The Structure of Index Pages
| Note
Index pages are structured much like data pages. As with all other types of pages in SQL Server, index pages have a fixed size of 8 kilobytes (KB), or 8,192 bytes. Index pages also have a 96-byte header, but just like in data pages, there is an offset array at the end of the page with 2 bytes for each row to indicate the offset of that row on the page. Each index has a row in the sys.indexes catalog view, with an index_id value of either 1, for a clustered index, or a number between 2 and 250, indicating a nonclustered index. In Chapter 6, where I started telling you about sys.indexes, I said that even heaps have a row in sys.indexes, with an index_id value of 0. Most of the information in sys.indexes is basic property information about indexes, including the values for each of the index options that we can specify in the CREATE INDEX command. To get space usage information about indexes, we can join sys.indexes with sys.partitions and sys.allocation_units. In Chapter 6, I showed a query that I referred to as the "allocation query," which reports the number of pages used for each partition of each table or index, with a separate row for each type of storage (in-row, row-overflow, or LOB). We'll look at more details about getting the space used for indexes later in this chapter. Although that allocation query returns space used for each table and index, it does not report any information about the location of the data. For that, we'll need to use the undocumented catalog view called sys.system_internals_allocation_units that I told you about in Chapter 6. In that chapter, we looked at the first_page column and I showed you how to take the hexadecimal value and convert it to a file number and page number. Every IAM chain (a chain of the same type of page for one partition of one table or index) has a first_page, which indicates the first page in the leaf level of the index. The view sys.system_internals_allocation_units also has a column called root_page and one called first_iam_page. The value for root_page can be converted to the file number and page number of the index's root, and for a heap, root_page stores the last page of the table. For heaps, first and last really have no meaning, but you can just think of them as the first page and last page returned by running DBCC IND to get the complete list of pages. As I mentioned in Chapter 6, if you prefer not to have to do hex-to-decimal conversions to find out actual page numbers, or if you want to get ALL the pages from a table or index, you can use the DBCC IND command. We looked at some of the basic information returned by DBCC IND in Chapter 6, but now we'll look at the rest of the details. Keep in mind that Microsoft doesn't support this command and that it isn't guaranteed to maintain the same behavior from release to release. In fact, the behavior of this command changed between the initial release of SQL Server 2005 and the release of Service Pack 1 (SP1). However, I find it enormously useful and will continue to use it as long as it is available. The description below refers to the use of DBCC IND in SQL Server 2005 SP1. The DBCC IND command has four parameters, but only the first three are required. DBCC IND ( { 'dbname' | dbid }, { 'objname' | objid }, { nonclustered indid | 1 | 0 | -1 | -2 } [, partition_number] )The first parameter is the database name or the database ID. The second parameter is an object name or object ID within the database; the object can be either a table or an indexed view. The third parameter is a specific nonclustered index ID or the value 1, 0, 1, or 2. The values for this parameter have the following meanings.
The final parameter is optional, to maintain backward compatibility with DBCC IND SQL Server 2000. It specifies a particular partition number, and if no value is specified or a 0 is given, information for all partitions is displayed. Unlike DBCC PAGE, SQL Server does not require that you enable trace flag 3604 before running DBCC IND. However, because I usually run DBCC IND to find out page numbers in preparation for using DBCC PAGE, it's a good idea to turn the trace flag on before running either command. The columns in the result set are described in Table 7-1. Note that all page references have the file and page component conveniently split between two columns, so you don't have to do any conversion.
