Chapter 6: Microsoft SQL Server 2000 Failover Clustering
Once you have installed your server cluster as described in Chapter 5, Designing Highly Available Microsoft Windows Servers, you can proceed to install and configure your SQL Server virtual servers. This chapter walks you through the planning, implementation, configuration, and administration of a Microsoft SQL Server 2000 failover cluster.
| More Info | For a basic understanding of failover clustering, including resources for each SQL Server 2000 virtual server, read Chapter 3, Making a High Availability Technology Choice. |
Planning for Failover Clustering
The most important step of installing your failover cluster is planning. Most flawed installations or problems stem from points missed during this phase of implementation. The main things you need to plan for are the network and disk resources, advanced security, service accounts, applications connecting to the cluster, and the use of any shared resources.
| On the CD | To assist you in your planning, use the document Failover_Clustering_Configuration_Worksheet.doc. |
Versions of Windows Supported
To install a SQL Server virtual server on a server cluster, you must be using one of the following: Windows 2000 Advanced Server, Windows 2000 Datacenter Server, Windows Server 2003 Enterprise Edition (32- or 64-bit), or Windows Server 2003 Datacenter Edition (32- or 64-bit). If you are implementing on a 64-bit edition, you must use the 64-bit version of SQL Server 2000. If you are installing on one of the 32-bit versions of Windows Server 2003, follow these rules:
-
If you have the SQL Server 2000 RTM or SQL Server Release A media, you must install SQL Server 2000 Service Pack 3 or later immediately after installing your SQL Server 2000 failover cluster. If you are using SQL Server 2000 Service Pack 2 or earlier (including RTM), those versions are not supported under Windows Server 2003.
-
If you are upgrading your existing Windows 2000 or Windows NT 4.0 Enterprise Edition clusters to Windows Server 2003 already configured with SQL Server 2000 failover clustering, you must install SQL Server 2000 Service Pack 3. Install the service pack to all SQL Server 2000 instances immediately prior to upgrading your operating system. If you are installing SQL Server 2000 under Windows Server 2003, you must immediately apply SQL Server 2000 Service Pack 3 or later. During the upgrade process, a message is displayed as another warning. If you have not applied the appropriate SQL Server 2000 service pack by the time you see this warning, cancel the installation process and apply it. To see these warnings, see Figures 5-1 and 5-2 in Chapter 5.
Number of SQL Server 2000 Instances per Server Cluster
As a quick reminder from Chapter 3, remember that a SQL Server 2000 failover cluster is built on top of a server cluster, and that a clustered instance of SQL Server 2000 is also known as a SQL Server virtual server because it has an associated IP address and network name in the server cluster. On a server cluster, as with a stand-alone server, you can install up to 16 clustered instances of SQL Server 2000 per server cluster. This is the same for both 32- and 64-bit versions of SQL Server. The 16-instance limitation is the tested limit; in theory you can have more. The 16 instances can be made up of 1 default instance and 15 named instances or 16 named instances. You can also combine local instances on a node and clustered instances of SQL Server, but it is not recommended. On a server cluster, you are limited only by the available resources ”namely disk, processor, networking, shared resources, and number of nodes.
| Note | Remember, you can only have one default instance per server cluster. |
Name of the SQL Server Virtual Server
If you are going to have multiple instances, each SQL Server failover cluster s name must be unique within a domain, whether it is a default or a named instance.
| Important | The SQL Server 2000 virtual server name cannot be the same as the name of any of the nodes or the name of the server cluster itself, so its behavior is not the same as that of a stand-alone server that assumes the name of its underlying server. This point is often misunderstood. |
For a server cluster with two nodes, PO8ServerA and PO8ServerB, Table 6-1 shows valid and invalid virtual_server_name\instance_name names for your SQL Server virtual servers.
