B-trees
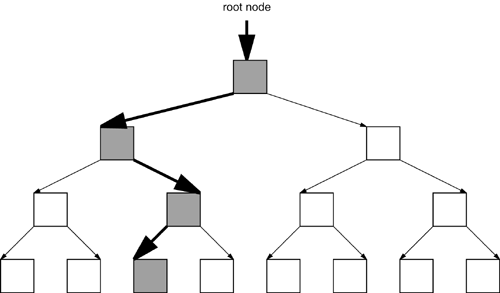
| Two types of searches are possible when you're retrieving data from your database. An internal search occurs when you're searching a file that fits into your computer's internal memory. When you need to retrieve data from a very large file, though, the search is called an external search because the entire file doesn't fit into the available RAM. B-tree structures lend themselves nicely to external searchingthey make it possible both to search and to update a large file with guaranteed efficiency. All DBMSs depend on B-treesthey are the default structures built when you create an index and are also the structures that will be used to enhance retrieval in most cases. Each of the Big Eight use the B-tree. Informix alone says explicitly that it uses a variant called the B+-tree, but the rest of the Big Eight do too. None of the Big Eight use the other important variant, the B*-tree. A B-tree is essentially just a sorted list of keys, which are {data, pointer or row locator} combinations. The actual structure of a B-tree consists of a number of nodes stored as items in the B-tree's file. Each node contains a portion of the sorted list of keys in the B-tree, along with pointers to other nodes. The root node for a given B-tree is where all searches through that tree begin. Figure 9-1 shows a simplified example of this principle. Figure 9-1. Searching a B-tree
In a B-tree, records are stored in locations called leaves. The name derives from the fact that records always exist at endpointsthere is nothing beyond them. The maximum number of children per node is known as the order of the tree. A practical B-tree can contain thousands, millions, or billions of records. The four characteristics that describe a B-tree are: sortable, selective, subset, balanced.
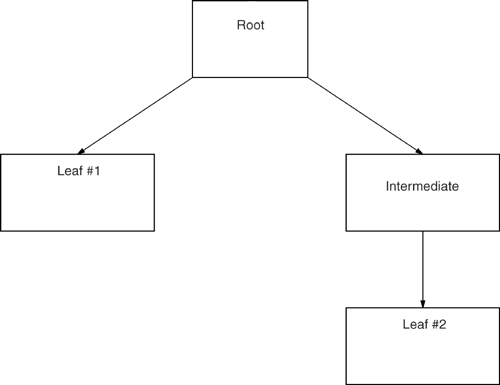
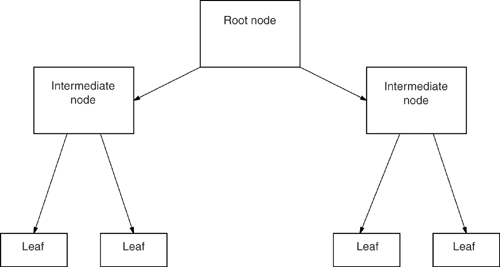
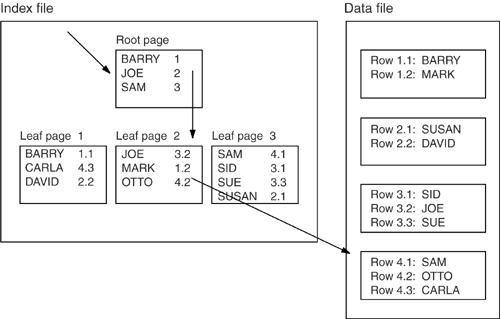
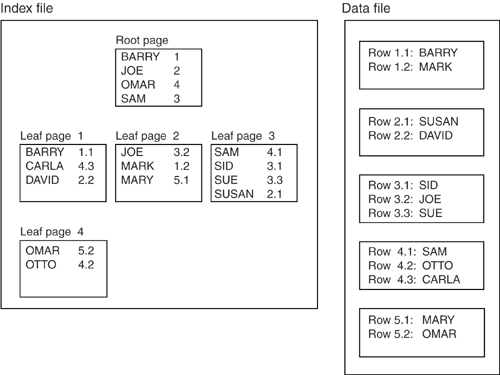
Confusingly, it's traditional to diagram a tree upside downthe root is sometimes called the "top layer" and the leaf is the bottom. The interesting thing to note about the tree shown in Figure 9-2 is that a direct pointer leads from the root to leaf page #1, but an intermediate node is between the root and leaf page #2, which is what makes the tree unbalanced. Therefore, eponymously, Figure 9-2 is not a B-treeB-trees are always balanced. In a Btree, all the keys are grouped inside fixed- size pages. The keys in the root page point to intermediate pages, the keys in the intermediate pages point to leaf pages, and the keys in the leaf pages point to data rows. That, at least, is what happens when three levels (or three layers ) are in the index, and the index is not clustered (the "clustered index" exception is something we'll talk about later). Figure 9-3 shows a three-level B-tree. Figure 9-3. Three-level B-tree showing root, intermediate, and leaf pages Searching a B-treeSuppose you have the table and index shown in Figure 9-4 (we'll call this our example database) and execute this SQL statement: SELECT * FROM Table1 WHERE column1 = 'OTTO' Figure 9-4. Example database with B-tree index To evaluate this query, the DBMS starts by scanning the index's root page. It scans until it's pointing to a key value that is greater than or equal to OTTO (in this case, SAM ). Now OTTO , if it exists, is on the path that is pointed to by the key just before that (in this case, JOE ), so the DBMS loads leaf page #2. Then it scans leaf page #2, looking again for the first value that is greater than or equal to OTTO (in this case, OTTO ). This second scan tells the DBMS to load data page #4. Once it has done so, it finds OTTO in the second row in that page. Two things are worth noting about this system:
