4.3 Designing in Debugging Support
| During software development, a good debugger, when combined with a seasoned developer, allows software to quickly evolve from its initial state to release-quality code. The debugger provides the tools to examine the state of the running software, while the developer provides the insight on how to interpret this information. But debuggers aren't always available when you need them. For example, your software may be in the hands of a customer and you only have a limited description of a problem, and are not able to reproduce it. In this section, we discuss some strategies for getting the information you need from your software. Besides using software debuggers, profilers, and other tools, you can also insert statements to log information during the debugging phase. This information is subsequently written to the console, file, or other device for later review; or, it is simply discarded. There are advantages and disadvantages to adding your own debugging code. The biggest advantage is that you are in total control. You can decide if your code waits for specific conditions to occur or if it generates reams of information immediately. This lets you detect many timing- related bugs that would otherwise be almost impossible to diagnose. One of the biggest disadvantages, however, is that debugging code is not present in production releases. Sometimes this results in timing-related bugs that appear only in the production version of the software. It is important to remove debugging statements from production releases. Debugging messages can expose sensitive information regarding the product's implementation. In the hands of competitors , this information can yield a wealth of information. Depending upon the nature of the application, we have found that some debugging information, such as customer-specific timing issues or details, is too sensitive to share with the rest of the company. Many people handle the debugging statements issue in code that looks very similar to this: #ifdef DEBUG std::cerr << "Some debugging messages" << std::endl; #endif During development, the makefile will define the variable DEBUG to compile the debugging code into the application. Production releases do not define this variable, effectively removing all of this code from the product. In this section, we present a strategy for handling debugging information that is:
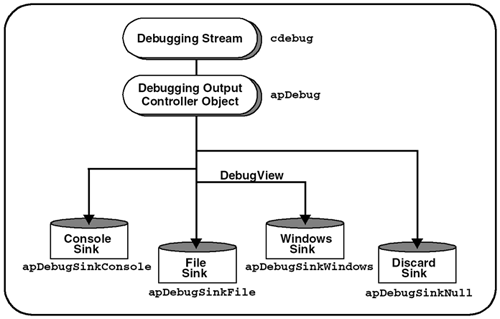
First, we design a generalized debugging stream. Next , we create destination objects, called sinks , for the debugging output. Once we have the destinations, we create an object to control the amount of debugging information that is actually output to those destinations. Finally, we extend our debugging environment to allow remote access to objects through an object registry. Figure 4.1 illustrates the components that make up our debugging environment. Figure 4.1. Debugging Environment Overview 4.3.1 Creating a Generalized Debugging StreamWhen we add debugging code to our application, we usually write information to a standard stream, such as std::cout or std::cerr (or C-style stdout , stderr ). This is useful, but we will do it one better by creating a new stream whose purpose is reserved for debugging. This leaves the standard streams available for casual debugging purposes. For in-depth information on streams, see [Langer00]. If you want to continue using std::cout , it is possible to redirect this stream if you need to create a permanent copy. We can temporarily redirect std::cout to a file, redirect.txt , with the following code: #include <iostream> #include <fstream> ... std::cout << "This should be written to the console" << std::endl; std::ofstream file ("redirect.txt"); std::streambuf* oldbuf = std::cout.rdbuf (); // Save std::cout.rdbuf (file.rdbuf()); std::cout << "This should be written to the file" << std::endl; std::cout.rdbuf (oldbuf); // Restore std::cout << "This should be written to the console" << std::endl; To create a more permanent solution, we really want to dedicate a stream to send debugging information. Then we can write statements such as: cdebug << "Debugging stream message" << std::stream; where cdebug is our new debugging stream. The C++ standard stream library consists of a very full set of classes to allow streams to be created and manipulated. However, the classes can be very complicated to use and understand. Fortunately, we do not have to jump in and completely understand std:: ostream and everything that goes with it. We can choose a subset that meets our needs. Since this is only being used in debug mode, we can afford to choose a solution that is not optimized for performance. This is an especially good trade-off if the solution is easy to understand and implement. To create our new debugging stream, cdebug , we first create regular static objects. In our header file, we declare the objects at global scope, as shown: extern apDebugStringBuf<char> debugstream; extern std::ostream cdebug; We then define them in our source file, as shown: apDebugStringBuf<char> debugstream; std::ostream cdebug (&debugstream); cdebug is an instance of std::ostream that connects a stream with our string buffer object. debugstream is our global stream buffer object (an instance of apDebugStringBuf<> , which is defined on page 100) that forwards the stream data to the appropriate destination, called a sink. (Sinks are fully described on page 96.) Let's look at the following example: cdebug << "This line goes to our null sink" << std::endl; debugstream.sink (apDebugSinkConsole::sOnly); cdebug << "This line goes to std::cout" << std::endl; apDebugSinkConsole::sOnly.showHeader (true); cdebug << "Also to std::cout, but with a timestamp" << std::endl; apDebugSinkFile::sOnly.setFile ("test.txt"); debugstream.sink (apDebugSinkFile::sOnly); cdebug << "This line goes to test.txt" << std::endl; apDebugSinkFile::sOnly.showHeader (true); cdebug << "Also to test.txt, but with a timestamp" << std::endl; If you look at the file, test.txt , it will contain: This line goes to test.txt Mon Apr 22 19:42:24 2002: Also to test.txt, but with a timestamp If you execute these lines again, you will see two additional lines in the file because we append data, rather than overwriting it. 4.3.2 Creating SinksWe are now ready to create objects that will hold the information from the debugging stream. These objects are called sinks. A sink is the ultimate destination for a stream of information, so it nicely describes what our object does. Our base class, apDebugSink , defines the basic interface that any derived sink object must implement. Its definition is shown here. class apDebugSink { public: apDebugSink (); virtual void write (const std::string& str) = 0; virtual void write (int c) = 0; // Write a string or character to our debugging sink; virtual void flush () {} // flush any stored information for this type of sink. virtual std::string header () { return standardHeader();} // By default, we emit a standard header when headers are enabled void showHeader (bool state) { enableHeader_ = state;} // Set the state of whether a header is written protected: std::string standardHeader (); bool enableHeader_; // true writes header when buffer is flushed }; apDebugSink is very simple. The write() method adds a string or character to our debugging stream with optional buffering. Derived classes can override flush() to emit any stored characters in the object. Although we do not make any assumptions regarding buffering, the intent is to buffer one line of information at a time. A timestamp, or other information, can be prepended to each line before it is output. Derived classes can call header() to retrieve the value of the header before outputting a line of debugging information. Unless overridden, header() will display just the time by calling standardHeader() , whose implementation is shown here. std::string apDebugSink::standardHeader () { std::string header; // Fetch the current time time_t now = time(0); header += ctime (&now); header.erase (header.length()-1, 1); // Remove newline written header += ": "; return header; } In our framework, we define four different types of sinks: null, console, file, and windows . We define apDebugSinkNull to discard any characters passed to it and to do nothing further. This is a useful way to shut off the stream. apDebugSinkNull is also the default sink when you construct a debugging stream, cdebug . The definition of apDebugSinkNull is shown here. class apDebugSinkNull : public apDebugSink { public: static apDebugSinkNull sOnly; virtual void write (const std::string& str) {} virtual void write (int c) {} private: apDebugSinkNull (); }; We only need a single instance of each sink, so we have defined a static instance, sOnly . In previous prototypes , we used a function, gOnly() , to access our singleton object. In this case, however, we are directly constructing the static object because we will be passing it around by reference. This is obvious when we look at how sink objects connect with the cdebug stream. The remaining lines of code contained in the source file are as follows : apDebugSinkNull apDebugSinkNull::sOnly = apDebugSinkNull (); apDebugSinkNull::apDebugSinkNull () {} apDebugSinkConsole writes a stream of characters to std::cout . Its definition is shown here. class apDebugSinkConsole : public apDebugSink { public: static apDebugSinkConsole sOnly; virtual void write (const std::string& str); virtual void write (int c); virtual void flush (); protected: virtual void display (const std::string& str); // Output the string. Derived classes can override this apDebugSinkConsole (); virtual ~apDebugSinkConsole (); std::string buffer_; }; apDebugSinkFile writes a stream to a specified file. Its definition is shown here. class apDebugSinkFile : public apDebugSinkConsole { public: static apDebugSinkFile sOnly; void setFile (const std::string& file); // Set/change our file name. The stream is flushed before the // file name is changed. private: virtual void display (const std::string& str); apDebugSinkFile (); virtual ~apDebugSinkFile (); std::string file_; }; As you can see, apDebugSinkFile actually derives from apDebugSinkConsole . We do this because the only difference between these objects is where the data is written when the internal buffer, buffer_ , is flushed. Flushing a SinkFlushing data from the internal buffer occurs in the following cases:
