions:
Because component load balancing is primarily implemented by programmers, Exam 70-293 covers only network load balancing and server clusters. 8.4.2.1. Planning a high-availability solution that uses network load balancingAll editions of Windows Server 2003 support network load balancing, which is used to distribute incoming IP traffic across a cluster of servers that share a single virtual IP address. You can balance the load across as few as 2 systems and up to 32 systems. Any IP-based application that uses TCP, UDP, or GRE can be used with network load balancing. This means network load balancing is ideally suited to use with web servers, Internet application servers, and media servers. Applications that are load balanced include:
Load balancing ensures that there is no single point of failure by directing client requests to a virtual IP address. If one of the load balanced servers fails, the remaining servers handle the workload of the failed server. When the failed server comes back online, the server can rejoin the group automatically and start handling requests. Network load balancing monitors the status of each load-balanced server, referred to as a node, using heartbeats. If a node fails to send a heartbeat message to other nodes within a specified time, the node is considered to be unavailable, and the remaining servers take over the failed servers workload. Clients using the failed server automatically retry the failed connection, in most cases, within several seconds, and are then redirected to another server. It is important, however, to point out that there is no shared data between the nodes, so any work that is stored only on the failed server is lost. To avoid this, clients can store data locally prior to submitting it in final form for processing and storage. 8.4.2.2. Implementing network load balancingUse the Network Load Balancing Manager, shown in Figure 8-21, to implement and manage network load balancing. To start Network Load Balancing Manager, click Network Load Balancing Manager on the Administrative Tools menu or type nlbmgr at a command prompt. Figure 8-21. Use Network Load Balancing Manager to implement and manage network load balancing.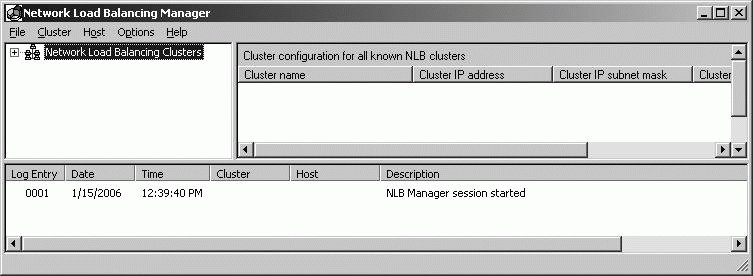 To install and configure load balancing, use the following technique:
You can then add hosts into the cluster as appropriate. If you need to change the cluster parameters later, right-click the cluster in the left pane and select Cluster Properties. You are then able to change the cluster IP configuration, operation mode, and port rules. After you create a cluster and add the initial host, you can add other hosts to the cluster at any time, up to a maximum of 32. Additional hosts use the cluster port rules from the initial host. To add a host to a cluster, follow these steps:
8.4.2.3. Planning a high-availability solution that uses clustering servicesWindows Server 2003 Enterprise Edition and Windows Server 2003 Datacenter Edition support clustering for up to eight nodes using Microsoft Cluster service. As Table 8-16 shows, this is different from the clustering support in Windows 2000. All nodes in a server cluster must be running the same version of Windows. You cannot mix server versions.
Server clustering with Microsoft Cluster service has many similarities and differences from clustering with Network Load Balancing. With Windows Server 2003, three types of server clusters can be used:
Most organizations use either single-node server clusters or single quorum device server clusters. Majority node server clusters typically are implemented for large-scale cluster deployments where cluster members of geographically separated. For example, you might use majority node server clusters to allow a backup site to handle failover from a primary site. With server clustering, nodes can be either active or passive:
With server clustering, scalability is as important as availability. Prior to deploying a cluster, you'll need to determine how many nodes you'll need, what hardware requirements must be met, and whether those nodes will be configured as active or passive nodes. Active and passive nodes are used in different ways:
Microsoft Cluster Service requires that each node in a single quorum cluster be connected to the same cluster storage devices. Connecting the cluster to the same storage devices allows nodes in the cluster to share the same data. In the event of failure, the data is available to the server that assumes the failed server's workloadand the availability of data after failure is an important distinction between NLB and cluster service. Prior to deploying clustering, you should prepare all the hard drives that the cluster will use and format all partitions appropriately using NTFS. For single quorum clusters, all nodes use the same quorum resource. With 32-bit editions of Windows Server 2003, you can use SCSI or fibre channel to share storage devices. However, fibre channel is preferred. Fibre channel is required with 64-bit editions of Windows Server 2003. Once clustering is implemented, any cluster-aware application or service can be easily clustered using resource groups. Resource groups are units of failover that are configured on a single node. When any of the resources in the resource group fail, failover is initiated for the entire resource group according to the failover policy. Cluster-aware applications and services include:
Server clusters can only use TCP/IP. They cannot use AppleTalk, IPX, NWLINK, or NetBEUI. However, clients should have NetBIOS enabled so they can browse to a virtual server by name. Cluster service tracks the status of each node in the cluster using state flags. The five possible state flags are:
Server clusters send heartbeat messages on dedicated network adapters, referred to as the cluster adapters . The heartbeat is used to track the availability of each node in the cluster. If a node fails to send a heartbeat message within a specified time, Cluster Service assumes the node has failed and initiates failover of resources. When failover occurs, another server takes over the workload, according to the failover policy. When the failed resource is back online, the original server is able to regain control of the resource. 8.4.2.4. Implementing a cluster serverYou use the Cluster Administrator, shown in Figure 8-24, to implement and manage server clustering. To start Cluster Administrator, click Cluster Administrator on the Administrative Tools menu or type cluadmin at a command prompt. Figure 8-24. Use Cluster Administrator to create and manage server clusters.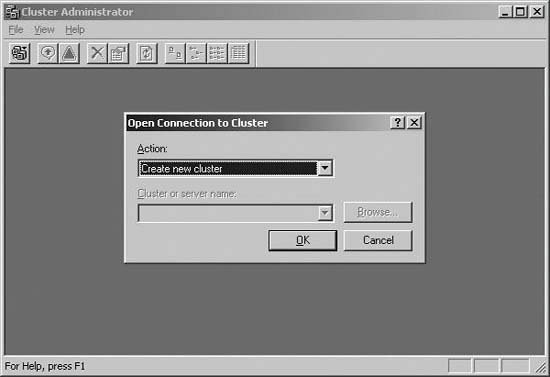 To install and configure server clustering, use the following technique:
After you create a cluster and add the initial node, you can add other nodes to the cluster at any time, up to a maximum of eight. Additional nodes use the quorum and resource configuration from the initial node. To add a node to a cluster, follow these steps:
8.4.3. Planning a Backup and Recovery StrategyA key part of availability planning is ensuring that you create and then implement a comprehensive backup and recovery strategy. For Exam 70-293, you'll need to be able to identify the appropriate backup type to use in a given situation, to plan a backup strategy that includes volume shadow copy, and to plan system recovery that uses Automated System Recovery (ASR). As part of your preparation, you should review the section "Managing and Implementing Disaster Recovery" in Chapter 2. Exam 70-293 expects you to know all the details in this section for using Backup, working with Volume Shadow Copy, and using Automated System Recovery (ASR). Additionally, the exam expects you to have a more detailed understanding of the appropriate backup types to use in a given situation. Windows Server 2003 includes the Backup utility for backing up and recovering servers. Like most third-party backup solutions, Backup supports five backup types:
For all servers and all critical workstations, you should create normal backups at least once a week and supplement these with daily incremental backups or daily differential backups. Because incremental backups contain only changes since the last incremental or full backup, incremental backups are smaller than differential backups and can be created more quickly. However, since each differential backup contains all the changes since the last normal backup, differential backups allow you to recover a system more quickly. Therefore, the decisive factors in whether to use incremental or differential backups in addition to normal backups are the required backup time and the required recovery time. For planning purposes, keep the following in mind:
Following this, in cases where you are backing up large data sets, you may need to use daily incremental backups to ensure that all the changes can be backed up within the allotted time. In cases where speed of recovery is critically important, you may need to use daily differential backups to ensure systems can be recovered more quickly. |
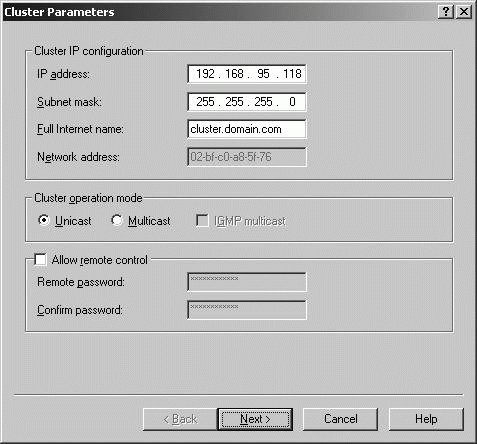
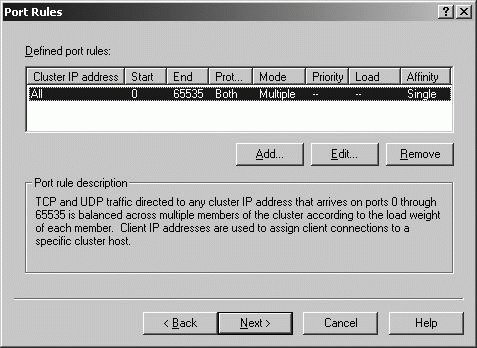
 New
New  Cluster.
Cluster.EAN: 2147483647
Pages: 95