The notes here are about exceptions and details. The fundamental point is much simpler: The DBMS needed two page reads to find the key. This figure is fixedthe number of index levels equals the number of reads, always, except that you can be fairly confident that the root page is in a cache. (There is actually one exception: If the DBMS is scanning leaf pages sequentially, there is no need to visit intermediate or root pages so the reads are fewer.) For example, suppose you execute this query: SELECT column1 FROM Table1 ORDER BY column1 and the DBMS decides to resolve the query by going through all the keys in the index, sequentially. In that case, with most DBMSs, the transit is from leaf page to leaf page directly and not via the upper (i.e., intermediate or root) index levels. This is because there are pointers from one leaf page forward to the next leaf or from one leaf page back to the previous leaf. The critical thing, then, is the number of layersnot the total index sizeand that's why it's good to have big pages. Typically an index page size is 8KB. It's this mandateKeep the number of layers small!that influences several of the design and updating decisions that programmers must make. A rule of thumb is that the number of layers should never exceed five. If there are more than five layers, it's time for drastic measures like partitioning. (This rule is somewhat arbitrary, as all "rules of thumb" arewe're just passing on the general consensus from many diverse sources.) Inserting into a B-treeWhen you INSERT a new row, or UPDATE with a new value for an indexed column, the result includes the insertion of a new key value into the index. Usually the insert of a new key value is simple:
What if a key value insert isn't simple? For example, what happens with our example database (Figure 9-4) if the following SQL statements are executed? INSERT INTO Table1 VALUES ('MARY') INSERT INTO Table1 VALUES ('OMAR') The page doesn't contain enough room on which to fit these new key values. To make them fit, the DBMS must take some keys out of the current page and put them in a new pagefor example, at the end of the index file. [1] This process is called splitting. The rules for splitting are as follows :
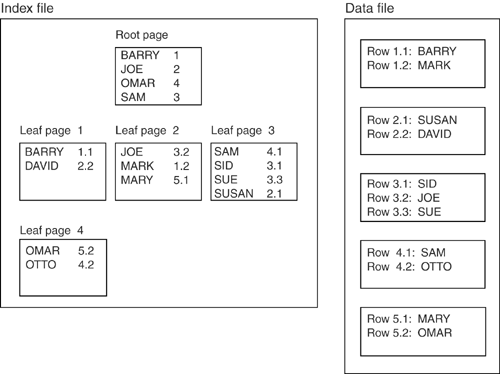
Figure 9-5 shows what the example database looks like after the INSERTs. Figure 9-5. Example database after INSERTs [*]
The effect of INSERT is much like the effect of dripping grains of sand, one grain at a time, onto the top of a pile. For a long time nothing happens, but eventually the addition of one more grain causes an avalanche, the shape of the pile changes, and a new equilibrium is reached. Because of splits, the speed of data-change statements (INSERT, UPDATE, DELETE) may vary unpredictably. To reduce that unpredictability , you can instruct the DBMS to leave a little bit of space in every page and therefore make splits unlikely . This is done with PCTFREE or FILLFACTOR (see the section "Free Page Space" in Chapter 8, "Tables"). But PCTFREE/FILLFACTOR and their ilk affect only the free space left during index creation or rebuilding. During data-change operations, splitting occurs only if there is absolutely no chance of fitting the new key in the page. Because of the rules of splits, a page will be less than 100% full after a large number of random key insertions (because of waste space at the end of the page), but more than 50% full (because a split makes pages 50% [2] full and then there's room for some INSERTs that won't cause a split). The rule of thumb to follow here is to assume pages are 70% full if insertions are random, or more than that if insertions are done in an ascending sequence.