The implementation of flush() is as shown: void apDebugSinkConsole::flush () { if (buffer_.size() == 0) return; if (enableHeader_) buffer_ = header() + buffer_; // Add a trailing newline if we don't have one // (we need this when we shut down) if (buffer_[buffer_.length()-1] != '\n') buffer_ += '\n'; display (buffer_); buffer_.clear (); } Since flush() does all the work of formatting the buffer, display() becomes very simple, as shown: void apDebugSinkConsole::display (const std::string& str) { std::cout << str; } void apDebugSinkFile::display (const std::string& str) { if (file_.size() == 0) return; // Open the file in append mode. The dtor will close // the file for us. std::ofstream output (file_.c_str(), std::ios_base::app); if (!output) return; // The file could not be opened. Exit output << str; } Although these sink objects are intended to be used by our stream object, they can also be used independently, as shown in the following lines of code: for (int i=0; i<10; i++) apDebugSinkConsole::sOnly.write ('0' + i); apDebugSinkConsole::sOnly.write ('\n'); This code outputs " 0123456789\n " to std::cout . Let's look at one more useful sink before we leave this topic. If you are developing under Microsoft Windows, there is a useful function, OutputDebugString() , that outputs a string to the debugger if one is running. And, thanks to a great piece of freeware called DebugView , which is provided on the CD-ROM included with this book, you can view these strings whenever you want, even in release builds. Adding a new sink to support this type of output is easy. Its definition is shown here. class apDebugSinkWindows : public apDebugSinkConsole { public: static apDebugSinkWindows sOnly; virtual void display (const std::string& str); }; apDebugSinkWindows apDebugSinkWindows::sOnly = apDebugSinkWindows(); void apDebugSinkWindows::display (const std::string& str) { OutputDebugString (str.c_str());} If there is no application or system debugger, then OutputDebugString() just makes a simple check; the overhead is negligible. 4.3.3 Connecting a Sink to a StreamWe are now ready to connect our sink object to a stream. If you study the standard library, you will find the std::basic_stringbuf<> class. This object manages an array of character elements for a stream object. What we want to do is derive an object from std::basic_stringbuf<> that uses our sink objects as the actual storage of the stream data. This is actually quite simple. If no storage buffer is allocated by the std::basic_stringbuf<> object, the object will call the virtual function overflow() with every character it attempts to save in its storage: int_type overflow (int_type c); where int_type is defined as the character type that the object handles. We need to override this function to insert characters into our apDebugSink object, as shown: template<class T, class Tr = std::char_traits<T>, class A = std::allocator<T> > class apDebugStringBuf : public std::basic_stringbuf<T, Tr, A> { public: apDebugStringBuf (apDebugSink& s = apDebugSinkNull::sOnly) : sink_ (&s) {} ~apDebugStringBuf () { sink_->flush();} typedef typename std::basic_stringbuf<T, Tr, A>::int_type int_type; int_type overflow (int_type c) { if (c != traits_type::eof()) sink_->write (c); return traits_type::not_eof(c); } void sink (apDebugSink& s) { sink_ = &s;} // Change our sink private: apDebugSink* sink_; }; This object looks confusing because of how the stream library is written, but it is actually very powerful. With this object, we can write to any kind of apDebugSink object (file, console, null, or windows) without worrying about the details. When the apDebugStringBuf<> object is constructed , we default to using the apDebugSinkNull object to discard all debugging output. If you recall from page 95, cdebug is created as a static instance of apDebugStringBuf<> , as shown: apDebugStringBuf<char> debugstream; std::ostream cdebug (&debugstream); 4.3.4 Controlling Debugging OutputOur debugging stream, cdebug , gives us a place to write debugging information and the flexibility to control where this information is sent. We still need more control over what information is generated. In the simplest case, we want something like: if (some condition) cdebug << "debugging" << std::endl; Sometimes the condition is complicated and depends upon certain run-time conditions; other times, the condition relates to the desired amount of debugging output. We are going to explore the usefulness of this latter case. We can define an object, apDebug , to keep track of the current amount of debugging detail to be generated. Its definition is shown here. class apDebug { public: static apDebug& gOnly (); int debug () { return debug_;} int debug (int d) { int cur = debug_; debug_ = d; return cur;} // Get/set the global debugging level bool isDebug (int level) { return debug_ >= level;} // Returns true if this level is enabled for debugging. private: static apDebug* sOnly_; int debug_; apDebug (); }; debug_ is an integer value that indicates the amount of debugging output to generate. We use the convention of the higher the number, the more detail to include. Whenever the debugging level of a piece of debugging code is greater than or equal to the current debugging level, the debugging code should be executed. We can automate this decision by constructing a clever macro. In general, we avoid macros, but this case really needs one: #ifdef NODEBUG #define DEBUGGING(level,statements) #else #define DEBUGGING(level,statements) \ if (apDebug::gOnly().isDebug(level)) { \ statements \ } #endif The macro, DEBUGGING , is disabled if the symbol NODEBUG is defined during compilation. This makes it easy to remove all debugging code from your application with a simple change to your makefile. You can treat this macro just like a function: DEBUGGING(level, statements); where level is the debugging level of these statements, and statements is one or more C++ statements that should be executed when debug_ >= level . In case you aren't used to the syntax of macros, the \ characters at the end of some lines indicate that the macro continues on the next line. Using this character allows us to make the macro look more like lines of code. Note that our symbol, NODEBUG , is different than the NDEBUG symbol, which is used by compilers to indicate when assertions should be included in a build. We want our debugging interface to be included in production builds during testing and early releases, so we use a separate symbol, NODEBUG , for this purpose. If we used NDBEUG for both purposes, we could not have our debugging support included without assertions also being present. One big downside to using macros is interpreting error messages during compilation. Macros are expanded, meaning that one line of your source code actually becomes many lines. If an error is found while compiling the macro, some compilers may or may not report the correct line of the error. And for those that do, you may still be left with some fairly cryptic messages. Here's another example: DEBUGGING(1, cdebug << "This is level 1" << std::endl; ); DEBUGGING(2, { for (int i=0; i<10; i++) cdebug << "This is line " << i << std::endl; }); In this example, we use the { and } braces to further make our macro look more like code. While this isn't strictly necessary, we think it improves the readability of the code. If the debugging level in apDebug::gOnly() is still zero (from the previous example), then neither of the above statements will execute. Once the macros are expanded, the above code is equivalent to the following statements: if (0 >= 1) { first debugging statement ... } if (0 >= 2) { second debugging statement ... } Although these statements add extra bytes to the application, they add very little overhead when they are inactive. Activating either or both of these lines is easy: apDebug::gOnly().debug (1); // Debug level set to 1 apDebug::gOnly().debug (2); // Debug level set to 2 We recommend that you define what the various debugging levels mean when using this technique. We also recommend that you use a limited number of values to keep things simple, as shown in Table 4.2. Table 4.2. Debugging Levels
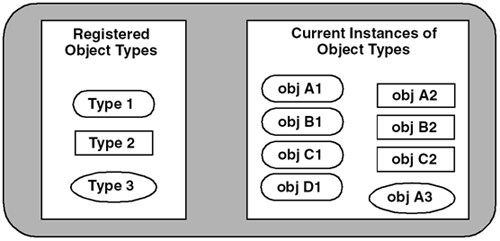
We can extend this technique to change the meaning of a debugging level by using the specific bits instead of the value. And, if an integer does not contain enough bits to contain all your combinations, you can modify apDebug to use a std::bitset to store an arbitrary number of bits, as follows: class apDebug { public: static apDebug& gOnly (); bool debug (int pos) { return debug_.test (pos);} bool debug (int pos, bool value) { bool cur = debug_.test (pos); if (value) debug_.set (pos); else debug_.reset (pos); return cur; } // Get/set the global debugging level bool set (int pos) { bool cur = debug_.test (pos); debug_.set (pos); return cur;} bool clear (int pos) { bool cur = debug_.test (pos); debug_.reset (pos); return cur;} // Set/clear a specific bit and return the old state void reset () { debug_.reset ();} // Turns off all debugging bool isDebug (int pos) { return debug_.test (pos);} // Returns true if this level is enabled for debugging. private: static apDebug* sOnly_; std::bitset<32> debug_; // 32 is an arbitrary value apDebug (); }; In this implementation, instead of setting a debugging level, you are setting a specific bit to enable or disable a specific debugging feature. Our earlier example now looks like: DEBUGGING(0, cdebug << "This is bit 0" << std::endl; ); DEBUGGING(1, { for (int i=0; i<10; i++) cdebug << "bit 1. This is line " << i << std::endl; }); It can be hard to remember the meaning of each bit, so we recommend you use an enumeration to manage them as shown. Bits are numbered starting with zero. enum { eGUIDebug = 0, // GUI debugging eImageDebug = 1, // Image