Implementing the design
2.3 Implementing the design
Once we are satisfied with the database design, it is time to physically create our database. Initially, one should create a small-scale version of the database and test design ideas here before building the full-size production system. There are various tools available to the designer to help create the warehouse; these will be discussed in other chapters. Here we will see how to create our database using nothing more sophisticated than SQL.
Database designers often prefer to create a script file containing the SQL commands to create the database, and this is perfectly acceptable. An alternative approach is to use the graphical user interface (GUI) tools in Oracle Enterprise Manager, which will be illustrated here.
| Hint: | If the SQL is complex, use these GUI tools to create the SQL, and then paste the SQL into your text file. |
In this section, we will walk through the various stages required to create our data warehouse. First we will see how to create the actual database and then learn how to create the tablespaces and data files where the actual data is stored. That will be followed by illustrations of how to create the tables and a brief introduction on creating the indexes and partitions. Finally, we will discuss materialized view creation and how to secure the objects in the data warehouse that we have just created.
2.3.1 Single database or many?
There was a time when the data warehouse was created in its own database. However, times are changing, and now some companies prefer to have a single database that contains all systems.
There are pros and cons for each approach, and whether you choose a single database or multiple databases will depend upon your business requirements. Creating a new database is not a difficult job, and the best approach is to use the GUI tool, Oracle Database Configuration Assistant. Once the database has been created, you can then add your own data files and tablespaces using Oracle Enterprise Manager Console GUI or SQL scripts.
A database can be created directly from SQL, but, if this approach is used, then it should be performed with care, because you will need to run a number of script files that are required by Oracle 9i. If you use the GUI, this work is done automatically.
2.3.2 Naming conventions
Before anything is created in the database, the naming conventions used for all database objects, such as data files, tablespaces, and table and column names, should be reviewed. Depending on the tools available to your end users, they may actually see these table and column names. Therefore, if they do not have sensible names, these end users, who are generally not computer literate, could be very confused.
In our Easy Shopping Inc. example, there is a column in the fact table called "time_key." Now, for people familiar with databases, it is obvious what that field contains, but to our end users of the warehouse it means nothing. Therefore, in this instance, a better column name might be "date_time_of_purchase." The warehouse designer should also remember that if end users will be using the warehouse, a more English-like column name should be provided.
So far we have not discussed the topic of metadata, but in a data ware-house metadata is very important. There should be one definition of a data item, which in the ideal world would have only one set of values. For example, a region code is supposed to be a three alphanumeric code, and it is in all systems except one, where it is defined as a number.
These are some of the challenges for the team responsible for loading the data into the warehouse, they are discussed further in Chapter 5, where we will apply all the necessary conversions to the data to ensure that, when this data is in the warehouse, all values are the same.
2.3.3 Oracle Database Configuration Assistant
Oracle 9i includes a number of GUI tools to assist with managing the database. A very useful one is the Oracle Database Configuration Assistant, from which you can create, delete, and modify a database or manage the templates used to create a database. This tool runs standalone (look for DBCA in the %ORACLE_HOME%/bin directory), and it does not require Oracle Enterprise Manager Server to run. In Oracle 9i it comes with three preconfigured databases, and selecting one of these will significantly reduce the time it takes to create the database; otherwise, you can create a new database.
Once you have decided which type of database is required, it must be given a name. As shown in Figure 2.4, we have called the database EASYDW.
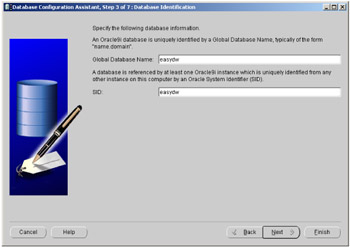
Figure 2.4: Oracle Database Configuration Assistant—naming the database.
The following steps will vary, depending on whether a preconfigured or new database is built.
Using a preconfigured database
There are three types of preconfigured database supplied with Oracle 9i:
-
Data warehouse
-
General purpose
-
Transaction processing
If you are unsure which one is suitable for your environment, the physical attributes of the database and installed components can be seen by clicking on the Show Details button, which will show the template being used.
There are only a few screens requiring input when a preconfigured database is used. One of the first is defining some of the parameters used to configure the database. An Oracle 9i database has a number of components that can be configured. In Figure 2.5 we see step 5 of seven steps from the Database Configuration Assistant, where we can define the parameters for the respective areas by clicking on the appropriate tabs, as follows:
-
Memory
-
Character sets
-
Memory used during sort operations
-
File locations for initialization and trace files
-
Archiving
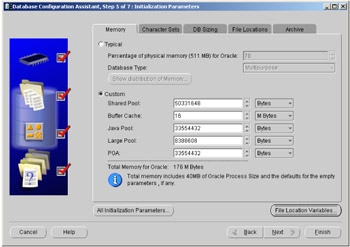
Figure 2.5: Oracle Database Configuration Assistant—initialization parameters.