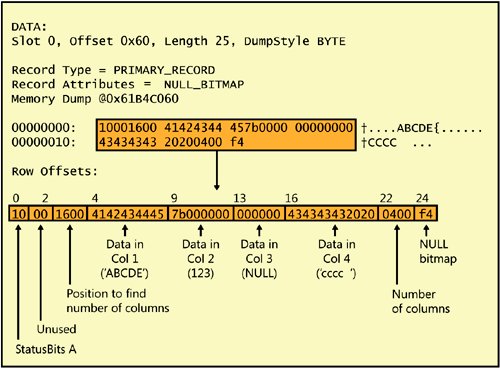
Most of the return values were described in Chapter 6 because they are equally relevant to heaps. When dealing with indexes, we also can look at the IndexID column, which will be 0 for a heap, 1 for pages from a clustered index, and a number between 2 and 250 for any nonclustered index pages. The IndexLevel value allows us to see at what level of the index tree a page is at, with a value of 1 meaning the leaf level. The highest value for any particular index is therefore the root page of that index, and you should be able to verify that the root page is the same value you get from the sys.system_internals_allocation_units view in the root_page column. The remaining four columns indicate the page linkage, at each level of each index. For each page, there is a file ID and page ID for the next page and a file ID and page ID for the previous page. Of course, for the root pages, all these values will be 0. You can also determine the first page by finding one with zeros for the previous page, and you can find the last page because it will have zeros for the next page. Because the output of this DBCC command is so wide and hard to display in a page of a book, I have created a script that copies the output of this command to a table. Once we have this information in a table, we can query it and retrieve just the columns we are interested in. Here is a script that creates a table called sp_table_pages with columns to hold all the returned information from DBCC IND. Note that any object created in the master database with a name that starts with sp_ can be accessed from any database, without having to qualify it with the database name. USE master; GO CREATE TABLE sp_table_pages (PageFID tinyint, PagePID int, IAMFID tinyint, IAMPID int, ObjectID int, IndexID tinyint, PartitionNumber tinyint, PartitionID bigint, iam_chain_type varchar(30), PageType tinyint, IndexLevel tinyint, NextPageFID tinyint, NextPagePID int, PrevPageFID tinyint, PrevPagePID int, Primary Key (PageFID, PagePID)); The following code truncates the sp_table_pages table and then fills it with DBCC IND results from the Sales.SalesOrderDetail table in the AdventureWorks database. TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, [Sales.SalesOrderDetail], -1)' );Once you have the results of DBCC IND in a table, you can select any subset of rows or columns that you are interested in. I'll use sp_table_pages to report on DBCC IND information for many examples in this chapter. You can then use DBCC PAGE to examine index pages, just as you do for data pages. However, if you use DBCC PAGE with style 3 to print out the details of each column on each row on an index page, the output looks quite different. We'll see some examples after I talk about index the structure of index pages. Index pages fall into three basic types: leaf level for nonclustered indexes, node (nonleaf) level for clustered indexes, and node level for nonclustered indexes. There isn't really a separate structure for leaf level pages of a clustered index because those are the data pages, which we've already seen in detail. There is, however, one special case for leaf-level clustered index pages which I'll tell you about now. Clustered Index Rows with a UniqueifierIf your clustered index was not created with the UNIQUE property, SQL Server adds a 4-byte field when necessary to make each key unique. Because clustered index keys are used as bookmarks to identify the base rows being referenced by nonclustered indexes, there needs to be a unique way to refer to each row in a clustered index. SQL Server adds the uniqueifier only when necessarythat is, when duplicate keys are added to the table. As an example, I'll create a small table with all fixed-length columns and then add a clustered, nonunique index to the table. (I created an identical table with a different name in Chapter 6.) USE AdventureWorks; GO CREATE TABLE Clustered_Dupes (Col1 char(5) NOT NULL, Col2 int NOT NULL, Col3 char(3) NULL, Col4 char(6) NOT NULL); GO CREATE CLUSTERED INDEX Cl_dupes_col1 ON Clustered_Dupes(col1); If you look at the row in the sysindexes compatibility view for this table, you'll notice something unexpected. SELECT first, indid, keycnt, name FROM sysindexes WHERE id = object_id ('Clustered_Dupes'); RESULT: indid keycnt name ------ ------ -------------- 1 2 Cl_dupes_col1The column called keycnt, which indicates the number of keys an index has, has a value of 2. (Note that this column is available only in the compatibility view sysindexes, and not in the catalog view sys.indexes.) If I had created this index using the UNIQUE qualifier, the keycnt value would be 1. If I had looked at the sysindexes row before adding a clustered index, when