Lesson 3:Overview of SQL Server 2000 Architecture
3 4
The data storage and analysis needs of a modern corporation or government organization are very complex. SQL Server 2000 provides a set of components that work together to meet the needs of the largest data processing systems and commercial Web sites while providing easy-to-use data storage services to an individual or small business. This lesson introduces you to the SQL Server 2000 architecture and describes how the various components work together to manage data effectively.
After this lesson, you will be able to:
- Identify and describe the various components that make up the SQL Server architecture.
Estimated lesson time: 30 minutes
Database Architecture
SQL Server 2000 data is stored in databases. The data in a database is organized into the logical components that are visible to users, while the database itself is physically implemented as two or more files on disk.
When using a database, you work primarily with the logical components (such as tables, views, procedures, and users). The physical implementation of files is largely transparent. Typically, only the database administrator needs to work with the physical implementation. Figure 1.2 illustrates the difference between the user view and the physical implementation of a database.
Each instance of SQL Server has four system databases (master, tempdb, msdb, and model) and one or more user databases. Some organizations have only one user database that contains all of their data; some organizations have different databases for each group in their organization. They might also have a database used by a single application. For example, an organization could have one database for sales, one for payroll, one for a document management application, and so on. Some applications use only one database; other applications might access several databases. Figure 1.3 shows the SQL Server system databases and several user databases.
You do not need to run multiple copies of the SQL Server database engine in order for multiple users to access the databases on a server. An instance of the SQL Server Standard Edition or Enterprise Edition is capable of handling thousands of users who are working in multiple databases at the same time. Each instance of SQL Server makes all databases in the instance available to all users who connect to the instance (subject to the defined security permissions).
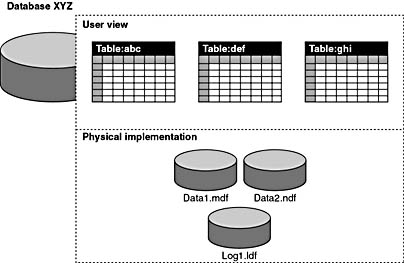
Figure 1.2 User view and physical implementation of a database.
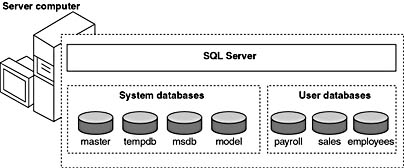
Figure 1.3 System databases and user databases.
If you connect to an instance of SQL Server, your connection is associated with a particular database on the server. This database is called the current database. You are usually connected to a database defined as your default database by the system administrator, although you can use connection options in the database APIs to specify another database. You can switch from one database to another by using either the Transact-SQL USE <database_name> statement or by using an API function that changes your current database context.
SQL Server 2000 enables you to detach a database from an instance of SQL Server, then reattach it to another instance or even attach the database back to the same instance. If you have a SQL Server database file, you can tell SQL Server when you connect to attach that database file using a specific database name.
Logical Database Components
The logical database components include objects, collations, logins, users, roles, and groups.
Database Objects
The data in a SQL Server 2000 database is organized into several different objects, which users see when they connect to the database. The following table provides a brief description of the main objects in a database. These objects are discussed in more detail in subsequent chapters.
| Object | Description |
|---|---|
| Table | A two-dimensional object consisting of rows and columns that is used to store data in a relational database. Each table stores information about one of the types of objects modeled by the database. For example, an education database might have one table for teachers, a second for students, and a third for classes. |
| Data type | An attribute that specifies what type of information can be stored in a column, parameter, or variable. SQL Server provides system-supplied data types; you can also create user-defined data types. |
| View | A database object that can be referenced the same way as a table in SQL statements. Views are defined by using a SELECT statement and are analogous to an object that contains the result set of this statement. |
| Stored procedure | A precompiled collection of Transact-SQL statements stored under a name and processed as a unit. SQL Server supplies stored procedures for managing SQL Server and for displaying information about databases and users. SQL Server-supplied stored procedures are called system stored procedures. |
| Function | A piece of code that operates as a single logical unit. A function is called by name, accepts optional input parameters, and returns a status and optional output parameters. Many programming languages support functions, including C, Visual Basic, and Transact-SQL. Transact-SQL supplies built-in functions that cannot be modified and supports user-defined functions that users can create and modify. |
| Index | In a relational database, a database object that provides fast access to data in the rows of a table, based on key values. Indexes can also enforce uniqueness on the rows in a table. SQL Server supports clustered and non-clustered indexes. The primary key of a table is automatically indexed. In full-text search, a full-text index stores information about significant words and their location within a given column. |
| Constraint | A property assigned to a table column that prevents certain types of invalid data values from being placed in the column. For example, a UNIQUE or PRIMARY KEY constraint prevents you from inserting a value that is a duplicate of an existing value; a CHECK constraint prevents you from inserting a value that does not match a search condition; and NOT NULL prevents empty values. |
| Rule | A database object that is bound to columns or user-defined data types and specifies which data values are acceptable in a column. CHECK constraints provide the same functionality and are preferred because they are in the SQL-92 standard. |
| Default | A data value, option setting, collation, or name assigned automatically by the system if a user does not specify the value, setting, collation, or name; also known as an action that is taken automatically at certain events if a user has not specified the action to take. |
| Trigger | A stored procedure that is executed when data in a specified table is modified. Triggers are often created to enforce referential integrity or consistency among logically related data in different tables. |
Collations
Collations control the physical storage of character strings in SQL Server 2000. A collation specifies the bit patterns that represent each character and the rules by which characters are sorted and compared.
