| Test Objective Covered: Design and set up an NCS cluster configuration.
Before you can build it, you must design it. As with any complex network system, you must design a high-availability architecture before you can install NCS 1.6. Designing Novell Cluster Services is a marriage between typical network design and atypical NCS architecture design. On the typical side, NCS design requires minimum server requirements, high-capacity network planning, and load balancing. On the other hand, atypical NCS design involves Fiber Channel or SCSI cluster configurations, NCS system design, and SAN management. In this lesson, we will focus on the atypical design components specific to NCS high availability. We will begin with a discussion of the NCS basic system architecture and then quickly expand into the area of NCS system design. In the primary section of this lesson, we will learn about cluster-enabled volumes and pools, fan-out failover, and a detailed process of casting off failed nodes in a cluster. Finally, we will complete the lesson with a quick overview of SAN management and troubleshooting. So without any further ado, let's begin our NCS design lesson with a peek at the basic NCS system architecture. REAL WORLD Novell does not recommend using SCSI drives for your shared disk subsystem in a production environment. SCSI is fine for testing and evaluation, but not for mission-critical deployments. Furthermore, it can be difficult to find a SCSI adapter whose NetWare .HAM driver will work in a shared disk system. You have been warned! |
Basic Clustering-System Architecture The basic clustering-system architecture involves two or more servers, NCS 1.6 software (installed on each server), a shared disk system, and a high-speed channel between them all. Figure 7.1 provides an illustration of this basic architecture. Figure 7.1. Basic clustering-system architecture.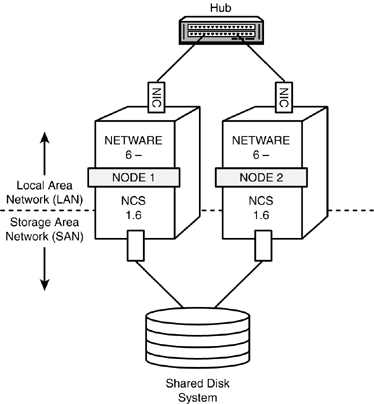
Actually, the NCS system architecture is much more complex than is shown in Figure 7.1. Let's take a moment to review the NCS cluster vocabulary. NCS Cluster Vocabulary To fully appreciate (and understand) the complexity of the NCS architecture, you should be familiar with the following clustering terms: Cluster A group of servers linked together in a dedicated network to minimize the loss of service by reducing or managing failures and minimizing downtime. Node A server in a cluster. Remember, NCS 1.6 supports up to 32 nodes in a single cluster. Cluster Resource A server resource (such as an application or network service) with a dynamic location managed by NCS. Remember that a cluster resource is only assignable to one node at a time in NCS. Shared Storage Device A device (such as an external hard drive) that hosts shared cluster resources. In most instances, this is the shared disk system we've been speaking of. Storage Area Network (SAN) A dedicated network connecting servers and shared storage devices. In NCS 1.6, a cluster is analogous to a SAN. Migration The process of moving resources from one node to another within a cluster. Migration differs from failover in that it occurs before a server fails. Migration is useful for tasks such as load balancing of resources and/or upgrading servers in a cluster. Failover The automatic migration of resources after a node fails. Failover normally results from a server hardware or power source problem. Fan-Out Failover Load balancing of the migration of resources to other nodes during a failover based on factors such as node traffic and/or availability of installed applications. In NCS clustering, you can configure fan-out failure options to optimize resource load balancing. Fan-out failover is also known as "intelligent failover." Failed Back The process of returning a failed node's resources back to the way they were before the failover. Of course, failback implies that the original cause of the failure has been remedied. Fiber Channel The Fiber Channel Standard (FCS) defines a high-speed data transfer interface for workstations, mainframes, supercomputers, storage devices, and displays. By using FCS, you can build a very fast and reliable NCS cluster. Fiber Channel supports a variety of optical and electrical media with data transfer rates from 260 megabits per second (copper wire) up to 4 gigabits per second (fiber optics). Furthermore, Fiber Channel with fiber optics supports very long connections up to 10 km (6.2 miles).