The default parameters may be suitable for your environment. However, if you are building a small database to evaluate some features and the memory available to you is limited, then click on the Custom option and amend the memory being allocated. You can see the effect of your changes instantly by monitoring the Total Memory for Oracle value.
| Hint: | If a parameter is set too low, you will be advised and given an opportunity to increase its value. |
One of the buttons shown in Figure 2.4 is File Location Variables. When the database is created, the location of all the files that comprise the database—that is, the data files, control files, initialization, redo log, and archiving files—are located according to the values of these parameters that you can configure for each database, as illustrated in Figure 2.6. Also at this time you can define your own variables and use this in the definition of your database.
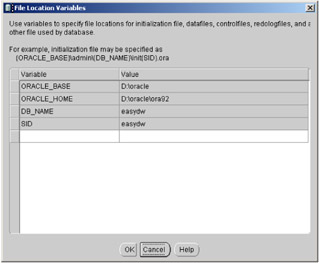
Figure 2.6: Oracle Database Configuration Assistant—file location variables.
When using one of the preconfigured databases, you cannot control the size of the database, only the location of the files, which is the screen shown in Figure 2.6. By default all of the files are placed in one directory; therefore, if you want them on different disks, now is the time to specify the new location.
All the information needed to build the database has now been defined, and you can now create the database or save this definition as a template for another time.
Using this approach your database is now ready for creation, and you can monitor its progress as it is being built. Once the build has finished, it is available for use.
Creating a new database using Oracle Enterprise Manager
Although creating a new database takes considerably longer than using one of the preconfigured ones, it does offer more flexibility in what is created, and, consequently, the steps to complete the task are different.
Once the database has been named, as shown in Figure 2.4, you will be asked which database features you require inside your customized database. In Figure 2.7 we can see that there are a number of features that we do not have to install. For example, here we have decided not to include Oracle Spatial, but we do want Oracle Data Mining.
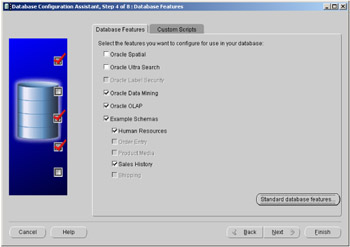
Figure 2.7: Oracle Database Configuration Assistant—database features.
| Hint: | Database creation time can be significantly reduced by only installing the features you require. |
Along with these features there are some sample schemas that can be installed, where examples are provided to help illustrate the functionality available in these features.
Next, the parameters we saw in Figure 2.5 must be defined; default values will be supplied, or the ones shown can be amended as required. When the DB Sizing tab is selected, there will also be the option to specify the database block size, which defines the lowest level of granularity and control you have concerning the allocation of space in the warehouse. It is recommended that your data warehouse be created with a large block size, such as 16,384 bytes, which means that you can store more records of the same type together in a single block, thus helping to reduce our I/O demands.
The next screen, which is shown in Figure 2.8, is where all of the files that comprise the database can be created, removed, or modified.
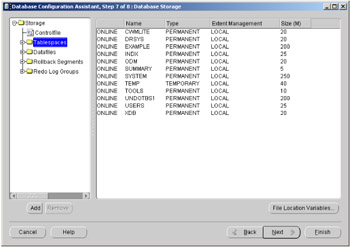
Figure 2.8: Oracle Database Configuration Assistant—database storage.
Using this screen, tablespaces can be added by clicking on the Add button. Here we can see that a new tablespace called SUMMARY has been added. Some tablespaces will automatically exist, and expanding the navigation window on the left and then selecting that item can modify the size and characteristics of these tablespaces.
Datafiles, rollback segments, and Redo Log Groups can also be defined at this stage by pressing the Add button.
The creation of the database is almost ready to begin. Now you can create the database; save this configuration as a template to use again later, and, optionally, request the creation of a SQL script so that you can create this database later.
If you request a SQL script, then a number of SQL files will be stored at a location you specify and there will be one master script, named using the database name specified in Figure 2.4, that will run all of these scripts.
If you decide to create the database now via the GUI, you can see how the creation of the database is progressing. It was mentioned earlier that during database creation a number of scripts are run against the database to provide certain functionality. Creating a database will take many minutes, so once it starts, take a short break, or do something else for a little while.
2.3.4 Which schema?
Now that we have a database, all objects defined in an Oracle database must reside inside a schema, a logical structure that describes a collection of objects. Therefore, before any tables are created, you should decide how many schemas you require. Since a data warehouse may contain only a few tables, it is probably a good idea to keep them all in one schema.