An object in a SQL Server 2000 database can use a collation different from another object within that same database. Separate SQL Server 2000 collations can be specified down to the level of columns. Each column in a table can be assigned different collations. Earlier versions of SQL Server support only one collation for each instance of SQL Server. All databases and database objects that are created in an instance of SQL Server 7.0 or earlier have the same collation.
SQL Server 2000 supports several collations. A collation encodes the rules governing the proper use of characters for either a language, such as Macedonian or Polish, or an alphabet, such as Latin1_General (the Latin alphabet used by western European languages).
Each SQL Server collation specifies three properties:
- The sort order to use for Unicode data types (nchar, nvarchar, and ntext)
- The sort order to use for non-Unicode character data types (char, varchar, and text)
- The code page used to store non-Unicode character data
NOTE
You cannot specify the equivalent of a code page for the Unicode data types (nchar, nvarchar, and ntext). The double-byte bit patterns used for Unicode characters are defined by the Unicode standard and cannot be changed.
SQL Server 2000 collations can be specified at any level. When you install an instance of SQL Server 2000, you specify the default collation for that instance. When you create a database, you can specify its default collation; if you do not specify a collation, the default collation for the database is the default collation for the instance. Whenever you define a character column, variable, or parameter, you can specify the collation of the object; if you do not specify a collation, the object is created with the default collation of the database.
Logins, Users, Roles, and Groups
Logins, users, roles, and groups are the foundation for the security mechanisms of SQL Server 2000. Users who connect to SQL Server must identify themselves by using a Specific Login Identifier (ID). Users can then see only the tables and views that they are authorized to see and can execute only the stored procedures and administrative functions that they are authorized to execute. This system of security is based on the IDs used to identify users. The following table provides a description of each type of security mechanism:
| Security Mechanism | Description |
|---|---|
| Logins | Login identifiers are associated with users when they connect to SQL Server 2000. Login IDs are the account names that control access to the SQL Server system. A user cannot connect to SQL Server without first specifying a valid login ID. Members of the sysadmin fixed server role define login IDs. |
| Users | A user identifier identifies a user within a database. All permissions and ownership of objects in the database are controlled by the user account. User accounts are specific to a database; for example, the xyz user account in the sales database is different from the xyz user account in the inventory database, although both accounts have the same ID. User IDs are defined by members of the db_owner fixed database role. |
| Roles | A role is like a user group in a Windows 2000 domain. It allows you to collect users into a single unit so that you can apply permissions against those users. Permissions that are granted to, denied to, or revoked from a role also apply to any members of the role. You can establish a role that represents a job performed by a class of workers in your organization and grant the appropriate permissions to that role. As workers rotate into the job, you simply add them as a member of the role. As they rotate out of the job, you can remove them from the role. You do not have to repeatedly grant, deny, and revoke permissions to or from each person as he or she accepts or leaves the job. The permissions are applied automatically when the users become members of the role. A role is similar to a Windows security group. |
| Groups | There are no groups in SQL Server 2000 or SQL Server 7.0. You can, however, manage SQL Server security at the level of an entire Windows NT or Windows 2000 group. |
Physical Database Architecture
This section describes the way in which SQL Server 2000 files and databases are organized. The organization of SQL Server 2000 and SQL Server 7.0 is different from the organization of data in SQL Server 6.5 or earlier.
Pages and Extents
The fundamental unit of data storage in SQL Server is the page. In SQL Server 2000, the page size is 8 kilobytes (KB). In other words, SQL Server 2000 databases contain 128 pages per megabyte (MB).
The start of each page is a 96-byte header used to store system information, such as the type of page, the amount of free space on the page, and the object ID of the object owning the page.
Data pages contain all of the data in data rows (except text, ntext, and image data, which are stored in separate pages). Data rows are placed serially on the page (starting immediately after the header). A row offset table starts at the end of the page. The row offset table contains one entry for each row on the page, and each entry records how far the first byte of the row is from the start of the page. The entries in the row offset table are in reverse sequence from the sequence of the rows on the page, as shown in Figure 1.4.
