The Data Model
The most abstract level of a database design is the data model, the conceptual description of a problem space. Data models are expressed in terms of entities, attributes, domains, and relationships. The remainder of this chapter discusses each of these in turn.
Entities
It's difficult to provide a precise formal definition of the term entity, but the concept is intuitively quite straightforward: an entity is anything about which the system needs to store information.
When you begin to design your data model, compiling an initial list of entities isn't difficult. When you (or your clients) talk about the problem space, most of the nouns and verbs used will be candidate entities. "Customers buy products. Employees sell products. Suppliers sell us products." The nouns "Customers," "Products," "Employees," and "Suppliers" are all clearly entities.
The events represented by the verbs "buy" and "sell" are also entities, but a couple of traps exist here. First, the verb "sell" is used to represent two distinct events: the sale of a product to a customer and the purchase of a product by the organization. That's fairly obvious in this example, but it's an easy trap to fall into, particularly if you're not familiar with the problem space.
The second gotcha is the inverse of the first: two different verbs ("buy" in the first sentence and "sell" in the second) are used to describe the same event, the purchase of a product by a customer. Again, this isn't necessarily obvious unless you're familiar with the problem space. This problem is often trickier to track down than the first. If a client is using different verbs to describe what appears to be the same event, they might in fact be describing different kinds of events. If the client is a tailor, for example, "customer buys suit" and "customer orders suit" might both result in the sale of a suit, but in the first case it's a prêt-à-porter sale and in the second it's bespoke. These are very different processes that might need to be modeled differently.
In addition to interviewing clients to establish a list of entities, it's also useful to review any documents that exist in the problem space. Input forms, reports, and procedures manuals are all good sources of candidate entities. You must be careful with documents, however. Printed documents have a great deal of inertia: input forms particularly are expensive to print and frequently don't keep up with changes to policies and procedures. If you stumble across an entity that's never come up in an interview, don't assume the client just forgot to mention it. Chances are that it's a legacy item that's no longer pertinent to the organization. You'll need to check.
Once you've developed an initial list of candidate entities, you need to review them for completeness and consistency. Again, you need to find duplicates and distinct entities that are masquerading as the same entity. A useful tool in this process is the concept of entity subtypes. To return to our example of the tailor, "prêt-à-porter" and "bespoke" both represent the purchase of an item of clothing, but they're different kinds of purchases. In other words, Sale and Order are both subtypes of the entity Purchase.
Attributes that are common to both types of Purchase are assigned to the supertype, in this case, Purchase, and attributes specific to a subtype—PretAPorter or Bespoke in this instance—are factored out to that subtype. This allows both kinds of events to be treated as generic Purchases when that is appropriate (as when calculating total sales) or as specific kinds of Purchases (as when comparing subtypes).
Sometimes you might discover that the entity subtypes don't actually have distinct attributes, in which case it's more convenient to make TypeOfSale (or TypeOfCustomer, or TypeOfWhatever) an attribute of the supertype rather than modeling the subtypes as distinct entities. With our tailoring example for bespoke sales you might need to know the cloth and color selected, whereas for prêt-à-porter sales you might need to track the garment manufacturer. In this case, you would use subtypes to model these entities. If, however, you only need to know that a sale was bespoke or prêt-à-porter, a TypeOfSale attribute would be simpler to implement.
Subtypes are usually mutually exclusive, but this is by no means always the case. Consider an employee database. All employees have certain attributes in common (hire date, department, and telephone extension), but only some will be salespeople (with specific attributes for commission rate and target) and only a few will join the company softball team. There's nothing preventing a salesperson from playing basketball, however.
Most entities model objects or events in the physical world: customers, products, or sales calls. These are concrete entities. Entities can also model abstract concepts. The most common example of an abstract entity is one that models the relationship between other entities—for example, the fact that a certain sales representative is responsible for a certain client or that a certain student is enrolled in a certain class.
Sometimes all you need to model is the fact that a relationship exists. Other times you'll want to store additional information about the relationships, such as the date on which it was established or some characteristic of the relationship. The relationship between cougars and coyotes is competitive, that between cougars and rabbits is predatory, and it's useful to know this if you're planning an open-range zoo.
