Unsafe Code
 | |||||||||||
| Chapter 4 - Advanced C# Topics | |
| bySimon Robinsonet al. | |
| Wrox Press 2002 | |
As we have just seen, C# is very good at hiding much of the basic memory management from the developer, thanks to the garbage collector and the use of references. However, there are cases in which you will want direct access to memory. This is most commonly for performance reasons, or because you wish to access a function in an external (non-.NET) DLL that requires a pointer to be passed as a parameter (as some Windows API functions do). Also, in some cases, you may wish to inspect memory contents for debugging purposes, or you may be writing an application such as a debugger that analyses other processes, and where the user needs direct access to memory. In this section, we will examine C#'s facilities that allow you to do this.
We should emphasize that although there are situations where you might need pointers, and we detail some of them below, they are really not that common. We would also strongly advise against using pointers unnecessarily, because if you do, your code will not only be harder to debug, but will fail the memory type-safety checks imposed by the CLR, which we discussed in Chapter 1. If you believe you have a good reason in the particular application you are developing for using pointers (the most likely reason is for backwards compatibility with some legacy code your application has to work with), then fine. Otherwise, you will usually find that using pointers is unnecessary. This advice particularly applies to ex-C++ developers who will be used to using pointers in C++ in a wide variety of situations. Pointers in C# are available in case you need them, but they are not needed nearly as often as they are in C++.
Pointers
Although we are introducing pointers as if they are a new topic, in reality pointers are not new to us at all, because we have been using references freely in our code, and a reference is simply a dressed-up pointer. We have already seen how variables that represent classes and arrays actually store the address in memory of where the corresponding data (the referent ) is actually stored. A pointer is simply a variable that stores the address of something else in the same way as a reference. The difference is that the C# syntax for reference does not allow you to access that address programmatically. With a reference, the variable is treated syntactically as if it stores the actual contents of the referent. If, say, the class instance referred to happened to be stored at memory location 0x334b38 , then there is no way that you could gain access to that number 0x334b38 using a reference.
C# references are designed that way to make the language simpler to use, and to prevent you from inadvertently doing something that corrupts the contents of memory, and possibly prevents the garbage collector from being able to do its job properly. With a pointer, on the other hand, the actual memory address is available to you. This gives you a lot of power to perform new kinds of operations. For example, you can add 4 bytes onto the address, so that you can examine or even modify whatever data happens to be stored 4 bytes further on.
There are three advantages to using pointers:
-
Performance - Provided you know what you are doing, you can ensure that the data is accessed or manipulated in the most efficient way possible - that is the reason why languages such as C and C++ have always allowed pointers.
-
Backwards compatibility - Remember that, despite all of the facilities provided by the .NET runtime, it is still possible to call the old Windows API functions if you wish to, and for some operations, this may be the only way to accomplish your task. These API functions are all written in C, a language that uses pointers extensively, which means that many of these functions take pointers as parameters. Third parties may also in the past have supplied DLLs containing functions that take pointer parameters. Having said all that, in many cases it is possible to write the DllImport declaration in a way that avoids use of pointers, for example, by using the System.IntPtr class.
-
You may need to make memory addresses available to the user - For example, if you are developing an application that provides some direct user interface to memory, such as a debugger).
However, this low-level memory access comes at various costs, in particular:
-
The syntax required to get this functionality is more complex.
-
Pointers are harder to use. You need very good programming skills and an excellent ability to think carefully and logically about what your code is doing in order to use them successfully. It is very easy to introduce subtle bugs to your program with pointers.
-
In particular, if you are not careful, it is easy to overwrite other variables, cause stack overflows, access some area of memory that doesn't store any variables as if it did, or even overwrite information about your code that is needed by the .NET runtime, thereby crashing your program.
-
For the case of .NET code, any use of pointers will cause the code to fail the .NET type safety checks, which, depending on your security policies, may cause the .NET Framework to refuse to execute the code.
Incidentally, not so many decades ago it was possible for careless use of pointers to crash not just your program, but also other programs running on the system - or in extreme cases, the entire operating system itself. These days, operating systems have much more security built in to prevent you from overwriting memory that belongs to other processes or to the operating system, and generally , it is now only your own process that is at risk from careless use of pointers.
Despite these risks, pointers remain a very powerful and flexible tool in the writing of efficient code, and are worth learning about.
Due to the risks associated with pointer use, C# only allows the use of pointers in blocks of code that you have specifically marked for this purpose. The keyword to do this is unsafe (if the previous discussion wasn't enough to warn you of the potential dangers of pointers, Microsoft has even chosen a keyword that reinforces the point!). You can mark an individual method as being unsafe like this:
unsafe int GetSomeNumber() { // code that can use pointers }
Any method can be marked as unsafe , irrespective of what other modifiers may have been applied to it (for example, static methods, or virtual methods ).