the table was still a heap, the row for the table would have had a keycnt value of 0 because a heap has no keys. I'll now add the same initial row that I added to the identical table I created in Chapter 6. To find the first (or only) data page of the table, three methods are available. I can examine the first column from the sysindexes compatibility view, I can run a query that joins the catalog view sys.indexes to sys.partitions and sys.system_internals_allocation_units, or I can run DBCC IND and find the page with a PageType of 1 with no previous pagethat will be the first page in logical order in the data pages, which are the leaf level of the clustered index. I'll use the third option and make use of the sp_table_pages table that I created earlier. INSERT Clustered_Dupes VALUES ('ABCDE', 123, null, 'CCCC'); GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, Clustered_Dupes, -1)' ); SELECT PageFID, PagePID FROM sp_table_pages WHERE PageType = 1 and PrevPageFID = 0 and PrevPagePID = 0;Although this single-row table has only one data page, I can use the preceding WHERE clause to find the first data page in any table with a clustered index, after inserting the results of DBCC IND into the table. Here are my results: PageFID PagePID ------- ----------- 1 21088 The output tells me that the first page of the table is on file 1, page 21088, so I can use DBCC PAGE to examine that page. Remember to turn on trace flag 3604 before executing the undocumented DBCC PAGE command. DBCC TRACEON (3604); GO DBCC PAGE (AdventureWorks,1,21088, 1); The only row on the page looks exactly like the row shown in Figure 6-10 in Chapter 6, but I'll reproduce it again here, in Figure 7-3. When you read the row output from DBCC PAGE, remember that each two displayed characters represents a byte. For character fields, you can just treat each byte as an ASCII code and convert that to the associated character. Numeric fields are stored with the low-order byte first, so within each numeric field, we must swap bytes to determine what value is being stored. Right now, there are no duplicates of the clustered key, so no extra information has to be provided. However, if I add two additional rows, with duplicate values in col1, the row structure changes: INSERT Clustered_Dupes VALUES ('ABCDE', 456, null, 'DDDD'); INSERT Clustered_Dupes VALUES ('ABCDE', 64, null, 'EEEE');Figure 7-3. A data row containing all fixed-length columns and a unique value in the clustered key column Figure 7-4 shows the three rows that are now on the page. Figure 7-4. Three data rows containing duplicate values in the clustered key column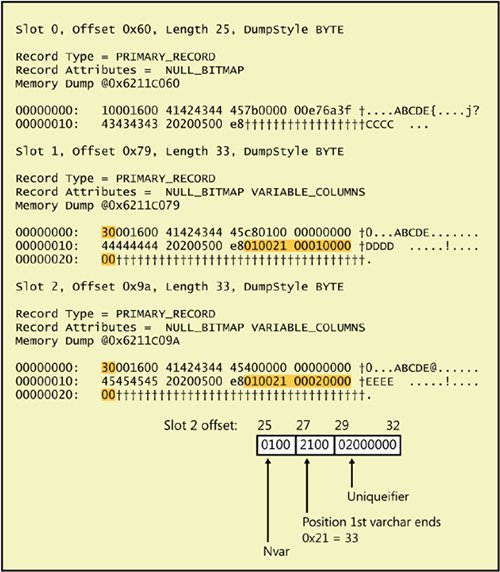 The first difference in the second two rows is that the bits in the first byte (TagA) are different. Bit 5 is on, giving TagA a value of 0x30, which means the variable block is present in the row. Without this bit on, TagA would have a value of 0x10. The extra variable-length portions of the second two rows are shaded in the figure. You can see that 8 extra bytes are added when we have a duplicate row. In this case, the first 4 extra bytes are added because the uniqueifier is considered a variable-length column. Because there were no variable-length columns before, SQL Server adds 2 bytes to indicate the number of variable-length columns present. These bytes are at offsets 33-34 in these rows with the duplicate keys and have the value of 1. The next 2 bytes (offsets 35-36) indicate the position where the first variable-length column ends. In both these rows, the value is 0x29, which converts to 41 decimal. The last 4 bytes (offsets 37-40) are the actual uniqueifier. In the second row, which has the first duplicate, the uniqueifier is 1. The third row has a uniqueifier of 2. Index Row FormatsThe row structure of an index row is very similar to the structure of a data row. An index row does not use the TagB or Fsize row header values. In place of the Fsize field, which indicates where the fixed-length portion of a row ends, the page header pminlen value is used to decode an index row. The pminlen value indicates the offset at which the fixed-length data portion of the row ends. If the index row has no variable-length or nullable columns, that is the end of the row. Only if the index row has nullable columns are the field called Ncol and the null bitmap both present. The Ncol field contains a value indicating how many columns are in the index row; this value is needed to determine how many bits are in the null bitmap. Data rows have an Ncol field and null bitmap whether or not any columns allow NULL, but index rows have only a null bitmap and an Ncol field if any NULLs are allowed in an index column. Table 7-2 shows the general format of an index row.