Whether relationships that do not have attributes ought to be modeled as separate entities is a matter of some discussion. I don't think anything is gained by doing so, and it complicates the process of deriving a database schema from the data model. However, understand that relationships are as important as entities are in the data model.
Attributes
Your system will need to keep track of certain facts about each entity. These facts are referred to as the entity's attributes. If your system includes Customer entities, for example, you'll probably want to know the names and addresses of the customers and perhaps the businesses they're in. If you're modeling an event such as a Service Call, you'll probably want to know who the customer was, who made the call, when it was made, and whether the problem was resolved.
Determining the attributes to be included in your model is a semantic process. You must make your decisions based on what the data means and how it will be used. Let's look at one common example: an address. Do you model the address as a single entity (the Address) or as a set of entities (HouseNumber, Street, City, State, ZipCode)? Most designers (myself included) would tend to automatically break the address up into a set of attributes on the general principle that structured data is easier to manipulate, but this is not necessarily correct and certainly not straightforward.
Let's take, for instance, a local amateur musical society. It will want to store the addresses of its members in order to print mailing labels. Since all the members live in the same city, there is no reason to ever look at an address as anything other than a blob: a single, multiline chunk of text that gets spat out on demand.
But what about a mail-order company that does all its business on the Internet? For sales tax purposes, the company needs to know the states in which its customers reside. While it's possible to extract the state from the single text field used by the musical society, it isn't easy; so it makes sense in this case to at least model the state as a separate attribute. What about the rest of the address? Should it be composed of multiple attributes, and if so, what are they? Be aware that while addresses in the United States conform to a fairly standard pattern, modeling them is probably not as simple as it appears.
You might think that a set of attributes {HouseNumber, Street, City, State, ZipCode} might be adequate. But then you need to deal with apartment numbers and post office boxes and APO addresses. What do you do with an address to be sent in care of someone else? And of course the world is getting smaller but not less complex, so what happens when you get your first customer outside the United States? Not only do you need to know the country and adjust the zip code, but the arrangement of the attributes might need to change. In most of Europe, for example, the house number follows the street name. That's not too bad, it's easy enough to map that when you're entering data, but how many of your users would know that in the address 4/32 Griffen Avenue, Bondi Beach, Australia, 4/32 means Apartment 4, Number 32?
The point here is not so much that addresses are hard to model, although they are, but rather that you can't make any assumptions about how you should model any specific kind of data. The complex schema that you develop for handling international mail order is completely inappropriate for the local musical society.
Matisse is reputed to have said that a painting was finished when nothing could be either added or subtracted. Entity design is a bit like that. How do you know when you've reached that point? The unfortunate answer is that you can never know for certain. At the current state of technology, there isn't any way to develop a provably correct database design. You can prove that some designs have flaws, but you can't prove that any given design doesn't. You can't, if you will, prove your innocence. How do you tackle this problem? There are no rules, but there are some strategies.
The first strategy is: start with the result and don't make the design any more complex than it needs to be.
What questions does your database have to answer? In our first example, the musical society, the only question was "Where do I mail a letter to this person?", so a single-attribute model was sufficient. The second example, the mail order company, also had to answer "In what state does this person live?", so we needed a different structure to provide the results.
You need to be careful, of course, that you try to provide the flexibility to handle not just the questions your users are asking now but also the ones you can foresee them asking in the future. I'd be willing to bet, for instance, that within a year of implementing the musical society system the society will come back asking you to sort the addresses by zip code so that they can qualify for bulk mail discounts.
You should also be on the lookout for questions the users would ask if they only knew they could, particularly if you're automating a manual system. Imagine asking a head librarian how many of the four million books in the collection were published in Chicago before 1900. He or she would point you to the card file and tell you to have fun. Yet this is trivial information to request from a well-designed database system.
One of the hallmarks of good designers is the thoroughness and creativity with which they solicit potential questions. Inexperienced analysts are frequently heard to remark that the users don't know what they want. Of course they don't; it's your job to help them discover what they want.
There's a trap here, however. Often, the trade-off for flexibility is increased complexity. As we saw with the address examples, the more ways you want to slice and dice the data the more exceptions you have to handle, and there comes a point of diminishing returns.
