Section 9.1. Laying Out the Repository
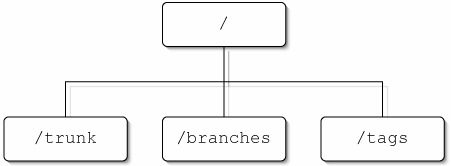
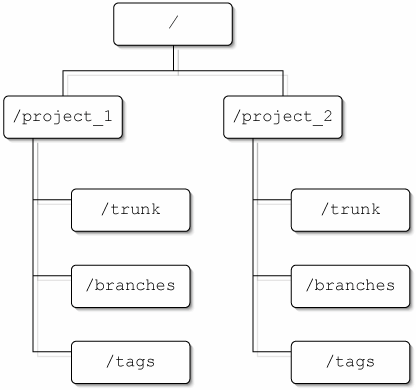
9.1. Laying Out the RepositorySubversion gives you a lot of options for laying out a repositoryor more to the point, it puts up very few roadblocks when you are laying out your repository. Your layout options are basically as unlimited as your options when laying out a regular filesystem. Additionally, because branches and tags are handled as copies, you are free to organize your repository layout to reflect the types of branches and tags that you expect to make (for example, a releases directory for release tags). 9.1.1. The Two Basic LayoutsThere are two basic Subversion layouts. If you are putting together a simple Subversion repository, or don't know exactly what the project structure and workflow is going to look like, your best bet may be to just use one of these simple repository layouts. Of course, as the project grows, you can always move things around to improve the layout at a later date. Monolithic LayoutThe first layout is the basic monolithic project layout. In this layout, you have a single project in each repository, with a top-level directory for the trunk, as well as directories for branches and tags (see Figure 9.1). This is the better layout to choose if you have multiple projects that are unrelated (or only loosely related), in which case you can place each project in its own repository with a monolithic layout structure. It's also the obvious choice if you are only tracking a single project. Figure 9.1. A simple monolithic repository layout. The main project trunk will go into the trunk directory, whereas branches and tags will be copied into the branches and tags directories, respectively. This allows a user to easily check out just the trunk directory, and use svn cp with URLs to create branches and tags. Then, when the user wants to work on a branch (or use a tag), it is easy to use svn switch to move the branch in to the checked out working copy of TRunk. By keeping multiple projects separated in their own monolithically organized repositories, you maintain the ability to relocate or back up individual repositories. That would, for example, allow you to maintain two heavily accessed repositories on different servers, or to archive the repository for a cancelled project off onto an offline storage medium to free up space on your active servers. Individual projects in separate projects also allow those projects to have their own revision numbers. If a modification is committed to project foo, project bar's head revision won't increase by one. If your projects are closely related, or are likely to share a lot of code, having each project in its own repository can be constraining. You lose the ability to copy or merge source from one project to another (while maintaining the history of the file in both projects), and you lose the ability to branch or tag both projects together. Also, because each project has its own independent revision numbers, it is hard to compare the state of two projects at an arbitrary point. However, if the projects are not closely related, but do reference each other, externals may allow you to share some commonalities between repositories without sacrificing the advantages of separate repositories. Multiproject LayoutThe second basic layout scheme is better for projects with lots of closely connected projects. In this scheme, instead of putting each project in a separate repository, with trunk, branches, and tags directories at the top level of the repository, you will create a top-level directory for each project in the repository. Then, at the top level of each project directory, you will put trunk, branches, and tags directories specific to that project, as in Figure 9.2. Figure 9.2. A repository layout with multiple projects. With this layout, you can easily copy source from between projects or create tags and branches that encompass multiple projects. All of the projects will also share revision numbers, so you always know what state other projects were in at a given revision number for the project you are working on. Of course, you lose the separation of multiple repositories and gain little advantage if the projects are not closely related. If two projects are unrelated or only reference each other with no (or at least very little) possibility that code will be copied from one to the other, you may be better off with a monolithic layout. 9.1.2. Organizing the TrunkThe trunk is the main branch of a project. As far as Subversion is concerned, it is no different from any other directory, because Subversion has no concept of special directories. Conceptually, though, it is the directory where the primary version of the project resides. Branches and tags are usually created from a revision of the trunk, and work done on a branch is often merged back into the trunk when they are complete. The trunk is usually stored in a directory named trunk, but could be named something else (like main_branch) if there were a compelling reason to do so. Generally, there is either a single trunk for the entire repository, or individual trunks for each project. This allows each project to have a clear place for the most current new development (also called the head development). Although most projects have only a single trunk, in theory you could have multiple "trunks" for a single project, but you should carefully consider the way you will be using the repository first. In most cases, you will find that things are better organized as multiple projects, or as branches of a project. For instance, if you maintain separate development paths for a consumer version and professional version (or versions for different platforms), the different development paths might be cleaner if they were different projects in the same repository. Similarly, if you have multiple versions of the same project, those might be more cleanly handled as branches, instead of multiple trunk directories. In many cases, the trunk will be the only part of the repository that users will check out into their working copy (using svn switch to get at the other parts). This means that you need to be sure that your trunk is a complete entity, containing all of the parts of the repository necessary for working with the project (if the repository is split into a scheme with one trunk for each project, it's acceptableand usually desireableto make each product so it needs to be checked out separately). What you want to avoid, though, is source that uses a relative path that points to parts of the repository outside the current project's trunk directory. 