| Proposed SQL Server Virtual Server Name | Valid or Not Valid |
|---|---|
| PO8 | Valid. This installs a SQL Server virtual server named PO8 on the server cluster; there is no instance name, therefore this installs a default instance. |
| PO8\INS1 | Not valid because there is already a virtual server named PO8. A virtual server can have only one instance with that name. |
| PO8a\INS1 | Valid. This would configure a second SQL Server virtual server. |
| PO8a\PO8a | Valid, but not recommended due to the probable confusion between (virtual) server name and instance name. |
| PO8a\INS2 | Not valid because there is already an instance with a virtual server name of PO8a. |
| PO8b\INS1 | Not valid because there is already a named instance of INS1 assigned to PO8a. |
| PO8b\PO8b | Valid, but again, not recommended due to the probable confusion between server and instance names. |
Number of Nodes
The number of nodes available to failover clustering is directly tied to the version of SQL Server as well as the operating system that you have chosen to install, as listed in Table 6-2.
| Operating System | Maximum Number of Nodes in a SQL Server 2000 Failover Cluster |
|---|---|
| Windows 2000 Advanced Server | 2 |
| Windows 2000 Datacenter Server, Windows Server 2003 Datacenter and Enterprise Editions (32-bit) | 4 |
| Windows Server 2003 Datacenter and Enterprise Editions (64-bit) | 8 |
Although the 32-bit versions of Windows Server 2003 Enterprise Edition and Windows Server 2003 Datacenter Edition support up to eight nodes at the operating system level, SQL Server 2000 32-bit can only support up to four nodes due to the way the installer was originally coded. SQL Server 2000 64-bit supports up to eight nodes because the installer was rewritten specifically for the 64-bit version. Some might see supporting only four nodes as a limitation in the 32-bit version of SQL Server 2000 under Windows Server 2003, but you do get two more nodes out of the box than you did with Windows 2000 Advanced Server, making Windows Server 2003 Enterprise Edition a more attractive option than Windows 2000 Datacenter Server (and there is also the additional memory supported by Windows Server 2003 Enterprise Edition).
Having more than two nodes allows you to configure an N + 1 or an N + I scenario. These scenarios are not unlike log shipping, where you have one or more nodes waiting for resources to fail to them. For example, if you have a three-node cluster, you could be hosting instances on both nodes 1 and 2, and in the event of a failover, you can set your clustered instance so that the third node will be the primary failover node for both instances. This makes balancing resources in the event of a failover much easier than it was under Windows 2000 Advanced Server, which limits you to a maximum of two nodes. The N + 1 scenario is demonstrated in Figures 6-1 and 6-2.

Figure 6-1: N + 1 prior to failover.
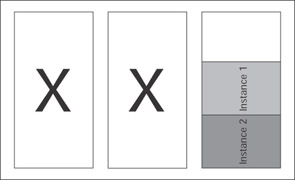
Figure 6-2: N + 1 after two node failures.
In an N + I scenario (note that it is I , and not a 1 ), you would have more than one node serving purely as failover nodes. The N + I scenario is more easily facilitated with 64-bit SQL Server 2000 because you have up to eight nodes available to you.
Disks
Configuring your disks properly is arguably the single most important aspect of failover clustering. Each clustered instance must have dedicated resources assigned to it. Two SQL Server virtual servers in the same server cluster cannot share disk resources. It is a 1:1 ratio for disks to SQL Server instance. In this case, a disk is defined as what is presented to the operating system. If you have one disk at the operating system, but you carve out multiple drive letters or partitions on it, it is considered one disk even though there are multiple drive letters. For example, you create a 50-GB logical unit (LUN) on your storage area network (SAN). When you configure it in Windows, you give it two 25-GB partitions with the letters I and J, respectively. When you install failover clustering, that LUN appears as one drive to SQL Server. This means that if you need to have more than one instance of SQL Server in a cluster, even if you configure two logical drive letters on one LUN, only one instance can use it. This is illustrated in Figure 6-3.
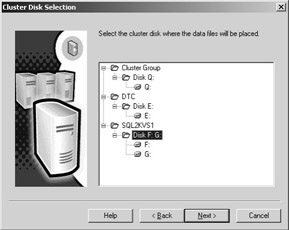
Figure 6-3: One LUN with two drive letters as seen by SQL Server Setup.