Extents are the basic unit in which space is allocated to tables and indexes. An extent is eight contiguous pages, or 64 KB. In other words, SQL Server 2000 databases have 16 extents per megabyte.
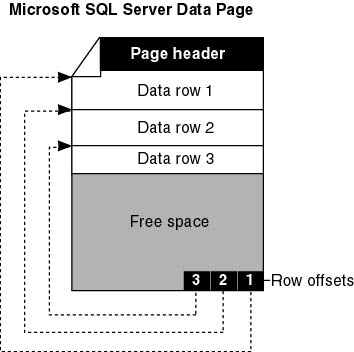
Figure 1.4 Entries in the row offset and rows on the page.
To make its space allocation efficient, SQL Server 2000 does not allocate entire extents to tables that have small amounts of data. SQL Server 2000 has two types of extents:
- A single object owns uniform extents; only the owning object can use all eight pages in the extent.
- Up to eight objects share mixed extents.
A new table or index is usually allocated pages from mixed extents. When the table or index grows to the point that it has eight pages, it is switched to uniform extents. If you create an index on an existing table that has enough rows to generate eight pages in the index, all allocations to the index are in uniform extents.
Database Files and Filegroups
SQL Server 2000 maps a database over a set of operating-system files. Data and log information are never mixed on the same file, and individual files are used only by one database.
SQL Server 2000 databases have three types of files:
- Primary data files. The primary data file is the starting point of the database and points to the other files in the database. Every database has one primary data file. The recommended filename extension for primary data files is .mdf.
- Secondary data files. Secondary data files comprise all of the data files other than the primary data file. Some databases might not have any secondary data files, while others might have multiple secondary data files. The recommended filename extension for secondary data files is .ndf.
- Log files. Log files hold all of the log information used to recover the database. There must be at least one log file for each database, although there can be more than one. The recommended filename extension for log files is .ldf.
Space Allocation and Reuse
SQL Server 2000 is effective at quickly allocating pages to objects and reusing space freed up by deleted rows. These operations are internal to the system and use data structures not visible to users, yet these processes and structures are occasionally referenced in SQL Server messages.
SQL Server uses two types of allocation maps to record the allocation of extents:
- Global Allocation Map (GAM). GAM pages record which extents have been allocated. Each GAM covers 64,000 extents (or nearly 4 GB of data). The GAM has one bit for each extent in the interval it covers. If the bit is 1, the extent is free; if the bit is 0, the extent is allocated.
- Shared Global Allocation Map (SGAM). SGAM pages record which extents are currently used as mixed extents and have at least one unused page. Each SGAM covers 64,000 extents (or nearly 4 GB of data). The SGAM has one bit for each extent in the interval it covers. If the bit is 1, the extent is being used as a mixed extent and has free pages; if the bit is 0, the extent is either not used as a mixed extent or it is a mixed extent whose pages are all in use.
Table and Index Architecture
SQL Server 2000 supports indexes on views. The first index allowed on a view is a clustered index. At the time a CREATE INDEX statement is executed on a view, the result set for the view materializes and is stored in the database with the same structure as a table that has a clustered index.
The data rows for each table or indexed view are stored in a collection of 8 KB data pages. Each data page has a 96-byte header containing system information, such as the identifier of the table that owns the page. The page header also includes pointers to the next and previous pages that are used if the pages are linked in a list. A row offset table is at the end of the page. Data rows fill the rest of the page, as shown in Figure 1.5.
SQL Server 2000 tables use one of two methods to organize their data pages—clustered tables and heaps:
- Clustered tables. Clustered tables are tables that have a clustered index. The data rows are stored in order based on the clustered index key. The index is implemented as a B-tree structure that supports the fast retrieval of the rows based on their clustered index key values. The pages in each level of the index, including the data pages in the leaf level, are linked in a doubly linked list, but navigation from one level to another is done using key values.
- Heaps. Heaps are tables that have no clustered index. The data rows are not stored in any particular order, and there is no particular order to the sequence of the data pages. The data pages are not linked in a linked list.
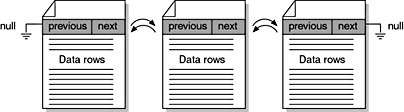
Figure 1.5 Organization of data pages.
Indexed views have the same storage structure as clustered tables.
SQL Server also supports up to 249 non-clustered indexes on each table or indexed view. The non-clustered indexes also have a B-tree structure but utilize it differently than clustered indexes. The difference is that non-clustered indexes have no effect on the order of the data rows. Clustered tables and indexed views keep their data rows in order based on the clustered index key. The collection of data pages for a heap is not affected if non-clustered indexes are defined for the table. The data pages remain in a heap unless a clustered index is defined.
