Using Analysis Services to Deliver Real-Time Data
| | ||
| | ||
| | ||
In this book, weve encouraged an architecture that uses Analysis Services as the primary query engine for your DW/BI system. The advantages of user -oriented metadata, support for complex analytic expressions, and generally excellent query performance are appealing to consumers of real-time data, too. Many DW/BI users also need to access purely operational data and would like the same rich tools in the real-time environment.
Microsoft provides some interesting functionality that you can use to deliver real-time data in Analysis Services. The two most important features are:
-
The ability to build an Analysis Services database directly from a transactional (normalized) data structure, without first putting that data in the data warehouse database. You may have seen this functionality described as the Unified Dimensional Model, or UDM. The UDM simply refers to the Analysis Services database definition metadata.
-
The ability to populate an Analysis Services database automatically, as data flows into the relational source.
Building Cubes from Normalized Data
Just for kicks, start up BI Studio and run the Analysis Services cube designer wizard against the AdventureWorks database, rather than the AdventureWorksDW or MDWT_AdventureWorksDW databases. As you will see, you can build a cube against a normalized database, and the design works surprisingly well.
You could create an Analysis Services layer atop each of your normalized transaction databases and always use Analysis Services for your query engine. The most obvious objection to this approachthat the transaction database has data quality issues that will gum up your cubeis partially addressed by a number of features in Analysis Services that will help fix up those data quality issues. Weve not talked about these features in this book because we want you to build a clean, conformed, dimensional relational data warehouse database, and define simpler cubes on top of that structure.
The reason we advocate what may seem a more complex architecture is that the cube-on-transaction-database approach works only when the underlying transaction database is really clean, already integrated, and contains all the data you need. In other words, when the underlying database is like AdventureWorks.
The ability to create an Analysis Services database against a normalized source database will appeal to small organizations and departments who dont have technical resources. Perhaps the most valuable use of this feature is in packaged transaction systems. The software development companies that write operational systems could do their customers a real service by shipping an Analysis Services database with their software. In this case, wed have to hope that the product development team could (and would) address the worst data quality issues revealed by allowing ad hoc access in a rich environment like Analysis Services.
| Note | To date, most existing ERP software companies havent done a good job of addressing data quality and enterprise data integration issues. But hope is cheap. |
Proactive Caching
One of the biggest challenges of processing cubes in real time is knowing when the system has received new data. The proactive caching feature of Analysis Services 2005 Enterprise Edition addresses this problem. Proactive caching consists of two components :
| |
In Chapter 7 we described the three storage modes of Analysis Services: MOLAP, HOLAP, and ROLAP. At that time, we recommended that you use MOLAP almost always, and weve not discussed the issue since then. Now we finally get to a subject where the different storage modes are more important. Lets quickly review:
-
MOLAP copies the atomic data from the relational source and stores it in Analysis Services MOLAP format. Pre-computed aggregations are also stored in MOLAP format. MOLAP storage has the best performance at query time because the MOLAP storage mode is highly optimized and indexed for dimensional access.
-
HOLAP queries the atomic data from the relational source and uses it to generate pre-computed aggregations. Only the aggregations are stored in MOLAP format. Queries to the atomic data are pushed back to the relational database. HOLAP is our least favorite storage mode because you pay almost the same cost at processing time as MOLAP, but you dont reap anywhere near the benefits at query time.
-
ROLAP keeps all the data in the relational database, both atomic data and aggregations. Analysis Services manages the creation of the aggregations for you. ROLAP performs significantly worse at query time than the other two options, and its surprisingly slow at processing time as well. Processing the summary tables is much slower because you have to accept the burden of the relational engines overhead. ROLAP is an excellent choice for a small, real-time partition with few or zero aggregations (summaries). Its a terrible choice for all partitions of a terabyte- sized database.
Storage mode is a decision that you make for each Analysis Services partition. Different partitions of the same measure group can have different storage modes and aggregation designs.
| |
-
A mechanism for watching the relational database from which the cube is sourced, to identify new data.
-
Sophisticated caching that enables uninterrupted high-performance querying while the new data is being processed and added to the cube.
