| Using the 80/20 rule, 80 percent of ETL work occurs in the "T" (transform) portion when extensive data integration and data cleansing are required, while extracting and loading represent only 20 percent of the ETL process. Source Data Problems The design of the transformation programs can become very complicated when the data is extracted from a heterogeneous operational environment. Some of the typical source data problems are described below. -
Inconsistent primary keys: The primary keys of the source data records do not always match the new primary key in the BI tables. For example, there could be five customer files, each one with a different customer key. These different customer keys would be consolidated or transformed into one standardized BI customer key. The BI customer key would probably be a new surrogate ("made-up") key and would not match any of the operational keys, as illustrated in Figure 9.4. Figure 9.4. Resolution of Inconsistent Primary Keys 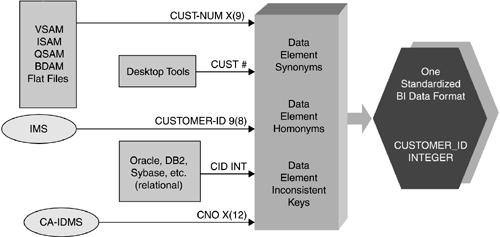 -
Inconsistent data values: Many organizations duplicate a lot of their data. The term duplicate normally means the data element is an exact copy of the original. However, over time, these duplicates end up with completely different data values because of update anomalies (inconsistent updates applied to the duplicates), which have to be reconciled in the ETL process. -
Different data formats: Data elements such as dates and currencies may be stored in a completely different format in the source files than they will be stored in the BI target databases. If date and currency conversion modules already exist, they need to be identified; otherwise , logic for this transformation has to be developed. -
Inaccurate data values: Cleansing logic has to be defined to correct inaccurate data values. Some of the data-cleansing logic can get extremely complicated and lengthy. The correction of one data violation can take several pages of cleansing instructions. Data cleansing is not done only once ”it is an ongoing process. Because new data is loaded into the BI target databases with every load cycle, the ETL data-cleansing algorithms have to be run every time data is loaded. Therefore, the transformation programs cannot be written "quick and dirty." Instead, they must be designed in a well- considered and well-structured manner. -
Synonyms and homonyms: Redundant data is not always easy to recognize because the same data element may have different names . Operational systems are also notorious for using the same name for different data elements. Since synonyms and homonyms should not exist in a BI decision-support environment, renaming data elements for the BI target databases is a common occurrence. -
Embedded process logic: Some operational systems are extremely old. They run, but often no one knows how! They frequently contain undocumented and archaic relationships among some source data elements. There is also a very good chance that some codes in the operational systems are used as cryptic switches. For example, the value "00" in the data element Alter-Flag could mean that the shipment was returned, and the value "FF" in the same data element could mean it was the month-end run. The transformation specifications would have to reflect this logic. Data Transformations Besides transforming source data for reasons of incompatible data type and length or inconsistent and inaccurate data, a large portion of the transformation logic will involve precalculating data for multidimensional storage. Therefore, it should not be surprising that the data in the BI target databases will look quite different than the data in the operational systems. Some specific examples appear below. -
Some of the data will be renamed following the BI naming standards (synonyms and homonyms should not be propagated into the BI decision-support environment). For example, the data element Account Flag may now be called Product_Type_Code. -
Some data elements from different operational systems will be combined (merged) into one column in a BI table because they represent the same logical data element. For example, Cust-Name from the CMAST file, Customer_Nm from the CRM_CUST table, and Cust_Acct_Nm from the CACCT table may now be merged into the column Customer_Name in the BI_CUSTOMER table. -
Some data elements will be split across different columns in the BI target database because they are being used for multiple purposes by the operational systems. For example, the values "A", "B", "C", "L", "M", "N", "X", "Y", and "Z" of the source data element Prod-Code may be used as follows by the operational system: "A," "B," and "C" describe customers; "L," "M," and "N" describe suppliers; and "X," "Y," and "Z" describe regional constraints. As a result, Prod-Code may now be split into three columns : -
- Customer_Type_Code in the BI_CUSTOMER table -
- Supplier_Type_Code in the BI_SUPPLIER table -
- Regional_Constraint_Code in the BI_ORG_UNIT table -
Some code data elements will be translated into mnemonics or will be spelled out. For example: -
- "A" may be translated to "Corporation" -
- "B" may be translated to "Partnership" -
- "C" may be translated to "Individual" -
In addition, most of the data will be aggregated and summarized based on required reporting patterns and based on the selected multidimensional database structure (star schema, snowflake ). For example, at the end of the month, the source data elements Mortgage-Loan-Balance, Construction-Loan-Balance, and Consumer-Loan-Amount may be added up (aggregated) and summarized by region into the column Monthly_Regional_Portfolio_Amount in the BI_PORTFOLIO fact table.  |