Or you can mark an entire class or struct as unsafe :
unsafe class MyClass { // any method in this class can now use pointers }
If you mark a class or struct as unsafe , all of its members are assumed to be unsafe.
Similarly, you can mark a field as unsafe :
class MyClass { unsafe int *pX; // declaration of a pointer field in a class }
Or you can mark a block of code within a method as unsafe :
void MyMethod() { // code that doesn't use pointers unsafe { // unsafe code that uses pointers here } // more 'safe' code that doesn't use pointers }
Note, however, that you cannot mark a local variable by itself as unsafe :
int MyMethod() { unsafe int *pX; // WRONG }
If you want to use an unsafe local variable, you will need to declare and use it inside a method or block statement that is unsafe. There is one more step before you can use pointers. The C# compiler will reject unsafe code unless you tell it that your code includes unsafe blocks. The flag to do this is unsafe . Hence, to compile a file named MySource.cs that contains unsafe blocks ( assuming no other compiler options), the command is:
csc /unsafe MySource.cs
or:
csc -unsafe MySource.cs
If you are using Visual Studio .NET, you will find the option to compile unsafe code in the project properties. For the Visual Studio .NET versions of the downloadable samples in this section, you will find that we have already set the unsafe compilation option.
Pointer Syntax
Once you have marked a block of code as unsafe , you can declare a pointer using this syntax:
int * pWidth, pHeight; double *pResult;
This code declares three variables. pWidth and pHeight are pointers to integers, and pResult is a pointer to a double . It is common practice to use the prefix p in front of names of pointer variables to indicate that they are pointers. When used in a variable declaration, the symbol * indicates that you are declaring a pointer, in other words, something that stores the address of a variable of the specified type.
| Important | C++ developers should beware that syntax is different in C#. The C# statement int *pX, pY; corresponds to the C++ statement int *pX, *pY; . In C#, the * symbol is associated with the type rather than the variable name . |
Once you have declared variables of pointer types, you can use them in the same way as normal variables, but first you need to learn two more operators:
-
& means 'take the address of', and converts a value data type to a pointer, for example int to *int . This operator is known as the address operator .
-
* means 'get the contents of this address', and converts a pointer to a value data type (for example, *float to float ). This operator is known as the indirection operator (or sometimes as the dereference operator ).
You will see from these definitions that & and * have the opposite effect to one another.
You might be wondering how it is possible to use the symbols & and * in this manner, since these symbols also refer to the operators of bitwise AND ( & ) and multiplication ( * ). Actually, it is always possible for both you and the compiler to know what is meant in each case, because with the new pointer meanings, these symbols always appear as unary operators - they only act on one variable and appear in front of that variable in your code. On the other hand, bitwise AND and multiplication are binary operators - they require two variables.
As examples of how to use these operators, consider this code:
int x = 10; int *pX, pY; pX = &x; pY = pX; *pY = 20;
We start off by declaring an integer, x , followed by two pointers to integers, pX and pY . We then set pX to point to x (in other words, we set the contents of pX to be the address of x ). Then we assign the value of pX to pY , so that pY also points to x . Finally, we change the contents of x to 20 - since pY happens to point to x , *pY will evaluate to x . So the statement *pY = 20; will result in the value of x being changed to 20 . Note that in all this code, there is no particular connection between the variables pY and x . It's just that at the present time, pY happens to point to the memory location at which x is held.
To understand what is going on further, let's suppose for the sake of argument that x is stored at memory locations 0x12F8C4 to 0x12F8C7 ( 1243332 to 1243335 in decimal) in the stack (there are 4 locations because an int occupies 4 bytes, and now we are choosing more realistic memory locations for our examples too). Since the stack allocates memory downwards, this means that the variables pX will be stored at locations 0x12F8C0 to 0x12F8C3 , and pY will end up at locations 0x12F8BC to 0x12F8BF . Note that pX and pY also occupy 4 bytes each. That is not because an int occupies 4 bytes. It's because on a 32-bit processor you need 4 bytes to store an address. With these addresses, after executing the above code, the stack would look like this:
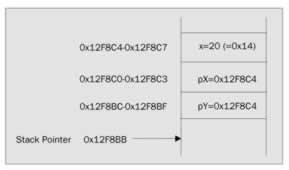
Although we have illustrated this process with int s, which will be stored consecutively on the stack on a 32-bit processor, this doesn't happen for all data types. The reason is that 32-bit processors work best retrieving data from memory in 4-byte chunks . Memory on such machines tends to be divided into 4-byte blocks, and each block is sometimes known under Windows as a DWORD because this was the name of a 32-bit unsigned int in pre .NET days. It is most efficient to grab DWORD s from memory - storing data across DWORD boundaries normally gives a hardware performance hit. For this reason, the .NET runtime normally pads out data types so that the memory they occupy is a multiple of 4. For example, a short occupies 2 bytes, but if a short is placed on the stack, the stack pointer will still be decremented by 4, not 2, so that the next variable to go on the stack will still start at a DWORD boundary.
