Topological Architecture
Topological architecture is the combined design of networks, systems, platforms, and storage architectures. Some call this area physical architecture ; however, I personally feel that the term topological infers topology, and WebSphere performance scalability is very much about topology selection.
WebSphere performance is just as much about how your physical components interact. If you treat a WebSphere platform as an onion and you peel the layers away, when you get to the innermost components you're looking at a distributed environment. Everything in the environment is object-oriented and, therefore, is indirectly (or directly, depending on how you perceive the analogy!) distributed.
Even in a single node system, components talk to one another via a distributed mechanism. In most cases, this communication takes place via EJBs over RMI/RMI-IIOP or legacy Java components such as CORBA objects and the like.
Either way you look at it, stuff is distributed. There are IBM extensions in WebSphere that provide the capability for EJBs to communicate over a quasilocal interface instead of remotely. This capability is known as Call-by-Reference, and you can set this during application deployment in the Application Assembly Tool (AAT). The default EJB specification is to call EJBs via a mechanism known as Call-by-Value .
| Note | In J2EE 1.3, the EJB 2.0 specification provides for a local interface that allows EJB clients to communicate to EJBs via a "local" interface instead of via a remote network call. This can help decrease overheads associated with having to call EJBs internal to EJB containers by not having to invoke a network call. |
For this reason, how you plug your physical components together to form your topological architecture is very important.
WebSphere Building Block Rules
The WebSphere topology that you select should roughly follow a capacity modeling equation that you can apply over and over again. I tried to stay away from using the clich of portraying it as blocks of LEGOs, but this analogy truly fits the bill in this example!
When you play (or played ) with LEGOs, you always knew that to build something, you have to choose among fixed, defined pieces. In my experience, the same idea can be applied to designing and building WebSphere platforms. You should select a basic model that's based on architectural design driven by capacity modeling and analysis, which will enable you to easily scale and grow your WebSphere application environment in any way needed, without a major redesign of your application.
For example, one of my personal building block rules is to always roll out components (i.e., CPU, memory, disks, I/O cards, etc.) in even numbers. I've found that, when I initially build the basic components of my WebSphere platform, by rolling everything out in even numbers I'm inherently introducing redundancy in everything I do.
Another rule I follow for WebSphere servers is this: For mission-critical systems, I always roll out WebSphere servers in combinations of three or more (to the extent to which there are obvious cost benefits). I then factor into my design a rule that states that any two servers in a three-way WebSphere server cluster must be able to handle the full load of the application utilization, with no more than 60 percent load any one host. This promotes a WebSphere platform that can run with a downed server through either a server crash or a scheduled outage period during nonpeak times. Two servers provide redundancy but not always performance under a 50 percent operational condition (i.e., where one server has crashed).
Example Building Block
To put this concept of "building blocks" into context, for medium- sized WebSphere environments an example of a WebSphere topological building block model would be to use Sun V880 servers. As I discussed in the previous chapter, Sun V880 servers provide the ability to take eight CPUs and 64GB of memory.
You may decide that, based on an application architecture in which there will be four deployed Enterprise Archive Resource (EAR) files (used to contain and structure J2EE applications) on each server, each WebSphere J2EE application Java server would require between 512MB and 1.5GB of Java heap memory. As a rough guide, each Java JVM should have ”in the majority of cases ”at least one dedicated CPU. This helps to cater for garbage collection, as garbage collection effectively stops more than 98 percent of requests from being serviced by the JVM while the garbage collection process is taking place.
| Note | Garbage collection is the term used to describe a Java JVM regularly going through its heap (allocated memory) and cleaning out unused objects and space. During this time, the JVM appears almost frozen to the servicing applications that are operating within it. Therefore, there's a delicate tuning process that needs to take place to ensure that the JVM doesn't spend its entire life garbage collecting. |
From a redundancy point of view, you'll look to clone two of the J2EE application servers for WebSphere version 4 or use cells and nodes for WebSphere version 5. More than one physical WebSphere server will also be included. Based on these requirements, you can state the following basic requirements:
-
Each physical server will require at least six CPUs (one for each JVM plus operating system overheads, or you can assume that the two uncloned/ non- cell -configured JVMs are low weight).
-
Each physical server will require at least 7GB (4 —S1.5GB and 2 —512MB) of memory for the JVMs plus operating system overhead (3GB), totaling approximately 10GB of memory.
To achieve redundancy across multiple servers, you will require a second Sun V880 server of equal capacity, given that you'll want to provide 100 percent processing ability during a node failure. The basic building block, therefore (excluding disk, network, and other peripherals at this stage), is a Sun V880 server with six CPUs and 10GB of memory. Each time you want to add in new capacity ”given that the V880 is only an eight-CPU chassis ”you would look to deploy another server (block) of equal capacity.