operations eStorageDebug = 2, // Image storage operations ... }; apDebug::gOnly().reset (); // Disable all debugging apDebug::gOnly().set (eImageDebug); // Enable bit-1 DEBUGGING(eImageDebug, cdebug << "Image Debugging Enabled";); 4.3.5 Accessing Objects Indirectly Through an Object RegistryDebugging allows you to monitor what the application is doing. It is a much more difficult task to design a full-featured remote debugger. In this section, we discuss how to access an object indirectly through a simple object registry. This registry can be used to develop debuggers running either on the same machine or on a remote machine. If you only ever have one instance of an object, accessing it would be easy. We are very fond of using a gOnly() method to reference a singleton object, and this reference is available throughout the application. For example, enabling debugging using the apDebug object we presented in the previous section is as easy as: apDebug::gOnly().set (eImageDebug); The problem is more complicated when multiple instances of an object exist. Without some listing of all objects in existence, you cannot easily communicate with a specific instance. An object registry consists of two parts , as shown in Figure 4.2. Figure 4.2. Object Registry The first part tracks what kinds of objects are registered, with one entry per object type. The second part tracks the current instances of the specific object types. With such a registry, we can quickly see if an object type is contained in the registry, and, if so, the specific instances of the object that exist.
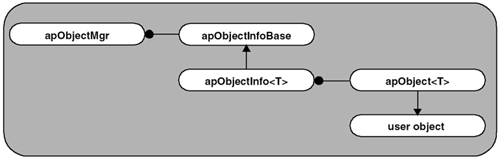
Fortunately, those days are behind us. Our design gives the developer the choice of whether an object should be registered, on both an object or instance basis. We also keep it simple so that you can use only the functionality you need. This design is shown in Figure 4.3. Figure 4.3. Object Registry Design The classes work together as follows:
Every object that enters the registry must derive from a common base class, because we need to maintain a list of objects in the registry. The base class allows us to track all instances of the object as well as do some basic control. We start by designing a singleton object for each object that we want to track. Using the gOnly() method to access the object also means that it is only created the first time the object is created. Like we have done in other examples, we split the objects into a common non-template object and a template object, as follows: class apObjectInfoBase { public: typedef std::map<void*, char> INSTANCEMAP; apObjectInfoBase () : debug_ (0) {} int debug () { return debug_;} void debug (int d) { debug_ = d;} bool isDebug (int level) { return debug_ >= level;} void addInstance (void* obj) { mapping_[obj] = 1;} void removeInstance (void* obj) { mapping_.erase (obj);} // Add/remove an object from our instance list virtual std::string process (const std::string& command) = 0; // Command processor. virtual std::string dump () = 0; // Returns a list of managed objects protected: int debug_; // Debug level for this object INSTANCEMAP mapping_; // List of all current objects }; apObjectInfoBase uses a std::map object to keep a list of all instances of a particular object. By storing the object as a void* pointer, as opposed to a native pointer, we are able to keep our solution generic. But why did we use a std::map object when a std::vector object would also work, as would a std::list object? We define mapping_ as a std::map<void*, char> , where void* is the key (the address of the object), and char is the value (an arbitrary number). The purpose of mapping_ is to be a list of object pointers. We chose a std::map object because it can efficiently handle additions and deletions and do all the work for us. For example, look at the code that adds or removes an object instance from this list: void addInstance (void* obj) { mapping_[obj] = 1;} void removeInstance (void* obj) { mapping_.erase (obj);} Not only are they very simple, but these insertions and deletions are also extremely fast. By using a std::map object, we do waste a little space because we store a char that we always ignore. std::map has the additional benefit of limiting the list to one instance of each object; this is a good choice, since we only track one instance of each debuggable object. Keep in mind that there are many alternatives to using std::map . It is easy to spend too much time researching the problem in hopes of finding the most efficient STL component. For example, we could have also chosen to use std::set , as this matches the requirements of our object very closely. With so many components to choose from, this can take longer than it takes to implement the entire object. If you have not used many STL components, you will soon discover that you end up using only a small subset of objects. This is not a bad thing. For commercial software, this can give you an edge. While some teams are crafting the "perfect solution," you already have a solution implemented and working.
