Section 3.5. Information Interaction
3.5. Information InteractionIn 1995, Nahum Gershon coined the term "Human Information Interaction" (HII) to denote "how human beings interact with, relate to, and process information regardless of the medium connecting the two." Since then, the term has been widely adopted by the traditional information science and retrieval communities. Gary Marchionini of the UNC School of Information and Library Science explains "the IR problem itself has fundamentally changed and a new paradigm of information interaction has emerged."[*]
This paradigm is characterized by highly interactive interfaces, user-centered methods, and a sensitivity to the dynamic, multi-channel nature of information seeking behavior. Researchers in Human Information Interaction draw insight and inspiration from the field of Human Computer Interaction (HCI) while recognizing they face unique challenges. As Elaine Toms suggests, "(the) unstructured, complex problem-solving task (of information seeking) cannot be reduced in a predictable way to a set of routine Goals, Operators, Methods, and Selections (GOMS)."[*] In other words, the complexity of information interaction is not expressed well in typical models of human-computer interaction. HCI approaches are optimal for software applications and interfaces where designers can exercise great control over form and function. HII approaches are optimal for networked information systems where control is sacrificed for interoperability. In such environments, users may find and interact with information objects through a variety of devices and interfaces. The emphasis shifts from interface to information.
Fortunately, we're not starting from scratch. Thanks to pioneers who anticipated the current paradigm, we've inherited a wealth of information interaction information. In particular, Marcia J. Bates deserves credit for shaping our understanding of information seeking behavior. In a 1989 article entitled "The Design of Browsing and Berrypicking Techniques for the Online Search Interface," Marcia Bates exposed the inadequacy of the classic information retrieval model characterized by a single query, shown in Figure 3-6. Figure 3-6. The classic information retrieval model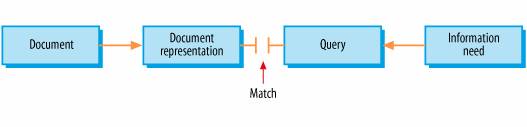 Instead, she proposed a berrypicking model that recognizes the iterative and interactive nature of the information seeking process. Bates understood that the query and the information need itself evolve as users interact with documents and search systems. She also recognized that since relevant documents (like berries) tend to be scattered, users move fluidly between search and browse modes, relying on a rich variety of strategies including footnote chasing, area scanning, and citation, subject, and author searching, as shown in Figure 3-7. In short, Bates described information seeking behavior on today's Web, back in 1989. Google relies on the citations we call "inbound links." Blogs support "backward chaining" through TrackBack. Flickr and del.icio.us Figure 3-7. Marcia Bates' berrypicking, evolving search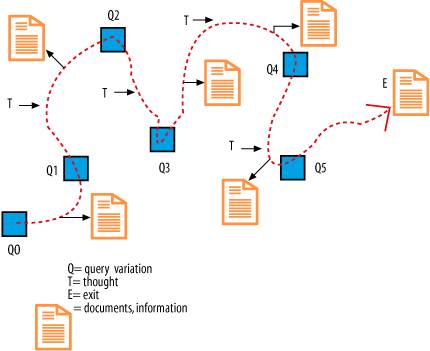 allow us to pivot on subject or author. The Web allows our information seeking to grow more iterative and interactive with each innovation. The berrypicking model is more relevant today than ever. By studying behavior with an open mind, Marcia Bates learned to see information systems and their human users from a new perspective. In fact, her insights laid the foundation for modern studies at the intersection of evolutionary psychology and information seeking. The thread she began with "berrypicking" was picked up by Xerox PARC researchers Peter Pirolli and Stuart Card in their study of information foraging . They explain "we use the term 'foraging' both to conjure up the metaphor of organisms browsing for sustenance and to indicate a connection to the more technical optimal foraging theory found in biology and anthropology."[*] Their studies in information foraging have been noted by Jakob Nielsen as vitally important in the age of Google.[
Today, researchers are probing the adaptive behavior of collaborative foraging in nature for insights into collaborative filtering on the Web. As one investigator explains:
And, scientists at the University of Washington are using a multidimensional approach called Cognitive Work Analysis to study collaborative information interaction:
And, of course, Marcia Bates continues to break new ground with her research investigations aimed at developing an integrated model of information seeking and searching that incorporates aesthetic, biological, historical, psychological, social, and even spiritual layers of understanding. She continues to ask tough questions:
In the spirit of Calvin Mooers, Bates makes painfully honest diagnoses, and follows up with creative prescriptions for the future. She explains why we value gossip so highly, and then encourages us to design gossip into our systems. It's not just about retrieval. We must embrace both push and pull. We must utilize the full spectrum of interaction. Finally, HII shifts emphasis from technology, interface, and medium to the information objects themselves. In recent years, Andrew Dillon and Misha Vaughan have begun exploring the concept of information shape and the emergent property of genre.[*] And Elaine Toms has identified the importance of cues, which:
In the literature of information shape and genre, we suddenly find ourselves back at the intersection of physical and digital, talking about document landscapes, textual landmarks, and wayfinding in cyberspace. Of course, this convergence is accelerating in accord with Moore's Law. The boundaries between information and objects blur more each day. To observe this in action, keep an eye on Google, whose stated mission is "to organize the world's information and make it universally accessible and useful." You see, the tricky thing about Google is they keep changing their definition of information. First, it was just web sites. Then images, online discussions, blogs, news, and products entered the fold. Then phone numbers, addresses, street maps, and FedEx tracking data. Then, the contents of your desktop computer. Then, the contents of the world's largest research libraries. Millions of books transformed into bytes. And acquisitions such as Keyhole, a company specializing in satellite imagery software, and Dodgeball, a pioneer in mobile social software, suggest Google has big plans for information, plans that reach far beyond what we normally think of as the Web. Now, Calvin Mooers might ask whether this promised land of pervasive computing and ambient information is as desirable as we're led to believe. Will our information environments of tomorrow really be less painful and troublesome than those of today? Is more really more or less? How will humans respond to such a wealth of information? These are important questions we will answer the hard way by surfing ahead at breakneck speed on the waves of the technology tsunami that's powered by Moore's Law. |
 ] And their concept of "information scent has entered the vernacular of web design.
] And their concept of "information scent has entered the vernacular of web design. ]
]EAN: 2147483647
Pages: 87