9.1.3. Organizing BranchesBranches are just that, branches of the main path of development that may or may not be merged back in at a later point. Typically, they are used for working on sections of development that may break the main trunk, or that may be tangential to the main trunk of development. Often, branches are long-running, but they may also be used for quick forays that only take a revision or two before they're merged back into the trunk and deleted. Branches are usually stored in a directory named branches, under a descriptive name that describes what part of the trunk the branch was created from, as well as purpose of the branch. For example, if your project has a graphics engine that is stored in a directory named graphics_engine and you want to add real-time processing to it, you might create a branch named graphics_engine-real_time_proc. The ease with which branches are created means that you can very easily end up with a lot of them. Furthermore, it is likely that many (if not most) of the branches will end up with semi-cryptic names that mean little to anyone except their creator. End result: The branches directory quickly becomes cluttered with a huge number of hard-to-sort-through branches. This "branch clutter" can easily get out of hand in a long-running project, and although it's unlikely to be a major drain on anyone's productivity, it can lead to developer frustration (which tends to result in less reliance on branches,) as well as improper use of branches (which will make the repository more difficult to deal with, as well as making its history harder to track properly). One possible solution to the problem is to make sure branches are deleted as soon as they are no longer used. This can help to keep the clutter to a minimum, but it can also make older branches harder to find. It also doesn't help the problem much if most of your branches are long-running branches, where deletion makes no sense. A better solution is to keep the repository organized in a sane manner that makes branches easy to find and list. The best structure for organizing branches depends a lot on your project's workflow, and the circumstances under which branches are typically generated. There are a wide number of uses under which developers will typically create branches, and it usually helps if you organize those branches categorically. Sometimes, you will want to categorize with subdirectories under your branches directory (or directories). For other branches, it may make more sense to place specific branch directories at the top level of the tree. The following examples illustrate some (but by no stretch all) of the possible ways you might organize different types of branches.
In short, you are limited only by your imagination and desire to create a level of organization that fits your development teams (which for many projects may indeed mean a monolithic branches directory). If you would like more ideas for how you can organize your branches, check out the development process case studies in Chapter 14, "Case Studies in Development Processes." 9.1.4. Organizing TagsIn contrast to branches, which represent forks in the development line, tags are static benchmarks that preserve the state of the repository (or a particular working copy) at a specific point in time, for easy reference later. Even though tags are just copies, the same as branches, they never change over time like branches do (if they do change, they become a branch instead, by definition). The closest thing to change that a tag should see is if an existing tag is removed and replaced by a new tag of the same name, such as if a tag named current_release is used to always represent the current release of a project. When a new release of the project is made current, the old tag would be removed, and a new tag named current_release would be created (you could achieve the same effect by using a merge into the tag, but removing and recopying is usually easier, less likely to cause problems, and uses less disk space). Keeping tags organized suffers from similar problems as the organization of branches. In general, if you have a lot of tags, it will quickly become difficult to wade through the tags to find the one you want if everything is stored in a monolithic tags directory. Instead, you are usually better off categorizing your tags into separate directories. In many cases, it can even be advantageous to move some of the tag-categorizing directories out of the tags directory and promote them to the top level of your repository. For example, if you tag your releases, it may be useful to create a top-level releases directory, where all of the release tags are created, such as in the layout shown in Figure 9.4. Figure 9.4. A releases directory can make project releases easy to find.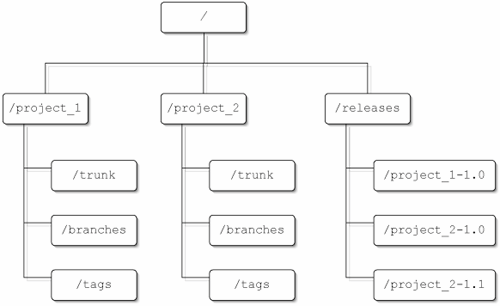 Top-level special tag directories can be especially useful if your repository has individual tags directories for each project. A top-level current directory, for instance, could store the most current release of each project. Then, individual developers would be able to easily check out the full project suite contained within the release, into a single working copy, while maintaining the benefits of splitting different projects into individual subdirectories with their own branches and tags. Remember, with Subversion's "cheap copies," tags take up essentially zero space in your repository, so there is no reason not to take advantage of them whenever possible.
|
EAN: N/A
Pages: 132