Managing Indexes
| SQL Server maintains your indexes automatically. As you add new rows, it automatically inserts them into the correct position in a table with a clustered index, and it adds new leaf-level rows to your nonclustered indexes that will point to the new rows. When you remove rows, SQL Server automatically deletes the corresponding leaf-level rows from your nonclustered indexes. So, although your indexes will continue to contain all the correct index rows in the B-tree to help SQL Server find the rows you are looking for, you might still occasionally need to perform maintenance operations on your indexes. In addition, several properties of indexes can be changed. ALTER INDEXSQL Server 2005 introduces the ALTER INDEX command to allow you to use a single command to invoke various kinds of index changes that in previous versions required an eclectic collection of different commands, including sp_indexoption, UPDATE STATISTICS, DBCC DBREINDEX and DBCC INDEXDEFRAG. Instead of having individual commands or procedures for each different index maintenance activity, they all can be done by using ALTER INDEX. Basically, you can make four types of changes using ALTER INDEX, three of which have corresponding options that you can specify when you create an index using CREATE INDEX.
Types of FragmentationAs I mentioned, you need to do very little in terms of index maintenance. However, indexes can become fragmented. Whether fragmentation is a bad thing depends on what you'll do with your data and indexes, as well as on the type of fragmentation. Although technically fragmentation can occur in heaps as well as in index B-trees, most of this discussion will center on index fragmentation. Fragmentation can be of two types: internal and external. Internal fragmentation occurs when space is available within your index pagesthat is, when the indexes pages have not been filled as full as possible. External fragmentation occurs when the logical order of pages does not match the physical order, or when the extents belonging to an index are not contiguous. (You might also think about fragmentation on the physical disk, which might occur when your database files grow in increments and the operating system allocates space for these new increments on different parts of the disk. I can recommend that you plan carefully and preallocate space for your files so they will not need to grow in an unplanned manner, but a full discussion of fragmentation at the disk level is beyond the scope of this book.) Internal fragmentation means that the index is taking up more space than it needs to. Scanning the entire table or index involves more read operations than if no free space were available on your pages. However, internal fragmentation is sometimes desirable. In fact, you can request internal fragmentation by specifying a low fillfactor value when you create an index. Having room on a page means that there is space to insert more rows without having to split a page. Splitting a page can be an expensive operation if it occurs frequently, and it can lead to external fragmentation because when a page is split, a new page must be linked into the indexes page chain, and usually the new page is not contiguous to the page being split. External fragmentation is truly bad only when SQL Server is doing an ordered scan of all or part of a table or an index. If you're seeking individual rows through an index, it doesn't matter where those rows are physically locatedSQL Server can find them easily. If SQL Server is doing an unordered scan, it can use the IAM pages to determine which extents need to be fetched, and the IAM pages list the extents in disk order, so the fetching can be very efficient. Only if the pages need to be fetched in logical order, according to their index key values, do you need to follow the page chain. If the pages are heavily fragmented, this operation is more expensive than if there were no fragmentation. Detecting FragmentationThe sys.dm_db_index_physical_stats function replaces DBCC SHOWCONTIG as the recommended way to get a fragmentation report for a table or index. From a usage standpoint, the nicest advantage of using the new function is that you can filter the information returned. If you request all the columns of information that this function could potentially return, you'll actually get a lot more information than you get with DBCC SHOWCONTIG, but because the data is returned with a table-valued function, you can restrict the columns as well as the rows that you want returned. The function sys.dm_db_index_physical_stats takes five parameters, and they all have defaults. If you set all the parameters to their defaults and do not filter the rows or the columns, the function will return 20 columns of data for (almost) every level of every index on every table on every partition in every database of the current SQL Server instance. You would request that information as follows: SELECT * FROM sys.dm_db_index_physical_stats (NULL, NULL, NULL, NULL, NULL); When I run this command on a very small SQL Server instance, with only the AdventureWorks, pubs, and Northwind databases in addition to the system databases, I get more than 390 rows returned. Obviously, 20 columns and 390 rows is too much output to illustrate here, so I'll just let you run the command for yourself and see what you get. Let's look at the parameters now.