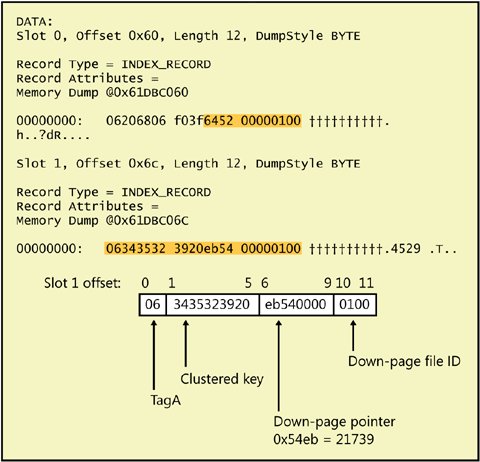
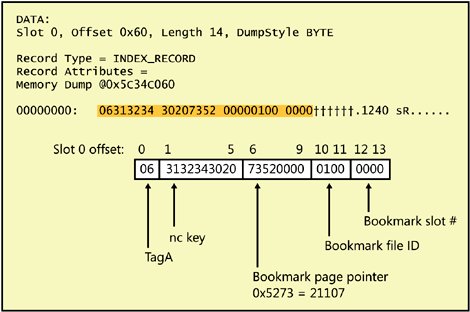
The data contents of an index row depend on the level of the index. All rows except those in the leaf level contain a 6-byte down-page pointer in addition to the key values and bookmarks. The down-page pointer is the last column in the fixed-data portion of the row. In nonclustered indexes, the nonclustered keys and bookmarks are treated as normal columns. They can reside in either the fixed or variable portion of the row, depending on how each of the key columns was defined. A bookmark that is a RID, however, is always part of the fixed-length data. If the bookmark is a clustered key value and the clustered and nonclustered indexes share columns, the actual data is stored only once. For example, if your clustered index key is lastname and you have a nonclustered index on (firstname, lastname), the index rows will not store the value of lastname twice. I'll show you an example of this shortly. Clustered Index Node RowsThe node levels of a clustered index contain pointers to pages at the next level down in the index, along with the first key value on each page pointed to. Page pointers are 6 bytes: 2 bytes for the file number and 4 bytes for the page number in the file. The following code creates and populates a table that I'll use to show you the structure of clustered index node rows. USE AdventureWorks; GO CREATE TABLE clustered_nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (600) NULL ); GO CREATE CLUSTERED INDEX idxCL ON Clustered_Nodupes(str1); GO SET NOCOUNT ON; GO DECLARE @i int; SET @i = 1240; WHILE @i < 13000 BEGIN INSERT INTO Clustered_Nodupes SELECT @i, cast(@i AS char), cast(@i AS char); SET @i = @i + 1; END; GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, Clustered_Nodupes, -1)' ); SELECT PageFID, PagePID, IndexLevel, PageType FROM sp_table_pages WHERE IndexId = 1 and IndexLevel >= 0 and PrevPageFID = 0 and PrevPagePID = 0; RESULT: PageFID PagePID IndexLevel PageType ------- ----------- ---------- -------- 1 21090 0 1 1 21092 1 2 1 21738 2 2 DBCC TRACEON (3604); GO DBCC PAGE (AdventureWorks,1,21090, 1);The results from the sp_table_pages table show us the first page at each level of the clustered index. We know it's the clustered index because the IndexID value is 1; we know it's the first page because the PrevPage values are 0. The filter on IndexLevel eliminates the IAM page for this index because its IndexLevel is null. The root of the index is the page at the highest IndexLevel, so in this case, the root page is 21738. Using DBCC PAGE to look at the root, we can see two index entries, as shown in Figure 7-5. When you examine index pages, you need to be aware that the first index key entry on each page is frequently either meaningless or empty. The down-page pointer is valid, but the data for the index key might not be a valid value. When SQL Server traverses the index, it starts looking for a value by comparing the search key with the second key value on the page. If the value being sought is less than the second entry on the page, SQL Server follows the page pointer indicated in the first index entry. In this example, the down-page pointer is at byte offsets 6 through 9, with a hex value of 0x5264. (The next two bytes are 0x0001 for the file ID.) In decimal, the page number for the first page at the next level down is 21092, which is the same value we saw earlier when looking at the output of DBCC IND. Figure 7-5. The root page of a clustered index We can then use DBCC PAGE again to look at page 21092, but I'll leave that to you to examine on your own. The row structure is identical to the rows on page 21738, the root page. When I look at the first row on page 21092 (not shown), I see that it has a meaningless key value, but the page-down pointer should be the first page in clustered index order. The hex value for the page-down pointer is 0x5262, which is 21090 decimal. That page is the leaf-level page, and it has a structure of a normal data