However, you may prefer to create multiple schemas by subject area, but this approach will also increase the effort required to manage the database to make the information in the tables available. This is because there will be extra tasks to perform, such as granting access to tables and defining synonyms.
| Hint: | It is very important to make this decision at the outset of the design, because the schema name plays an integral part in the naming convention used to retrieve information from the database. |
A schema object is created every time a database user is defined. A user is created via the SQL CREATE USER statement or from within Oracle Enterprise Manager by selecting User from the object list and completing the window shown in Figure 2.9.
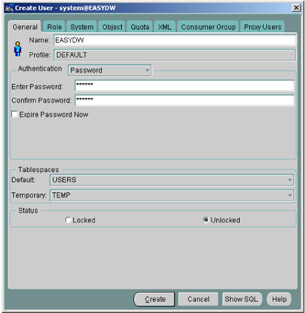
Figure 2.9: Oracle Enterprise Manager—create a user.
In our Easy Shopping Inc. example, we have decided to create a user called EASYDW. Here we can specify how the user will be authenticated, and we have selected the default mode of By Password. This means a password must be specified and used for all subsequent database access. If, in the future, this password needs to be changed, it can be done from within Oracle Enterprise Manager, using the screen shown in Figure 2.9 or via SQL.
We must also select a default area where objects created by this user, such as tables and indexes, will reside. In a well-designed database, this is not an issue, because every object will explicitly state in which tablespace it must be stored. There are a number of other options that can be specified for a user, such as privileges. It is important to set these; otherwise, you will not be able to retrieve data. As we progress through this book, you will be advised about which privileges are required when a topic is discussed.
When the user is created, a schema is automatically created with that user name. However, you will not be able to see the schema name until the first object, such as a table, is defined for that user.
The schema name is very important, because it is used to fully qualify an object in the database. For example, we could have a table called TIME in the EASYDW schema and also in our ORDERS schema. To advise the optimizer which table you wish to retrieve data from, you specify the table name as:
schema name. table name
Therefore, to retrieve all the records in our time dimension, the fully qualified table name would be:
SELECT * FROM easydw.time;
When Oracle Enterprise Manager first starts, the standard navigation window is displayed in the left frame. If you click on Schema, a list of all of the users defined in this database is displayed, as illustrated in Figure 2.10.
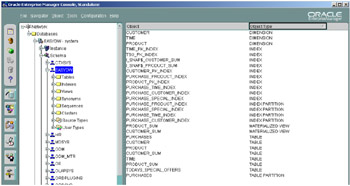
Figure 2.10: Oracle Enterprise Manager Console—schemas.
You can create as many users of the database as you require, but it is recommended that only one of them should be used for the purpose of creating objects, such as tables and indexes. Therefore, when the DBA connects as user EASYDW, all the tables and indexes created will reside here, as illustrated in Figure 2.10. In section 2.3.11, we will discuss enabling privileges for a user.
2.3.5 Data files and tablespaces
Once the database has been created, you can add your own data files and tablespaces. By default, you will find a number of data files; on a Windows NT system, they will be located in:
\<Oracle_Home>\Oradata\<database name>\
and will comprise two control files, index area, system space, rollback, and user area.
Inside these tablespaces is where objects are stored in the Oracle database, and a tablespace can have one or more data files associated with it. Therefore, the tablespace is the logical name that is used within the database schema to specify where objects must reside. An object is then actually stored in one or more data files, and part of the tablespace definition is their physical location and size.
In our Easy Shopping Inc. example, we have decided to implement the following tablespaces:
-
Dimensions—for all dimension data
-
Default area that users are assigned by default
-
Summary—for the materialized views we will create
-
Purchases_month_year for our partitioned fact table
-
Indx tablespace—for indexes
-
Temp area—for temporary space
In this example, we will create only one data file per tablespace, but, of course, you can create more if required. Also, the files shown here will be very small, and in the real world, they could be extremely large.
These tablespaces and their associated data files can be created either directly from SQL or by using the Oracle Enterprise Manager Console tool, which is part of Oracle Enterprise Manager, illustrated here in Figure 2.11.
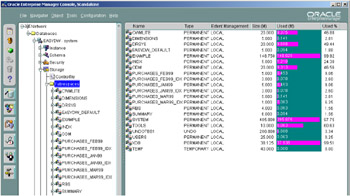
Figure 2.11: Oracle Enterprise Manager Console—tablespaces.
When you are managing a database using Oracle Enterprise Manager, it means that you no longer have to keep querying the metadata to find out the state and information on objects in your database, because the information is already available.
In Figure 2.11, we see the EASYDW database; we have then selected the database EASYDW, then storage, and then tablespaces, so in the right-hand window we see a list of tablespaces, their size, current state, and space used.