You can declare a pointer to any value type, in other words, any of the predefined types uint , int , byte , and so on, or to a struct. However, it is not possible to declare a pointer to a class or array; this is because doing so could cause problems for the garbage collector. In order to work properly, the garbage collector needs to know exactly what class instances have been created on the heap, and where they are, but if your code started manipulating classes using pointers, you could very easily corrupt the information on the heap concerning classes that the .NET runtime maintains for the garbage collector. In this context, any data type that the garbage collector can access is known as a managed type . Pointers can only be declared as unmanaged types since the garbage collector cannot deal with them.
Casting Pointers to Integer Types
Since a pointer really stores an integer that represents an address, you won't be surprised to know that the address in any pointer can be explicitly converted to or from any integer type. For example, it is perfectly legitimate to write the following:
int x = 10; int *pX, pY; pX = &x; pY = pX; *pY = 20; uint y = (uint)pX; int *pD = (int*)y; y will now be a uint . We have then converted this quantity back to an int* , stored in the new variable pD . Hence, pD also points to the original value of x .
One reason for casting a pointer value to an integer type is in order to display it. The Console.Write() and Console.WriteLine() methods do not have any overloads that can take pointers, but will accept and display pointer values that have been cast to integer types:
Console.WriteLine("Address is" + pX); // wrong - will give a // compilation error Console.WriteLine("Address is" + (uint) pX); // OK
Note that you can legally cast a pointer to any of the integer types. However, since an address occupies 4 bytes on 32-bit systems, casting a pointer to anything other than a uint , long , or ulong is almost certain to lead to overflow errors, and is therefore probably not a good idea. (An int can also cause problems, because its range is from roughly -2 billion to 2 billion, whereas an address runs from zero to about 4 billion). When C# is released for 64-bit processors, an address will occupy 8 bytes. Hence, on such systems, casting a pointer to anything other than ulong is likely to lead to overflow errors. It is also important to be aware that the checked keyword does not apply to conversions involving pointers. For such conversions, exceptions will not be raised when overflows occur, even in a checked context. The .NET runtime assumes that if you are using pointers you probably know what you are doing and are happy about the overflows!
Pointer-to-integer-type conversions must be explicit. Implicit conversions are not available for such conversions.
Casting Between Pointer Types
You can also explicitly convert between pointers pointing to different types. For example:
byte aByte = 8; byte *pByte= &aByte; double *pDouble = (double*)pByte;
This is perfectly legal code, though again, if you try something like this, be careful. With the above example, if we look up the double pointed to by pDouble , we will actually be looking up some memory that contains a byte, combined with some other memory, and treating it as if this area of memory contained a double, which won't give a meaningful value. However, you might want to convert between types in order to implement a union, or you might want to cast pointers to other types into pointers to sbyte in order to examine individual bytes of memory.
void Pointers
If you wish to maintain a pointer, but do not wish to specify what type of data it points to, you can declare it as a pointer to a void :
void *pointerToVoid; pointerToVoid = (void*)pointerToInt; // pointerToInt declared as int*
The main use of this is if you need to call any API functions that require void* parameters. Within the C# language, there isn't a great deal that you can do using void pointers. In particular, the compiler will flag an error if you attempt to dereference a void pointer using the * operator.
The sizeof Operator
Throughout this section, we have been referring to the sizes of various data types. If you need to explicitly use the size of a type in your code, you can use the sizeof operator, which takes the name of a data type as a parameter, and returns the number of bytes occupied by that type. For example:
int x = sizeof(double); This will set x to the value 8 .
The advantage of using sizeof is that you don't have to remember the sizes of particular types, and you can be certain the value you are using in your program is correct. For the predefined data types, sizeof returns the following values:
| sizeof(sbyte) = 1; | sizeof(byte) = 1; |
| sizeof(short) = 2; | sizeof(ushort) = 2; |
| sizeof(int) = 4; | sizeof(uint) = 4; |
| sizeof(long) = 8; | sizeof(ulong) = 8; |
| sizeof(char) = 2; | sizeof(float) = 4; |
| sizeof(double) = 8; | sizeof(bool) = 1; |
You can also use sizeof for structs that you define yourself, though in that case, the result will depend on what fields are in the struct. You cannot use sizeof for classes.
