Information Aggregation
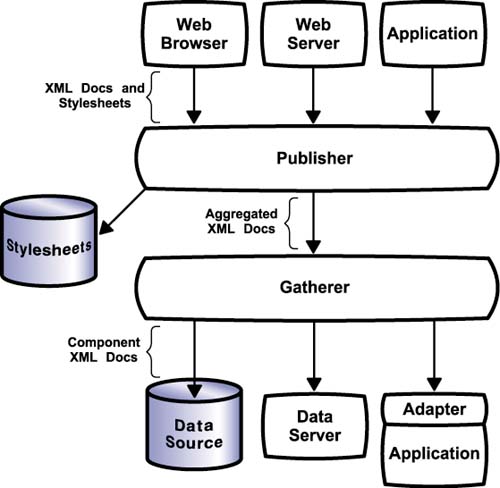
Business ChallengeValue-added resellers have become an accepted source for products and services. They provide an important function by aggregating the components of various vendors into a complete solution for particular markets. Information aggregators are the digital equivalent of value-added resellers. They add value by combining pieces of information from a number of different sources into packages of information customized for particular markets. In some cases, the aggregated information may facilitate the flow of physical goods and services. Consider the problem of PC configuration. Thousands of vendors sell components for PCs. Millions of customers want to order PCs with combinations of these components. How can these customers be sure that the combinations of components they order will work together? They certainly don't want to sort through all the product specifications for each component they want. Information aggregators provide the solution. To a certain extent, PC retailers act as the information aggregators and guide customers in the selection of compatible components. However, the sheer volume of component combinations and the rate at which available components change are too great even for most retailers. An independent information aggregator could address this problem by gathering information from all the component vendors and organizing it so that retailers and customers can access it to determine workable configurations of PC components. In other cases, an aggregator may add value to information that is already valuable . Consider the providers of digital video recorders like TiVo. These providers offer a combination of hardware and software. The hardware enables consumers to record television on hard disks instead of videocassettes, improving the ease-of-use. But the software tremendously magnifies the ease-of-use advantage by giving consumers access to an interactive television schedule. Integrating the schedule with the recorder makes it possible to turn on the television, look for programs, and set the device to record them with a few clicks of the remote control. Because this schedule includes metadata about the programs, it can even predict what programs a user might want to watch and proactively record them. These features depend on having a consolidated schedule for all the different antenna, cable, and satellite channels across the country. In fact, the hardware is actually easy for consumers to build themselves, but they chose not to because they can't aggregate the schedules themselves . The scheduling information already exists, but putting it all together enables a completely new category of product. XML BenefitThere are two barriers to efficient information aggregation: one on the input side and one on the output side. On the input side, the problem is that the information component suppliers have a wide variety of different sources, each with its own format. Extracting the desired information in a machine-readable format is an onerous task that isn't cost justified in any but the most critical areas. On the output side, the problem is ensuring that the potential information consumers can effectively use the aggregated information in the format supplied. Not only can XML address both barriers by providing common formats, it introduces an additional value ”schema design. Designing schemas that capture the essential features of information components in a particular domain helps information suppliers make their information more valuable. By designing schemas that capture the requirements of information consumers, you gain a competitive advantage. Essentially, you create value by making the market for information more efficient. Not only do XML schemas provide a convenient mechanism for you to streamline the flow of information, the XML paradigm also provides other essential infrastructure for free. Information consumers certainly want to view the aggregated information, and XSL stylesheets provide the ideal means for that. Not only can you deliver the information to their Web browsers, you can also quickly customize the presentation for different types of information consumers. An important aspect of organizing information is indicating relationships between different pieces. XLink provides a convenient way to specify such relationships independent of the actual information. Your whole service could be creating XLinks that represented a package of documents. ArchitectureFigure 8-2 shows the architecture for a potential information aggregation application. A gatherer process accesses the XML documents from each information provider. In cases where the information provider cannot use XML, either the information provider or the aggregator must create an adaptor. The gatherer then processes the documents, performing any necessary filtering and aggregation. This processing constitutes the unique value. The gatherer then stores the resulting documents in a repository. In response to client queries, a publisher process accesses the appropriate documents in the repository, combines them with the appropriate stylesheets, and sends them to the client. Of course, the gatherer and publisher may be part of the same software executable, but there is a logical separation to their functions. A given information provider may supply more than one information aggregation application, and clients may query information from more than one information aggregator. Figure 8-2. Information Aggregation Architecture Key FeaturesThe key feature of information aggregation is the flow of documents from information supplier, to information aggregator, to information consumer. At each step, the information aggregator provides value ”first by extracting only the relevant information from the information supplier and then by responding to particular client queries. Development ProcessTo start the development of an information aggregation application, there are three critical design tasks . First, you have to figure out what information consumers think is valuable. This process results in schemas for the document types in the repository and accompanying XSL stylesheets for each audience segment. Second, you have to figure out what information suppliers have that is relevant to what consumers want. This process results in schemas for the document types you retrieve from suppliers. Third, you have to figure out precisely how to transform the information that suppliers provide into the information consumers want. After the design phase, you need to provide access to consumer clients and achieve access to supplier sources. A Web server is probably the easiest way to provide access to clients, although there are other possibilities, such as e-mail. A Web server is also the easiest way to achieve access to sources. Unfortunately, the reality is that most suppliers have information in existing systems and need to use a data integration server to provide the documents. You may well have to build this application yourself if suppliers are unwilling to bear the cost. Schema SourceIn most case, you want to design the schemas for documents you plan to deliver to consumers. However, industry standards could exist for certain types of information you plan to acquire from suppliers, in which case you could leverage these existing schemas. If you have to design schemas for the supplier information as well, you probably want to try to get suppliers to adopt your schemas as an industry standard. Document Life CycleInformation suppliers create and maintain their own documents. They may choose to maintain their documents in a repository or to generate them dynamically from back-end sources. Gatherer processes consume these documents and, from them, publisher processes create their own documents. If the publishers have to create these documents in real time, you may want to use a native XML store or data server to maintain the gathered documents to achieve fast response times. You definitely maintain these documents in a repository because they are your primary assets.Information consumers take these documents and potentially archive them at their own sites. |
EAN: 2147483647
Pages: 75
- ERP Systems Impact on Organizations
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Healthcare Information: From Administrative to Practice Databases