You must be careful when using the built-in db_id or object_id functions. If you specify an invalid name, or simply misspell the name, you do not receive an error message and the value returned is NULL. However, because NULL is a valid parameter, SQL Server will just assume that this is what you meant to use. For example, say I want to see all the previously described information, but only for the AdventureWorks database, and I mistype the command as follows: SELECT * FROM sys.dm_db_index_physical_stats (db_id('AdventureWords'), NULL, NULL, NULL, NULL);There is no such database as AdventureWorks, so the db_id function will return NULL, and it will be as if I had called the function with all NULL parameters. No error or warning will be given. You might be able to guess from the number of rows returned that you made an error, but of course, if you have no idea how much output you are expecting, it might not be immediately obvious. Books Online suggests that you can avoid this issue by capturing the IDs into variables and error-checking the values in the variables before calling the sys.dm_db_index_physical_stats function, as shown in this code: DECLARE @db_id SMALLINT; DECLARE @object_id INT; SET @db_id = DB_ID(N'AdventureWorks'); SET @object_id = OBJECT_ID(N'AdventureWorks.Person.Address'); IF @db_id IS NULL BEGIN; PRINT N'Invalid database'; END; ELSE IF @object_id IS NULL BEGIN PRINT N'Invalid object'; END; SELECT * FROM sys.dm_db_index_physical_stats (@db_id, @object_id, NULL, NULL, NULL); Another, more insidious problem is that the object_id function is called based on your current database, before any call to the sys.dm_db_index_physical_stats function is made. So if you are in the AdventureWorks database but want information from a table in the pubs database, you could try running the following code: SELECT * FROM sys.dm_db_index_physical_stats (DB_ID(N'pubs'), OBJECT_ID(N'dbo.authors'), null, null, null); Because there is no dbo.authors table in my current database (AdventureWorks), the object_id is treated as NULL, and I get all the information from all the objects in pubs. The only time SQL Server will report an error is when there are objects with the same name in two different databases. So if there were a dbo.authors table in AdventureWorks, the ID for that table would be used to try to retrieve data from the pubs database. SQL Server will return an error if the ID value returned by OBJECT_ID does not match the ID value of the object in the specified database. The following script shows the error: USE AdventureWorks GO CREATE TABLE dbo.authors (ID char(11), name varchar(60)) GO SELECT * FROM sys.dm_db_index_physical_stats (DB_ID(N'pubs'), OBJECT_ID(N'dbo.authors'), null, null, null); When you run the preceding SELECT, the dbo.authors ID will be determined based on the current environment, which is still AdventureWorks. But when SQL Server tries to use that ID in pubs, an error will be generated: Msg 2573, Level 16, State 40, Line 1 Could not find table or object ID 512720879. Check system catalog. The best solution is to fully qualify the table name, either in the call to the sys.dm_db_index_physical_stats function itself or, as in the code sample from Books Online shown earlier, to use variables to get the ID of the fully qualified table name. If you write wrapper procedures to call the sys.dm_db_index_physical_stats function, you can concatenate the database name onto the object name before retrieving the object ID and thereby avoid the problem. Because the output of this function is a bit cryptic, you might find it beneficial to write your own procedure to access this function and return the information in a slightly friendlier fashion. As I mentioned, you can potentially get a lot of rows back from this function if you use all the default parameters. But even for a subset of tables or indexes, and with careful use of the available parameters, you still might get more data back than you want. Because sys.dm_db_index_physical_stats is a table-valued function, you can add your own filters to the results being returned. For example, you can choose to look at the results for just the nonclustered indexes. Using the available parameters, your only choices are to see all the indexes or only one particular index. If we make the third parameter NULL to specify all indexes, we can then add a filter in a WHERE clause to indicate that we want only rows WHERE index_id is BETWEEN 2 and 250. Alternatively, we can choose to look only at rows that indicate a high degree of fragmentation. Next we'll look at the table returned by this function and see what information about fragmentation is returned. Fragmentation ReportI mentioned earlier that the output of sys.dm_db_index_physical_stats can return a row for each