PointerPlayaround Example
We are now ready to present an example that uses pointers. The following code is a sample that I have named PointerPlayaround . It does some simple pointer manipulation and displays the results, allowing us to see for ourselves what is happening in memory and where variables are stored:
using System; namespace Wrox.ProCSharp.AdvancedCSharp { class MainEntryPoint { static unsafe void Main() { int x=10; short y = -1; byte y2 = 4; double z = 1.5; int *pX = &x; short *pY = &y; double *pZ = &z; Console.WriteLine( "Address of x is 0x{0:X}, size is {1}, value is {2}", (uint)&x, sizeof(int), x); Console.WriteLine( "Address of y is 0x{0:X}, size is {1}, value is {2}", (uint)&y, sizeof(short), y); Console.WriteLine( "Address of y2 is 0x{0:X}, size is {1}, value is {2}", (uint)&y2, sizeof(byte), y2); Console.WriteLine( "Address of z is 0x{0:X}, size is {1}, value is {2}", (uint)&z, sizeof(double), z); Console.WriteLine( "Address of pX=&x is 0x{0:X}, size is {1}, value is 0x{2:X}", (uint)&pX, sizeof(int*), (uint)pX); Console.WriteLine( "Address of pY=&y is 0x{0:X}, size is {1}, value is 0x{2:X}", (uint)&pY, sizeof(short*), (uint)pY); Console.WriteLine( "Address of pZ=&z is 0x{0:X}, size is {1}, value is 0x{2:X}", (uint)&pZ, sizeof(double*), (uint)pZ); *pX = 20; Console.WriteLine("After setting *pX, x = {0}", x); Console.WriteLine("*pX = {0}", *pX); pZ = (double*)pX; Console.WriteLine("x treated as a double = {0}", *pZ); Console.ReadLine(); } } }
This code declares three value variables:
-
An int x
-
A short y
-
A double z
as well as pointers to these values. Then, we display the values of all these variables as well as their sizes and addresses. Note that in taking the address of pX , pY , and pZ , we are effectively looking at a pointer to a pointer - an address of an address of a value! Notice that, in accordance with usual practice when displaying addresses, we have used {0:X} format specifier in the Console.WriteLine() commands to ensure that memory addresses are displayed in hexadecimal format.
Finally, we use the pointer pX to change the value of x to 20 , and do some pointer casting to see what rubbish results if we try to treat the content of x as if it was a double!
Compiling and running this code results in this output. In this screen output we have demonstrated the effects of attempting to compile both with and without the /unsafe flag:
csc PointerPlayaround.cs Microsoft (R) Visual C# .NET Compiler version 7.00.9466 for Microsoft (R) .NET Framework version 1.0.3705 Copyright (C) Microsoft Corporation 2001. All rights reserved. PointerPlayaround.cs(7,26): error CS0227: Unsafe code may only appear if compiling with /unsafe csc /unsafe PointerPlayaround.cs Microsoft (R) Visual C# .NET Compiler version 7.00.9466 for Microsoft (R) .NET Framework version 1.0.3705 Copyright (C) Microsoft Corporation 2001. All rights reserved. PointerPlayaround Address of x is 0x12F8C4, size is 4, value is 10 Address of y is 0x12F8C0, size is 2, value is -1 Address of y2 is 0x12F8BC, size is 1, value is 4 Address of z is 0x12F8B4, size is 8, value is 1.5 Address of pX=&x is 0x12F8B0, size is 4, value is 0x12F8C4 Address of pY=&y is 0x12F8AC, size is 4, value is 0x12F8C0 Address of pZ=&z is 0x12F8A8, size is 4, value is 0x12F8B4 After setting *pX, x = 20 *pX = 20 x treated as a double = 2.63837073472194E-308
Checking through these results confirms our description of how the stack operates, which we gave in the Memory Management Under the Hood section, earlier in the chapter. It allocates successive variables moving downwards in memory. Notice how it also confirms that blocks of memory on the stack are always allocated in multiples of 4 bytes. For example, y is a short (of size 2), and has the address 1243328 , indicating that the memory locations reserved for it are locations 1243328 - 1243331 . If the .NET runtime had been strictly packing variables up next to each other, then Y would have occupied just the two locations 1243328 - 1243329 .
Pointer Arithmetic
It is possible to add or subtract integers to and from pointers. However, the compiler is quite clever about how it arranges for this to be done. For example, suppose you have a pointer to an int , and you try to add 1 on to its value. The compiler will assume you actually mean you want to look at the memory location following the int , and so will actually increase the value by 4 bytes - the size of an int . If it is a pointer to a double , adding 1 will actually increase the value of the pointer by 8 bytes, the size of a double . Only if the pointer points to a byte or sbyte (1 byte each) will adding 1 to the value of the pointer actually change its value by 1.
You can use the operators + , - , += , -= , ++ , and -- with pointers, with the variable on the right-hand side of these operators being a long or ulong .
Note that it is not permitted to carry out arithmetic operations on void pointers.