Now that you're a pro with NCS nomenclature, let's explore the four basic components that make up our cluster system architecture. NCS Cluster Components The four components that make up a NetWare 6 NCS cluster are NetWare 6 Servers You must have two or more NetWare 6 servers configured to communicate with each other via TCP/IP. In addition, each server must have at least one local disk device used for the SYS volume. NCS 1.6 supports up to 32 NetWare 6 servers in a single cluster. NCS 1.6 You must install the Novell Cluster Services 1.6 software on each server in the cluster. In addition, NCS 1.6 runs on the NetWare 6 platform; therefore, you must also install NetWare 6 on each server in the cluster. Shared Disk System The whole point of clustering is multinode access to a shared disk system. This is the cornerstone component of NCS 1.6. NOTE A number of NetWare services do not require a shared disk system including: Novell Licensing, LDAP Server, and DHCP.
NCS Communications Platform NCS 1.6 provides two options for communications between cluster nodes and the shared disk system. Your two choices are: Fiber Channel (recommended) and SCSI. Refer to the next section for a description of these two NCS cluster configurations.
NCS Cluster Configurations In NCS, the server (node) acts as a midpoint between two networks: LAN (Local Area Network) and SAN. LAN communications are accomplished via an internal server NIC (Network Interface Card) and Ethernet cabling through a central network hub. This half of the NCS cluster communications equation operates the same way it operates for any Novell network. SAN communications, on the other hand, are the cornerstone of Novell clustering. In a Fiber Channel configuration, SAN communications are accomplished via a Fiber Channel card in each server. Furthermore, these cards are connected to a shared storage device via a Fiber Channel switch. NCS 1.6 supports two basic SAN cluster configurations: REAL WORLD You must check Novell's hardware compatibility list for NICs before implementing a cluster. Many NICs (especially older ones) don't work correctly with the cluster heartbeat, causing everyone in the cluster to take the poison pill this is bad! It will cause your cluster to abend like crazy! Personally, I like to use CE100 cards from Compaq (which are actually manufactured by Intel). Finally, beware of some mainstream boards, such as the 3Com 3c509. |
Fiber Channel Cluster Configuration Figure 7.2 illustrates a typical Fiber Channel cluster configuration. This configuration defines two levels of communication: LAN communication via Ethernet NICs and SAN communications via Fiber Channel cards (FC). Figure 7.2. Fiber Channel cluster configuration.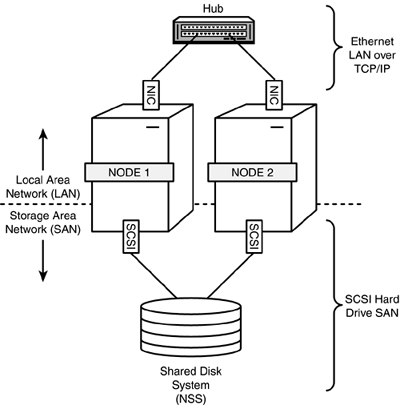
The interesting thing about the Fiber Channel architecture is that it supports both copper and fiber-optic cabling. In fact, Fiber Channel is an architecture standard protocol for transmitting data at very high speeds within a SAN. SCSI Hard Drive Cluster Configuration Although Fiber Channel is the recommended cluster configuration, you can also use a dedicated SCSI hardware architecture. Figure 7.3 illustrates the SCSI hard drive cluster configuration. In some nonmission critical environments (such as testing and demos), you can configure a small two-node cluster to use an external shared SCSI hard drive. Remember: This is not a recommended configuration for production cluster systems. Figure 7.3. SCSI Hard Drive cluster configuration.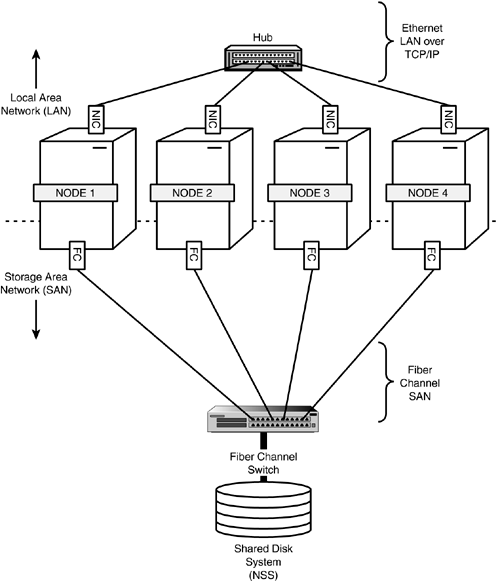
In this cluster configuration, an Ethernet NIC handles LAN communications and SAN communications operate over SCSI adapter cards and high-speed cables. If you use SCSI cards and a SCSI hard drive to configure a two-node cluster, make sure each card and the hard drive is assigned a different SCSI ID number. That completes our basic discussion of clustering system architecture. We hope that we have clarified any questions you have regarding NCS cluster vocabulary, the components that make up a clustering system, and the two cluster configurations supported by NCS 1.6 Fiber Channel and SCSI. NCS System Design To build a reliable high-availability solution with NCS 1.6, you must understand how all of the different components communicate with each other. We will use the Fiber Channel architecture to explore the detailed operation of Novell Cluster Services in this section. During this system design