Figure 4.4 shows our favorite subset of STL components. Figure 4.4. Recommended STL Components Our base class, apObjectInfoBase , also contains a debugging interface very similar to the apDebug object we presented earlier. In this implementation, we use the debug_ variable as a level, rather than as a sequence of bits. The class also defines pure virtual methods process() and dump() . dump() produces a human readable description of the object. process() is a general interface that we can use for remote debugging. To use this functionality, however, we still need one instance for every object type. That is exactly what the apObjectInfo<> class provides: template <class T> class apObjectInfo : public apObjectInfoBase { public: static apObjectInfo<T>& gOnly (); const std::string& name () const { return name_;} virtual std::string process (const std::string& command); virtual std::string dump (); private: static apObjectInfo<T>* sOnly_; std::string name_; apObjectInfo (); }; The template argument, T , for apObjectInfo<> is the name of the object type we want to debug. In addition to being a singleton object and defining our usual gOnly() function, apObjectInfo<> also provides an implementation for the pure virtual methods in apObjectInfoBase , as shown: template <class T> std::string apObjectInfo<T>::dump () { std::string str; char buffer[16]; INSTANCEMAP::iterator i; for (i=mapping_.begin(); i != mapping_.end(); i++) { sprintf (buffer, " %d", i->first); str += buffer; } return str; } Our object maintains a list of all instances, so the dump() method produces a list of instances by address. We could have made the default implementation of dump() do much more, like display the object details of each instance, but this goes beyond the scope of apObjectInfo<> . If we didn't restrict ourselves to a minimal representation of this object, we would have added some means of iterating on all the instances of the object. This would give the client the ability to access any instance. Besides, dump() is more of a debugging aid to monitor how many instances exist. We should be spending our time deciding what process() does. When we first considered process() , we didn't know exactly what the function should do, so we wrote a stub function instead: template <class T> std::string apObjectInfo<T>::process (const std::string& command) { //TODO return ""; }
As the stub function indicates, a command string is sent to process() for processing and any result is returned as a string. Both the argument and return type are strings, because we want to keep the interface very generic. Using strings comes at a price, because the command string must be parsed each time to decide what to do. Writing a generic parsing routine isn't difficult. We place it in a class, apStringTools , to serve as a namespace for similar string functions. Our parsing function takes a string and a list of terminator characters and returns two strings: one containing the next token in the string, and the other containing the remaining string data. The header file contains: typedef struct apToken { std::string parsed; std::string remainder; } apToken; class apStringTools { public: ... static apToken sParse (const std::string& str, const std::string& term = sStandardTerm); static std::string sStandardTerm; // Standard terminators (space, tab, newline) }; Our implementation uses only std::string functions to accomplish the parsing. The find_first_of() and find_first_not_of() methods are used to determine where the next token is located, and substr() divides the string into two pieces, as shown: // Note. The first character in the string is a space std::string apStringTools::sStandardTerm = " \t\r\n"; apToken apStringTools::sParse (const std::string& str, const std::string& term) { apToken result; // Skip over leading terminators size_t start = str.find_first_not_of (term); if (start == str.npos) { // The entire string only contains terminator characters return result; } // Find the first command size_t end = str.find_first_of (term, start); if (end == str.npos) { result.parsed = str; return result; } // Extract the first command result.parsed = str.substr (start, end-start); // Return the rest of the string (after the terminators) size_t next = str.find_first_not_of (term, end); if (next != str.npos) result.remainder = str.substr (next); return result; } With this function, we can now write a simple command processor to parse our string. We support three functions.