page. If we use DBCC PAGE to look at that page, we'll see that the first row has the value of '10000', which is the minimum value of the str1 column in the table. We can verify this with the following query: SELECT min(str1), min(id) FROM Clustered_Nodupes; Remember that the clustered index column is a char(5) column. Although the lowest (and first) number I inserted was 1240, which is the minimum value for the id column, when converted to a char(5), that's '1240'. When sorted alphabetically, '10000' comes well before '1240'. Nonclustered Index Leaf RowsIndex node rows in a clustered index contain only the first key value of the page they are pointing to in the next level and page-down pointers to guide SQL Server in traversing the index. Nonclustered index rows can contain much more information. The rows in the leaf level of a nonclustered index contain every key value and a bookmark. I'll show you three examples of nonclustered index leaf rows. First we'll look at the leaf level of a nonclustered index built on a heap. I'll use the same code I used to build the clustered index with no duplicates in the previous example, but the index I build on the str1 column will be nonclustered. I'll also put only a few rows in the table so the root page will be the entire index. USE AdventureWorks; SET NOCOUNT ON; CREATE TABLE NC_Heap_Nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (600) NULL ); GO CREATE UNIQUE INDEX idxNC_heap ON NC_Heap_Nodupes (str1); GO SET NOCOUNT ON; GO DECLARE @i int; SET @i = 1240; WHILE @i < 1300 BEGIN INSERT INTO NC_Heap_Nodupes SELECT @i, cast(@i AS char), cast(@i AS char); SET @i = @i + 1; END; GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, NC_Heap_Nodupes, -1)' ); SELECT PageFID, PagePID, IndexID, IndexLevel, PageType FROM sp_table_pages WHERE IndexLevel >= 0; RESULTS: PageFID PagePID IndexID IndexLevel PageType ------- ------- ------- ---------- -------- 1 21107 0 0 1 1 21109 2 0 2 1 21111 0 0 1 1 22088 0 0 1 1 22089 0 0 1 1 22090 0 0 1 1 22091 0 0 1You can see that there are six data pages in the heap and one index page in the nonclustered index. That one page is both the leaf and the root. As the leaf, its rows contain bookmarks or pointers to actual data rows. Because this index is built on a heap, the bookmark is an 8-byte RID. These RIDs are 8 bytes long, and we can see them if we look at the page for index 2 returned by the preceding query. For me, it is page 21109. DBCC TRACEON (3604); GO DBCC PAGE (AdventureWorks,1,21109, 1); As you can see in Figure 7-6, this RID is fixed-length and is located in the index row immediately after the index key value of '1240'. The first 4 bytes of the RID (0x5273) are the page number (21107), the next 2 bytes (0x0001) are the file ID, and the last 2 bytes are the slot number (0x0000). Figure 7-6. An index row on a leaf-level page from a nonclustered index on a heap I'll build a nonclustered index on a similar table, but first I'll build a clustered index on a varchar column so we can see what an index looks like when a bookmark is a clustered index key. Also, in order not to have the same values in the same sequence in both the str1 and str2 columns, I'll introduce a bit of randomness into the generation of the values for str2. If you run this script, the randomness might generate some duplicate values for the unique clustered index column str2. Because each row is inserted in its own INSERT statement, a violation of uniqueness will cause only that one row to be rejected. If you get error messages about PRIMARY KEY violation, just ignore them. You'll still have enough rows. USE AdventureWorks; GO SET NOCOUNT ON; GO CREATE TABLE NC_Nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 varchar (10) NULL ); GO CREATE UNIQUE CLUSTERED INDEX idxcl_str2 on NC_Nodupes (str2); CREATE UNIQUE INDEX idxNC ON NC_Nodupes (str1); GO SET NOCOUNT ON; GO DECLARE @i int; SET @i = 1240; WHILE @i < 1300 BEGIN INSERT INTO NC_Nodupes SELECT @i, cast(@i AS char), cast(cast(@i * rand() AS int) as char); SET @i = @i + 1; END; GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, NC_Nodupes, -1)' ); SELECT PageFID, PagePID, IndexID, IndexLevel, PageType FROM sp_table_pages WHERE IndexLevel >= 0; RESULT: PageFID PagePID IndexID IndexLevel PageType ------- ----------- ------- ---------- -------- 1 22104 1 0 1 1 22106 2 0 2Figure 7-7 shows the first index row from the nonclustered index on NC_Nodupes. Figure 7-7. An index row on a leaf-level page from a nonclustered index built on a clustered table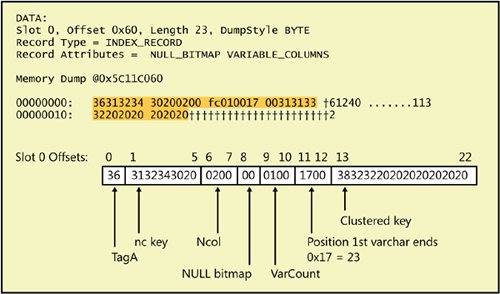 The index row contains the nonclustered key value of '1240', and the bookmark is the clustered key '1132'. Because the clustered key is variable-length, it comes at the end of the row after the Ncol value and null bitmap. A variable-length key column in an index uses only the number of bytes needed to store the value inserted. However, the preceding script creates the varchar value by first converting an int to a char, which will assume a length of 30 and pad the string with blanks to that length. When the session option ANSI_PADDING is enabled (the default), the trailing blanks up to the 10th character are preserved when you insert into the varchar(10) column in the table. If you've had enough of translating the cryptic hex strings into meaningful values, another alternative is available. The third parameter to DBCC PAGE provides a different format for the output when you print an index page, as I mentioned earlier. Using format 3 on an index page basically provides tabular output showing the contents of each index row, including the bookmarks. The following output is from DBCC PAGE on the one index page from my NC_Nodupes table. There are 60 rows of data, so the index page has 60 index rows. (Because of the random generation of values, you might have fewer than 60 rows in your table.) Each index row has the nonclustered key as well as the clustered key stored in the row, along with the file and page IDs and the row number on the page where the rows can be found. Because there is just one data page, all the file and page IDs are the same. The final value displayed is called the KeyHashValue, which is not actually stored in the index row. It is a fixed-length string derived using a hash formula on all the key columns. This value is used to represent the row in certain other tools. One such tool that we will see in Chapter 8 is the dynamic management view that shows the locks that are being held. When a lock is held on an index row, the list of locks displays the KeyHashValue to indicate which key is locked. DBCC PAGE (AdventureWorks,1,21106, 3); FileId PageId Row Level str1 (key) str2 KeyHashValue ------ ----------- ------ ------ ---------- ---------- ---------------- 1 22106 0 0 1240 1132 (510089f2f438) 1 22106 1 0 1241 706 (5100c8c3ef21) 1 22106 2 0 1242 344 (51000b90c20a) 1 22106 3 0 1243 682 (51004aa1d913) 1 22106 4 0 1244 926 (51008d37985c) 1 22106 5 0 1245 359 (5100cc068345) 1 22106 6 0 1246 383 (51000f55ae6e) 1 22106 7 0 1247 1052 (51004e64b577) 1 22106 8 0 1248 986 (510081782df0) 1 22106 9 0 1249 946 (5100c04936e9) 1 22106 10 0 1250 312 (5100be983639) 1 22106 11 0 1251 735 (5100ffa92d20) 1 22106 12 0 1252 1017 (51003cfa000b) 1 22106 13 0 1253 1097 (51007dcb1b12) 1 22106 14 0 1254 615 (5100ba5d5a5d) 1 22106 15 0 1255 185 (5100fb6c4144) 1 22106 16 0 1256 394 (5100383f6c6f) 1 22106 17 0 1257 1027 (5100790e7776) 1 22106 18 0 1258 1111 (5100b612eff1) 1 22106 19 0 1259 129 (5100f723f4e8) 1 22106 20 0 1260 425 (5100e726703b) 1 22106 21 0 1261 111 (5100a6176b22) 1 22106 22 0 1262 220 (510065444609) 1 22106 23 0 1263 503 (510024755d10) 1 22106 24 0 1264 332 (5100e3e31c5f) 1 22106 25 0 1265 12 (5100a2d20746) 1 22106 26 0 1266 182 (510061812a6d) 1 22106 27 0 1267 982 (510020b03174) 1 22106 28 0 1268 535 (5100efaca9f3) 1 22106 29 0 1269 48 (5100ae9db2ea) 1 22106 30 0 1270 693 (5100d04cb23a) 1 22106 31 0 1271 200 (5100917da923) 1 22106 32 0 1272 49 (5100522e8408) 1 22106 33 0 1273 1170 (5100131f9f11) 1 22106 34 0 1274 815 (5100d489de5e) 