Transaction Log Architecture
Every SQL Server 2000 database has a transaction log that records all transactions and the database modifications made by each transaction. This record of transactions and their modifications supports three operations:
- Recovery of individual transactions
- Recovery of all incomplete transactions when SQL Server is started
- Rolling a restored database forward to just before the point of failure
Relational Database Engine Architecture
The server components of SQL Server 2000 receive SQL statements from clients and process those SQL statements. Figure 1.6 shows the major components involved with processing a SQL statement that is received from a SQL Server client.
Tabular Data Stream
SQL statements are sent from clients by using an application-level protocol specific to SQL Server, called Tabular Data Stream (TDS). SQL Server 2000 accepts the following versions of TDS:
- TDS 8.0, sent by clients who are running versions of the SQL Server client components from SQL Server 2000. TDS 8.0 clients support all the features of SQL Server 2000.
- TDS 7.0, sent by clients who are running versions of the SQL Server client components from SQL Server version 7.0. TDS 7.0 clients do not support features introduced in SQL Server 2000, and the server sometimes has to adjust the data that it sends back to those clients.
- TDS 4.2, sent by clients who are running SQL Server client components from SQL Server 6.5, 6.0, and 4.21a. TDS 4.2 clients do not support features introduced in either SQL Server 2000 or SQL Server 7.0, and the server sometimes has to adjust the data that it sends back to those clients.
Server Net-Libraries
TDS packets are built by the Microsoft OLE DB Provider for SQL Server, the SQL Server Open Database Connectivity (ODBC) driver, or the DB-Library dynamic link library (DLL). The TDS packets are then passed to a SQL Server client Net-Library, which encapsulates them into network protocol packets. On the server, the network protocol packets are received by a server Net-Library that extracts the TDS packets and passes them to the relational database engine. This process is reversed when results are returned to the client.
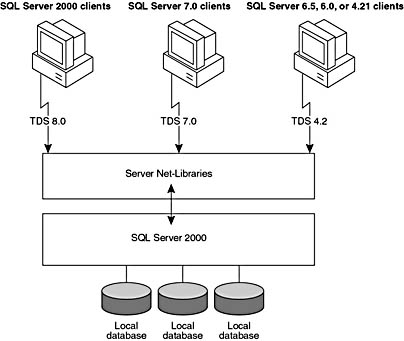
Figure 1.6 Processing a SQL statement that is received from a client.
Each server can be listening simultaneously on several network protocols and will be running one server Net-Library for each protocol on which it is listening.
Relational Database Engine
The database server processes all requests passed to it from the server Net-Libraries. The server then compiles all the SQL statements into execution plans and uses the plans to access the requested data and build the result set that is returned to the client.
The relational database engine of SQL Server 2000 has two main parts: the relational engine and the storage engine. One of the most important architectural changes made in SQL Server 7.0 (and carried over to SQL Server 2000) was to strictly separate the relational and storage engine components within the server and to have them use the OLE DB API to communicate with each other, as shown in Figure 1.7.
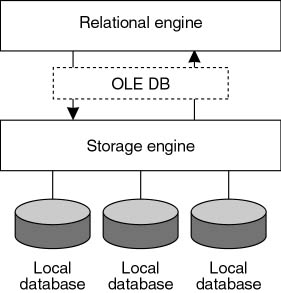
Figure 1.7 Relational engine components.
Query Processor Architecture
SQL statements are the only commands sent from applications to SQL Server 2000. All of the work done by an instance of SQL Server is the result of accepting, interpreting, and executing SQL statements. SQL Server 2000 executes SQL statements by using one of the following processes:
- Single SQL statement processing
- Batch processing
- Stored procedure and trigger execution
- Execution plan caching and reuse
- Parallel query processing
Memory Architecture
SQL Server 2000 dynamically acquires and frees memory as needed. Typically, it is not necessary for an administrator to specify how much memory should be allocated to SQL Server, although the option still exists and is required in some environments. When running multiple instances of SQL Server on a computer, each instance can dynamically acquire and free memory to adjust for changes in the workload of the instance.
SQL Server 2000 Enterprise Edition introduces support for using Windows 2000 Address Windowing Extensions (AWE) to address approximately 8 GB of memory for instances running on Windows 2000 Advanced Server and approximately 64 GB for instances running on Windows 2000 Data Center. Each instance using this additional memory, however, must statically allocate the memory it needs.
Input/Output (I/O) Architecture
The primary purpose of a database is to store and retrieve data, so performing a lot of disk reads and writes is one of the inherent attributes of a database engine. Disk input/output (I/O) operations consume many resources and take a relatively long time to complete. Much of the logic in relational database software concerns making the pattern of I/O usage highly efficient.