Proactive caching itself does not provide real-time capability; it is a feature that helps you manage your real-time business needs. You can use Management Studio to set proactive caching settings for dimensions, and also for facts on a partition-by-partition basis. A key setting is the data latencythe time spent inactivebetween the time when source data can be changed and when it must be available to end users.
| |
The best choice for very low-latency real-time systems is to use MOLAP storage for the vast majority of the cube. Define one small Analysis Services partition most often just for the current day or even the current hour as ROLAP with few or zero aggregations.
If your business users definition of real time is longer (for example hourly), you may be able to use MOLAP for the real-time partition. Each of these choices requires very different settings for the proactive cache, discussed in the text that follows .
| |
When a business user issues a query of a database partition that has proactive caching enabled, Analysis Services first checks the data latency settings that you defined. If you said latency was one hour, and the partition was last refreshed 20 minutes ago, the query will resolve from the partitions MOLAP cache. If the partition is out of date, Analysis Services will direct the query to the underlying relational source. This all happens automatically, as illustrated in Figure 17.4.
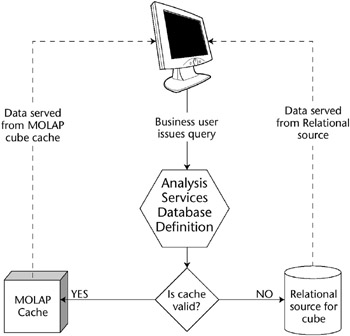
Figure 17.4: With proactive caching, the query is directed to the appropriate data store.
| Warning | If the relational source system is the transaction system, you need to be very careful. Queries that you might think would be handled entirely by Analysis Services can be pushed through to the relational database and can affect system performance. You must test the proactive caching settings carefully , with a realistic workload, before you go live. Otherwise you run the risk of making the transaction system DBAs justifiably irate. |
Proactive cache settings are defined for each partition and dimension. Most often youll define proactive caching only for a very small partition, perhaps for the current day. The occasional querying into the relational source occurs only for this partition and only when the cache is out of date. The part of the query that asks for older data would simply access those static partitions. Analysis Services breaks apart the query for you, and sends it to the appropriate places. Then it stitches the result set back together for you, and performs any necessary calculations and aggregations.
Lets talk more about what happens when the cache is out of date. Weve already said the query goes off to the relational data source, but whats going on with the cache? Analysis Servicesmore precisely, the Proactive Caching Management Threadis listening to the relational database for activity. It also knows the settings youve defined for the partition, notably the latency setting. If data has been added to the database, and the latency level has been reached, this thread starts processing that new data. Its during this processing period that queries are redirected to the relational database.
The query performance during the cache refresh process will degrade somewhat. Theres a lot of stuff going on during this period, even if data volumes are small:
-
Analysis Services is grabbing new data from the relational database and processing it.
-
The partitions cache is being updated from that data.
-
Analysis Services is figuring out which part of users queries to send to the relational engine.
-
The relational engine is serving up these users queries.
-
Analysis Services is stitching the result sets back together again.
-
Analysis Services performs any computations , like calculated measures, that would normally be performed on a result set.
This is impressively complex functionality that really will deliver data, with all the advantages of Analysis Services databases, within the latency specified. In other words, users do get real-time data.
Fortunately for the user, the cache building is done as a background thread and assigned a low priority. This means users queries are given higher priority than the background proactive caching thread. If at any time during this rebuild process someone initiates a process that will change the data in the cube, for example by re-processing the cube or doing a writeback to the cube, the background proactive caching thread to rebuild the MOLAP cache will be cancelled. Similarly, if Analysis Services receives another notification of a data change, the MOLAP cache rebuilding process will be cancelled. Its important to be aware of this behavior so you can ensure the correct properties are set for the proactive caching feature based on your business requirements. We talk more about these settings in the next section.
After we discuss the proactive caching settings, well talk about how to set up the notification mechanism. There are several methods for communicating between the relational source and Analysis Services, eachnaturallywith advantages and disadvantages.
