Scraping RSS from HTML
| In the RSS world, the process of extracting data from a Web site is called scraping, and there are several ways to do it. Some software looks at a site and guesses what you want in an RSS feed, and other software requires that you set up your site in a certain way so it can scrape data off it easily. Both kinds are valid, so which software you choose is up to you. Note Don't start scraping Web sites and publishing the content in your own RSS feeds before you get permission. RSS with FeedFireFeedFire (www.feedfire.com) is an easy software package to start with (Figure 6.1). Figure 6.1. Registration is free at FeedFire.com. To log in you need to register first, and registration is free. After you've set your user name and password, log in, and it's time to create a new channel by scraping a Web page. In this example, a sample feed for the USAToday.com home page was created to show how FeedFire works. The USA Today's URL has been entered in FeedFire's Create a Channel page (Figure 6.2). Figure 6.2. Creating a new channel at FeedFire.com is easy. When you click the Create button, the new sample channel is created for you (Figure 6.3). Figure 6.3. The new feed is based on the home page of USAToday.com. FeedFire creates RSS 1.0 feeds. <?xml version="1.0" encoding="ISO-8859-1"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns="http://purl.org/rss/1.0/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:ag="http://purl.org/rss/1.0/modules/aggregation/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:syn="http://purl.org/rss/1.0/modules/syndication/"> <channel rdf:about="http://www.usatoday.com"> <title>USATODAY.com News & Information Homepage</title> <link>http://www.usatoday.com</link> <description>Up-to-the-minute news & information including National and International News, Money, Sports, Life, Tech and Weather news updated 24/7. Created by FeedFire.com</description> <syn:updatePeriod>daily</syn:updatePeriod> <syn:updateFrequency>1</syn:updateFrequency> <dcterms:modified>2005-12-29T16:12:40+00:00</dcterms:modified> <dcterms:created>2005-12-29T16:12:40+00:00</dcterms:created> <items> <rdf:Seq> <rdf:li rdf:resource="http://www.usatoday.com/life/2005-12-28- year-in-bad-news_x.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/ interactive-media.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/gallery/ 2005/12-28-day/flash.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/nation/2005- 12-27-oklahoma-fires_x.htm" /> <rdf:li rdf:resource="http://usatodaytv.feedroom.com/ ?fr_story=FEEDROOM127556" /> <rdf:li rdf:resource="http://www.usatoday.com/news/health/2005- 12-28-smoking-limits_x.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/world/2005- 12-29-israel-explosion_x.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/money/economy/ housing/2005-12-29-existing-homes_x.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/ washington/2005-12-28-corps-jeep_x.htm" /> <rdf:li rdf:resource="http://www.usatoday.com/news/nation/2005- 12-28-young-moving_x.htm" /> . . . </rdf:Seq> </items> </channel> <item rdf:about="http://www.usatoday.com/life/2005-12-28-year- in-bad-news_x.htm"> <title>2005 seemed to validate Chicken Little's pessimism</title> <link>http://www.usatoday.com/life/2005-12-28-year-in-bad- news_x.htm</link> <dc:date>2005-12-29T16:12:40+00:00</dc:date> </item> <item rdf:about="http://www.usatoday.com/news/interactive- media.htm"> <title>Interactive Media</title> <link>http://www.usatoday.com/news/interactive-media.htm</link> <dc:date>2005-12-29T16:12:40+00:00</dc:date> </item> . . . </rdf:RDF> To subscribe to this new feed, use the XML button. There are a couple of things you should notice about this USA Today feed (Figure 6.4). One is that it's simple, showing only links, not item content. Another is that the items in the RSS feed don't appear in the same order as on the original Web page. FeedFire also often puts ads in its free RSS feeds. Figure 6.4. The new USA Today feed is displayed in the description window.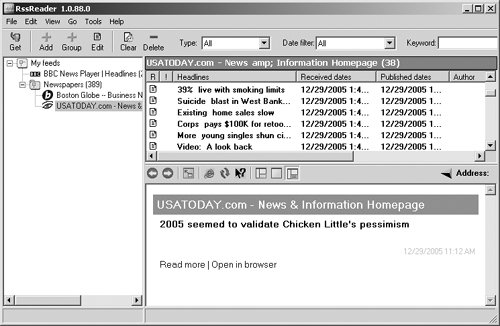 You can also pay for various other levels of RSS feed creation at FeedFire. In the paid levels, you can list keywords to specify what links you want to include in your feed, and you can "sponsor" a feed, which allows you to place your name at the beginning of the feed's name. RSS with myWebFeedsAnother Web-site scraper is myWebFeeds, at www.mywebfeeds.com (Figure 6.5). Figure 6.5. You can turn any Web page into a feed with myWebFeeds. Select the Build Me a Feed link to create a new feed, and enter the URL (Figure 6.6)here, http://www.usatoday.com. Figure 6.6. Just follow the directions to build a new feed at myWebFeeds. The Preview button lets you see the items in the new feed (Figure 6.7). However, setting up a new feed at myWebFeeds isn't free. Figure 6.7. There is a fee to receive the code for a feed at myWebFeeds.