Deleting from a B-treeThere are two ways to delete keys from B-trees: the obvious way, and the Microsoft/Oracle way. If the DBMS treats deletions as merely insertions in reverse, the deletion rules are:
Microsoft and Oracle don't do deletions the obvious way. For these DBMSs, the deletion rules are:
The obvious advantage of the Microsoft/Oracle way is that the expense of shifting and cascading is eliminatedfor now. (An additional and perhaps more important reason has to do with a special type of lock called a "key range lock," which we'll discuss in Chapter 15, "Locks.") That's all very well, and the space is reused when a new value will fit in the same place or when a low-priority background thread clears up the page. However, it does mean you shouldn't repeatedly change an indexed column to an ever- newer value. Consider this snippet of code, part of a program to make an index grow indefinitely: for (i=0; i<1000000; ++i) { num=rand(); EXEC SQL UPDATE Table1 SET column1 = :num; } We ran a program containing a loop like this after inserting 10,000 rows into Table1 . When the program finished, the index had at least doubled in size. So although the old tipDo DELETE before INSERTis still good, it isn't as powerful as it once was. Let's do one more change to our example database (Figure 9-5). We'll DELETE with this SQL statement: DELETE FROM Table1 WHERE column1 = 'CARLA' Now, assuming the DBMS has deleted the obvious way, the example database won't have any ghost rows but will still look rather messy. Figure 9-6 shows what it looks like now; this is what is known as a fragmented database. Figure 9-6. Example database after DELETEfragmented FragmentationSo far, we've done two INSERTs and one DELETE on the example database, and the result is a horrible mess! Look at everything that's wrong with Figure 9-6:
Hey, we admit this isn't a real example. In particular, by limiting the page size so the maximum number of rows per page is four, and by making changes in precisely the wrong places, we've made it look very easy to cause a mess. In fact, though, on a real database, the rule of thumb is that you don't have to worry about fragmentation and skewing until the number of rows you've changed or added is equal to more than 5% of the total number of rows in the database. After that, it's probably time to rebuild. Tools are available to check how messy an index looks, but they're vendor-specific so we'll skip them and proceed right to the rebuilding step. Rebuilding a B-treeIf you've followed us this far, you know that rebuilding will be an inevitable part of database life until DBMSs learn how to rearrange indexes automatically during regular activity. Skew and fragmentation cause a need for cleanup. There are two ways to do it: ALTER INDEX/REBUILD or DROP INDEX/RECREATE. ALTER INDEX/REBUILDWe're being vague with our syntax here because it varies, but most DBMSs support some type of nonstandard SQL extension that will "rebuild" an index. The important thing is that rebuilding doesn't really happen. What does happen is shown, in pseudocode, in Listing 9-1. Listing 9-1 Pseudocode of ALTER INDEX/REBUILDfor (each leaf page) if (first index key in page could fit in prior leaf page) if (insert wouldn't overflow past index's free page space) shift this index key to the prior leaf page shift following keys up; adjust intermediate-page pointers repeat for (each intermediate page) do approximately the same things as for leaf-page loop We have left out some important matters in Listing 9-1, such as what to do if a page becomes empty and the index can be shrunk. But the important thing is that the algorithm will fix skew. It won't, however, fix fragmentation. Table 9-1 shows the command each of the Big Eight provides for index rebuilding. DROP INDEX/RECREATEAlthough it's reasonable to guess that it will take 100 times longer than ALTER INDEX/REBUILD, sometimes the only way to fix an index is to drop the index (with the nonstandard SQL-extension statement DROP INDEX) and then remake it with CREATE INDEX. And even that won't be enough unless you also run an operating system defragger program. We can only say that DROP INDEX/RECREATE should be more frequent than it is, but there is no rule of thumb and no consensus about this. In this context, let's address some general issues about "bulk changes"changing many keys at once. Long ago, someone had the insight that if bulk changes were made in order by key value, the process would go much more quickly because