Setting Up Proactive Caching Policies on a Partition
You can set up proactive caching in either BI Studio or Management Studio. Both approaches use the same user interface. We consider dealing with partitions and storage modes to be primarily a management, rather than a development, activity, so we prefer to use Management Studio. If youre working with a development databaseas you should do at the outsetit doesnt matter. For test and certainly for production systems, of course, you must carefully script these configuration changes, as we described in Chapter 14.
Youll find the user interface for setting proactive caching properties in the Partition Properties dialog box, illustrated in Figure 17.5.
Figure 17.5: Partition Properties dialog box
| |
The proactive cache is just a partition, whose processing is managed automatically by Analysis Services. Microsoft calls it a cache because it sounds better. We understand their desire to send this message because weve spent a lot of time arguing with people who hate that the Analysis Services MOLAP storage copies the atomic data. Computers copy data all the time:
-
All data gets copied into memory as its accessed.
-
Web browsers cache copies of web pages locally.
-
Relational databases copy data for index structures.
Nobody objects to these forms of data copying because the systems manage them for you automatically. The same is true of Analysis Services, particularly with proactive caching.
So, yes, we agree this thing were talking about qualifies as a cache.
But, for the purposes of building and managing the system, you need to understand whats going on. The proactive cache is simply a partition like any other. The only difference is that its processing is managed automatically by Analysis Services, using the proactive caching settings that you define.
| |
The dialog box has four pages listed in the upper left, including the Proactive Caching page, illustrated in Figure 17.6. You can choose between seven standard configurations on the Proactive Caching page, ranging from real-time ROLAP on the left, to MOLAP on the right. These are standard sets of settings to simplify your task; you can set customized configurations if you wish.
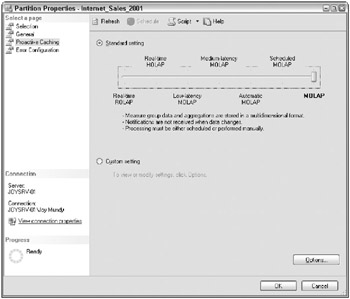
Figure 17.6: The Proactive Caching page of the Partition Properties dialog box
You can set all the properties for proactive caching by clicking the Options button on the Proactive Caching page. Youre presented with the Storage Options dialog box illustrated in Figure 17.7.
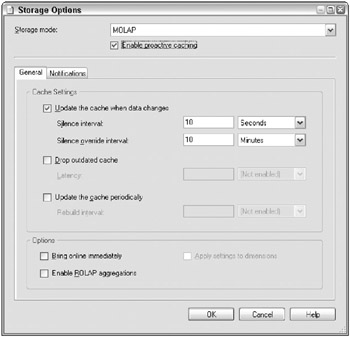
Figure 17.7: Storage Options dialog box
If proactive caching is turned off, as it is by default for the MOLAP and Scheduled MOLAP configurations, most of the settings are unavailable. Turn them on by checking the Enable proactive caching checkbox at the top of the Storage Options dialog box.
These settings are a bit confusing at first glance. You need to understand all the settings, and how they work together, to correctly set up proactive caching for your technical environment and business requirements.
-
Silence interval is the amount of time that must elapse from the time Analysis Services detects change in the relational data before it starts rebuilding the MOLAP cache. As soon as a data change is detected, a time counter starts to count down to the specified silence interval time. If a new data change is detected , the silence interval time is reset once again. The purpose of the silence interval is to let some kind of batch processlike the ETL process that loads your data warehouse databasefinish before you kick off proactive cache processing. Otherwise, every little change in the relational database might launch proactive cache processing.
-
Silence override interval does what it sounds like: It lets you override the Silence interval. If your relational source is, for example, a transaction system, you may never get a quiet moment in which to start processing. The Silence override interval lets you say, basically, Wait for 10 seconds of silence before you start processing, but if its been more than 10 minutes just go ahead.
-
Latency defines how long users are allowed to query an old image of the data. Even if the underlying database is changing constantly, you may want users to query a consistent dataset for up to an hour (or five minutes, or whatever latency suits your business requirements). The real-time partition (cache) is dropped when the latency limit is reached. In order to set Latency, you must check the Drop outdated cache checkbox. During the interval between when the real-time cache is dropped and rebuilt, Analysis Services will direct the queries to the underlying relational database.