SQL Server 2000 allocates much of its virtual memory to a buffer cache and uses the cache to reduce physical I/O. Each instance of SQL Server 2000 has its own buffer cache. Data is read from the database disk files into the buffer cache. Multiple logical reads of the data can be satisfied without requiring the data to be physically read again. The data remains in the cache until it has not been referenced for some time and the database needs the buffer area to read in more data. Data is written back to the disk only if it is modified. Data can be changed multiple times by logical writes before a physical write transfers the new data back to the disk.
The I/O from an instance of SQL Server is divided into logical and physical I/O. A logical read occurs every time the database engine requests a page from the buffer cache. If the page is not currently in the buffer cache, a physical read is then performed in order to read the page into the buffer cache. If the page is currently in the cache, no physical read is generated. The buffer cache simply uses the page that is already in memory. A logical write occurs when data is modified in a page in memory. A physical write occurs when the page is written to disk. A page can remain in memory long enough to have more than one logical write made before it is physically written to disk.
Full-Text Query Architecture
The SQL Server 2000 full-text query component supports sophisticated searches on character string columns. This capability is implemented by the Microsoft Search service, which has two roles:
- Indexing support. Implements the full-text catalogs and indexes defined for a database. Microsoft Search accepts definitions of full-text catalogs as well as the tables and columns making up the indexes in each catalog. This tool also implements requests to populate the full-text indexes.
- Querying support. Processes full-text search queries and determines which entries in the index meet the full-text selection criteria. For each entry that meets the selection criteria, it returns the identity of the row plus a ranking value to the MSSQLServer service, where this information is used to construct the query result set. The types of queries supported include searching for words or phrases, words in close proximity to each other, and inflectional forms of verbs and nouns.
The full-text catalogs and indexes are not stored in a SQL Server database. They are stored in separate files that are managed by the Microsoft Search service. The full-text catalog files are not recovered during a SQL Server recovery. They also cannot be backed up and restored by using the Transact-SQL BACKUP and RESTORE statements. The full-text catalogs must be resynchronized separately after a recovery or restore operation. The full-text catalog files are accessible only to the Microsoft Search service and to the Windows NT or Windows 2000 system administrator.
Transactions Architecture
SQL Server 2000 maintains the consistency and integrity of each database, despite errors that occur in the system. Every application that updates data in a SQL Server database does so by using transactions. A transaction is a logical unit of work made up of a series of statements (selects, inserts, updates, or deletes). If no errors are encountered during a transaction, all of the modifications in the transaction become a permanent part of the database. If errors are encountered, none of the modifications are made to the database.
A transaction goes through several phases:
- Before the transaction starts, the database is in a consistent state.
- The application signals the start of a transaction. This process can be initiated explicitly with the BEGIN TRANSACTION statement. Alternatively, the application can set options to run in implicit transaction mode; the first Transact-SQL statement executed after the completion of a prior transaction starts a new transaction automatically. No record is written to the log when the transaction starts; the first record is written to the log when the application generates the first log record for data modification.
- The application starts modifying data. These modifications are made one table at a time. As a series of modifications are made, they might leave the database in a temporarily inconsistent intermediate state.
- When the application reaches a point where all of the modifications have completed successfully and the database is once again consistent, the application commits the transaction. This step makes all of the modifications a permanent part of the database.
- If the application encounters some error that prevents it from completing the transaction, it undoes (or rolls back) all of the data modifications. This process returns the database to the point of consistency it was at before the transaction started.
SQL Server applications can also run in autocommit mode. In autocommit mode, each individual Transact-SQL statement is committed automatically if it is successful and is rolled back automatically if it generates an error. There is no need for an application running in autocommit mode to issue statements that specifically start or end a transaction.
All Transact-SQL statements run in a transaction: an explicit transaction, an implicit transaction, or an autocommit transaction. All SQL Server transactions that include data modifications either reach a new point of consistency and are committed or are rolled back to the original point of consistency. Transactions are not left in an intermediate state in which the database is not consistent.
Administration Architecture
Each new version of SQL Server seeks to automate or eliminate some of the repetitive work performed by database administrators. Because database administrators are typically among the people most highly trained in database issues at a site, these improvements enable a valuable resource—the administrator—to spend more time working on database design and application data access issues.
Many components contribute to the effectiveness of SQL Server 2000 administration:
- The SQL Server 2000 database server reduces administration work in many environments by dynamically acquiring and freeing resources. The server automatically acquires system resources (such as memory and disk space) when needed and frees the resources when they are no longer required. Although large OLTP systems with critical performance needs are still monitored by trained administrators, SQL Server 2000 can also be used to implement smaller desktop or workgroup databases that do not require constant administrator attention.
- SQL Server 2000 provides a set of graphical tools that help administrators perform administrative tasks easily and efficiently.
- SQL Server 2000 provides a set of services that help administrators schedule the automatic execution of repetitive tasks.
- Administrators of SQL Server 2000 can program the server to handle exception conditions or to at least send e-mail or pages to the on-duty administrator.