the DBMS would always be going forward to a later page in the index. It would never have to backtrack, and therefore the heads would not thresh back and forth on the disk drive. This is relevant to CREATE INDEX because, as it happens, all DBMSs have optimized CREATE INDEX so that the DBMS will sort the keys before putting them in the index. That's why you'll often see the tipLoad data first, make index second. Presorting the keys yourself is so much better that you'll even see this tipIf you're going to change more than 5% of the keys, drop the index first and create it again when the changes are over. (Of course, you'll make sure that the relevant table can't be used by another transaction while you're doing this!) Table 9-1. DBMS ALTER INDEX/REBUILD Support
In an ideal world, you would sort the rows you were about to process (e.g., by UPDATE statements), so that the DBMS could update the index in key order, but within a pagedoing deletions before insertions so that room would be guaranteed for the new keys. The latest version of Microsoft's DBMS does such sorting automatically. Finally, most DBMSs will allow options like "disable index" (e.g., MySQL, Oracle) or " defer index key write" (e.g., MySQL). These options are confessions of weakness on the DBMS maker's part, but that is no reason to disdain them. Tip Just before a peak period, anticipate by rebuilding your index even if it's not fragmented. Use PCTFREE/FILLFACTOR, so that lots of space will be in each index page when the split times come. The Bottom Line: B-treesAll DBMSs depend on B-treesthey are the default structures built when you create an index and are also the structures that will be used to enhance retrieval in most cases. A B-tree is sortable because you travel through a B-tree's keys in order. A B-tree is selective because you want to get only some of the rows. A B-tree is a subset because the key value (the part of an index key other than the pointer) is completely derived from the column value in the data row. A B-tree is balanced because the distance from the root to any leaf is always the same. When searching a B-tree, the DBMS is scanning keys that are known to be in order, so it can do a binary searchnot a sequential searchof the keys in the page. Thus it makes no difference whether keys are at the start or at the end of the pagesearch time is the same. The number of B-tree index levels equals the number of index page reads, always, except that you can be fairly confident that the root page is in a cache. The critical thing is the number of B-tree layersnot the total index sizeand that's why it's good to have big pages. Keep the number of layers small! A rule of thumb for B-trees is that the number of layers should never exceed five. If there are more than five layers, it's time for drastic measures like partitioning. The rules for index splitting are:
Because of splits, the speed of data-change statements may vary unpredictably. To reduce that unpredictability, you can instruct the DBMS to leave a little bit of space in every page and therefore make splits less likely. Because of the rules of splits, a page will be less than 100% full after a large number of random key insertions (because of wasted space at the end of the page) but more than 50% full (because a split makes pages 50% full and then there's room for some INSERTs that won't cause a split). The rule of thumb to follow is to assume pages are 70% full if insertions are random, or more than that if insertions are done in an ascending sequence. Don't repeatedly change an indexed column to an ever-newer value. You don't have to worry about fragmentation and skewing until the number of rows you've changed or added is equal to more than 5% of the total number of rows in the database. After that, it's probably time to rebuild. Skew and fragmentation cause a need for cleanup. There are two ways to do it: ALTER INDEX/REBUILD or DROP INDEX/RECREATE (syntax deliberately vague). If bulk changes are made in order by key value, the process goes much more quickly because the DBMS is always going forward to a later page in the index. Soload data first, make index second. If you're going to change more than 5% of the keys, drop the index first and create it again when the changes are over. Just before a peak period, anticipate by rebuilding your index even if it's not fragmented. Use PCTFREE/FILLFACTOR, so that each index page will have lots of space when the split times come. |
EAN: 2147483647
Pages: 125