-
Rebuild interval will rebuild the real-time partition on a specific interval, regardless of whether Analysis Services has received notification from the relational database that new data have arrived. In order to set the Rebuild Interval, you must check the Update cache periodically checkbox.
Warning The alert reader will recognize that you could use the Rebuild interval setting to automatically refresh your cube even in non-real -time situations, like daily processing. In Figure 17.6 , the predefined setting for Scheduled MOLAP does exactly this. However, theres a flaw with the way this feature works. It kicks off at an elapsed time after the last processing completes. If processing takes one hour and youre processing daily, your partition processing will start an hour later every day. Thats probably not what you want. If youre not in a real-time situation, youre better off scheduling processing in Integration Services.
-
Bring online immediately will, as you might expect, bring the real-time partition online immediately. This setting applies only if theres infinite latencyin other words, if youre not forcing a rebuild of the real-time partition after a certain amount of time. As weve already mentioned, most people will be creating a new real-time partition every day. When you create the partition, Analysis Services will grab all the existing data for today and process the real-time partition (cache). If this takes a while, you may want your users to be able to query todays data immediately. By selecting this option, youre telling Analysis Services to send users to the relational database until the first processing of the day has completed. In most cases this isnt going to have a huge impact, as youll create a new daily partition right around midnight, when theres very little data to process or user queries to redirect.
-
Enable ROLAP aggregations sets up indexed or materialized views in the relational database. These indexed views will be used during those periods when a MOLAP real-time partition is being processed, and queries are redirected to the relational database.
Warning Indexed views can be expensive for the relational database to maintain, especially if the underlying table receives updates in addition to inserts . Wed be reluctant to use this setting ever, and certainly not if the relational database is a transaction system.
-
Apply settings to dimensions is an option thats available only if youre setting up an entire cube for proactive caching. It will propagate the proactive caching settings to all the cubes dimensions.
Warning Only if your entire cube is very small, several gigabytes in size or less, should you consider using proactive caching on the entire cube and all its dimensions. Maybe a software developer whos integrating Analysis Services into a packaged ERP system would use this feature. Wed never consider using this option for an enterprise DW/BI system.
Receiving Notifications of Data Changes
In the preceding discussion, we talked about what Analysis Services does when it receives a notification that the data in the source relational database has changed. But we didnt describe what that notification looks like and how you set it up. You have several options, summarized in Table 17.2.
| OPTION | DESCRIPTION | PROS | CONS |
|---|---|---|---|
| Trace Events | You identify the table to track. Analysis Services sets up and monitors a trace in the relational database. | Easiest to use | Available only if the source databaseis SQL Server Requires full reprocessing of the real-time partition Requires that the Analysis Services service account have administrator privileges on the relational database server Delivery of the events is not 100 percent guaranteed |
| Client-initiated | You write an application that figures out when the underlying table has changed. Communicate that change to Analysis Services via a Web Service call. | Ooh, a Web Service call Can be used with non-SQL Server sources Flexible | Requires full reprocessing of the real-time partition Sketchy documentation; difficult to set up Requires actual coding |
| Polling | You specify a query for Analysis Services to execute against the source database server. A change in the query results from one poll to the next means the data has changed. | Supports incremental processing of the partition Can be used with non-SQL Server sources Flexible Moderately easy | Somewhat more complex than Trace Events |
Obviously, we have a preference for the polling mechanism, although the trace events approach is so easy that its really appealing. On the other hand, if youre implementing a real-time Analysis Services database, youve already crossed the line on ease-of-use, so setting up polling shouldnt be too much additional burden. Its hard for us to understand why youd implement the client-initiated approach. It seems way too difficult in comparison to the other methods.
Figure 17.8 illustrates the Notifications tab of the Storage Options (proactive caching) dialog box, in which were defining polling for incremental processing.