Essentially what I'm saying here is that you should select your topological architecture before anything else, and when you've confirmed it, lock it in. Changing your topological architecture midstream generally is a complex and expensive task because you may need to alter the application architecture and there's a potential for several high-risk outages for hardware upgrades.
Considerations for Scalability and Performance
In the land of J2EE, and specifically with WebSphere-based implementations , two areas of your overall application infrastructure determine its ability to scale and perform. The first is the application design itself, which I cover later in Chapter 10. The second is the way that the physical layers are designed and constructed .
As I've touched on in earlier sections, WebSphere can scale both horizontally and vertically to achieve performance and scalability. In the upcoming sections, you're going to look at some key topological architectures in detail and examine the pros and cons of each. To summarize the various approaches, this section presents some considerations before you start planning the infrastructure components of your WebSphere environment.
JVM Memory Characteristics
The JVM is the central component in any Java-based application. The JVM is the virtual machine that the Java application threads operate within, and it provides the bytecode interpretation for your nominated platform. Over the years , JVMs have evolved somewhat in terms of their performance. Back in J2EE 1.1, JVM performance, while good, suffered all sorts of weird anomalies, most of which have been addressed in subsequent versions.
One of the main aspects of a JVM's role involves managing the memory space allocated to the Java applications operating within it. The memory allocated to the JVM at JVM bootstrap time is known as the heap . At the time the heap is allocated during JVM initialization, there are two primary settings used to set memory requirements: the initial heap and the maximum heap. The initial heap is the starting point for allocation, and the maximum heap is the maximum amount of memory space that the JVM can or will reference during its lifetime.
Java is based around objects, and these objects need to be resident in memory until their use has expired . One of the selling points of Java is that it manages the memory allocation and deallocation for you, and for this reason you need to tune the JVM carefully so that it knows what it can and can't reference.
Those of you who have used languages such as C and C++ know that programming in those languages involves the use of the malloc() library to obtain memory for your runtime. C and C++ runtime compilers don't automanage the memory for you and, as such, it is up to you to manage the memory space. Therefore, in Java you need to plan around the area of memory allocation prior to sizing a system.
I've noted two Java JVM settings that are specific to memory usage. There are, in fact, many more. Most of them you'll never need to use, but from time to time, and on large environments, you may find a need to use them. It's important to note at this stage that there are several JVM vendors on the market. IBM, Sun, and BEA are just three vendors that produce their own JVM implementations. Each of these JVMs has the majority of the primary settings available to it, but if you do have a need to use a JVM other than the one that comes with WebSphere, study the release notes carefully. A setting on an IBM JVM may have an adverse affect on a BEA JRockit JVM.
Because the JVM manages the memory allocation and object heap space for your J2EE and Java applications, it needs to clean itself and its workspace periodically. How frequently this occurs is dependant on how busy your application is and how much memory you've allocated to it.
I've referred to garbage collection many times during the book so far, but now I'll cover it in more detail. Essentially, garbage collection is the JVM's way of cleaning out unused and unwanted objects from its heap. Quite often, applications don't clean up and dereference objects from use. This includes items such as arrays and vector lists, which are used frequently by applications but may not always be removed after use. Garbage collection takes care of this.
However, there is a downside to this paradigm of software development. As the JVM is providing the runtime for your applications as well as garbage collection for your applications' unused objects, there is a clash . When garbage collection occurs, the JVM is almost 100 percent dedicated to the task of garbage collection. This causes applications to mostly freeze during this housecleaning exercise. Excessive (i.e., constant) garbage collection can cause an application to appear to not respond. Therefore, it's important to size and tune your JVM correctly.
Here are some JVM rules of thumb to follow:
-
Because of 32-bit limitations (or complications ”whichever way you look at it), don't allocate more than 2GB of heap space per JVM. Unless your JVM is one of the new 64-bit JVMs that are soon to be commonplace, trying to use more than 2GB of JVM space can cause problems. This is why you may want to look at using multiple JVMs to run multiple instances of an application (I discuss this later in the chapter).
-
Keep to the rule of initially setting your JVM maximum heap size to half of the physical amount of memory or half the physical amount of system memory allocated to the JVM's purpose.
-
Keep the minimum or initial heap size to half of the maximum heap size until tuning tells you otherwise .
-
Avoid (like the plague) allocating more memory to your JVM (or more JVMs if you're running multiple instances on the same server) than you have physical memory. Don't let the JVM eat into swapping and memory paging danger areas.
