8.7. Filesystem Snapshots A filesystem snapshot is a frozen image of a filesystem at a given instant in time. Snapshots support several important features: the ability to provide backups of the filesystem at several times during the day, the ability to do reliable dumps of live filesystems, and (most important for soft updates) the ability to run a filesystem check program on an active system to reclaim lost blocks and inodes. Creating a Filesystem Snapshot Implementing snapshots has proven to be straightforward. Taking a snapshot entails the following steps: - 1. A snapshot file is created to track later changes to the filesystem; a snapshot file is shown in Figure 8.28 (on page 350). This snapshot file is initialized to the size of the filesystem's partition, and its file block pointers are marked as zero, which means "not copied." A few strategic blocks are allocated, such as those holding copies of the superblock and cylinder group maps.
Figure 8.28. Structure of a snapshot file. 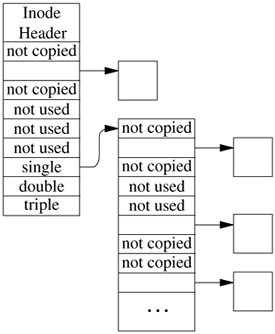
- 2. A preliminary pass is made over each of the cylinder groups to copy it to its preallocated backing block. Additionally, the block bitmap in each cylinder group is scanned to determine which blocks are free. For each free block that is found, the corresponding location in the snapshot file is marked with a distinguished block number (1) to show that the block is "not used." There is no need to copy those unused blocks if they are later allocated and written.
- 3. The filesystem is marked as "wanting to suspend." In this state, processes that wish to invoke system calls that will modify the filesystem are blocked from running, while processes that are already in progress on such system calls are permitted to finish them. These actions are enforced by inserting a gate at the top of every system call that can write to a filesystem. The set of gated system calls includes write, open (when creating or truncating), fhopen (when creating or truncating), mknod, mkfifo, link, symlink, unlink, chflags, fchflags, chmod, lchmod, fchmod, chown, lchown, fchown, utimes, lutimes, futimes, truncate, ftruncate, rename, mkdir, rmdir, fsync, sync, unmount, undelete, quotactl, revoke, and extattrctl. In addition gates must be added to pageout, ktrace, local-domain socket creation, and core dump creation. The gate tracks activity within a system call for each mounted filesystem. A gate has two purposes. The first is to suspend processes that want to enter the gated system call during periods that the filesystem that the process wants to modify is suspended. The second is to keep track of the number of processes that are running inside the gated system call for each mounted filesystem. When a process enters a gated system call, a counter in the mount structure for the filesystem that it wants to modify is incremented. When the process exits a gated system call, the counter is decremented.
- 4. The filesystem's status is changed from "wanting to suspend" to "fully suspended." This status change is done by allowing all system calls currently writing to the filesystem being suspended to finish. The transition to "fully suspended" is complete when the count of processes within gated system calls drops to zero.
- 5. The filesystem is synchronized to disk as if it were about to be unmounted.
- 6. Any cylinder groups that were modified after they were copied in step two are recopied to their preallocated backing block. Additionally, the block bitmap in each recopied cylinder group is rescanned to determine which blocks were changed. Newly allocated blocks are marked as "not copied," and newly freed blocks are marked as "not used." The details on how these modified cylinder groups are identified follows. The amount of space initially claimed by a snapshot is small, usually less than a tenth of one percent. Snapshot file space utilization is given in the snapshot performance subsection.
- 7. With the snapshot file in place, activity on the filesystem resumes. Any processes that were blocked at a gate are awakened and allowed to proceed with their system call.
- 8. Blocks that had been claimed by any snapshots that existed at the time that the current snapshot was taken are expunged from the new snapshot for reasons described below.