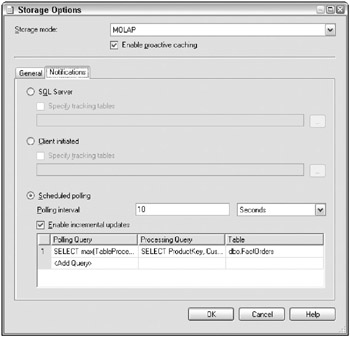
Figure 17.8: Defining polling parameters for incremental processing
Set up the following parameters:
-
Polling interval is the frequency at which to poll the source database.
-
Enable incremental updates is a checkbox that, yes, enables incremental updates. If you check this box, youll need to specify a processing query and a table. If you dont check this box, the entire real-time partition will be fully processed every time the data changes.
-
Polling query is the text of the SQL query to determine whether new data has been added. What this query looks like depends on your source system. The polling query should return a scalar: one row and one column.
-
Processing query is the text of the SQL query to determine which new data to add. This query, and the associated partition incremental processing, is launched only if the polling query indicates that data has changed. As we describe in the associated sidebar (Sample Polling and Processing Queries), Analysis Services makes available to you the old and new values of the polling query, for you to parameterize the processing query. You dont need to use these parameters, but its usually the best way to implement the processing query.
-
Table specifies the relational table from which the partition is sourced.
| |
We will walk through a simple example of polling and processing queries. Perhaps your real-time partition is sourced directly from a transaction system. Hopefully you have a transaction ID, or a transaction date and time. Your polling query could be
SELECT max(TrxnDateTime) FROM MyTrxnTable
The corresponding processing query could be
SELECT <list of columns> FROM MyTrxnTable WHERE TrxnDateTime > ISNULL(?, -1) AND TrxnDateTime <= ?
The first question mark refers to the old value from the polling query, and the second refers to the current value. The ISNULL logic is there for the first time the partition is processed.
The <list of columns> is a little tricky. You need to return them in the correct order. To do so, exit from this part of the dialog box (click OK to save your work!), and go back out to the General page of the Partition Properties dialog box. (You may have forgotten, but all the proactive caching settings are managed in a subpage of the Partition Properties dialog.) From the General page, grab the Source property of the partition, copy it, and then go back to where you were to paste it as the processing query. Whew! Dont forget to add the WHERE clause we described previously.
| |
Incremental processing is a great technique for delivering data with medium latency of, say, hourly. If your data volumes are quite large, this technique will let you deliver MOLAP query performance with reasonably quick and efficient processing.
If you need very low latency, youre probably best off using a relational real-time partition with no aggregations. In this case, you dont need any processing at all. With extremely large data volumes, you may want to create hourly real-time partitions.
| Warning | Dont set up frequent incremental processing on a partition that lives for a long time. Incremental processing of a partition increases its size (and hence reduces its query performance). Its best practice to occasionally fully process a partition that undergoes frequent incremental processing. A day-old partition thats been updated hourly is a good candidate for full processing. This would be a good time to merge that daily partition into a monthly or weekly partition. |
Setting Up Proactive Caching Policies on a Dimension
The process, and options, for setting up proactive caching on a dimension are the same as for a partition. For the most part, just re-read the two sections immediately preceding this one, and replace partition with dimension.
There are a few points for us to highlight. First, we assume youre not using the (terrifying, to us) option of setting up a whole cube with the same proactive caching settings. Set up settings for a single dimension by right-clicking on the dimension in Management Studio and choosing Properties. Youll see the same proactive caching page and options as for a partitionas far as we can tell, theyre exactly the same dialog boxes.