-
Be aware that large heap sizes will require longer garbage collection cycle times, so, if you believe you need large amounts of memory allocated to your JVM, either tune the JVM (see next the section for more information) or allocate a smaller amount of heap and look into using multiple JVMs.
-
If, after testing, you find that the JVM is garbage collecting more than 10 to 15 percent of the time, there is something incorrect with your JVM heap settings.
Garbage Collection Monitoring
Checking for how much time your JVM spends garbage collecting is a fairly simple task. Within your WebSphere console, or manually through wscp, XMLConfig, or wsadmin, add in the bootstrap property to your JVM startup parameters of -verbosegc and restart the JVM. If you then monitor the log file associated with the application server that you've modified with the -verbosegc parameter, you'll see entries starting with "GC" appear when garbage collection occurs.
With the current JVM versions available, the current method of garbage collection is typically conducted in a multithreaded fashion; however, when garbage collection occurs, the JVM attempts to defragment the heap and compacts it. This compacting or defragging is a single-threaded operation and tends to be the main cause for application freezing during garbage collection. This is why you'll generally want to avoid long periods of garbage collection or frequent garbage collection.
Figure 5-3 shows an example of what garbage collection looks like on a system that is exhibiting memory leaks. The ever-growing heap memory usage is a giveaway of this situation or of a system that has had its initial heap set too low. The time period is 5 minutes, with a garbage collection occurring about once every 30 seconds or so.
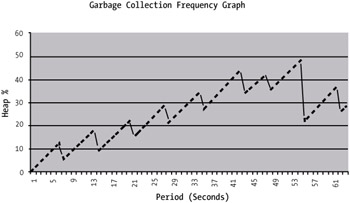
Figure 5-3: An example garbage collection monitoring graph
I discuss tuning in more detail during later chapters, but it's worth noting here that the output of this graph suggests that I'm able to increase the initial heap size a little. This won't necessarily decrease the frequency of garbage collection, but it will reduce the time that garbage collection takes.
This type of profiling and tuning exercise should be a normal part of your capacity management program. In Chapter 13, you'll look at other ways to monitor the JVM and its operational characteristics, plus you'll learn about ways to tune it.
Other JVM Memory Issues to Consider
Although I've discussed garbage collection, I haven't touched on what can cause it. Two key factors can drive a JVM to be a painful part of your architecture: memory leaks and Java object overuse.
Probably the nastiest of all Java-based problems is memory leakage. Although Java insulates developers from a memory allocation and deallocation, there can still be problems within your application code that cause certain types of objects to build up over time and not get swept up in garbage collection. Hashtables and vector lists are common causes of memory leaks, as they can continue to exist without application references to them. Over time, they'll build up and the available heap will become less and less, yet the JVM will try more and more frequently to garbage collect as its available heap becomes exhausted.
The most obvious sign of a memory leak is a Java "out of memory exception." If you see one of these, it's a sure sign that either you've grossly underspecified your Java JVM heap settings or you have memory leaks. You'll look at how to identify these exceptions and fix them in Chapter 13.
Another memory- related problem is the overuse of Java objects. That is, instead of using pooled or cached instances of the specific object, your application instantiates a completely new instance of the object on each and every request.
| Caution | Although the approach of pooling Java objects will help with Java heap management, it does have the potential to introduce other problems that can lead to poor performance and issues associated with threading. Be sure to design your application architecture carefully if you're using manual Java object pooling (i.e., you're not letting the WebSphere containers take care of it). |
Again, you'll look at this problem and how to identify it in more detail in later chapters. The obvious sign of this problem occurring is that the time to garbage collect is taking longer on each request. A quick remedy to this problem is to run multiple JVMs (which I discuss later in this chapter), but this is a temporary solution and it does not address the problem's root cause.
JVM Threading Characteristics
When you're capacity planning your WebSphere topological architecture (your server platform), you need to consider the number of CPUs you'll require for your application to perform at adequate levels. There are a number of rules of thumb relating to the allocation of Java JVMs against CPUs that you can follow but, once again, nothing beats good solid modeling of your application against your chosen hardware platform.
The first rule of thumb is this: For every CPU you have within a system, my general recommendation is that you allocate 1.5GB of memory per JVM (for JDK 1.2/1.3) and 2GB to 2.5GB of memory per JVM (for JDK 1.4). For each medium-to high-operating JVM, you should allocate a single CPU.
In Chapter 4 you looked at sizing your application environment based on the perceived number of threads operating concurrently within your J2EE application. At a higher level, you can use the preceding guide for memory per JVM or work within the guideline of one CPU per JVM in a medium-sized environment or two CPUs per JVM in a larger production environment in which the JVM is heavily used. Therefore, for an application server that has four applications, two of which are heavy-operating JVMs and the other two of which are low-operating JVMs, you should look for a system with 6GB of memory and three CPUs.