If you prefer to create your tablespace directly from SQL, then you can use the SQL*Plus utility. If you are unsure of the SQL required to perform a task, you can click on the Show SQL button in most of the GUIs, and a window appears at the bottom of the display containing the SQL. In Figure 2.12, we can see the SQL to create the dimension tablespace.
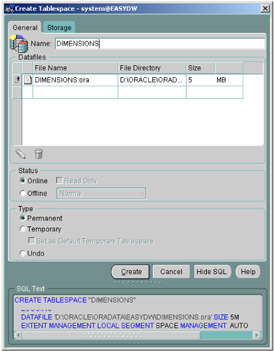
Figure 2.12: Oracle Enterprise Manager Console—dimension.
Creating a tablespace using Oracle Enterprise Manager is very easy. Simply select the database, then Storage followed by Tablespace and then right-click on the mouse and select Create. The screen shown in Figure 2.12 appears, where you specify all of the attributes of this tablespace.
The first step is to enter the name of the tablespace. It is wise to choose sensible names, because you will be using these constantly throughout the schema, and it helps if they mean something to you. For example, the tablespace called DIMENSIONS will be used to hold the dimension tables, whereas the purchases made in January are held in a tablespace called PURCHASES_JAN2002. Another favorite approach is to suffix all data areas with a "D" and indexes with an "X," to identify the type of data that is held in that tablespace.
To specify the location of the data file, click in the File Directory box to change the default location. The same approach is used to change the name of the file and its size. Click on the Storage tab to display the page where you can set the file to automatic allocation. Some designers do not like files that automatically extend; however, many do, because it means that a task will not fail because there is no space left in the database. Instead, the data file will automatically extend itself, and you can control how large those extents are. Of course, when the disk is full, autoextend will fail.
2.3.6 Creating the fact and dimension tables
Now that we have a database and the tablespaces and users are defined, we are ready to create the fact and dimension tables. The fact and dimension tables are created as if they were any ordinary tables inside the database. Therefore, all the options one would specify on a table, such as the initial and subsequent extent size, can be specified. Although we call them "fact" and "dimension" tables, they are no different from all of the other tables in the database.
When defining the fact table, carefully select the column data types, because selecting one that occupies too much space, when your fact table contains hundreds of millions of rows, will create a considerable waste of disk space.
Tables are created using the SQL CREATE TABLE command, but we will now see how to create tables quickly using Oracle Enterprise Manager. For the moment, a dimension table is defined as if it were any other table in the database. In Chapter 4, we will see how to define an actual dimension object, which will be based on the table that we created here. In fact, the dimension table created at this stage is a prerequisite for creating a dimension object.
When Oracle Enterprise Manager Console is started, if you select Object, Create, Table, Create, the Table Wizard will start, the first screen is shown in Figure 2.13.
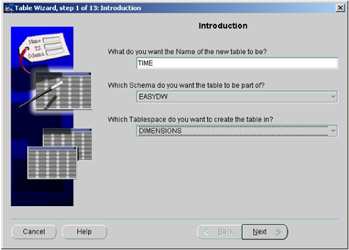
Figure 2.13: Oracle Enterprise Manager Console—Table Wizard.
In Figure 2.13, you specify the name of the table, the schema in which it will reside, and the tablespace for this table. Clicking on the Next button will display Figure 2.14, which is where you define the columns that are to appear in the table.
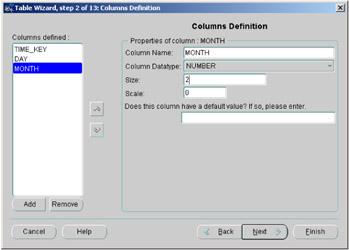
Figure 2.14: Oracle Enterprise Manager Console—table columns.
This is a really nice screen for quickly creating the table. All you have to do is enter the column name, select the data type and its size, and then press the Add button, and the column appears in the list on the left of the window. Define each column using this approach, and don't click on the Next button until you have defined all of the columns in the table.
If you do click on the Next button by mistake, you can return to this screen by clicking on the Back button. Once all of the columns in the table have been defined, the following screens will allow you to create the constraints.
2.3.7 Constraints
The job of the constraint is to ensure that all data conform to its rules, such as a value corresponds to a specified range of values via a CHECK constraint. If a primary key is defined, then this guarantees that the value is unique. A foreign key will ensure that all values correspond to one of the primary keys in another table.
Mention constraints to designers, and they will probably tell you that they do not want them in the database because they are an overhead, especially when new data is being loaded. It is highly recommended that you implement at least primary-and foreign-key constraints, especially if you wish to use the Summary Management feature described in Chapter 4. One of the interesting aspects of Summary Management is the ability to rewrite a query to use a materialized view. If you have defined constraints in your database, then it will be possible to do some complex forms of query rewrite.