- SQL Server 2000 publishes the same administration APIs used by the SQL Server utilities. These APIs support all of the administration tasks of SQL Server. This functionality enables developers of applications that use SQL Server 2000 as their data store to completely shield users from the administration of SQL Server 2000.
Data Definition Language, Data Manipulation Language, and Stored Procedures
Transact-SQL is the language used for all commands sent to SQL Server 2000 from any application. Transact-SQL contains statements that support all administrative work done in SQL Server. These statements fall into two main categories:
- Data Definition Language/Data Manipulation Language. Data definition language (DDL) is used to define and manage all of the objects in a SQL database, and data manipulation language (DML) is used to select, insert, update, and delete data in the objects that are defined using DDL. The Transact-SQL DDL that is used to manage objects such as databases, tables, and views is based on SQL-92 DDL statements (with extensions). For each object class, there are usually CREATE, ALTER, and DROP statements such as CREATE TABLE, ALTER TABLE, and DROP TABLE. Permissions are controlled using the SQL-92 GRANT and REVOKE statements and the Transact-SQL DENY statement.
- System stored procedures. Administrative tasks not covered by the SQL-92 DDL and DML are typically performed using system stored procedures. These stored procedures have names that start with sp_ or xp_, and they are installed when SQL Server is installed.
SQL Distributed Management Framework
The SQL Distributed Management Framework (SQL-DMF) is an integrated framework of objects, services, and components that are used to manage SQL Server 2000. SQL-DMF provides a flexible and scalable management framework that is adaptable to the requirements of an organization. This tool lessens the need for user-attended maintenance tasks (such as database backup and alert notification) by providing services that interact directly with SQL Server 2000.
The key components of SQL-DMF support the proactive management of the instances of SQL Server on your network by enabling you to define the following information:
- All SQL Server objects and their permissions
- Repetitive administrative actions to be taken at specified intervals or times
- Corrective actions to be taken when specific conditions are detected
Figure 1.8 shows the main components of SQL-DMF.
Graphical Tools
SQL Server 2000 includes many graphical utilities that help users, programmers, and administrators perform the following tasks:
- Administering and configuring SQL Server
- Determining the catalog information in a copy of SQL Server
- Designing and testing queries for retrieving data
In addition to these tools, SQL Server contains several wizards to walk administrators and programmers through the steps needed to perform more complex administrative tasks.
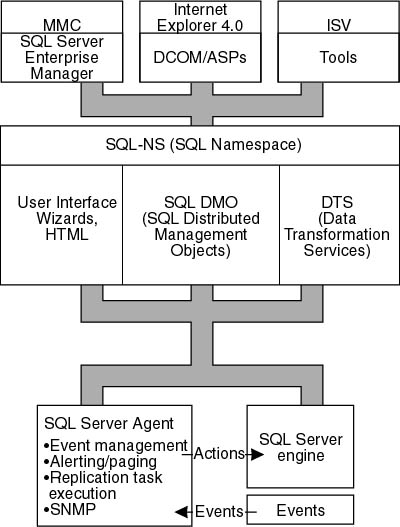
Figure 1.8 The components that make up SQL-DMF.
Automated Administration Architecture
SQL Server 2000 provides a number of features that enable administrators to program the server to administer itself for many repetitive actions or exception conditions. This functionality enables the administrators to spend more time on activities such as designing databases and working with programmers on efficient database access coding techniques. Applications from any vendor can choose SQL Server as their data storage component and minimize the administrative requirements of customers by automating administrative tasks.
These automation features are not limited to database administration tasks such as scheduling backups. They can also be used to help automate the business practices that the database supports. Applications can be scheduled to run at specific times or intervals. Specific conditions detected in the system can be used to trigger these applications if they need to be executed before the next scheduled time.
The features that support the automation of administrative tasks are SQL Server Agent, jobs, events and alerts, operators, and triggers.
Backup/Restore Architecture
The backup and restore components of SQL Server 2000 allow you to create a copy of a database. This copy is stored in a location protected from the potential failures of the server running the instance of SQL Server. If the server running the instance of SQL Server fails or if the database is somehow damaged, the backup copy can be used to recreate or restore the database.
Data Import/Export Architecture
SQL Server 2000 includes several components that support importing and exporting data, including DTS, replication, bulk copying, and distributed queries.
DTS
Data Transformation Services can be used to import and export data between heterogeneous OLE DB and ODBC data sources. A DTS package is defined that specifies the source and target OLE DB data sources; the package can then be executed on an as-required basis or at scheduled times or intervals. A single DTS package can cover multiple tables. DTS packages are not limited to transferring data straight from one table to another, because the package can specify a query as the source of the data. This functionality enables packages to transform data, such as by running a query that returns aggregate summary values instead of the raw data.