During steps 3 through 6, all write activity on the filesystem is suspended. Steps 3 and 4 complete in at most a few milliseconds. The time for step 5 is a function of the number of dirty pages in the kernel. It is bounded by the amount of memory that is dedicated to storing file pages. It is typically less than a second and is independent of the size of the filesystem. Typically step 6 needs to recopy only a few cylinder groups, so it also completes in less than a second. The splitting of the bitmap copies between steps 2 and 6 is the way that we avoid having the suspend time be a function of the size of the filesystem. By making the primary copy pass while the filesystem is still active, and then having only a few cylinder groups in need of recopying after it has been suspended, we keep the suspend time down to a small and usually filesystem size independent time. The details of the two-pass algorithm are as follows. Before starting the copy and scan of all the cylinder groups, the snapshot code allocates a "progress" bitmap whose size is equal to the number of cylinder groups in the filesystem. The purpose of the "progress" bitmap is to keep track of which cylinder groups have been scanned. Initially, all the bits in the "progress" map are cleared. The first pass is completed in step 2 before the filesystem is suspended. In this first pass, all the cylinder groups are scanned. When the cylinder group is read, its corresponding bit is set in the "progress" bitmap. The cylinder group is then copied, and its block map is consulted to update the snapshot file as described in step 2. Since the filesystem is still active, filesystem blocks may be allocated and freed while the cylinder groups are being scanned. Each time a cylinder group is updated because of a block being allocated or freed, its corresponding bit in the "progress" bitmap is cleared. Once this first pass over the cylinder groups is completed, the filesystem is "suspended." Step 6 now becomes the second pass of the algorithm. The second pass need only identify and update the snapshot for any cylinder groups that were modified after it handled them in the first pass. The changed cylinder groups are identified by scanning the "progress" bitmap and rescanning any cylinder groups whose bits are zero. Although every bitmap would have to be reprocessed in the worst case, in practice only a few bitmaps need to be recopied and checked. Maintaining a Filesystem Snapshot Each time an existing block in the filesystem is modified, the filesystem checks whether that block was in use at the time that the snapshot was taken (i.e., it is not marked "not used"). If so, and if it has not already been copied (i.e., it is still marked "not copied"), a new block is allocated from among the "not used" blocks and placed in the snapshot file to replace the "not copied" entry. The previous contents of the block are copied to the newly allocated snapshot file block, and the modification to the original is then allowed to proceed. Whenever a file is removed, the snapshot code inspects each of the blocks being freed and claims any that were in use at the time of the snapshot. Those blocks marked "not used" are returned to the free list. When a snapshot file is read, reads of blocks marked "not copied" return the contents of the corresponding block in the filesystem. Reads of blocks that have been copied return the contents in the copied block (e.g., the contents that were stored at that location in the filesystem at the time that the snapshot was taken). Writes to snapshot files are not permitted. When a snapshot file is no longer needed, it can be removed in the same way as any other file; its blocks are simply returned to the free list, and its inode is zeroed and returned to the free inode list. Snapshots may live across reboots. When a snapshot file is created, the inode number of the snapshot file is recorded in the superblock. When a filesystem is mounted, the snapshot list is traversed and all the listed snapshots are activated. The only limit on the number of snapshots that may exist in a filesystem is the size of the array in the superblock that holds the list of snapshots. Currently, this array can hold up to 20 snapshots. Multiple snapshot files can exist concurrently. As just described, earlier snapshot files would appear in later snapshots. If an earlier snapshot is removed, a later snapshot would claim its blocks rather than allowing them to be returned to the free list. This semantic means that it would be impossible to free any space on the filesystem except by removing the newest snapshot. To avoid this problem, the snapshot code goes through and expunges all earlier snapshots by