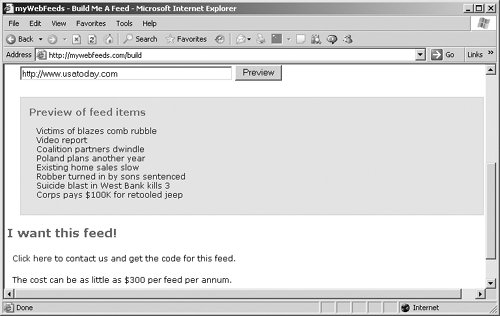 FeedFire and myWebFeeds are nice tools that let you scrape Web sites and publish RSS feeds from those sites. If you want to extract more detailed information, however, you have to customize the Web pages you're scraping for data. RSS with W3C's Online ServiceThe World Wide Web Consortium's online Web-site scraper gives you more power but at the price of more work (Figure 6.8). When something is from the W3C, as you might expect if you've ever worked with W3C specifications, things can get complex. Figure 6.8. The W3C site gives directions on how to configure your XHTML page. For starters, you can only scrape XHTML pages, not HTML. XHTML, which stands for Extensible Hypertext Markup Language, is the W3C's recasting of HTML 4.01the final version of HTMLin XML 1.0. (You can read all about XHTML at www.w3.org/TR/xhtml1/.) In other words, XHTML documents are XML documents that look just like HTML to a browser. Note Remember that you can make up your own tags in XML. You use XML tags to match the standard HTML tagsfor example, <html>,<head>, <body>, and so on, and they look like normal HTML tags to the browser. But since the tags are actually XML tags, the resulting document is an XML document even though its extension is .html. XHTML has two advantages: First, it can be validated just like any XML document, and validating an XHTML document will show you any syntax errors in the document. Second, because it's XML, you can extend XHTML by creating your own tags. (However, you have to do some fancy footwork to make the browser understand what the new tag is supposed to dousually, you use Cascading Style Sheets (CSS) styles to customize what a new tag does in the browser.) There are plenty of rules that specify how to write XHTML, and as a result it's cumbersome and hasn't really caught on among the home page crowd, although it's popular on corporate Web sites. Tip Still confused about XHTML? The W3C provides a tool to help convert XHTML into HTML. Read on. To scrape an XHTML Web page and create an RSS 1.0 feed, go to www.w3.org/2000/08/w3c-synd (Figure 6.8). I used a simple XHTML page and scraped it to create an RSS feed (Figure 6.9). In order to be scraped, an XHTML page has to use a lot of special XHTML behind the scenes. For example, you can see some of the directions on how to configure your XHTML page in Figure 6.9. Figure 6.9. Here's a sample XHTML page. How do you build an XHTML page that can be scraped? Let's create news.html, an XTHML page, to show how this works. You start news.html like any XML document, with an XML declaration: <?xml version="1.0" encoding="utf-8"?> . . . There are three main types of XHTML: strict, transitional, and frameset. Strict XHTML 1.0 will be used in this example. To indicate to the browser that you're using strict XHTML 1.0, use a <!DOCTYPE> element that points to the strict XHTML 1.0 DTD (recall from Chapter 4, "Creating RSS Feeds from Scratch," that DTDs let you check an XML document's validity and make sure there are no syntax errors). Here's the strict XHTML 1.0 <!DOCTYPE> element: <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> . . . Now you can add the <html> element, giving it the standard XHTML namespace of http://www.w3.org/1999/xhtml. <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> . . . You also specify how you're going to work with XHTML so that the W3C tool can convert the document into RSS (with <div> elements and class attributes to set up an RSS item, for example) using the profile attribute of the <head> element. The profile attribute should be set to http://www.w3.org/2000/08/w3c-synd/#, as you see in news.html: <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> . . . The name of the new RSS channel is taken from the XHTML document's <title> element; that title in our example is Steve's News. Note In XHTML, each <head> element must contain one, and only one, <title>element. <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> . . . So far, so good; you've named your new channel. To create items for your RSS feed, you use the <body> element of the document. To create a new item, you use a <div> element with a class attribute set to "item". <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > . . . Using a <div> opening tag with a class attribute set to "item" starts a new item. To set the title of the item you must use an <h3> XHTML element. The title of this item is set to "Steve shovels the snow." <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> . . . At this point, then, a new item has been created and given a title. Now it's time to add a description using a <p> element. <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p> . . . </p> </div> </body> </html> To set the date of an item, you can use a <span> element with a class attribute set to "date". <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p> <span >2005-12-29</span> . . . </p> </div> </body> </html> Now you can add the