In a data warehouse, there is often concern that because the data can come from many sources, it may not be as "clean" as normal data, and, therefore, constraints may fail. Although this is a valid concern, clean data should always be stored in the warehouse to ensure that accurate results are returned.
Another argument put forward for not implementing constraints is that validating every record when it is first inserted into the database imposes a considerable burden on the load operation. Therefore, it takes considerably longer than via a standard load, and if the loading window is very small, then one way to reduce the time is not to have constraints. However, the ETL stage can also be used to programmatically validate the constraint candidates, resulting in them being disabled as novalidate.
In Oracle 9i, many of these concerns can be overcome thanks to some options on the constraint:
-
ENABLE NOVALIDATE
-
DISABLE NOVALIDATE
If you are still concerned about the overhead of having constraints and worried that your data isn't clean enough to get past the constraint checks, you can use the ENABLE NOVALIDATE clause, which turns on a constraint and applies it against all new inserts and updates, but it doesn't check existing records. It is enabled immediately, but you should be aware that incorrect results could be returned if existing rows in the table have violated the constraint.
By using the ENABLE NOVALIDATE clause as illustrated in the following code segment, we can turn on the constraint SYS_C001136 without having to validate all of the data.
SQL> ALTER TABLE todays_special_offers ENABLE NOVALIDATE CONSTRAINT SYS_C001136;
If we know or want to assume that the data is clean, we can just turn on the constraint immediately without incurring any overhead. Using this approach, the database doesn't spend time validating the constraint against all the rows in the table, but it does mean that the designer had better be certain that the data is clean.
| Hint: | Use sensible constraint names, such as customer_pkey, which will mean so much more than SYS_C001136. |
Also, before data is loaded, the constraints can be quickly disabled using the DISABLE clause, as shown in the following code segment:
SQL> ALTER TABLE todays_special_offers DISABLE CONSTRAINT SYS_C001136;
At the time of writing, Oracle Enterprise Manager does not support the ENABLE/DISABLE NOVALIDATE clause; therefore, you will have to enter this manually in SQL. But you can ENABLE/DISABLE the constraint within OEM.
There is an additional clause called RELY, which is required by the Summary Management feature. This clause tells the optimizer that you can rely on the accuracy of the constraint. An example of using the RELY clause is shown in the following code segment on a constraint in the "todays_special_offers" table.
SQL> ALTER TABLE purchases MODIFY CONSTRAINT special_offer RELY;
You can check the constraints that have been defined in your database using the Schema Manager. Select the table of interest and click on the Constraints tab, as shown in Figure 2.15.
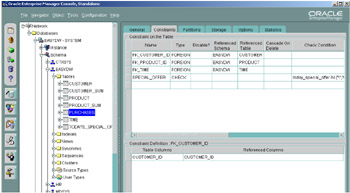
Figure 2.15: Oracle Enterprise Manager Console—constraints.
In Figure 2.16, we see how to create a primary key within the Table Wizard by clicking on the column for the key. Not every table in our data ware-house, such as the fact table, will have a primary key, but some of the columns may require that they are not null.
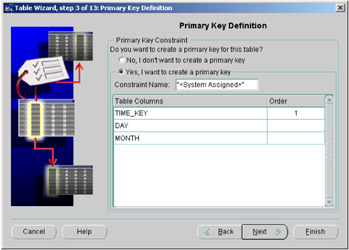
Figure 2.16: Table Wizard—specifying the primary key.
Clicking on the Next button in the Create Table Wizard displays Figure 2.17. For each column in the table, click on the Radio button to specify whether it may be null or unique, and then click on the column names in the list on the left side of the screen to move back and forth between the columns in the table.
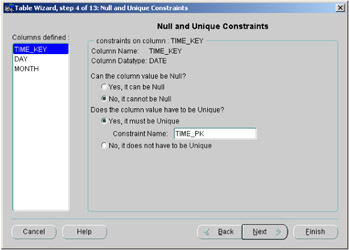
Figure 2.17: Oracle Enterprise Manager—null constraint.
Clicking on the Next button again will display Figure 2.18, where you can specify whether any columns are foreign keys.
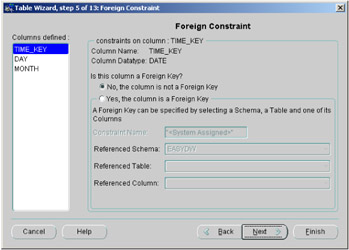
Figure 2.18: Oracle Enterprise Manager—foreign key.
On pressing the Next button, Figure 2.19 appears, where you can specify check constraints. A check constraint enables you to guarantee the values that a column will take. In our example in Figure 2.19, we have specified that the column DAY may take only the values between 1 and 31. Therefore, before a value is stored in this database, a check is automatically made by the database server to see if the column takes one of these values.