Replication
Replication is used to create copies of data in separate databases and keep these copies synchronized by replicating modifications in one copy to all the others. If it is acceptable for each site to have data that might be a minute or so out of date, replication enables the distribution of data without the overhead of requiring distributed transactions to ensure all sites have an exact copy of the current data. Replication can therefore support the distribution of data for a relatively low cost in network and computing resources.
Bulk Copying
The bulk copy feature of SQL Server provides for the efficient transfer of large amounts of data. Bulk copying transfers data into or out of one table at a time.
Distributed Queries
Transact-SQL statements use distributed queries to reference data in an OLE DB data source. The OLE DB data sources can be another instance of SQL Server or a heterogeneous data source, such as a Microsoft Access database or Oracle database.
Data Integrity Validation
Transact-SQL uses a set of DBCC statements to verify the integrity of a database. The DBCC statements in SQL Server 2000 and SQL Server 7.0 contain several improvements to the DBCC statements used in SQL Server 6.5:
- The need to run the statements is reduced significantly. Architectural changes in SQL Server have improved the robustness of the databases to the point that you do not have to verify their integrity as often.
- It is not necessary to run DBCC validation statements as part of your normal backup or maintenance procedures. You should run them as part of a system check before major changes, such as before a hardware or software upgrade or after a hardware failure. You should also run them if you suspect any problems with the system.
- SQL Server 2000 introduces a new PHYSICAL_ONLY option that enables a DBCC statement to run faster by checking only for the types of problems that are likely to be generated by a hardware problem. Run a DBCC check with PHYSICAL_ONLY if you suspect a hardware problem on your database server.
- The DBCC statements themselves also run significantly faster. Checks of complex databases typically run 8 to 10 times faster, and checks of some individual objects have run more than 300 times faster. In SQL Server 6.5, DBCC CHECKDB processed the tables serially. For each table, it first checked the structure of the underlying data and then checked each index individually. This procedure resulted in a very random pattern of reads. In SQL Server 2000, DBCC CHECKDB performs a serial scan of the database while performing parallel checks of multiple objects as it proceeds. SQL Server 2000 also takes advantage of multiple processors when running parallel DBCC statements.
- The level of locks required by SQL Server 2000 DBCC statements is much lower than in SQL Server 7.0. SQL Server 2000 DBCC statements can now be run concurrently with data modification statements, significantly lowering their impact on users who are working in the database.
- The SQL Server 2000 DBCC statements can repair minor problems they might encounter. The statements have the option to repair certain errors in the B-tree structures of indexes or errors in some of the allocation structures.
Replication Architecture
Replication is a set of technologies that allows you to keep copies of the same data on multiple sites, sometimes covering hundreds of sites. Replication uses a publish-subscribe model for distributing data:
- The Publisher is a server that is the source of data to be replicated. The Publisher defines an article for each table or other database object to be used as a replication source. One or more related articles from the same database are organized into a publication. Publications are convenient ways to group together related data and objects that you want to replicate.
- The Subscriber is a server that receives the data replicated by the publisher. The Subscriber defines a subscription to a particular publication. The subscription specifies when the Subscriber receives the publication from the Publisher and maps the articles to tables and other database objects in the Subscriber.
- The Distributor is a server that performs various tasks when moving articles from Publishers to Subscribers. The actual tasks performed depend on the type of replication performed.
SQL Server 2000 also supports replication to and from heterogeneous data sources. OLE DB or ODBC data sources can subscribe to SQL Server publications. SQL Server can also receive data replicated from a number of data sources, including Microsoft Exchange, Microsoft Access, Oracle, and DB2.
Data Warehousing and Online Analytical Processing (OLAP)
SQL Server 2000 provides components that can be used to build data warehouses or data marts. The data warehouses or data marts can be used for sophisticated enterprise intelligence systems that process the types of queries used to discover trends and analyze critical factors. These systems are called OLAP systems. The data in data warehouses and data marts is organized differently than in traditional transaction-processing databases.
Enterprise-level relational database management software, such as SQL Server 2000, was designed originally to centrally store the data generated by the daily transactions of large companies or government organizations. Over the decades, these databases have grown to be highly efficient systems for recording the data required to perform the daily operations of the enterprise. Because the system is based on computers and records the business transactions of the enterprise, these systems are known as Online Transaction-Processing (OLTP) systems.
OLTP Systems
The data in OLTP systems is organized primarily to support transactions such as the following:
- Recording an order entered from a point-of-sale terminal or through a Web site
- Placing an order for more supplies when inventory drops to a defined level
- Tracking components as they are assembled into a final product in a manufacturing facility
- Recording employee data
- Recording the identities of license holders, such as restaurants or drivers
Individual transactions are completed quickly and access relatively small amounts of data. OLTP systems are designed and tuned to process hundreds or thousands of transactions being entered at the same time.