1 22106 35 0 1275 1114 (510095b8c547) 1 22106 36 0 1276 1038 (510056ebe86c) 1 22106 37 0 1277 321 (510017daf375) 1 22106 38 0 1278 1023 (5100d8c66bf2) 1 22106 39 0 1279 70 (510099f770eb) 1 22106 40 0 1280 1107 (5100ed0bee31) 1 22106 41 0 1281 1108 (5100ac3af528) 1 22106 42 0 1282 464 (51006f69d803) 1 22106 43 0 1283 1035 (51002e58c31a) 1 22106 44 0 1284 50 (5100e9ce8255) 1 22106 45 0 1285 1143 (5100a8ff994c) 1 22106 46 0 1286 1036 (51006bacb467) 1 22106 47 0 1287 943 (51002a9daf7e) 1 22106 48 0 1288 695 (5100e58137f9) 1 22106 49 0 1289 797 (5100a4b02ce0) 1 22106 50 0 1290 269 (5100da612c30) 1 22106 51 0 1291 202 (51009b503729) 1 22106 52 0 1292 1063 (510058031a02) 1 22106 53 0 1293 823 (51001932011b) 1 22106 54 0 1294 960 (5100dea44054) 1 22106 55 0 1295 316 (51009f955b4d) 1 22106 56 0 1296 1251 (51005cc67666) 1 22106 57 0 1297 1284 (51001df76d7f) 1 22106 58 0 1298 266 (5100d2ebf5f8) 1 22106 59 0 1299 1123 (510093daeee1) The last example will show a composite nonclustered index on str1 and str2 and an overlapping clustered index on str2. I'll just show you the code to create the table and indexes; the code to populate the table and to find the root of the index is identical to the code in the previous example. USE AdventureWorks; CREATE TABLE NC_Overlap ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (10) NULL ); GO CREATE UNIQUE CLUSTERED INDEX idxCL_overlap ON NC_Overlap (str2); CREATE UNIQUE INDEX idxNC_overlap ON NC_Overlap (str1, str2); GO Here are several of the leaf-level index rows from the nonclustered composite index on the table NC_Overlap. FileId PageId Row Level str1 (key) str2 (key) KeyHashValue ------ ----------- ------ ------ ---------- ---------- -------------- 1 22110 0 0 1240 676 (e700d6c3e711) 1 22110 1 0 1241 476 (e500845fb78e) 1 22110 2 0 1242 156 (e200b66ef631) Note that the value in column str2 (676 in the first row) is part of the index key for the nonclustered index as well as the bookmark because it is the clustered index key. The only real difference between this output and the previous output (besides the values in str2, which are generated randomly) is that in this output the str2 column is labeled a key. It is included in the previous output only because it is the clustered index key, used as the bookmark. Although it serves two purposes in the rows in this output, its value is not duplicated. The value 676 occurs only once, and if you look at the format 1 output of the page, you'll see that it takes the maximum allowed space of 10 bytes. Because this is a leaf-level row, there is no page-down pointer, and because the index is built on a clustered table, there is no RID, only the clustered key to be used as a bookmark. Nonclustered Index Node RowsYou now know that the leaf level of a nonclustered index must have a bookmark because from the leaf level you want to be able to find the actual row of data. The nonleaf levels of a nonclustered index only need to help us traverse down to pages at the lower levels. If the nonclustered index is unique, the node rows need to have only the nonclustered key and the page-down pointer. If the index is not unique, the row contains key values, a down-page pointer, and a bookmark. I'll leave it to you to create a table that will have enough rows for more than a single nonclustered index level. You can use a script similar to the ones shown previously and change the upper limit of the WHILE loop to about 13000. You can create two tables, one with a non-unique, nonclustered index on str1 and a clustered index on str2 and another table with a unique nonclustered index on str1 and a clustered index on str2. Keep in the mind that for the purposes of creating the index rows, SQL Server doesn't care whether the keys in the non-unique index actually contain duplicates. If the index is not defined to be unique, even if all the values are unique, the nonleaf index rows will contain bookmarks. I'll let you use DBCC IND and DBCC PAGE to view the index rows for yourself. |
EAN: 2147483647
Pages: 115