Consider this configuration example: you have two clustered instances of SQL Server, A and B. You also have five disk resources dedicated to the cluster, two of which are already used by the quorum (Q) and MS DTC (E), and drive letters A, C, and D are taken with your floppy drive, internal hard drive, and DVD-ROM drive, respectively. That leaves 18 available drive letters. Now, of the three disk resources left (F, G, and H), you need to make sure each SQL Server instance can use what it needs. Each instance needs at least one drive letter associated with it, so that takes care of drives F and G, leaving only drive H. As you can see, the number of drive letters available to you (a maximum of 26 but, realistically , probably around 22) severely limits the number of instances and drive resources that can be used by SQL Server in a clustered environment.
| More Info | See Chapter 4, Disk Configurations for High Availability for detailed information on disks and SQL Server 2000. The section Configuration Example has an example of a clustered implementation of SQL Server. |
Basic disks are supported for use with failover clustering. Mounted drives, sometimes known as mountpoints , are supported for clustering in Windows Server 2003 only, and can be used with a SQL Server 2000 failover cluster. This should help you if you run out of drive letters to configure, because the mounted drive you add to the cluster does not need to be assigned a drive letter. To achieve this, create a blank directory on a disk used by the SQL Server virtual server (such as E:\SQLMountData) and then associate the newly mounted drive with that directory in Disk Management, add the mounted drive to the resource group with SQL Server, and add the new Physical Disk clustered resource as a dependency of the drive you created the blank directory on. Do not add the mounted drive as a dependency of SQL Server.
Although this will let you use different disks in your cluster without making it a direct dependency of SQL Server, there is seemingly no way to control how the mounted drive uses the directory that is part of the mountpoint. If you create a mountpoint that references a disk used for other things and your disk becomes full, you have created additional problems for yourself.
| Warning | If you decide to use mountpoints, make sure the mounted drive is located only on the shared disk array and is never a local (that is, system) disk that only exists in one of the nodes. Only use disks on the shared drive array, as everything comprising the mountpoint would need to be available to SQL Server after the failover. For information on creating a mountpoint, see Creating a Mountpoint in Chapter 5. |
Dynamic disks provide features that basic disks do not, such as the ability to create volumes that span multiple disks ( spanned and striped volumes), and the ability to create fault-tolerant volumes (mirrored and RAID 5 volumes ). Dynamic disks are not supported natively in the operating system for clustering. If you choose to use dynamic disks, you have to use a third-party program such as Veritas Volume Manager, and the third-party vendor will be the first point of contact for any disk issues.
IP Addresses, Ports, and Network Card Usage
For each SQL Server virtual server, you need at least one dedicated IP address. During the installation process, this is bound to one of the public networks of the server cluster, which means it is, in essence, also bound to a physical network card. SQL Server 2000 supports assigning multiple IP addresses to one instance. To do this, you must have separate network cards and public networks to be able to assign another IP address. You do not want to share IP addresses on one network or network card, because that affects the availability of all SQL Server IP addresses if the network card or cluster network goes down. If you have more than one instance per server cluster, you need separate network cards for each instance to ensure availability.
During the installation of a SQL Server virtual server, as with a stand-alone instance, a port number is dynamically assigned. The first instance is usually assigned port 1433, and the rest are randomly picked during setup. Pick static port numbers prior to installing your SQL Server virtual servers and change them to the ports you want after installation. If you do not assign ports postinstallation, when the SQL Server resources fail over to another node, it might not grab the same port number because it might not be available or because a dynamic one might be assigned. For predictability alone, you should assign the port numbers . This is very important if you have machines with older versions of Microsoft Data Access Components (MDAC) that need to have the port number of SQL Server specified.