partition of each table or index, but it actually can return more than that. By default, the function returns a row for each level of each partition of each index. For a small index with only in-row data (no row-overflow or LOB pages) and only the one default partition, we might get only two or three rows back (one for each index level). But if there are multiple partitions and additional allocation units for the row-overflow and LOB data, we might see many more rows, even though only the leaf level of a clustered index (the data) can have row-overflow and LOB data. For example, a clustered index on a table containing row-overflow data, built on 11 partitions and being two levels deep, will have 33 rows (2 levels x 11 partitions + 11 partitions for the row_overflow allocation units) in the fragmentation report returned by sys.dm_db_index_physical_stats. The following columns in the output will help you identify what each row of output refers to:
In SQL 2000, DBCC SHOWCONTIG provides information about four types of fragmentation, which include internal fragmentation and three types of external fragmentation. The values reported for two of the types of fragmentation are actually meaningless if a table or index spans multiple files, but the output is returned anyway. For SQL Server 2005, all values reported are valid across multiple files. However, not every type of fragmentation is relevant to every structure. Here are the columns in the output from sys.dm_db_index_physical_stats that report on fragmentation:
Logical fragmentation is the percentage of out-of-order pages in one level of an index. Each page has a pointer in the page header that indicates what the next page in that level in logical order should be, and an out-of-order page is one that has a lower page number that the previous page. For example, if the leaf level of an index contains page 86 and page 86 indicates that the next page in index key order is page 77, page 77 is an out-of-order page. If the next page after 86 is 102, it is not out of order. Logical fragmentation is not concerned with contiguousness, only that the logical order of pages matches the physical order on the disk. Logical order is meaningful only for an index, where the order is controlled by the data type of the index key column. Extent fragmentation measures the contiguousness of the data belonging to a heap. SQL Server allocates space to a table or to index extents, which are eight contiguous pages. The first page number of every extent is a multiple of 8, so the extent starting on page 16 is contiguous with the extent starting on page 24. Extent fragmentation counts the gaps between extents belonging to the same object. If the extent starting on page 8 belongs to Table1 and the extent starting on page 24 also belongs to Table1 but the extent starting on page 16 belongs to a different table, there is one gap and two extents for Table1. The value for avg_fragmentation_in_percent, whether it indicates logical or extent fragmentation, should be as close to zero as possible for maximum performance when SQL Server is scanning a table or index.
Not all the values can be computed in every mode. The LIMITED mode scans all pages for a heap, but only the parent-level pages for an index, which are the pages above the leaf level. This means that certain values cannot be computed and returned in LIMITED mode. In particular, any of the values that require SQL Server to examine the contents of the leaf-level pages, such as avg_page_space_used_in_percent, are not available in LIMITED mode. The function returns NULL for that value in LIMITED mode. Other values returned by the sys.dm_db_index_physical_stats function also always report NULL in LIMITED mode, and their meanings are pretty self-explanatory. These include:
You can consider using SAMPLED mode when the table is very large because a SAMPLED scan looks at only 1 percent of the pages. SQL Server basically just looks at the first of every 100 pages to get this sample. However, if the table is less than 10,000 pages in size, SQL Server considers it too small to worry about and automatically converts a request for SAMPLED into DETAILED and examines all the pages. If the table is a heap, a sampled scan will not be able to report any information about fragments or fragment size. Fragments can be analyzed only if SQL Server knows ALL the pages that belong to a table. For a table with a clustered index, the upper levels of the index give SQL Server the information it needs to determine the number of fragments and their average size, but for a heap, there are no additional structures to provide this information. The sys.dm_db_index_physical_stats function returns two additional pieces of information that can indicate fragmentation in your structures.