For example, let's assume these definitions:
uint u = 3; byte b = 8; double d = 10.0; uint *pUint= &u; // size of a uint is 4 byte *pByte = &b; // size of a byte is 1 double *pDouble = &d; // size of a double is 8
and let's assume the addresses to which these pointers point are:
-
pUint : 1243332
-
pByte : 1243328
-
pDouble : 1243320
After executing this code:
++pUint; // adds 1= 4 bytes to pUint pByte -= 3; // subtracts 3=3bytes from pByte double *pDouble2 = pDouble - 4; // pDouble2 = pDouble - 32 bytes (4*8 bytes)
the pointers will contain:
-
pUint : 1243336
-
pByte : 1243321
-
pDouble2 : 1243328
Important The general rule is that adding a number X to a pointer to type T with value P gives the result P + X*(sizeof(T) ).
You need to be careful of this rule. If successive values of a given type are stored in successive memory locations, then pointer addition works very well to allow you to move pointers between memory locations. If you are dealing with types such as byte or char though, whose sizes are not multiples of 4, successive values will not by default be stored in successive memory locations.
You can also subtract one pointer from another pointer, provided both pointers point to the same data type. In this case, the result is a long whose value is given by the difference between the pointer values divided by the size of the type that they represent:
double *pD1 = (double*)1243324; // note that it is perfectly valid to // initialize a pointer like this. double *pD2 = (double*)1243300; long L = pD1-pD2; // gives the result 3 (=24/sizeof(double))
Pointers to Structs - The Pointer Member Access Operator
We have not yet seen any examples of pointers that point to structs. In fact, pointers to structs work in exactly the same way as pointers to the predefined value types. There is, however, one condition - the struct must not contain any reference types. This is due to the restriction we mentioned earlier that pointers cannot point to any reference types. To avoid this, the compiler will flag an error if you create a pointer to any struct that contains any reference types.
Suppose we had a struct defined like this:
struct MyGroovyStruct { public long X; public float F; }
then we could define a pointer to it like this:
MyGroovyStruct *pStruct; and initialize it like this:
MyGroovyStruct Struct = new MyGroovyStruct(); pStruct = &Struct;
It is also possible to access member values of a struct through the pointer:
(*pStruct).X = 4; (*pStruct).F = 3.4f;
However, this syntax looks a bit complex. For this reason, C# defines another operator that allows you to access members of structs through pointers with a simpler syntax. It is known as the pointer member access operator , and the symbol is a dash followed by a greater than sign, so it looks like an arrow: - >.
C++ developers will recognize the pointer member access operator, since C++ uses the same symbol for the same purpose.
Using the pointer member access operator, the above code can be rewritten:
pStruct->X = 4; pStruct->F = 3.4f;
You can also directly set up pointers of the appropriate type to point to fields within a struct:
long *pL = &(Struct.X); float *pF = &(Struct.F);
or, equivalently:
long *pL = &(pStruct->X); float *pF = &(pStruct->F);
Although these expressions also look syntactically rather complex, there is no equivalent of the - > operator to help us out here.
Pointers to Class Members
We have indicated that it is not possible to create pointers to classes. That's because the garbage collector does not maintain any information about pointers, only about references, so creating pointers to classes could cause garbage collection to not work properly.
However, most classes do contain members that are themselves of value types, and you might wish to create pointers to them. This is possible, but requires a special syntax. For example, suppose we rewrite our struct from our previous example as a class:
class MyGroovyClass { public long X; public float F; }
Then you might wish to create pointers to its fields, X and F , in the same way as before. Unfortunately, doing so will produce a compilation error:
MyGroovyClass myGroovyObject = new MyGroovyClass(); long *pL = &( myGroovyObject.X); // wrong float *pF = &( myGroovyObject.F); // wrong
So what's the problem? We are, after all, declaring pointers of perfectly legitimate types here - long* and float* . What is wrong is that although X and F are themselves unmanaged types, they are embedded in a class, which sits on the heap. This means that they are still indirectly under the control of the garbage collector. In particular, the garbage collector may at any time kick in and decide to move MyGroovyClass to a new location in memory in order to tidy up the heap. If it does that, then the garbage collector will of course update all references to the object, so that for example, the variable myGroovyObject will still point to the correct location. However, the garbage collector doesn't know about what pointers might be around, so if it moves the object referred to by myGroovyObject , pL and pF will still be unchanged and will end up pointing to the wrong memory locations. As a result of the risk of this problem, the compiler will not let you assign addresses of members of managed types to pointers in this manner.
The way round this problem is to use a new fixed keyword, which tells the garbage collector that there may be pointers pointing to members of certain class instances, and so those instances must not be moved. The syntax for using fixed looks like this if we just want to declare one pointer:
MyGroovyClass myGroovyObject = new MyGroovyClass(); // do whatever fixed (long *pObject = &( myGroovyObject.X)) { // do something }
In other words, we mark out a block of code as fixed . The block of code is bounded by braces, while in round brackets we define and initialize the pointer that we want to point to a class member. This pointer variable ( pObject in the example) will now be scoped to the fixed block, and the garbage collector will then know not to move the instance myGroovyObject of MyGroovyClass while the code inside the fixed block is executing.