Applications and Failover Clustering
Before you implement failover clustering, check to see that the applications accessing the virtual server can handle a failover of your SQL Server instance, much as you would with any other availability technology. If your application does not behave well in a failover, it could cause other problems for your end users. For example, remember that during the failover process, SQL Server goes through a stop on one node, and the resources are started again on another node automatically. However, suppose your application persists an Open Database Connectivity (ODBC) connection to SQL Server that is dropped during the failover. Because the application developers did not take this into account in their design, the Web server needs to be restarted, which affects other applications as well.
-
Failover might not be transparent to end users. You do not have to worry about a change in server name because the SQL Server virtual server keeps the same name and IP address in a failover. However, you do need to ensure that the application can reconnect again after a failover. You have to either code a cluster-aware application (which is preferred, but not necessary) or code retry logic into your applications. SQL Server 2000 applications (such as Query Analyzer) are cluster-aware, which is why they handle failovers gracefully.
More Info For more information on coding cluster-aware applications, see Knowledge Base article 273673, INF: SQL Virtual Server Client Connections Must Be Controlled by Clients, at http://support.microsoft.com , as well as the information about the clustering API (which is part of the Platforms Software Development Kit) in Microsoft Developer Network at http://msdn.microsoft.com.
-
Make sure your application has friendly error messages to handle the failover.
-
During the startup process, any transactions that are incomplete will be rolled back. However, if the application tolerates the failover, during the switch to another server, if your application allows more transactions to be submitted, those new transactions might be lost if you do not employ some mechanism to capture them. You can do something locally at the client (such as using a cookie on a Web- based application) or use middleware (such as Microsoft BizTalk Server) to queue transactions until SQL Server is available.
-
Because the transaction log is applied during the restart of SQL Server, a long-running transaction that failed will need to be rolled back, which could take some time. If possible, ensure that your transactions are fairly small so that your recovery time will be minimal. Commit in logical units of work.
-
Set timeout values in the application effectively to close connections gracefully or perform some other appropriate response, such as a friendly message, so that the user experience is positive. The end user should never have to be concerned with what is happening on the back end.
Third-Party Applications, File Shares, Dependencies, and SQL Server 2000 Failover Clustering
Beyond adding disks as dependencies of the SQL Server resource so that SQL Server can use them, you should not make any other application or clustered resource a dependency of any of the SQL Server resources. The reason for this is simple: once you make something a dependency, the resource that you added the dependency to cannot come online if that other resource fails (for whatever reason). So if you have a perfectly working SQL Server virtual server, but a dependency that it really did not need (say an application or a file share) fails, it takes down your SQL Server. There are other reasons not to configure resources like file shares or other applications as a dependency: you could experience increased failover time due to the additional resource needing to be online, added disk I/O (in the case of a file share), driver issues, controller or network issues, SAN or disk array reconfiguration, DNS issues, bad policies, registry corruption, and permissions that could affect any cluster resource.
| Tip | If you need to make a resource dependent on a SQL resource, it would be better to use SQL Server Agent than SQL Server. Although SQL Server Agent is vital to SQL Server, if it goes down, it does not affect normal SQL Server usage for client applications. |
A good example is a piece of third-party backup software that is supposedly cluster-aware, but winds up being a generic cluster application that makes itself dependent on the disk resources of SQL Server so that it can back up your data. The problem is that the backup software has now installed a few resources in your SQL Server resource group that it is dependent on. If this is the case and you must use this software, make sure that the Do Not Affect The Group check box is selected on the Properties tab of the added third-party generic resource to ensure that if that resource fails, it does not take your SQL Server disks offline. That in turn would take your SQL Server instance offline and cause a failover. Another example is that if you are not using the SQL Server Fulltext resource, you can also clear the Do Not Affect The Group check box to ensure that if an underlying Microsoft Search problem occurs, it does not affect your SQL Server.
Hardware-Assisted Backups and SQL Server 2000 Failover Clustering
It is important to ensure that if you are employing a hardware-assisted backup, sometimes known as a snapshot/ split-mirror , the backup software is coded not only to the SQL Server 2000 Virtual Device Interface (VDI) mentioned earlier, but also when adding the mirror back into your RAID set, that the disk signatures will not be altered . A cluster depends on disk signatures remaining the same.