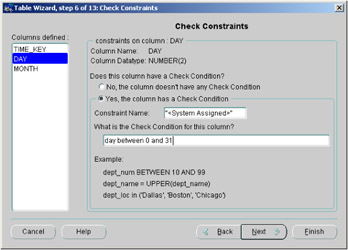
Figure 2.19: Oracle Enterprise Manager—check constraints.
An alternative to using the GUI to obtain information from Oracle 9i is to query the many system tables that are available; they provide a wealth of information about the state of your database and objects. The following code illustrates the information held about constraints in the table USER_CONSTRAINTS.
SQL> DESCRIBE user_constraints Name Null? Type ----------------------------------- -------- ------------ OWNER NOT NULL VARCHAR2(30) CONSTRAINT_NAME NOT NULL VARCHAR2(30) CONSTRAINT_TYPE VARCHAR2(1) TABLE_NAME NOT NULL VARCHAR2(30) SEARCH_CONDITION LONG R_OWNER VARCHAR2(30) R_CONSTRAINT_NAME VARCHAR2(30) DELETE_RULE VARCHAR2(9) STATUS VARCHAR2(8) DEFERRABLE VARCHAR2(14) DEFERRED VARCHAR2(9) VALIDATED VARCHAR2(13) GENERATED VARCHAR2(14) BAD VARCHAR2(3) RELY VARCHAR2(4) LAST_CHANGE DATE INDEX_OWNER VARCHAR2(30) INDEX_NAME VARCHAR2(30) INVALID VARCHAR2(7) VIEW_RELATED VARCHAR2(14)
Every constraint that you define for this schema will be recorded in this table. All of the system tables provided by Oracle will be prefixed either ALL_, USER_, or DBA_.
Therefore, to see on which constraints you have used the RELY clause, use the query shown in the following code:
SQL> SELECT constraint_name, table_name, rely FROM all_constraints WHERE OWNER = 'EASYDW'; CONSTRAINT_NAME TABLE_NAME RELY ------------------------------ ------------------------------ ---- COST_PRICE_NOT_NULL PRODUCT FK_CUSTOMER_ID PURCHASES FK_PRODUCT_ID PURCHASES FK_TIME PURCHASES NOT_NULL_CUSTOMER_ID PURCHASES NOT_NULL_PRODUCT_ID PURCHASES NOT_NULL_TIME PURCHASES PK_CUSTOMER CUSTOMER PK_PRODUCT PRODUCT PK_SPECIALS TODAYS_SPECIAL_OFFERS PK_TIME TIME PUBLIC_HOLIDAY TIME SELL_PRICE_NOT_NULL PRODUCT SHIPPING_CHARGE_NOT_NULL PRODUCT SPECIAL_OFFER PURCHASES RELY
Here we can see that the constraint SPECIAL_OFFER has the RELY clause enabled, whereas constraint SHIPPING_CHARGE_NOT_NULL does not. In Figure 2.20, we can see the constraints that have been defined on the table PURCHASES.
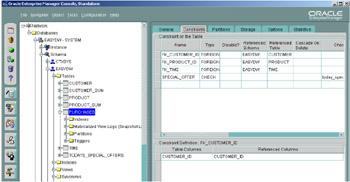
Figure 2.20: Oracle Enterprise Manager—viewing constraints.
At the time of writing, you can see in Oracle Enterprise Manager whether the constraint has been enabled or disabled, but you cannot see if it has been validated. This information can be determined by querying one of the constraint system tables, such as USER_CONSTRAINTS. To see which constraints have been enabled using the NOVALIDATE clause, use the query shown in the following code:
SQL> SELECT constraint_name, validated FROM user_constraints WHERE OWNER = 'EASYDW'; CONSTRAINT_NAME VALIDATED ------------------------------ ------------- PK_CUSTOMER VALIDATED COST_PRICE_NOT_NULL VALIDATED SELL_PRICE_NOT_NULL VALIDATED SHIPPING_CHARGE_NOT_NULL VALIDATED
The definition of the table is almost complete. We have defined the columns and the constraints that are required, and we could press the Finish button, but there are two more categories of information that the Table Wizard requests—storage and partitioning—which will be described later.
The final screen in the Create Table Wizard is shown in Figure 2.21, where we can see the SQL that will create our table. If you are happy with the table definition, then press the Finish button; otherwise, press the Back key, and amend the entry accordingly.
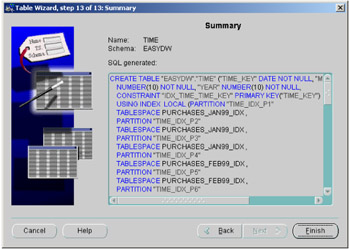
Figure 2.21: Table Wizard— final screen.