discussion, we will describe the activities of five very important NCS components: Master Node The first server that is enabled in an NCS cluster is assigned the cluster IP address and becomes the master node. The master node updates information transmitted between the cluster and eDirectory, and monitors the health of the other cluster nodes. If the master node fails, NCS migrates the cluster IP address to another server in the cluster and that server becomes the master node. Slave Nodes All servers in an NCS cluster (except the master node) are referred to as slave nodes. Slave nodes receive instructions from the master node and wait patiently in case the master node fails. Cluster Resource A Cluster Resource is an object in eDirectory that represents an application or other type of service that you can migrate or failover from one node to another in NCS. This resource can be an e-mail application, DHCP server, the master IP address, or anything else that eDirectory supports. It is important that each Cluster Resource has an accompanying object in NDS, that includes scripts for unloading the service from one node and loading it to another. Also you must make sure that the Cluster Resource service itself is installed on all nodes in the cluster that will host it. Shared Storage Device The Shared Storage Device is the cornerstone of the NCS SAN. This is where all the users' files are stored. By moving all files to a Shared Storage Device, you can reduce the number of servers needed in your network and reserve files on the local node drive for network administration. Remember that each node must have a local SYS: volume that isn't shared for operating system files and utilities. Cluster-Enabled Volumes and Pools A cluster-enabled volume is a NetWare 6 NSS volume that gives users continuous Read/Write file access on the shared storage device. Furthermore, NetWare 6 allows you to cluster-enable Storage Pools. This enables you to migrate or failover more than one volume at a time. With NetWare 6 clustering, volumes are associated with NSS pools that provide a unique secondary Internet Protocol (IP) address (through a virtual server object) for locating the volumes on the cluster's shared storage device.
In this section, we will learn how master and slave nodes monitor the LAN and SAN for cluster health. We'll learn how NCS handles slave node and master node failovers in case something unexpected happens. Finally, we'll explore a specific design for load-balancing cluster resources using the fan-out failover method. Now it's time to master NCS system design. TIP NetWare 5 Clustering Services only allowed you to migrate or failover volumes individually. It did not support storage pools. With NetWare 6 clustering, you can migrate or failover more than one volume at a time by assigning each one to a pool and cluster-enabling the pool.
Monitoring the LAN and SAN NCS uses two important mechanisms for monitoring the health of communications on the LAN and the SAN. The goal of this monitoring strategy is to ensure high availability of cluster resources on both the LAN and SAN segments. Following is a brief description of how NCS monitors the health of LANs and SANs: Monitoring the LAN NCS uses heartbeats to monitor the health of nodes on the LAN. A heartbeat is a small IP packet sent periodically over the LAN (not the SAN) by the master node and all slave nodes in the cluster. The master node sends out a multicast heartbeat to all slaves, while the slaves send a unicast response back to the master. All nodes in a cluster monitor the heartbeat of each other at a tolerance rate of eight seconds (default setting). The tolerance rate is the amount of time a node waits for a heartbeat from another node before taking action that results in casting off a failed node. Monitoring the SAN Simultaneously, NCS uses a Split-Brain Detector (SBD) on the shared storage device to ensure that each node maintains membership in the cluster. SBD is implemented as a small dedicated disk partition on the shared disk. Each node in the cluster periodically writes an Epoch Number over the SAN (not the LAN) to the SBD partition on the shared storage device. Before writing its own Epoch Number, the node reads the Epoch Numbers of all other nodes in the cluster. This number increases by one each time a node leaves or joins the cluster. SBD is an important mechanism for monitoring the migration of nodes in and out of a given cluster.