Service Accounts and SQL Server 2000 Failover Clustering
There are a few Windows-level accounts that need to be configured prior to installing both the server cluster and the SQL Server 2000 virtual server.
-
The account already used to configure the server cluster, as described in Chapter 5. This is a valid domain account with the proper rights on each node. This account is also used during the installation of the SQL Server virtual server.
-
At least one domain account must be created to administer the SQL Server and the SQL Server Agent. This can be two separate accounts, and does not need to be, nor should it be, a domain administrator, but a valid domain account is required. If you make the SQL administrator account(s) a domain administrator, you will be giving that user escalated privileges he or she does not need. If desired, it can be the same as the account for the server cluster, but you should not use the same account as the server cluster administrator.
-
You do not have to put the SQL Server and SQL Server Agent accounts in the Administrators group on each node for Windows 2000 Server or Windows Server 2003. If you were installing on Windows NT 4.0 Enterprise Edition you would need to.
-
The SQL service accounts are automatically assigned the rights listed in Table 6-3 during setup. If you ever need to manually re-create the login, you need to assign it these privileges.
Table 6-3: SQL Server Service Account Privileges Needed Act as part of the operating system
Bypass traverse checking
Increase quotas
Lock pages in memory
Log on as a batch job
Log on as a service
Replace a process level token
-
The service account for the Cluster Service must have the right to log in to SQL Server. If you accept the default, the account [NT Authority\System] must have login rights to SQL Server so that the SQL Server resource DLL can run the IsAlive query against SQL Server.
Warning Keep in mind that any corporate policy that requires the changing of an account s password (such as having to change it every 90 days) could affect your virtual server s availability because you need to periodically reconfigure each SQL Server 2000 virtual server, including stopping and restarting it for the change to take effect. You must take this into account when planning the amount of availability your environment needs and balancing it with corporate security.
Important You must use SQL Server Enterprise Manager if you need to change the accounts associated with the SQL Server virtual server (SQL Server or SQL Server Agent). This changes the service password on all the nodes and grants the necessary permissions to the chosen user account. If SQL Server Enterprise Manager is not used to change passwords, and the Windows-based Services tool is used to modify the underlying service instead, you might not be able to start SQL Server after a shutdown or a failover, and things such as Full-Text Search might not function properly. See Changing SQL Server Service Accounts later in this chapter; also refer to Chapter 14, Administrative Tasks to Increase Availability under Security for more information.
-
Memory
It is important to remember that how you configure your memory directly influences your failover times and your ability to have multiple instances in a cluster ( assuming at some point that all instances need to coexist on one node simultaneously ). If you are using large amounts of memory, that memory needs to be available on the failover node. So if you have a two-node cluster, each currently configured with 8 GB of memory as well as two instances of SQL Server (one with 5 GB of memory and the other with 7 GB), 7 + 5 does not equal 8; it equals 12. If they both happen to run on the same node, one will probably be able to get the memory it needs and the other will not. You need to adjust the amount of memory your instances are using so that, in a failover scenario, you do not starve one instance or possibly have it not start up after failover.
| More Info | Detailed coverage of setting memory for all types of SQL Server 2000 instances, including clustered ones, is in Chapter 14. |
Coexistence with Stand-Alone Instances and Other Versions of SQL Server
Although you can install local instances of SQL Server 2000 on each node of your server cluster, or have a local instance of Microsoft SQL Server 7.0 configured as a local (nonclustered) default instance (meaning all of your clustered instances are named instances of SQL Server 2000), this is not recommended. You cannot have any other version of SQL Server clustering (such as 6.5 or 7.0) configured and running on the same machine (and active) at the same time as a SQL Server 2000 failover cluster. Because of instance support, you can have multiple clustered instances of SQL Server 2000 in the server cluster.