Although OLTP systems excel at recording the data required to support daily operations, OLTP data is not organized in a manner that easily provides the information required by managers to plan the work of their organizations. Managers often need summary information from which they can analyze trends that affect their organization or team.
OLAP Systems
Systems designed to handle the types of queries used to discover trends and critical factors are called OLAP systems. OLAP queries typically require large amounts of data. For example, the head of a government motor vehicle licensing department could ask for a report that shows the number of each make and model of vehicle registered by the department each year for the past 20 years. Running this type of query against the original detail data in an OLTP system has two effects:
- The query takes a long time to aggregate (sum) all of the detail records for the last 20 years, so the report is not ready in a timely manner.
- The query generates a very heavy workload that, at least, slows down the normal users of the system from recording transactions at their normal pace.
Another issue is that many large enterprises do not have only one OLTP system that records all the transaction data. Most large enterprises have multiple OLTP systems, many of which were developed at different times and use different software and hardware. In many cases, the codes and names used to identify items in one system are different from the codes and names used in another. Managers who are running OLAP queries generally need to be able to reference the data from several of these OLTP systems.
Online analytical processing systems operate on OLAP data in data warehouses or data marts. A data warehouse stores enterprise-level OLAP data, while a data mart is smaller and typically covers a single function in an organization.
Application Development Architecture
Applications use two components to access a database: an API or a Uniform Resource Locator (URL) and a database language.
API or URL
- An API defines how to code an application to connect to a database and pass commands to the database. An object model API is usually language-independent and defines a set of objects, properties, and interfaces; a C or Visual Basic API defines a set of functions for applications written in C, C++, or Visual Basic.
- A URL is a string, or stream, that an Internet application can use to access resources on the Internet or an intranet. Microsoft SQL Server 2000 provides an Internet Server Application Programming Interface (ISAPI) DLL that Microsoft Internet Information Services (IIS) applications use to build URLs that reference instances of SQL Server 2000.
APIs Supported by SQL Server
SQL Server supports a number of APIs for building general-purpose database applications. The supported APIs include open APIs with publicly defined specifications supported by several database vendors, such as the following:
- ActiveX Data Objects (ADO)
- OLE DB
- ODBC and the object APIs built over ODBC: Remote Data Objects (RDO) and Data-Access Objects (DAO)
- Embedded SQL for C (ESQL)
- The legacy DB-Library for C API that was developed specifically to be used with earlier versions of SQL Server that predate the SQL-92 standard
Internet applications can also use URLs that specify IIS virtual roots referencing an instance of SQL Server. The URL can contain an XPath query, a Transact-SQL statement, or a template. In addition to using URLs, Internet applications can also use ADO or OLE DB to work with data in the form of XML documents.
Database Language
A database language defines the syntax of the commands sent to the database. The commands sent through the API enable the application to access and modify data. They also enable the application to create and modify objects in the database. All commands are subject to the permissions granted to the user. SQL Server 2000 supports two languages: (1) Transact-SQL and (2) Internet applications running on IIS and using XPath queries with mapping schemas.
Transact-SQL
Transact-SQL is the database language supported by SQL Server 2000. Transact-SQL complies with the entry-level SQL-92 standard but also supports several features from the intermediate and full levels. Transact-SQL also supports some powerful extensions to the SQL-92 standard.
The ODBC specification defines extensions to the SQL defined in the SQL-92 standard. The ODBC SQL extensions are also supported by OLE DB. Transact-SQL supports the ODBC extensions from applications using the ADO, OLE DB, or ODBC APIs, or the APIs that layer over ODBC. The ODBC SQL extensions are not supported from applications that use the DB-Library or Embedded SQL APIs.
XPath
SQL Server 2000 supports a subset of the XPath language defined by the World Wide Web Consortium (W3C). XPath is a graph navigation language used to select nodes from XML documents. First, you use a mapping schema to define an XML-based view of the data in one or more SQL Server tables and views, then you can use XPath queries to retrieve data from that mapping schema.
You usually use XPath queries in either URLs or the ADO API. The OLE DB API also supports XPath queries.
Lesson Summary
The SQL Server 2000 architecture consists of many components. One type of component in SQL Server is the database, which is where data is actually stored. A database is made up of logical components and physical components. Another component of SQL Server is the relational database engine. The relational database engine processes queries and manages memory, thread, task, and I/O activity. This engine also processes full-text queries and transactions. SQL Server 2000 supports database administration through DDL and DML, stored procedures, SQL-DMF, graphical tools, automated administration, backup and restore processes, import and export processes, data validation, and replication. In addition, SQL Server 2000 provides components that can be used to build data warehouses or data marts. SQL Server supports OLAP systems and OLTP systems. Applications use two components to access a SQL Server database: an API or a URL and a database language.
EAN: 2147483647
Pages: 97