NCS uses heartbeats and SBD to constantly monitor node conditions on the LAN and the SAN. Once NCS determines there's been a change in the availability of cluster resources from a given node, it can initiate a failover. Let's take a closer look. Slave Node Failover The following steps describe the detailed process of casting off a failed slave node in NCS: Each node in the NCS cluster sends a heartbeat packet over the LAN at a preconfigured rate (one second by default). Simultaneously each node also writes an Epoch Number to the SBD on the shared storage device. The Epoch Number is written at half the preconfigured tolerance rate of the heartbeat (four seconds by default). The master node monitors the heartbeats of all other nodes in the cluster to determine whether they are still "alive." The master node also reads the Epoch Numbers for all nodes in the cluster. If a heartbeat is a not received from a slave node within eight seconds (the default tolerance rate), the master node and remaining slave nodes create a new Cluster Membership View. The new Cluster Membership View does not include the node that failed to communicate to the master node. This slave node has now been "cast off." Furthermore, each node in the new view must update its Epoch Number by one because there has been a change in cluster membership. Now there are two Cluster Membership Views. The node that failed to send a heartbeat uses the old Cluster Membership View with the old Epoch Number. The other nodes use the new Cluster Membership View with a new Epoch Number. This causes a Split-Brain condition. NCS uses the information in SBD to vote between the two Cluster Membership Views. The Cluster Membership View that has the most nodes wins. However, if there are equal nodes in both Views, the side with the master node wins. The nodes in the surviving Cluster Membership View write a special token to the SBD for the losing node. The losing node reads the special token and then abends (that is, has an abnormal ending) by taking a poison pill. Abending ensures that nodes on the losing side cannot corrupt the new, healthy cluster. The new cluster migrates the resources assigned to the failed node to other nodes in the cluster and users are none the wiser. Ergo, cluster services are uninterrupted and high availability is maintained.
REAL WORLD When NCS nodes "vote" between multiple Cluster Membership Views, the view with the most nodes win. If there are equal nodes in both views, the side with the master node wins. In the special case of a two-node cluster, the node with good connectivity over the LAN will win (regardless of whether or not it is the master node). In some rare instances, NCS will not be able to detect the heartbeat from a master or slave node's NIC driver. If you run a two-node cluster and the master node fails to send a heartbeat over the LAN (because its NIC doesn't support NCS), Clustering Services might accidentally cast off the slave node instead of the master. This only happens in a two-node cluster in which both master and slave have a vote and NCS can't determine which node is communicating. In a three-node cluster, the slaves have two votes and will cast off the failed master node. |
Master Node Failover The following steps describe the process of casting off a failed master node in NCS: Each node in the NCS cluster sends a heartbeat packet over the LAN at a preconfigured rate (one second by default). Simultaneously each node also writes an Epoch Number to the SBD on the shared storage device. The Epoch Number is written at half the preconfigured tolerance rate of the heartbeat (four seconds by default). The master node monitors the heartbeats of all other nodes in the cluster to determine whether they are still alive. Simultaneously each slave node in a cluster continuously monitors the heartbeat of the master node. If the master node fails to send a heartbeat to the slaves within eight seconds (the default tolerance level), the slave nodes create a new Cluster Membership View. At the same time, the old Cluster Membership View is maintained by the master node. In addition, each node in the new Cluster Membership View updates its Epoch Number by one in the SBD partition. Now there are two Cluster Membership Views. The master node uses the old Cluster Membership View with the old Epoch Number. The other nodes use the new Cluster Membership View with a new Epoch Number. This causes a Split-Brain condition. NCS uses the information in SBD to vote between the two Cluster Membership Views. The Cluster Membership View that has the most nodes wins. However, if there are equal nodes in both Views, the side with the master node wins. Because the master node has a different Cluster Membership View and is the only node with a different Epoch Number, the new Cluster Membership View with the slave nodes wins. The nodes in the new Cluster Membership View write a special token to the sector in SBD for the master node. The losing master node reads the special token and then it abends by taking a poison pill. At the same time, the slave nodes use an algorithm to vote on which node becomes the new master. The new cluster (with a new master node) migrates all cluster resources (volumes and services) assigned to the previous master node and high availability is maintained. Again, NCS and all of your users win!