Removing FragmentationIf fragmentation becomes too severe, you have several options for removing it. You might also wonder how severe is too severe. First of all, fragmentation is not always a bad thing. The biggest performance penalty from having fragmented data arises when your application needs to perform an ordered scan on the data. The more the logical order differs from the physical order, the greater the cost of scanning the data. If, on the other hand, your application needs only one or a few rows of data, it doesn't matter whether the table or index data is in logical order or is physically contiguous, or whether it is spread all over the disk in totally random locations. If you have a good index to find the rows you are interested in, SQL Server can find one or a few rows very efficiently, wherever they happen to be physically located. If you are doing ordered scans of an index (such as table scans on a table with a clustered index, or a leaf-level scan of a nonclustered index), it is frequently recommended that if your avg_fragmentation_in_percent value is between 5 and 20, you should reorganize your index to remove the fragmentation. As we'll see shortly, reorganizing an index (also called defragging) rearranges the pages in the leaf level of an index to correct the logical fragmentation, using the same pages that the index originally occupied. No new pages are allocated, so extent fragmentation and fragment size are unaffected. If the avg_fragmentation_in_percent value is greater than 30, or if the avg_fragment_size_in_pages value is less than 8, you should consider completely rebuilding your index. Rebuilding an index means that a whole new set of pages will be allocated for the index. This will remove almost all fragmentation, but it is not guaranteed to completely eliminate it. If the free space in the database is itself fragmented, you might not be able to allocate enough contiguous space to remove all gaps between extents. In addition, if other work is going on that needs to allocate new extents while your index is being rebuilt, the extents allocated to the two processes can end up being interleaved. Keep in mind that it is possible to have a good value for avg_fragmentation_in_percent and a bad value for avg_fragment_size_in_pages (for example, they could both be 2), or vice-versa (they could both be 40). A suboptimal value for avg_fragmentation_in_percent means that ordered scan performance will suffer, and a suboptimal value for avg_fragment_size_in_pages means that even unordered scans will not have ideal performance. Defragmentation is designed to remove logical fragmentation from the leaf level of an index while keeping the index online and as available as possible. When defragmenting an index, SQL Server acquires an Intent-Share lock on the index B-tree. Exclusive page locks are taken on individual pages only while those pages are being manipulated, as we'll see below when I describe the defragmentation algorithm. Defragmentation in SQL Server 2005 is initiated using the ALTER INDEX command. The general form of the command to remove fragmentation is as follows: ALTER INDEX { index_name | ALL } ON <object> REORGANIZE [ PARTITION = partition_number ] [ WITH ( LOB_COMPACTION = { ON | OFF } ) ]ALTER INDEX with the REORGANIZE option offers enhanced functionality compared to DBCC INDEXDEFRAG in SQL Server 2000. It supports partitioned indexes, so you can choose to defragment just one particular partition. The default is to defragment all the partitions. It is an error to specify a partition number if the index is not partitioned. Another new capability allows you to control whether the LOB data is affected by the defragmenting. Defragmenting an index takes place in two phases. The first phase is a compaction phase, and the second is the actual rearranging of data pages to allow the logical and physical order of the pages to match. As mentioned earlier, every index is created with a specific fillfactor. The initial fillfactor value is stored with the index metadata, so when defragmenting is requested, SQL Server can inspect this value. During defragmentation, SQL Server attempts to reestablish the initial fillfactor if it is greater than the current fillfactor. Defragmentation is designed to compact data, and this can be done by putting more rows per page and increasing the fullness percentage of each page. SQL Server might end up then removing pages from the index after the defragmentation. If the current fillfactor is greater than the initial fillfactor, SQL Server must add more pages to reestablish the initial value, and this will not happen during defragmentation. The compaction algorithm inspects adjacent pages (in logical order) to see if there is room to move rows from the second page to the first. SQL Server 2005 makes this process even more efficient by looking at a sliding window of eight logically consecutive pages. It determines whether rows from any of the eight pages can be moved to other pages to completely empty a page. As mentioned earlier, SQL Server 2005 also provides the option to compact your LOB pages. The default is ON. Reorganizing a specified clustered index compacts all LOB columns that are contained in the clustered index before it compacts the leaf