A process() method to support these commands with simple if statements is shown here. template <class T> std::string apObjectInfo<T>::process (const std::string& command) { // Parse our command apToken token = apStringTools::sParse (command); INSTANCEMAP::iterator i; std::string result; // Our result string char buffer[16]; // Buffer for sprintf() if (token.parsed == "list") { // "list" Returns list of all instance addresses for (i=mapping_.begin(); i != mapping_.end(); ++i) { sprintf (buffer, "%x ", i->first); result += buffer; } } else if (token.parsed == "execute") { // "execute <command>" Send the remaining string to instances for (i=mapping_.begin(); i != mapping_.end(); ++i) { T* obj = reinterpret_cast<T*>(i->first); result += obj->process (token.remainder); result += " "; } } else if (token.parsed == "to") { // "to <instance> <command>" Send remaining string to a // specific instance. Matching is by string because the list // command returns a list of strings apToken instance = apStringTools::sParse (token.remainder); for (i=mapping_.begin(); i != mapping_.end(); ++i) { sprintf (buffer, "%x", i->first); if (instance.parsed == buffer) { T* obj = reinterpret_cast<T*>(i->first); result += obj->process (instance.remainder); } } } else { // Unknown command. Don't do anything } return result; } If you had a large number of commands to support, you could make the parsing faster by using some shortcuts. For example, we can rewrite the comparison portion of our previous example to group commands by their length, as shown: switch (token.parsed.size()) { case 2: if (token.parsed == "to") { // 'to' processing } break; case 4: if (token.parsed == "list") { // 'list' processing } break; case 7: if (token.parsed == "execute") { // 'execute' processing } break; default: } This example may look unimpressive, but imagine what would happen if you had 50 commands and implemented process() with this style. Instead of performing 50 comparisons in the worst case, you would probably perform no more than 10 to 15. Perhaps a better solution when you have many commands to process is to use a std::map object to map the command name (a string) to a function or object that handles the request. This solution is beyond the scope of this book, but the idea is to define the following inside apObjectInfo<> : std::map<std::string /*command*/, apCommandProcessor*> mapping_; We have not defined apCommandProcessor , but we would derive one object from apCommandProcessor for every command we want to handle. Once mapping_ is built with the data, either during static initialization or by means of an initialization function, it can be used to start processing commands. Before going any further, let us review how using templates has drastically improved the design. Before templates, we might have used macros to construct the equivalent of the apObjectInfo<> object. Macros are workable for short definitions, but for anything longer than a few lines, they can be difficult to follow and maintain. For example, a macro to declare, but not define the object, is as shown. #define CREATEINSTANCECLASS(classname) \ class apObjectInfo_##classname : public apObjectInfoBase \ { \ public: \ static apObjectInfo_##classname gOnly (); \ virtual std::string process (const std::string& command); \ virtual std::string dump (); \ private: \ static apObjectInfo_##classname* sOnly_; \ apObjectInfo_##classname (); \ }; To create an object similar to apObjectInfo<T> , we do as follows: CREATEINSTANCECLASS(T); where T is the name of the object of which you want to track the instances. This creates an object apObjectInfo_T . Another macro is still needed to supply the definition of the object. If templates did not exist, we would still exploit macros to avoid duplicate code. It is our experience that writing a macro for the first time is not too difficult, especially if you already have the class design. The real trouble begins when you later try to extend or correct problems with it. This happens because it is hard to visualize the function when it is written in macro format. The merging operator inside macros (i.e., ## ) also reduces the readability a great deal. We have two more pieces to go. apObjectInfo<> contains information about each instance of a particular object. We still need a way to keep track of each apObjectInfo<> in existence. This is also a singleton object, which represents the overall object registry: class apObjectMgr { public: typedef std::map<std::string, apObjectInfoBase*> OBJMAP; static apObjectMgr& gOnly (); std::string dump (); // Text dump of all objects in use void debugMessage (const std::string& header, const std::string& msg); // Generate a debug message to cdebug void add (const std::string& name, apObjectInfoBase* obj); // Add an object to our list apObjectInfoBase* find (const std::string& name); // Returns a pointer to a specific apObjectInfoBase, or 0 private: static apObjectMgr* sOnly_; apObjectMgr (); OBJMAP mapping_; // List of all managed classes }; mapping_ takes the name of an object to a pointer and maps it to the singleton object that manages it. This is not a pointer to an apObjectInfo<> class, but to its base class, apObjectInfoBase . debugMessage() is a general purpose function that you can use to write to the cdebug stream. It does nothing more than write a header (which is particular to an object type) and a message, as shown here. void apObjectMgr::debugMessage (const std::string& header, const std::string& msg) { cdebug << header.c_str() << msg.c_str() << std::endl;} The add() method adds a new object type to our registry. We can see how it is used by looking at the