Designing Fan-Out Failover As we learned earlier, failover is the process of automatically migrating resources from a failed node to other slaves and masters in a cluster. Although this migration happens automatically, you must design and configure where each volume and cluster resource migrates during failover. Furthermore, you will probably want to distribute or fan-out the volumes and resources to several nodes based on a variety of factors, including load balancing, network configuration, availability of installed applications, hardware platform, and so on. While the process of fan-out failover is automatic, its design and configuration are not. Follow along by using Figures 7.4 and 7.5 as we walk through an example of designing fan-out failover for ACME. Figure 7.4. Three-node Fiber Channel cluster at ACME.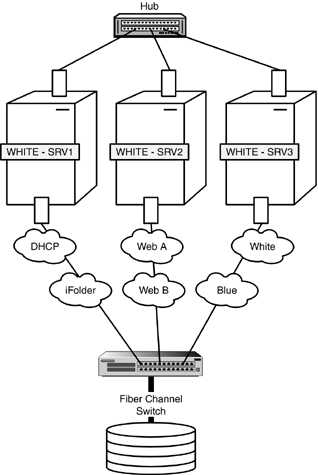
Figure 7.5. Fan-out failover at ACME.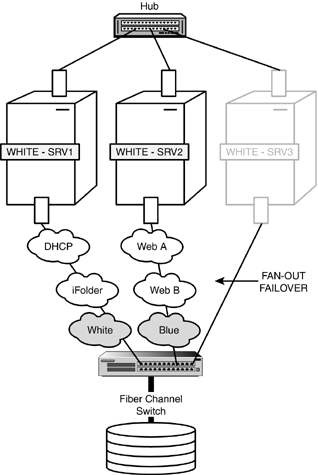
In Figure 7.4, the Tokyo location of ACME has a three-node Fiber Channel cluster of WHITE servers. During normal cluster operations, each server remains in constant communication with the others by sending out periodic heartbeats over the LAN. In addition, you can see that each server hosts specific network resources and services: WHITE-SRV1 hosts DHCP and iFolder, WHITE-SRV2 hosts two websites (A and B), and WHITE-SRV3 hosts two e-mail servers (WHITE and BLUE). One day, something catastrophic happens to WHITE-SRV3. Fortunately, you have preconfigured the WHITE NCS cluster for automatic fan-out failover. Figure 7.5 illustrates the automatic fan-out failover of e-mail services from WHITE-SRV3 to WHITE-SRV1 and WHITE-SRV2. During this automatic migration, the shared data volumes and e-mail applications running on WHITE-SRV3 are restarted on WHITE-SRV1 (WHITE e-mail services) and WHITE-SRV2 (BLUE e-mail services). It is important to note that these e-mail services must already be installed on WHITE-SRV1 and WHITE-SRV2. In this example, the e-mail migration happens so quickly that users may not even notice. In most cases, they will only lose e-mail access for a few seconds. When the problems with WHITE-SRV3 are resolved, you can migrate both e-mail services back to their original host server. This process, known as failback, can be accomplished manually or automatically. By default, NCS configures failback in manual mode. This gives you the opportunity to test the WHITE and BLUE e-mail services on the newly restored WHITE-SRV3 before you make them live. You can, however, with a flip of a switch, configure NCS for automatic failback. This means WHITE-SRV3 will initiate its original e-mail services as soon as it is added back to the cluster. That completes our lesson in NCS system design. As you can see, this is a complex and sophisticated system. Believe us when we say that Novell Cluster Services is not for the faint of heart. However, the rewards are great! You will quickly gain hero status for maintaining five 9s availability on mission-critical systems. Now let's complete our NCS design lesson with a quick jaunt through SAN management. NCS Storage Area Network (SAN) Management Just as in life, rules in networking separate cluster services from storage chaos. In this section, we explore a number of SAN management and troubleshooting rules for maintaining an orderly cluster system. Let's start with the following four guidelines for avoiding data corruption or volume loss: Noncluster Servers Don't attach a noncluster server to a central shared storage device unless you isolate the system so that the noncluster server only has access to its own volumes. Remember that all servers attached to the shared storage device (whether in the cluster or not) have access to all volumes unless you specifically prevent such access. NCS manages access to shared volumes for all cluster nodes, but cannot protect shared volumes from being corrupted by noncluster servers. NetWare 6 Installation Don't install NetWare 6 on a server that is currently attached to shared storage. You must first disconnect the shared device from the server before installing NetWare. This rule is necessary because NetWare 6 installation deletes all NetWare partitions it finds on local and shared storage devices. Imagine the chaos in your high-availability solution if your NetWare partitions suddenly disappeared. Ouch. NSS Cluster Volume Operations Don't perform NSS cluster volume operations (such as deleting, resizing, and renaming) from noncluster nodes. Shared Volumes Don't clutter the shared storage device with volumes that can be kept on local server drives. Only place volumes on shared storage that contain data or files that need to be shared by multiple users or multiple applications. This way you can keep your cluster uncluttered.