changing its view of them to being zero-length files. With this technique, the freeing of an earlier snapshot releases the space held by that snapshot. When a block is overwritten, all snapshots are given an opportunity to copy the block. A copy of the block is made for each snapshot in which the block resides. Overwrites typically occur only for inode and directory blocks. File data usually are not overwritten. Instead, a file will be truncated and then reallocated as it is rewritten. Thus, the slow and I/O intensive block copying is infrequent. Deleted blocks are handled differently. The list of snapshots is consulted. When a snapshot is found in which the block is active ("not copied"), the deleted block is claimed by that snapshot. The traversal of the snapshot list is then terminated. Other snapshots for which the block is active are left with an entry of "not copied" for that block. The result is that when they access that location, they will still reference the deleted block. Since snapshots may not be modified, the block will not change. Since the block is claimed by a snapshot, it will not be allocated to another use. If the snapshot claiming the deleted block is deleted, the remaining snapshots will be given the opportunity to claim the block. Only when none of the remaining snapshots wants to claim the block (i.e., it is marked "not used" in all of them) will it be returned to the freelist. Large Filesystem Snapshots Creating and using a snapshot requires random access to the snapshot file. The creation of a snapshot requires the inspection and copying of all the cylinder group maps. Once in operation, every write operation to the filesystem must check whether the block being written needs to be copied. The information on whether a blocks needs to be copied is contained in the snapshot file metadata (its indirect blocks). Ideally, this metadata would be resident in the kernel memory throughout the lifetime of the snapshot. In FreeBSD, the entire physical memory on the machine can be used to cache file data pages if the memory is not needed for other purposes. Unfortunately, data pages associated with disks can only be cached in pages mapped into the kernel physical memory. Only about 10 megabytes of kernel memory is dedicated to such purposes. If we allow up to half of this space to be used for any single snapshot, the largest snapshot whose metadata that we can hold in memory is 11 Gbytes. Without help, such a tiny cache would be hopeless in trying to support a multiterabyte snapshot. In an effort to support multiterabyte snapshots with the tiny metadata cache available, it is necessary to observe the access patterns on typical filesystems. The snapshot is only consulted for files that are being written. The filesystem is organized around cylinder groups that map small contiguous areas of the disk (see Section 8.9). Within a directory, the filesystem tries to allocate all the inodes and files in the same cylinder group. When moving between directories different cylinder groups are usually inspected. Thus, the widely random behavior occurs from movement between cylinder groups. Once file writing activity settles down into a cylinder group, only a small amount of snapshot metadata needs to be consulted. That metadata will easily fit in even the tiny kernel metadata cache. So the need is to find a way to avoid thrashing the cache when moving between cylinder groups. The technique used to avoid thrashing when moving between cylinder groups is to build a look-aside table of all the blocks that were copied while the snapshot was made. This table lists the blocks associated with all the snapshot metadata blocks, the cylinder groups maps, the super block, and blocks that contain active inodes. When a copy-on-write fault occurs for a block, the first step is to consult this table. If the block is found in the table, then no further searching needs to be done in any of the snapshots. If the block is not found, then the metadata of each active snapshot on the filesystem must be consulted to see if a copy is needed. This table lookup saves time because it not only avoids faulting in metadata for widely scattered blocks, but it also avoids the need to consult potentially many snapshots. Another problem with snapshots on large filesystems is that they aggravate existing deadlock problems. When there are multiple snapshots associated with a filesystem, they are kept in a list ordered from oldest to youngest. When a copy-on-write fault occurs, the list is traversed, letting each snapshot decide if it needs to copy the block that is about to be written. Originally, each snapshot inodc had its own lock. A deadlock could occur between two