pages. Reorganizing a nonclustered index compacts all LOB columns that are nonkey (included) columns in the index. In SQL Server 2000, the only way a user can compact LOBs in a table is to unload and reload the LOB data. LOB compaction in SQL Server 2005 finds low-density extentsthose less than 75-percent utilized. It moves pages out of these low-density uniform extents and places the data from them in available space in other uniform extents already allocated to the LOB allocation unit. This functionality allows much better use of disk space, which can be wasted with low-density LOB extents. No new extents are allocated either during this compaction phase or during the next phase. The second phase of the reorganization operation actually moves data to new pages in the in-row allocation unit with the goal of having the logical order of data match the physical order. The index is kept online because only two pages at a time are processed in an operation similar to a bubble sort. The following example is a simplification of the actual process of reorganization. Consider an index on a column of datetime data. Monday's data logically precedes Tuesday's data, which precedes Wednesday's data, which precedes data from Thursday. If, however, Monday's data is on page 88, Tuesday's is on page 50, Wednesday's is on page 100, and Thursday's is on page 77, the physical and logical ordering doesn't match in the slightest, and we have logical fragmentation. When defragmenting an index, SQL Server determines the first physical page belonging to the leaf level (page 50 in our case) and the first logical page in the leaf level (page 88, which holds Monday's data) and swaps the data on those two pages using one additional new page as a temporary storage area. After this swap, the first logical page with Monday's data is on the lowest numbered physical page, page 50. After each page swap, all locks and latches are released and the key of the last page moved is saved. The next iteration of the algorithm uses the saved key to find the next logical pageTuesday's data, which is now on page 88. The next physical page is 77, which holds Thursday's data. So another swap is made to place Tuesday's data on page 77 and Thursday's on page 88. This process continues until no more swaps need to be made. Note that no defragmenting is done for pages on mixed extents. You might wonder whether there is any harm in initiating a defragmentation operation if there is no or little existing fragmentation, because the amount of page swapping seems to be proportional to the number of out-of-order pages. In most cases, if there is no fragmentation, the defragmentation will do no swapping of pages. However, a pathological situation can occur in which a small amount of fragmentation requires an enormous amount of work to be done. Imagine an index of thousands of pages, all in order except for the last one in logical sequence. The first page of data in order (say, for January 1, 2000) is on page 101, the next (for January 2, 2000) is on page 102, the next is on 103, and so on. But the last logical page of data for January 31, 2006, is stored on page 100. With a 1000-page table, the fragmentation value reported would be only 0.1 percent because 1 out of 1000 pages is out of order. If we decided to reorganize this index even with such a low fragmentation percentage, the defragmentation algorithm would switch page 100 with 101, then switch 101 with 102, then switch 102 with 103, in an effort to have the data for the last date in the table be on the last page. We might have just one page out of order, but we have to do a thousand page swaps. I strongly suggest that you don't defragment your data unless you know the data is fragmented and you have determined that you need unfragmented data for maximum performance. You need to be aware of some restrictions on using the REORGANIZE option. Certainly, if the index is disabled it cannot be defragmented. Also, because the process of removing fragmentation needs to work on individual pages, you will get an error if you try to reorganize an index that has the option ALLOW_PAGE_LOCKS set to OFF. Reorganization cannot happen if a concurrent online index is built on the same index or if another process is concurrently reorganizing the same index. You can observe the progress of each index's reorganization in the sys.dm_exec_requests dynamic management view in the complete_percentage and estimated_completion_time columns. The value in the column complete_percentage reports the percentage completed in one index's reorganization; the value in the column estimated_completion_time shows the estimated time (in milliseconds) required to complete the remainder of the index reorganization. If you are reorganizing multiple indexes in the same command, you might see these values go up and down as each index is defragmented in turn. Rebuilding an IndexYou can completely rebuild an index in several ways. You can use a simple DROP INDEX and CREATE INDEX, but this method is probably the least preferable. In particular, if you are rebuilding a clustered index in this way, all the nonclustered indexes must be rebuilt when you drop the clustered index. This nonclustered index rebuilding is necessary to change the row locators