Each Java JVM that's a medium-to high-operating JVM will undoubtedly conduct a fair amount of garbage collection. Therefore, you don't want other JVMs affected by the cleanup processes of another application.
| Caution | These recommendations in this section are intended as general guides and rules of thumb. Your mileage may vary with these ratios. It goes to prove that you must perform capacity modeling, but use these recommendations as a starting point. |
You'll recall that in Chapter 4 you looked at the ratio of threads per JVM. This varies on how your deployed application is architected, but it's an important part of sizing your environment. At the end of the day, the number of Java JVM threads compared to the number of operating system or Kernel threads is going to vary based on the particular vendor's JVM you use as well as your chosen operating system. Recent operating system versions come with more advanced thread libraries that marry better with the platform-specific Java JVM.
There are a number of ways to monitor and tune threads within your JVM and the application itself. You'll also look at this in Chapter 13.
Local Network Environment
I touched on network architectures in the previous chapter and which ones are better suited to WebSphere platforms. Although there's no hard-and-fast rule here for the right network architecture for WebSphere (how long is a piece of string?), there are a few considerations that you should either include as standard in your architecture or use to build off of.
You can break a network within a WebSphere environment into three main categories, as shown in Figure 5-4.
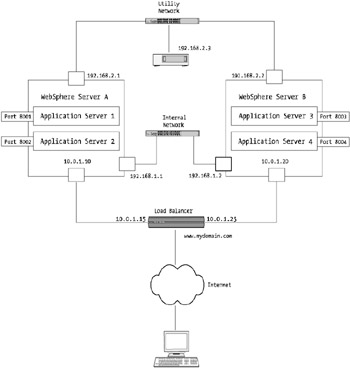
Figure 5-4: Major network types within a WebSphere topological architecture
First, you have the external network components. These network links and interfaces typically handle the traffic to areas outside the application space. These include, for example, the link through which customer traffic traverses. This network is depicted in Figure 5-4 as the 10.0.1. x network.
The second network type is the internal private network "mesh." This network is the 192.168.1. x network depicted in Figure 5-4. This network is for internal WebSphere-to-WebSphere communications. Depending on your physical architecture, this may or may not be the network in which traffic from your Web servers to your application servers traverses ”the Web servers may be located at a physical distance from the WebSphere application servers. Typically, however, this internal private network would be used for WebSphere nodes to be able to communicate to one another (e.g., for workload management, JNDI tree spanning, database queries to database servers, etc.).
The third type of network is the utility network, depicted in the diagram as the 192.168.2. x network. This network should be used for all backup (e.g., tape backup) and administrative functions. The driver behind this network is so that backups and administration/operational functions don't interfere with the user - facing operations and vice versa. Consider the situation in which you may be receiving a denial of service (DoS) attack and your application is under load from the excessive traffic. If your network is saturated , then it's going to be difficult to administer the WebSphere server components. Therefore, you should always consider this third network type as a requirement.
| Note | You could do away with the third network interface and look at serial-based communications. These are out-of- band and are not subject, in most cases, to typical DoS attacks and other forms of network storms. The only downside to this approach is that graphical tools aren't available, and neither is the ability to easily transfer files back and forth and use the medium for backups. |
I'd also always recommend at least a backup route to be shared between the customer-or user-facing network requests and the internal private network traffic. Intelligent routing and/or switching can make this a trivial exercise to set up and configure.
A note on Gigabit Ethernet versus Fast Ethernet: I've been witness to some odd discussions over the past 12 months or so, in which Gigabit was dismissed simply because it was Gigabit. Comments such as "We don't need 1000Mb/s" were common. My qualm with this is that Gigabit Ethernet is only fractionally more expensive than Fast Ethernet. For an extra 10 to 15 percent of the cost of hardware and switches, you get an extra (theoretical) 10 times the throughput performance! My recommendation is that if you have the infrastructure in place, or you have spare funds, go for Gigabit. Simple things such as file transfers and WebSphere clustering will be noticeably faster and will result in a better, higher performing application platform.
EAN: 2147483647
Pages: 111
- Success Story #1 Lockheed Martin Creating a New Legacy
- Seeing Services Through Your Customers Eyes-Becoming a customer-centered organization
- Success Story #3 Fort Wayne, Indiana From 0 to 60 in nothing flat
- Success Story #4 Stanford Hospital and Clinics At the forefront of the quality revolution
- Designing World-Class Services (Design for Lean Six Sigma)