If you want to declare more than one such pointer, you can place multiple fixed statements before the same code block:
MyGroovyClass myGroovyObject = new MyGroovyClass(); fixed (long *pX = &( myGroovyObject.X)) fixed (float *pF = &( myGroovyObject.F)) { // do something }
You can nest entire fixed blocks if you wish to fix several pointers for different periods:
MyGroovyClass myGroovyObject = new MyGroovyClass(); fixed (long *pX = &( myGroovyObject.X)) { // do something with pX fixed (float *pF = &( myGroovyObject.F)) { // do something else with pF } }
You can also initialize several variables within the same fixed block, provided they are of the same type:
MyGroovyClass myGroovyObject = new MyGroovyClass(); MyGroovyClass myGroovyObject2 = new MyGroovyClass(); fixed (long *pX = &( myGroovyObject.X), pX2 = &( myGroovyObject2.X)) { // etc.
In all these cases, it is immaterial whether the various pointers you are declaring point to fields in the same or different instances of classes, or to static fields not associated with any class instance.
Adding Classes and Structs to our Example
In this section, we will illustrate pointer arithmetic, as well as pointers to structs and classes, using a second example, which we will imaginatively title PointerPlayaround2 . To start off, we will return to our earlier Currency struct we introduced in the section titled User-Defined Casts , and define a class and a struct that each represent a Currency . These types are similar to the Currency struct that we defined earlier, but simpler and with slightly different fields:
struct CurrencyStruct { public long Dollars; public byte Cents; public override string ToString() { return "$" + Dollars + "." + Cents; } } class CurrencyClass { public long Dollars; public byte Cents; public override string ToString() { return "$" + Dollars + "." + Cents; } }
There is nothing significant about our choice of Currency for the struct and class, except to make our example look a bit less abstract and more realistic. Note also that CurrencyStruct and CurrencyClass are identical, aside from CurrencyStruct being a struct, and CurrencyClass being a class. This is just so we can demonstrate using pointers with both types of object.
Now we have our struct and class defined, we can apply some pointers to them. Here is the code for the new example. Since the code is fairly long, we will go through it in detail. We start off by displaying the size of the Currency struct, creating a couple of instances of it along with some pointers, and we use these pointers to initialize one of the Currency structs, amount1 . Along the way we display the addresses of our variables:
public static unsafe void Main() { Console.WriteLine( "Size of Currency struct is " + sizeof(CurrencyStruct)); CurrencyStruct amount1, amount2; CurrencyStruct *pAmount = &amount1; long *pDollars = &(pAmount->Dollars); byte *pCents = &(pAmount->Cents); Console.WriteLine("Address of amount1 is 0x{0:X}", (uint)&amount1); Console.WriteLine("Address of amount2 is 0x{0:X}", (uint)&amount2); Console.WriteLine("Address of pAmt is 0x{0:X}", (uint)&pAmount); Console.WriteLine("Address of pDollars is 0x{0:X}", (uint)&pDollars); Console.WriteLine("Address of pCents is 0x{0:X}", (uint)&pCents); pAmount->Dollars = 20; *pCents = 50; Console.WriteLine("amount1 contains " + amount1);
Now we do some pointer manipulation that relies on our knowledge of how the stack works. Due to the order in which the variables were declared, we know that amount2 will be stored at an address immediately below amount1 . sizeof(CurrencyStruc) returns 16 (as demonstrated in the screen output coming up), so CurrencyStruct occupies a multiple of 4 bytes. Therefore, after we decrement our currency pointer, it will point to amount2 :
--pAmount; // this should get it to point to amount2 Console.WriteLine("amount2 has address 0x{0:X} and contains {1}", (uint)pAmount, *pAmount);
This Console.WriteLine() statement is interesting. We have displayed the contents of amount2 , but we haven't yet initialized it to anything! What gets displayed will be random garbage - whatever happened to be stored at that location in memory before execution of the sample. There is an important point here, though. Normally, the C# compiler would prevent us from using an uninitialized value, but when you start using pointers, it is very easy to circumvent all the usual compilation checks. In this case we have done so because the compiler has no way of knowing that we are actually displaying the contents of amount2 . Only we know that, because our knowledge of the stack means we can tell what the effect of decrementing pAmount will be. Once you start doing pointer arithmetic, you find you can access all sorts of variables and memory locations that the compiler would usually stop you from accessing, hence the description of pointer arithmetic as unsafe.