in the leaf level from the clustered key values to row IDs. Then, when you rebuild the clustered index, all the nonclustered indexes must be rebuilt again. In addition, if the index supports a PRIMARY KEY or UNIQUE constraint, you can't use the DROP INDEX command at all. Better solutions are to use the ALTER INDEX command or to use the DROP_EXISTING clause along with CREATE INDEX. As an example, here are both methods for rebuilding the PK_TransactionHistory_TransactionID index on the Production.TransactionHistory table: ALTER INDEX PK_TransactionHistory_TransactionID ON Production.TransactionHistory REBUILD; CREATE UNIQUE CLUSTERED INDEX PK_TransactionHistory_TransactionID ON Production.TransactionHistory (TransactionDate, TransactionID) WITH DROP_EXISTING; Although the CREATE method requires more typing, it is actually more powerful and offers more options that you can specify. You can change the columns that make up the index, change the uniqueness property, or change a nonclustered index to clustered, as long as there isn't already a clustered index on the table. You can also specify a new filegroup or a partition scheme to use when rebuilding. Note that if you do change the properties, all nonclustered indexes must be rebuilt, but only once (not twice, as would happen if we were to execute a DROP INDEX followed by a CREATE INDEX). With the ALTER INDEX option, the nonclustered indexes never need to be rebuilt just as a side effect, because you can't change the index definition at all. However, you can specify ALL instead of an index name and request that all indexes be rebuilt. Another advantage of the ALTER INDEX method is that you can specify just a single partition to be rebuiltif, for example, the fragmentation report from sys.dm_db_index_physical_stats shows fragmentation in just one partition or a subset of the partitions. Online Index BuildingThe default behavior of either method of rebuilding an index is that SQL Server takes an exclusive lock on the index, so it is completely unavailable while the index is being rebuilt. If the index is clustered, the entire table is unavailable; if the index is nonclustered, there is a shared lock on the table, which means no modifications can be made but other processes can SELECT from the table. Of course, they cannot take advantage of the index you're rebuilding, so the query might not perform as well as it should. SQL Server 2005 provides the option to rebuild one or all indexes online. The ONLINE option is available with both ALTER INDEX and CREATE INDEX, with or without also using the DROP_EXISTING option. Here's the syntax for building the preceding index, but doing it online: ALTER INDEX PK_TransactionHistory_TransactionID ON Production.TransactionHistory REBUILD WITH (ONLINE = ON); The online build works by maintaining two copies of the index simultaneously, the original (source) and the new one (target). The target is used only for writing any changes made while the rebuild is going on. All reading is done from the source, and modifications are applied to the source as well. SQL Server row-level versioning is used so anyone retrieving information from the index will be able to read consistent data. Figure 7-10 (taken from SQL Server 2005 Books Online) illustrates the source and target, and it shows three phases that the build process goes through. For each phase, the figure describes what kind of access is allowed, what is happening in the source and target tables, and what locks are applied. Figure 7-10. The structures and phases of online index building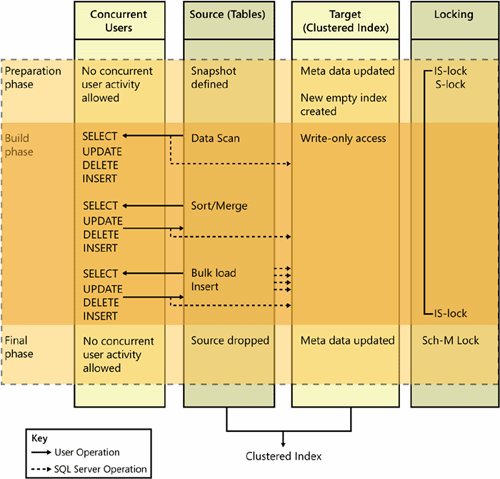 The actual processes might differ slightly depending on whether the index is being built initially or being rebuilt, and whether the index is clustered or nonclustered. Following are details about what SQL Server does after the index create or rebuild command is issued. Here are the steps involved in rebuilding a nonclustered index:
Building a new nonclustered index involves exactly the same steps, except there is no target index so the versioned scan is done on the base table. Write operations need to maintain only the target index, rather than both indexes. A clustered index rebuild works exactly like a nonclustered rebuild, as long as there is no schema change (a change of index keys or uniqueness property). For a build of new clustered index, or a rebuild of a clustered index with a schema change, there are a few more differences. First, an intermediate mapping index is used to translate between the source and target physical structures. Additionally, all existing nonclustered indexes are rebuilt one at a time after a new base table has been built. For example, creating a clustered index on a heap with two nonclustered indexes involves the following steps:
Before the operation is completed, SQL Server will be maintaining six structures at once. Online index building is not really considered to be a performance enhancement because an index can actually be built faster offline, and all these structures do not need to be maintained simultaneously. Online index building is an availability featureyou can rebuild indexes to remove all fragmentation or re-establish a fillfactor even if your data must be fully available 24/7. |
EAN: 2147483647
Pages: 115