When you click on the Finish button, the table is created, and you are now ready to create the next table. Hopefully, you will agree that this is a very easy way to create a table, and, since a data warehouse probably only has a few tables, you may prefer to use this friendly approach as opposed to writing SQL commands, where you will probably make many syntax errors, which you will have to correct.
2.3.8 Indexes
A data warehouse is likely to contain a number of indexes, and, as with any other database, the designer must choose the indexes that are most suitable. Oracle offers several different types of indexes, but the ones that will be of interest to the designer are as follows:
-
B*tree index
-
Bitmapped index
-
Bitmapped join index
Indexes should be selected carefully, and the various options and reasoning behind certain choices will be described in detail in Chapter 3. Please consult this chapter, because there you will learn whether to select a global or local index and how to partition it if required.
To set the scene for this section, a bitmapped index is ideally suited to the data warehouse environment when you want to index a column that takes only a few values. For example, suppose we wanted to index the column PUBLIC_HOLIDAY, which has only two values: "Y" or "N." A bitmapped index, which is described in more detail in Chapter 3, will store this information in an extremely compact fashion; this also has additional benefits for the way that the Oracle optimizer accesses the data for typical warehouse queries.
Although indexes can easily be dropped and created, due to the time required to create them, especially on a fact table with millions of rows, careful planning at the outset of the project will ensure that you won't have to spend a lot of time creating the index. An index can be created by using either the SQL CREATE INDEX command or Oracle Enterprise Manager. (See Figure 2.22.)
Figure 2.22: Oracle Enterprise Manager—indexes.
2.3.9 Partitioning
Partitioning data is a design technique that is very important in the ware-house because it provides a means of managing large amounts of data and controlling their placement on the disks. Rather than place all of the data from a table in one tablespace, partitioning enables us to place the data in many tablespaces. To determine in which tablespace data is stored, a partition key is selected, such as time_key, illustrated in Figure 2.23.
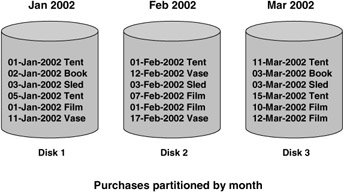
Figure 2.23: Partitioning.
In this example, we are partitioning by month, so January's data go in one partition, and February's in another, and so forth. You must select the partition key carefully, although a common one is by time. Therefore, you could partition data by month, and then each month would reside in its own tablespace. This helps result in a more manageable partition, and it also has the advantage that if you ever had to archive the data, it would be as simple as dropping a partition. Of course, don't forget to back up the partition before you drop it! This is a very quick process and doesn't invalidate any of the data that are already in the fact table.
Oracle 9i provides several different types of partitioning techniques, and, after reading the partitioning section in Chapter 3 (section 3.3), you can pick the one that is most appropriate for your data warehouse.
When a table is being created using the Table Wizard, there are five screens that allow you to range partition a table. The first of those screens is shown in Figure 2.24. If you want to use any of the other partitioning methods, such as composite, then the table will have to be partitioned manually.
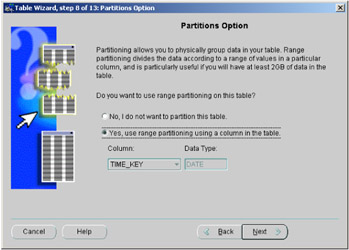
Figure 2.24: Table Wizard—partitioning screen.
The other four screens allow you to specify the partitioning criteria, illustrated in Figure 2.25, where you can easily define your range partition.
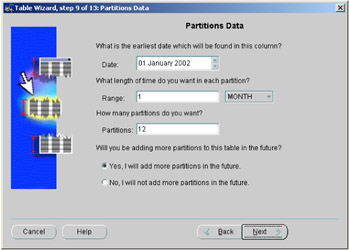
Figure 2.25: Table Wizard—partitioning criteria.
This is followed by a screen where you specify the tablespace used for each table partition, the columns to be used on the indexed partition, and the tablespace for each of those index partitions.
2.3.10 Materialized views
We have already seen that a data warehouse or data mart can hold a huge number of records in the fact table. Even if we had the fastest machine in the world and could cache some of the data warehouse in memory, the time required to respond to queries could be days—and it would certainly be minutes or hours.
To overcome this problem, warehouse designers use the technique of creating summaries, a summary being a preaggregated table of results, which Oracle calls a materialized view. For example, suppose you always query the number of purchases of today's special offer by day. Rather than compute those results every time, a materialized view is created that contains the required information. Then, whenever you make this query, instead of querying the fact table, you query the materialized view instead.
Although it partially defeats the object of a warehouse, where you make unknown queries to the database, it is fair to say that quite a few queries upon the warehouse are well known. If we can improve the response time on those queries, our users will be very grateful.