apObjectInfo<> constructor: apObjectInfo<T>::apObjectInfo<T> () { // Setup our object name. This is compiler and platform // dependent so this function can be modified to create // a more uniform string name_ = typeid(T).name(); // Add this class to our apObjectMgr list apObjectMgr::gOnly().add (name_, this); } Since apObjectInfo<> is a singleton object, this constructor only runs once. We use typeid() to specify the object name to use in the registry. Keep in mind that typeid() is compiler and platform dependent so the value of this string may surprise you. For example: in Microsoft Visual Studio on a Windows platform, using typeid() for an object, apTest , returns class apTest . On a FreeBSD system using gcc (version 2.95.3), it returns 6apTest . For our purposes this is fine because the string is unique on any platform. There is no subtract() method in this object, because once an object is first constructed, it always stays in mapping_ . Our singleton object is only destroyed when the application closes , so there is no need to remove an item from our map. find() does nothing more than return a specific pointer to an apObjectInfo<> object, as shown here. apObjectInfoBase* apObjectMgr::find (const std::string& name) { OBJMAP::iterator i = mapping_.find (name); if (i == mapping_.end()) return 0; return i->second; } In many applications, find() is not needed, since you can deal directly with a specific instance of apObjectInfo<> (for example, apObjectInfo<apTest> ). apObjectMgr has a minimalistic design. For example, if you wanted to send a command to the command processor of each object manager (which will in turn send it to each instance), you could add a method such as this: std::string apObjectMgr::process (const std::string& command) { std::string result; OBJMAP::iterator i; for (i=mapping_.begin(); i != mapping_.end(); ++i) { result += i->second->process (command); result += " "; } return result; } Now that we have a top-level registry object, as well as one that can track all the instances of an object, we need to add some functionality to the objects themselves . We do this by creating a base class for all objects that need debugging. By writing it as a template class, the compiler will enforce the data types for us. We will keep the interface very simple. template <class T> class apObject { public: enum eOptions {eNone=0, eTrackInstance=1}; apObject (eOptions options = eTrackInstance); virtual ~apObject (); int debug () { return apObjectInfo<T>::gOnly().debug();} void debug (int d) { apObjectInfo<T>::gOnly().debug(d);} bool isDebug (int level) { return apObjectInfo<T>::gOnly().isDebug(level);} // Interface to apObjectInfo<T> to simplify our code void debugMessage (const std::string& msg); // Output a debug Message. virtual std::string header () const; // The header string printed before any debugging messages virtual std::string process (const std::string& command); // Command processor for a specific instance }; Objects that you write will derive from apObject<> , so it helps to remember this when you decide what functionality apObject<> should have. Although we assume that all object instances of a particular object type will use this debugging interface, we can exclude certain objects from our object list by passing eNone to the constructor. The constructor and destructor are shown here. template <class T> apObject<T>::apObject (eOptions options) { // Add ourself to our instance list if enabled if (options & eTrackInstance) apObjectInfo<T>::gOnly().addInstance (this); } template <class T> apObject<T>::~apObject () { apObjectInfo<T>::gOnly().removeInstance (this);} The methods debug() and isDebug() are simple wrappers to the corresponding methods in apObjectInfo<> . debugMessage() is a wrapper function that sends a message and header, via header() , to our debugging stream. template <class T> void apObject<T>::debugMessage (const std::string& msg) { apObjectMgr::gOnly().debugMessage (header(), msg); } template <class T> std::string apObject<T>::header () const { const T* obj = static_cast<const T*> (this); char buffer[32]; sprintf (buffer, " (0x%0x): ", obj); std::string h = apObjectInfo<T>::gOnly().name(); h += buffer; return h; } process() is the method most objects should override. When we showed a sample command processor earlier, we defined an execute command to send a string to all object instances. process() is the method that will receive that string, do some processing, and return a result string. process() is not a pure virtual function, and will return an empty string if not overridden. You can see an example where process() is overridden to output a debugging string in the unit test for debugging on the CD-ROM. Our debugging registry is somewhat heavy, in that there are many template objects that are created to manage the interface. This registry is not designed to be used by all objects in a system. Rather, it is suitable for higher-level objects that are complex or contain a lot of information, such as an image object. Often there will be from just a couple to a few hundred instances of an image in existence at any one time. All told, there may be no more than ten to twenty objects that require this type of interface. You certainly do not want or need this interface for a simple class like: class apSum { public: apSum : sum_ (0) {} void sum (double d) { sum_ += d;} double sum () const { return sum_;} private: double sum_; }; |


EAN: 2147483647
Pages: 59
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter XI User Satisfaction with Web Portals: An Empirical Study
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVII Internet Markets and E-Loyalty