In addition to SAN management, there are a number of rules that can help you troubleshoot SAN problems when they occur. Most problems in setting up a SAN result from errors in preparing and connecting devices on the SCSI bus. If you have problems with your SAN, use the following troubleshooting rules to check your configuration: Multi-Initiator Enabled Is the SCSI adapter card and driver you are using multi-initiator enabled? (That is, can it support multiple host adapters on the same SCSI bus?) NCS requires this feature when attaching multiple nodes to a single shared device. To determine the capabilities of your SCSI adapter card and drivers, refer to the manufacturer's website. Beware, only a few third-party drivers support multi-initiation. Personally, I like to use the Adaptec 2940 adapter card with the Novell .HAM driver. SCSI Hardware Installation Make sure that all SCSI cables in the cluster have the same impedance and the same length, and that the same manufacturer built them. In addition, make sure that all SCSI devices are turned on and that the adapter cables and power are properly connected. Finally, confirm that the SCSI adapter card is seated securely in the motherboard of each cluster node. Unique SCSI IDs Each device in the SCSI bus (including adapter cards and hard drives) must have a unique SCSI ID number. Most SCSI hard drives are preset with an ID number of zero (0) and SCSI adapter cards are preset with an ID number of seven. If you are using an external SCSI hard drive, the SCSI ID number is usually set with a switch on the back of the device. Finally, when configuring a two-node SCSI cluster for NCS, consider using seven as the SCSI ID for one card and six for the other card. Even if higher ID numbers are available (such as 8 through 15), avoid using them with NCS. SCSI Hard Drive Termination To ensure reliable communication on the SCSI bus, the end devices must be properly terminated. For a two-node NCS SCSI cluster, each SCSI adapter must be terminated. Furthermore, the hard drive is not terminated because it sits in the middle of the SCSI bus system. Termination on most SCSI hard drives is controlled by installing or removing a SCSI terminator plug. However, some hard drives allow you to enable or disable termination by using a switch on the back of the drive. SCSI Hard Drive Low-Level Format Every SCSI hard disk must be low-level formatted, partitioned, and logically formatted before it can store data. Most SCSI drives are preformatted at the factory. However, if you connect a used SCSI hard drive to the NCS nodes for clustering, you must perform a low-level format before you can use the drive. Because this process destroys all data on the drive, make sure you back up the data before performing a low-level format. Finally, consider using the SCSI utility to configure various BIOS settings on your SCSI adapter card. See Table 7.3 for more details.
Table 7.3. SCSI Adapter Card BIOS Settings for NCSBIOS SETTING | SUGGESTED NCS CONFIGURATION |
|---|
Maximum Sync Transfer Rate | Set both SCSI adapter cards to a common transfer speed. If one card is transferring data at a faster rate than the other, you might experience problems when running the NCS cluster. | Advanced "Speed Up" Options | Disable advanced options designed to increase the speed of transferring data. These include Wide, Ultra, and Send Start Unit Command. | Extended BIOS Translation for DOS Drive | Turn off (or disable) drive translation. This function can be fatal to NetWare and possibly cause an abend. |
Good job, you have successfully designed a sophisticated clustering system. In this lesson, we learned Novell's basic clustering system architecture and explored Fiber Channel and SCSI configurations. In addition, we used heartbeats and Split-Brain Detector to monitor the LAN and SAN. And with these tools in place, we learned how slave and master node failover works. Finally, in the last section of this lesson, we armed ourselves with some important rules for SAN management and troubleshooting. Now, we think you're ready for the real action installing Novell Clustering Services. So far, you have mastered the fundamentals of NCS and designed a basic system architecture. Now let's build one for ourselves. Ready, set, cluster! |