Next in our sample, we do something else that is equally cheeky. We do some pointer arithmetic on our pCents pointer. pCents currently points to amount1.Cents , but our aim here is to get it to point to amount2.Cents , again using pointer operations instead of directly telling the compiler that's what we want to do. Since to do this we need to decrement the address it contains by sizeof(Currency) , we need to do some casting to get the arithmetic to work out:
// do some clever casting to get pCents to point to cents // inside amount2 CurrencyStruct *pTempCurrency = (CurrencyStruct*)pCents; pCents = (byte*) ( --pTempCurrency ); Console.WriteLine("Address of pCents is now 0x{0:X}", (uint)&pCents);
Finally, we use the fixed keyword to create some pointers that point to the fields in a class instance, and use these pointers to set the value of this instance. Notice that this is also the first time that we have been able to look at the address of an item that is stored on the heap rather than the stack:
Console.WriteLine("\nNow with classes"); // now try it out with classes CurrencyClass amount3 = new CurrencyClass(); fixed(long *pDollars2 = &(amount3.Dollars)) fixed(byte *pCents2 = &(amount3.Cents)) { Console.WriteLine( "amount3.Dollars has address 0x{0:X}", (uint)pDollars2); Console.WriteLine( "amount3.Cents has address 0x{0:X}", (uint) pCents2); *pDollars2 = -100; Console.WriteLine("amount3 contains " + amount3); }
Running this code gives this output:
csc /unsafe PointerPlayaround2.cs Microsoft (R) Visual C# .NET Compiler version 7.00.9466 for Microsoft (R) .NET Framework version 1.0.3705 Copyright (C) Microsoft Corporation 2001. All rights reserved. PointerPlayaround2 Size of Currency struct is 16 Address of amount1 is 0x12F8A8 Address of amount2 is 0x12F898 Address of pAmt is 0x12F894 Address of pDollars is 0x12F890 Address of pCents is 0x12F88C amount1 contains .50 amount2 has address 0x12F898 and contains 40121818976080.102 Address of pCents is now 0x12F88C Now with classes amount3.Dollars has address 0xBA4960 amount3.Cents has address 0xBA4968 amount3 contains $-100.0
These results were obtained using the first release version of the .NET Framework. You may find that the actual addresses displayed are different if you run the sample on a different version of .NET.
Notice in this output the uninitialized value of amount2 that we display, and that the size of the Currency struct is 16 - somewhat larger than we would expect given the sizes of its fields (1 long = 8 + 1 byte = 1). Evidently, some more word alignment is going on here. We can also see from this code the typical value of addresses on the heap: 12272624 = 0xBB43F0 . The heap clearly exists in a very different area of the virtual address space from the stack.
Using Pointers to Optimize Performance
Up to now, we have spent a lot of time looking at the various things that you can do with pointers, but in all our examples so far, we haven't really seen anything that would be very useful in many real applications. All we have done up to now essentially is to play around with memory in a way that is probably interesting to people who like to know what's happening under the hood, but doesn't really help us to write very good code. That's going to change in this section. Here we're going to apply our understanding of pointers and demonstrate an example in which judicious use of pointers will have a significant performance benefit.
Creating Stack-Based Arrays
In this section, we are going to look at the other main area in which pointers can be very useful; creating high performance, low overhead arrays on the stack. We showed in Chapter 2 how C# includes rich support for handling arrays. While C# makes it very easy to use both one dimensional and rectangular or jagged multidimensional arrays, it suffers from the disadvantage that these arrays are actually objects; they are instances of System.Array . This means that the arrays are stored on the heap with all of the overhead that it involves. There may be occasions when you just want to create an array for a short period of time and don't want the overhead of reference objects. It is possible to do this using pointers, although only for one-dimensional arrays.
In order to create a high-performance array we need another keyword, stackalloc . The stackalloc command instructs the .NET runtime to allocate a certain amount of memory on the stack. When you call it, you need to supply it with two pieces of information:
-
The type of variable you want to store
-
How many of these variables you need to store
As an example, to allocate enough memory to store 10 decimal s, you would write this:
decimal *pDecimals = stackalloc decimal [10]; Note that this command simply allocates the memory. It doesn't attempt to initialize it to any value - it is up to you to do that. The idea is that this is an ultra -high performance array, and initializing values unnecessarily would hurt performance.
Similarly, to store 20 double s you would write this:
double *pDoubles = stackalloc double [20]; Although this line of code specifies the number of variables to store as a constant, this can equally be a quantity evaluated at run-time. So you could equally write the second example above like this:
int size; size = 20; // or some other value calculated at run-time double *pDoubles = stackalloc double [size];
You will see from these code snippets that the syntax of stackalloc is slightly unusual. It is followed immediately by the name of the data type you want to store (and this must be a value type), and then by the number of variables you need space for in square brackets. The number of bytes allocated will be this number multiplied by sizeof(data type) . The use of square brackets here suggests an array, which isn't too surprising, because if you have allocated space for, say, 20 double s, then effectively what you have is an array of 20 double s. The simplest, most basic type of array that it is possible to have is a block of memory that stores one element after another, like this:
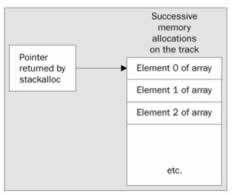
In this diagram, we have also shown the pointer returned by stackalloc , which always returns a pointer to the allocated data type, and sets this return value so that the pointer points to the start of the memory allocated.