Its important for you to remember that these proactive cache settings are for the entire dimension, and all uses of that dimension. You really need to think through the implications of setting up a dimension to use proactive caching. Non-real-time cubes, measure groups, even partitions will be affected by changes to the dimension. On the one hand, this is a good thing, because you certainly want a single view of an entity like Customer. But realistically , as we discussed at the beginning of this chapter, you may be burdening non-real-time users with a lot of confusing changesand burdening your system with a lot of reprocessingif you havent thoroughly considered the big picture.
| Warning | Type 1 dimension attributes, which are updated in place, are problematic for real-time systems. For dimensions that are updated in real time, we recommend that you avoid building stored aggregations on a Type 1 attribute thats frequently updated. This is particularly important if your database is large. And remember, a Type 1 update affects all partitions that use that dimension, not just the real-time partition. Although we discussed this issue at the beginning of this chapter, its worth repeating. Any aggregation thats built on a Type 1 attribute is invalidated any time a member is updated. Now, these aggregations will rebuild in the background, so for daily updating this usually isnt a huge problem. But if youre in real-time mode and updating hourly (or more frequently), this constant rebuilding of aggregations could be never-ending . To set up an Analysis Services dimension attribute so it doesnt participate in aggregations, go to the Cube Editor in BI Studio. Set the AggregationUsage property of the dimension attribute in the cube to None. Note: AggregationUsage is a property of the dimension attribute within the cube, so youll need to set it in all the cubes that use this dimension. |
Unless you set up a fairly complex polling mechanism, you run a risk of having proactive caching kick off for a partition before its corresponding dimension is processed. In this case, you may attempt to process a fact row that doesnt have a corresponding member in the Analysis Services dimension.
In Chapter 7 we briefly mentioned Analysis Services functionality that handles referential integrity violations for you. We said your DW/BI system should forbid RI violations so we recommended that you not use these features.
In a real-time environment, especially for a cube thats sourced directly from a transaction system, you do need these features. Even for a cube thats sourced from a data warehouse database, you still run a greater risk of handling fact rows before their dimension rows have been processed.
The default error processing, which you can change from the Error Configuration page of the Partition Properties dialog box, is probably what you want for a real-time partition. This configuration will report errors, and convert RI violations to an unknown member, but is relatively unlikely to halt processing because of errors. We really hate that you might need the ability to move ahead with junky data, but in some real-time scenarios, thats what youll need to do.
Using Integration Services with Analysis Services in Real Time
Proactive caching allows you to configure processing of Analysis Services objects based upon changes in the relational database or at periodic time intervals. If youre delivering data to business users with a latency of less than a day, you should see first if proactive caching meets your requirements.
If you cant or dont want to use proactive caching, you can still update cubes with a latency of less than a day. Integration Services provides several mechanisms for working with Analysis Services databases:
-
Use the Analysis Services Execute DDL task to automate the definition of new partitions, like a new real-time daily partition. You can also use this task to automate Analysis Services backups .
-
Use the Analysis Services Processing task to process an OLAP database or data mining model, as we described in Chapter 15.
-
Within a Data Flow task, use the Dimension Processing transform to populate an Analysis Services dimension directly from the Integration Services pipeline. In normal usage, the last step of a data flow task is usually to write the transformed data into a relational table. A later step would use the Analysis Services Processing task to process the dimension. Instead, you could use the Dimension Processing transform to write the data directly into an Analysis Services partition. We dont recommend this approach for most applications because you generally want a permanent record in the relational database. Nonetheless, this transform can be useful in a low-latency system, especially if you write the data to the relational database at the same time it goes into Analysis Services.
-
Similarly, the Partition Processing transform will write the data flow directly into an Analysis Services partition.
We expect most systems to use the Analysis Services Execute DDL and Analysis Services Processing tasks. Of course, non-real-time systems will use these tasks for all of their Analysis Services processing. Even a real-time system thats using proactive caching will use these tasks to set up new partitions, merge the daily partition into a larger partition, and perform periodic full processing of partitions that have been incrementally updated with proactive caching.
The Dimension Processing and Partition Processing transforms within the Data Flow are interesting features. If youre in the business of providing information, you may use these features to deliver cubes to your customers. As weve said throughout this book, however, most systems should store the clean, integrated data in a relational database.
If, for whatever reason, you have performance problems in writing the data to your relational database, you may save substantial time by multicasting the data flow and populating an Analysis Services partition directly from the flow. This processing would occur at the same time youre writing a copy of the data to the relational database, and could reduce the time it takes for processing to complete.
| | ||
| | ||
| | ||
EAN: N/A
Pages: 125