Analysis Services and Failover Clustering
Microsoft SQL Server 2000 Analysis Services is not cluster-aware. This means that it cannot be configured for use in a cluster and made available in the way that SQL Server 2000 can. To make Analysis Services available, you have two options: you can use Network Load Balancing, which was discussed in Chapter 5, or you can use a server cluster and install Analysis Services as a generic resource in the server cluster. The following are some caveats regarding use of Analysis Services on a server cluster:
-
Registry replication synchronizes the memory settings for Analysis Services, which might be a problem if the two nodes in the cluster have different amounts of RAM.
-
Although it is possible to administer and query Analysis Services by using the name of the currently active node on the cluster, you should not do this. You must perform all administration and querying using the cluster server name.
-
Analysis Manager registers Analysis Services by using the machine name of the node. You must remove this server registration and then register the cluster server name.
-
Analysis Manager stores all server registrations in the registry. Registry replication synchronizes the registered servers on the two nodes of the cluster. Therefore, you must perform any new server registrations in Analysis Manager on the currently active node of the cluster.
More Info For full instructions on how to install Analysis Services in a server cluster, refer to Knowledge Base article 308023, HOW TO: Cluster SQL Server 2000 Analysis Services in Windows 2000, which you will find at http://support.microsoft.com .
SQL Mail and Failover Clustering
If you intend to use SQL Mail with a SQL Server 2000 virtual server, be aware that it might or might not work. The underlying MAPI protocol that is used is not cluster- aware. You need to configure each node with the same MAPI profile, such as the Microsoft Outlook profile. If you change the password or account used for your SQL Server virtual server, you also need to update the Mail profile in the Control Panel on each node. With the 64-bit edition of SQL Server 2000, SQL Mail is not available at all. You can use SQL Server Agent Mail remotely configured by SQL Server Enterprise Manager as long as the client connecting uses SQL Server 2000 Service Pack 3 or later.
| More Info | For more information on SQL Mail and failover clustering, refer to Knowledge Base articles 298723, BUG: SQL Mail Not Fully Supported for Use in Conjunction with Cluster Virtual SQL Servers, and 263556, INF: How to Configure SQL Mail, at http://support.microsoft.com . For more information on configuring mail capabilities with 64-bit SQL Server 2000, see the section SQL Mail under the topic Differences Between 64-bit and 32-bit Releases (64-bit) in the 64-bit edition of SQL Server Books Online. |
Exchange and SQL Server on the Same Cluster
You should not place Microsoft Exchange Server and SQL Server on the same cluster. First and foremost, both are mission-critical applications. You do not want to have one starve the resources of the other, especially under Windows 2000 Advanced Server. There are also some potential conflicts in things like memory models and versions of MDAC or versions of the Microsoft Search functionality. If you choose to implement both on the same server cluster and encounter problems, Microsoft Product Support Services (PSS) will assist you to the best of their abilities , but their recommendation might be to remove one of them from the server cluster if the issue cannot be resolved. It would be best to deploy separate clusters for SQL Server and Exchange.
| Tip | If both SQL Server and Exchange must exist on the same cluster, install Exchange first and then install SQL Server 2000. There are certain shared resources, such as the underlying Microsoft Search service. Modifications to one application could negatively affect the other. |
Cluster Group Configuration for Failover Clustering
Your SQL Server 2000 failover cluster should resemble the following when it is configured:
-
The Cluster Group resource group contains the Cluster IP address, cluster name, and quorum disk in one group.
-
Microsoft Distributed Transaction Coordinator (MS DTC) should be configured as described in Chapter 5. This is version-dependent.
-
Each SQL Server virtual server needs its own dedicated group, which will contain the SQL Server IP Address, SQL Server Network Name, SQL Server, SQL Server Agent, and SQL Server Fulltext resources. Two instances cannot share the same group. See Figure 6-4 to see the resources that exist after a base SQL Server virtual server installation.
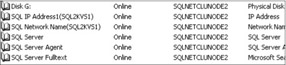
Figure 6-4: Resource configuration in Cluster Administrator.
EAN: 2147483647
Pages: 137