text for the item. <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p> <span >2005-12-29:</span> It snowed once again. Time to shovel! . . . </p> </div> </body> </html> Finally, you can add a link to the full text of the document using an <a> element with a rel attribute set to "details" and an href attribute set to the URL of the item's full text. <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p> <span >2005-12-29:</span>It snowed once again. Time to shovel! <a rel="details" title="Snow Item" href="http://www.rssmaniac.com/news.html"></a> </p> </div> </body> </html> In order to give the W3C converter access to your XHTML Web page, that page has to be online. (In general, that's not a big problem because Web pages are supposed to be online, but it would have been nice if the W3C had provided a way to read the Web page from your hard drive or allowed you to paste it into its converter to make testing and development of your Web pages a lot easier.) So to see how to convert your XHTML page to RSS, first upload the page so it is available online. Then go to the W3C converter page and enter the URL of your XHTML page (don't change the XSL file URLXSL stands for Extensible Stylesheet Language, and it's used to convert your XHTML into RSS). When you're ready, click the Get Results button (Figure 6.10). Figure 6.10. Fill in the information about the XHTML page you want to scrape. If all goes well, a new page appears displaying your RSS items. That's what you want. Tip If all doesn't go well when you try to convert your file, check your Web page's XHTML with the W3C validator at http://validator.w3.org/. It'll tell you if there's something wrong with your XHTML. Now view the page source in the browser (select View > Source in Internet Explorer or View > Page Source in Firefox) to see the XML for the page. That XML is the RSS 1.0 version of your RSS feed. Here's what the RSS 1.0 looks like for our example, as created by the W3C converter: <?xml version="1.0" encoding="utf-8"?> <?xml-stylesheet href="http://www.w3.org/2000/08/w3c- synd/style.css" type="text/css"?> <rdf:RDF xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:h="http://www.w3.org/1999/xhtml" xmlns:hr="http://www.w3.org/2000/08/w3c-synd/#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns="http://purl.org/rss/1.0/"> <channel rdf:about="http://www.rssmaniac.com/steve"> <title>Steve's News</title> <description/> <link>http://www.rssmaniac.com/steve</link> <dc:date/> <items> <rdf:Seq> <rdf:li rdf:resource="http://www.rssmaniac.com/news.html"/> </rdf:Seq> </items> </channel> <item rdf:about="http://www.rssmaniac.com/news.html"> <title>Steve shovels the snow</title> <description>2005-12-29:It snowed once again. Time to shovel!</description> <link>http://www.rssmaniac.com/news.html</link> <dc:date>2005-12-29</dc:date> </item> </rdf:RDF> There you goyour Web page has been scraped and turned into RSS 1.0. It's a fairly quick process if you write your Web pages in XHTML, but the XHTML part can be a problem for many people. Converting HTML to XHTMLThe W3C has another online tool that can convert HTML pages into XHTML; that tool, at http://cgi.w3.org/cgi-bin/tidy, is named Tidy (Figure 6.11). The original purpose was to "tidy up" the HTML in Web pages. (There's a great deal of sloppy HTML on the Internetnesting errors, no closing tags, and so on; by some estimates, nearly half the code in browsers is there to deal with problematic HTML.) Figure 6.11. Use the W3C's Tidy tool to convert HTML pages to XHTML. Say you've written an HTMLnot XHTMLpage that uses the conventions that the W3C converter needs to turn a page into RSS, such as using a profile attribute in the <head> opening tag, a class attribute set to "item" in a <div> opening tag to create an RSS item, and so on. Your HTML file might look like the following: <html> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p> <span >2005-12-29:</span>It snowed once again. Time to shovel! <a rel="details" title="Snow Item" href="http://www.rssmaniac.com/news.html"></a> </p> </div> </body> </html> You can convert the HTML file into XHTML by uploading this document, entering the URL into the Tidy page (click the indent check box if you want the results to be indented), and then clicking the Get Tidy Results button. You can see the results as they appear in Internet Explorer (Figure 6.12). Figure 6.12. The HTML page was converted to XHTML. To get the XHTML source, go to View > Source or View > Page Source as before, and copy the XHTML. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head profile="http://www.w3.org/2000/08/w3c-synd/#"> <meta name="generator" content= "HTML Tidy for Linux/x86 (vers 12 April 2005), see www.w3.org" /> <title>Steve's News</title> </head> <body> <div > <h3>Steve shovels the snow</h3> <p><span >2005-12-29:</span>It snowed once again. Time to shovel! <a rel="details" title="Snow Item" href= "http://www.rssmaniac.com/news.html"></a></p> </div> </body> </html> Tidy is a useful tool if you want to use the W3C converter to scrape XHTML pages into RSS, and you can create HTML pages if you're not familiar with XHTML. RSS from EmailHere's another option: You can automatically create RSS feeds from email. That's a cool way of creating RSS feeds, and we'll take a look at how it works here. This technique is especially useful if you have regular mass mailings and you want to make the content available via RSS feed. RSS with NewslettersByRSSUsing NewslettersByRSS (www.newslettersbyrss.com/pubDefault.aspx), you can create RSS feeds automatically from email (Figure 6.13). First sign up at the site by filling in your name, email address, newsletter title, description of your feed, Web site URL, and the other requested information. Figure 6.13. Click the Learn More links on NewslettersByRSS site to get additional information about sending and using newsletters. After you sign up at NewslettersByRSS, you're given an email address where you can send your news (Figure 6.14). When you want to send email to an email listor just add an item to your RSS feedmake sure you send it to the address you're given. NewslettersByRSS will generate an RSS 2.0 feed for you, based on your email. Figure 6.14. You've successfully created an account. You'll next see a confirming Web page that lists ways to publicize your feed (Figure 6.15). Note the link to the RSS Link Page, which gives you the URL for your created feed. Figure 6.15. Copy any of the RSS graphics to use for your newsletter. NewslettersByRSS gives interested readers an easy way to subscribe to the content of your newsletter as a feed instead of receiving it via email (Figure 6.16). Figure 6.16. NewslettersByRSS makes it easy for your subscribers to read your feed. The URL for the new feed will also be sent to you in a confirming email, as well as your publisher ID and password, and the email address to add to your email list. When you send out a mailing to your email list, make sure that you also send the email address NewslettersByRSS gives you so that it can publish the email in your RSS feed. The subject line of your newsletter email will become a new item's title in your RSS feed, and the date of your email will become the date of your new item. It's that simplejust sign up with NewslettersByRSS, get an email address and URL for your new feed, send your email to that email address, and NewslettersByRSS publishes your feed. Here's the RSS 2.0 that was created when an email was sent to NewslettersByRSS. <?xml version="1.0" encoding="us-ascii"?> <rss version="2.0"> <channel> <title>Steve's News</title> <link>http://www.NewslettersByRSS.com/952.nbrss</link> <description>News from Steve!</description> <generator>NewslettersByRSS v1.0</generator> <atom:link xmlns:atom="http://www.w3.org/2005/Atom" rel="self" href="http://www.newslettersbyrss.com/Feed/952.xml" type="application/rss+xml" /> <image> <title>Steve's News</title> <url>http://www.newslettersbyrss.com/images/powered_by_rss.gif </url> <link>http://www.NewslettersByRSS.com</link> </image> <item> <title>Steve shovels the snow</title> <link>http://www.NewslettersByRSS.com/30594.952.nbrss</link> <description>It snowed once again. Time to shovel!</description> <pubDate>Fri, 30 Dec 2005 11:55:03 GMT</pubDate> </item> </channel> </rss> RSS with iUploadBesides dedicated email-to-RSS utilities like NewslettersByRSS, many blog sites let you post blog entries by email, and they'll create an RSS feed for you. In other words, you just email your items to the blogging site and it'll create your RSS feed for you. One such site is iUpload at www.iuplog.com (Figure 6.17). Figure 6.17. iUplog.com can create an RSS feed for you. To create a blog that you can email to, enter your information, the name of your new blog, a description, and other information requested. Click Submit to create your new, empty blog (Figure 6.18). Figure 6.18. Although not available in this empty blog, the iUpload site provides viewer stats for each blog. When your new blog is created, you get a confirming email that includes an email address for where to send your posts. After emailing your posts to iUplog, they appear in your blog (Figure 6.19). Figure 6.19. Here's a new post with my blog. You can use the RSS button to subscribe to your new RSS feed, which can then be read in RSS readers such as SharpReader (Figure 6.20). Figure 6.20. A new feed from iUpload appears in SharpReader. RSS with Automatic SoftwareThere's also free software available that works on Web servers and can scrape or create RSS feeds for you. If you want to use a software package to scrape Web sites and create RSS, be sure that your Web site can run Perl, Python, Java, or whatever language the package you want to use needs. For more information, check the Web sites for the software package you're interested in using. Here's a starter list of available RSS-scraping software:
|