The next question is how you use the memory you have just obtained. Carrying on our example, we have just said that the return value from stackalloc points to the start of the memory. It therefore follows that you can get to the first location of allocated memory by dereferencing that pointer. So, for example, to allocate our double s and then set the first element (that is, element 0 of the array) to the value 3.0 , you could write this:
double *pDoubles = stackalloc double [20]; *pDoubles = 3.0; What about the next element? This is where the pointer arithmetic that we learned earlier comes in. Recall that if you syntactically add 1 to a pointer, its value will actually be increased by the size of whatever data type it points to. In this case, this will be just enough to take us to the next free memory location in the block that we have allocated. So, we can set the second element of a block (that is to say, element number 1 of the array, since we always count arrays from zero) like this:
double *pDoubles = stackalloc double [20]; *pDoubles = 3.0; *(pDoubles+1) = 8.4; And by the same reasoning in general, we can obtain the element with index X of the array with the expression *(pDoubles+X) .
That's good as far as it goes - we effectively have a means by which we can access elements of our array, but for general purpose use, having to use that kind of syntax to get to array elements isn't going to win many friends . Fortunately, C# defines an alternative syntax. The way it works is that C# gives a very precise meaning to square brackets when they are applied to pointers. In general, if the variable p is any pointer type and X is any numeric type, then in C#, the expression p[X] is always interpreted by the compiler as meaning *(p+X) . This is actually true in general - the pointer p doesn't need to have been initialized using stackalloc . And with this shorthand notation, we now have a very convenient syntax for accessing our array. In fact, it means that we have exactly the same syntax for accessing stack-based arrays as we do for accessing heap based arrays that are represented by the System.Array class:
double *pDoubles = stackalloc double [20]; pDoubles[0] = 3.0; // pDoubles[0] is the same as *pDoubles pDoubles[1] = 8.4; // pDoubles[1] is the same as *(pDoubles+1)
This idea of applying array syntax to pointers isn't new. It has been a fundamental part of both the C and the C++ languages ever since those languages were invented. Indeed, C++ developers will recognize the stack based arrays we can obtain using stackalloc as being essentially identical to classic stack-based C and C++ arrays. It is this syntax and the way it links pointers and arrays which was one of the reasons why the C language became popular back in the '70s, and the main reason why the use of pointers became such a popular programming technique in C and C++.
Although our high-performance array can be accessed in the same way as a normal C# array, we do need to point out one word of warning. The following code in C# will raise an exception:
double [] myDoubleArray = new double [20]; myDoubleArray[50] = 3.0;
The exception occurs for the obvious reason that we are trying to access an array using an index that is out of bounds (the index is 50 , maximum allowed value is 19 ). However, if you declare the equivalent array using stackalloc , there is now no object wrapped around the array that can do any bounds checking. Hence, the following code will not raise an exception:
double *pDoubles = stackalloc double [20]; pDoubles[50] = 3.0;
In this code, we allocate enough memory to hold 20 doubles. Then we set sizeof(double) memory locations starting at the location given by the start of this memory + 50*sizeof(double) to hold the double value 3.0 . Unfortunately, that memory location is way outside the area of memory that we have allocated for the double s. And who knows what data might be stored at that address? At best, we may have 'merely' corrupted the value of another variable, but it is equally possible for example that we may have just overwritten some locations in the stack that were being used to store the return address from the method currently being executed - the address that tells the computer where to carry on from when the method returns. In this case, the future execution path of our program is going to be, shall we say, novel ! Once again, we see that the high performance to be gained from pointers comes at a cost; you need to be certain you know what you are doing, or you will get some very strange run-time bugs.
QuickArray Example
We will round off our discussion about pointers with a stackalloc example called QuickArray . In this example, the program simply asks the user how many elements they want to be allocated for an array. The code then uses stackalloc to allocate an array of long s that size. The elements of this array are populated with the squares of the integers starting from 0 and the results displayed on the console:
using System; namespace Wrox.ProCSharp.AdvancedCSharp { class MainEntryPoint { static unsafe void Main() { Console.Write("How big an array do you want? \n> "); string userInput = Console.ReadLine(); uint size = uint.Parse(userInput); long *pArray = stackalloc long [(int)size]; for (int i=0 ; i<size ; i++) pArray[i] = i*i; for (int i=0 ; i<size ; i++) Console.WriteLine("Element {0} = {1}", i, *(pArray+i)); } } }
QuickArray How big an array do you want? > 15 Element 0 = 0 Element 1 = 1 Element 2 = 4 Element 3 = 9 Element 4 = 16 Element 5 = 25 Element 6 = 36 Element 7 = 49 Element 8 = 64 Element 9 = 81 Element 10 = 100 Element 11 = 121 Element 12 = 144 Element 13 = 169 Element 14 = 196
EAN: 2147483647
Pages: 244