Oracle 9i includes a specific Summary Management Component, which will enable you to create materialized views rather than ordinary tables; then the optimizer will transparently rewrite your query to use the materialized view. This feature is described in detail in Chapter 4. At this stage of the design, if you can identify any queries that would lend themselves to being created as materialized views, they should be recorded now for subsequent creation. Some examples of the materialized views that we might create for our Easy Shopping Inc. example are as follows:
-
Sum of sales by product by day
-
Count of products sold by day
-
Sum of sales by week
-
Profit by product by day
The number of materialized views you expect to create will determine how many tablespaces and data files should be defined for this data ware-house.
| Hint: | It's not necessary to create a materialized view for every possible combination; this will be explained in Chapter 4. |
2.3.11 Security
One should not forget that some data in the warehouse could be very sensitive, and, therefore, for a variety of reasons, you may not wish for all of your staff to have access to this data. Oracle 9i provides various types of security that prevents users from changing the objects inside the database and accessing data.
Object privileges
Object privileges can be placed on the following types of objects:
-
PL/SQL modules
-
Queues
-
Sequences
-
Synonyms
-
Tables
-
Types
-
Views
You will most likely place security on tables and views, by stating whether a user can select, insert, and update the data, along with a number of other options. If you decide to create a number of users, then always ensure that sufficient privileges have been allocated so that everyone can read the data. This can be achieved by using either the SQL statement, GRANT SELECT ON command, or the GRANT SELECT ANY TABLE command, or these privileges can be allocated directly to the user name using Oracle Enterprise Manager, within the security section.
In Figure 2.26, we are giving the user EASYDW the rights to ALTER, INSERT, SELECT, and UPDATE the CUSTOMER table in the EASYDW schema. Simply repeat this process for all users with the tables they are allowed to access.
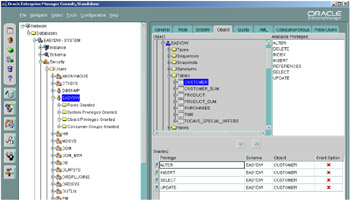
Figure 2.26: Oracle Enterprise Manager—object security.
Role
Alternatively, you could create a role. Then you assign all of the privileges to the role, and the role is assigned to the user. This is the preferred approach—especially if you create many users—because then you can create roles for the different job levels, and each user is granted one of those roles instead of assigning the privileges individually. Using the role approach, you reduce the likelihood of users accidentally being given access to data that they shouldn't have access to. It is also quicker if many users have to be defined. You can either use existing roles or create your own role using the SQL CREATE ROLE statement.
System privileges
Most of the time will be spent granting object privileges to users and maybe creating roles. However, some users will require system privileges. A system privilege is one that gives you the right to perform high-level tasks such as creating or dropping a table. Since you will not want to grant this right to many users, you shouldn't have to spend too much time giving system privileges.
The method used to define a system privilege is the same as for an object privilege, except this time system privileges are chosen. In a data warehouse, there are some specific system privileges that you may want to grant to specific users, such as CREATE DIMENSION and CREATE MATERIALIZED VIEW. In this instance, you would only be granting this privilege to users who would create dimensions and materialized views.
2.3.12 Using the PARALLEL clause
Our database is almost complete, but there is one other important feature that is available in Oracle 9i that should be mentioned, and that is the PAR-ALLEL clause. A number of the statements shown here can be executed in parallel, and the use of this technique is very important in a data warehouse because it can significantly improve statement execution time. Parallel operations are available on table scans, sorts, joins, aggregates, and some table and index operations.
If you are using a symmetric multiprocessor or a massively parallel system, then serious consideration should be given to using the PARALLEL clause. When specified, a statement, if eligible for parallel processing, will be decomposed into a number of parallel threads, and Oracle 9i will perform the job using parallel tasks and coordinate their running and the results. Therefore, all the user has to do is include the clause, and Oracle 9i does the rest.
The PARALLEL clause will expect you to specify the number of parallel processes to use. Choose this value carefully. Some testing may be required to determine the optimum value. For example, the following clause could be added to the CREATE TABLE statement for our purchases fact table:
PARALLEL (DEGREE 2)
This would mean that any operations on this table should be done using two server processes if they can be executed in parallel.
Data may also be loaded in parallel. The SQL*Loader facility, which we will discuss later, allows you to request parallel operations. Obviously, this can significantly improve the time required to store data; however, you should be aware of the possible fragmentation of your data that could occur. Therefore, it is suggested that when data is being loaded in parallel, you specify the number of parallel operations to be equivalent to the number of data files available for that tablespace. Therefore, referring to our Easy Shopping Inc. example, if we decided to specify a value of:
PARALLEL (DEGREE 3)
on our purchases table, there should be three data files defined for every tablespace.
EAN: 2147483647
Pages: 91