processes, each trying to do a write. Consider the example in Figure 8.29. It shows a filesystem with two snapshots: snap1 and snap2. Process A holds snapshot 1 locked, and process B holds snapshot 2 locked. Both snap1 and snap2 have decided that they need to allocate a new block in which to hold a copy of the block being written by the process that holds them locked. The writing of the new block in snapshot 1 will cause the kernel running in the context of process A to scan the list of snapshots that will get blocked at snapshot 2 because it is held locked by process B. Meanwhile, the writing of the new block in snapshot 2 will cause the kernel running in the context of process B to scan the list of snapshots that will get blocked at snapshot 1 because it is held locked by process A. Figure 8.29. Snapshot deadlock scenario. 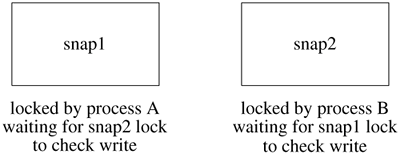
The resolution to the deadlock problem is to allocate a single lock that is used for all the snapshots on a filesystem. When a new snapshot is created, the kernel checks whether there are any other snapshots on the filesystem. If there are, the per-file lock associated with the new snapshot inode is released and replaced with the lock used for the other snapshots. With only a single lock, the access to the snapshots as a whole are serialized. Thus, in Figure 8.29, process B will hold the lock for all the snapshots and will be able to make the necessary checks and updates while process A will be held waiting. Once process B completes its scan, process A will be able to get access to all the snapshots and will be able to run successfully to completion. Because of the added serialization of the snapshot lookups, the look-aside table described earlier is important to ensure reasonable performance of snapshots. In gathering statistics on our running systems, we found that the look-aside table resolves nearly half of the snapshot copy-on-write lookups. Thus, we found that the look-aside table keeps the contention for the snapshot lock to a reasonable level. Snapshot Performance The experiments described in this section used the hardware and software configuration given in Table 8.6. Table 8.6. Hardware and software configuration for snapshot testing.Item | Configuration |
|---|
Computer | Dual Processor using two Celeron 350MHz CPUs. The machine has 256 Mbyte of main memory. | Operating System | FreeBSD 5.0-current as of December 30, 2001. | I/O Controller | Adaptec 2940 Ultra2 SCSI adapter. | Disk | Two <IBM DDRS-39130D DClB> Fixed Direct Access SCSI-2 device, 80 Mbyte/sec transfers, Tagged Queuing Enabled, 8715 Mbyte, 17,850,000 512 byte sectors: 255 heads, 63 sectors per track, 1111 cylinders. | Small Filesystem | 0.5 Gbyte, 8 Kbyte block, 1 Kbyte fragment, 90% full, 70874 files, initial snapshot size 0.392 Mbyte (0.08% of filesystem space). | Large Filesystem | 7.7 Gbyte, 16 Kbyte block, 2 Kbyte fragment, 90% full, 520715 files, initial snapshot size 2.672 Mbyte (0.03% of filesystem space). | Load | Four continuously running simultaneous Andrew benchmarks that create a moderate amount of filesystem activity intermixed with periods of CPU intensive activity [Howard et al., 1988]. |
Table 8.7 shows the time to take a snapshot on an idle filesystem. The elapsed time to take a snapshot is proportional to the size of the filesystem being captured. However, nearly all the time to take a snapshot is spent in steps 1, 2, and 8. Because the filesystem permits other processes to modify the filesystem during steps 1, 2, and 8, this part of taking a snapshot does not interfere with normal system operation. The "suspend time" column shows the amount of real-time that processes are blocked from executing system calls that modify the filesystem. As Table 8.7 shows, the period during which write activity is suspended, and thus apparent to processes in the system, is short and does not increase proportionally to filesystem size. Table 8.7. Snapshot times on an idle filesystem.Filesystem Size | Elapsed Time | CPU Time | Suspend Time |
|---|
0.5Gb | 0.7 sec | 0.1 sec | 0.025 sec | 7.7Gb | 3.5 sec | 0.4 sec | 0.034 sec |
Table 8.8 shows the times to snapshot a filesystem that has four active concurrent processes running. The elapsed time rises because the process taking the snapshot has to compete with the other processes for access to the filesystem. Note that the suspend time has risen slightly, but it is still insignificant and does not increase in proportion to the size of the filesystem under test. Instead, it is a function of the level of write activity present on the filesystem. Table 8.8. Snapshot times on an active filesystem.Filesystem Size | Elapsed Time | CPU Time | Suspend Time |
|---|
0.5Gb | 3.7 sec | 0.1 sec | 0.027 sec | 7.7Gb | 12.1 sec | 0.4 sec | 0.036 sec |
Table 8.9 shows the times to remove a snapshot on an idle filesystem. The elapsed time to remove a snapshot is proportional to the size of the filesystem being captured. The filesystem does not need to be suspended to remove a snapshot. Table 8.9. Snapshot removal time on an idle filesystem.Filesystem Size | Elapsed Time | CPU Time |
|---|
0.5Gb | 0.5 sec | 0.02 sec | 7.7Gb | 2.3 sec | 0.09 sec |
Table 8.10 shows the times to remove a snapshot on a filesystem that has four active concurrent processes running. The elapsed time rises because the process removing the snapshot has to compete with the other processes for access to the filesystem. Table 8.10. Snapshot removal time on an active filesystem.Filesystem Size | Elapsed Time | CPU Time |
|---|
0.5Gb | 1.4 sec | 0.03 sec | 7.7Gb | 4.9 sec | 0.10 sec |
Background fsck Traditionally, after an unclean system shutdown, the filesystem check program, fsck, has had to be run over all the inodes in a filesystem to ascertain which inodes and blocks are in use and to correct the bitmaps. This check is a painfully slow process that can delay the restart of a big server for an hour or more. The current implementation of soft updates guarantees the consistency of all filesystem resources, including the inode and block bitmaps. With soft updates, the only inconsistency that can arise in the filesystem (barring software bugs and media failures) is that some unreferenced blocks may not appear in the bitmaps and some inodes may have to have overly high link counts reduced. Thus, it is completely safe to begin using the filesystem after a crash without first running fsck. However, some filesystem space may be lost after each crash. Thus, there is value in having a version of fsck that can run in the background on an active filesystem to find and recover any lost blocks and adjust inodes with overly high link counts. A special case of the overly high link count is one that should be zero. Such an inode will be freed as part of reducing its link count to zero. This garbage collection task is less difficult than it might at first appear, since this version of fsck only needs to identify resources that are not in use and cannot be allocated or accessed by the running system. With the addition of snapshots, the task becomes simple, requiring only minor modifications to the standard fsck. When run in background cleanup mode, fsck starts by taking a snapshot of the filesystem to be checked. Fsck then runs over the snapshot filesystem image doing its usual calculations just as in its normal operation. The only other change comes at the end of its run, when it wants to write out the updated versions of the bitmaps. Here, the modified fsck takes the set of blocks that it finds were in use at the time of the snapshot and removes this set from the set marked as in use at the time of the snapshot the difference is the set of lost blocks. It also constructs the list of inodes whose counts need to be adjusted. Fsck then calls a new system call to notify the filesystem of the identified lost blocks so that it can replace them in its bitmaps. It also gives the set of inodes whose link counts need to be adjusted; those inodes whose link count is reduced to zero are truncated to zero length and freed. When fsck completes, it releases its snapshot. The complete details of how background fsck is implemented can be found in McKusick [2002; 2003]. User Visible Snapshots Snapshots may be taken at any time. When taken every few hours during the day, they allow users to retrieve a file that they wrote several hours earlier and later deleted or overwrote by mistake. Snapshots are much more convenient to use than dump tapes and can be created much more frequently. The snapshot described above creates a frozen image of a filesystem partition. To make that snapshot accessible to users through a traditional filesystem interface, the system administrator uses the vnode driver, vnd. The vnd driver takes a file as input and produces a character device interface to access it. The vnd character device can then be used as the input device for a standard mount command, allowing the snapshot to appear as a replica of the frozen filesystem at whatever location in the name space that the system administrator chooses to mount it. Live Dumps Once filesystem snapshots are available, it becomes possible to safely dump live filesystems. When dump notices that it is being asked to dump a mounted filesystem, it can simply take a snapshot of the filesystem and run over the snapshot instead of on the live filesystem. When dump completes, it releases the snapshot. |