This leads me to strategy two: find the exceptions. There are two sides to this strategy: first that it is important to identify all the exceptions, and second that you must design the system to handle as many exceptions as you can without confusing users. To illustrate what this means, let's walk through another example: personal names.
If your system will be used to produce correspondence, it's crucial that you get the name right. (Case in point: any unsolicited mail arriving at my house addressed to Mr. R. M. Riordan doesn't even get opened.) Most names are pretty straightforward. Ms. Jane Q. Public consists of the Title, FirstName, MiddleInitial, and LastName, right? Wrong. (You saw this coming, didn't you?) In the first place, FirstName and LastName are culturally specific. It's more correct to use GivenName and Surname. Next, what happens to Sir James Peddington Smythe, Lord Dunstable? Is Peddington Smythe his Surname or is Peddington his MiddleName, and what do you do about the "Lord Dunstable" part? And the singer Sting? Is that a GivenName or a Surname? And what will happen to The Artist Formerly Known as Prince? Do you really care?
That last question isn't as flippant as it sounds. A letter addressed to Sir James Peddington Smythe probably won't offend anyone. But the gentleman in question is not Sir Smythe; he's Sir James, or maybe Lord Dunstable. Realistically, though, how many of your clients are lords of a realm? The local musical society is not going to thank you for giving them a membership system with a screen like the one in Figure 1-4.
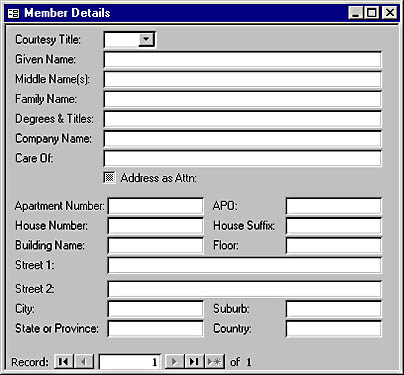
Figure 1-4. An overly complex address screen.
So be aware that there's a trade-off between flexibility and complexity. While it's important to catch as many exceptions as possible, it's perfectly reasonable to eliminate some of them as too unlikely to be worth the cost of dealing with them.
Distinguishing between entities and attributes is sometimes difficult. Again, addresses are a good example, and again, your decision must be based on the problem space. Some designers advocate the creation of a single address entity used to store all the addresses modeled by the system. From an implementation viewpoint, this approach has certain advantages in terms of encapsulation and code reuse. From a design viewpoint, I have some reservations.
It's unlikely that addresses for employees and customers will be used in the same way. Mass mailings to employees, for example, are more likely to be done via internal mail than the postal service. This being the case, the rules and requirements are different. That awful data entry screen shown in Figure 1-4 might very well be justified for customer addresses, but by using a single address entity you're forced to use it for employees as well, where it's unlikely to be either necessary or appreciated.
Domains
You might recall from the beginning of this chapter that a relation heading contains an AttributeName:DomainName pair for each attribute. I said then that a domain definition specifies the kind of data represented by the attribute. More particularly, a domain is the set of all possible values that an attribute may validly contain.
Domains are often confused with data types, but this is inaccurate. Data type is a physical concept while domain is a logical one. "Number" is a data type, and "Age" is a domain. To give another example, "StreetName" and "Surname" might both be represented as text fields, but they are obviously different kinds of text fields; they belong to different domains.
Domain is also a broader concept than data type in that a domain definition includes a more specific description of the valid data. Take, for example, the domain DegreeAwarded, which represents the degrees awarded by a university. In the database schema, this attribute might be defined as Text[3], but it's not just any three-character string, it's a member of the set {BA, BS, MA, MS, PhD, LLD, MD}.
Of course, not all domains can be defined by simply listing their values. Age, for example, contains a hundred or so values if we're talking about people, but tens of thousands if we're talking about museum exhibits. In such instances it's useful to define the domain in terms of the rules which can be used to determine the membership of any specific value in the set of all valid values. For example, PersonAge could be defined as "an integer in the range 0 to 120," whereas ExhibitAge might simply be "an integer equal to or greater than 0."
"Ah," I can hear you saying to yourself. "Domain is the combination of the data type and the validation rule." Well, if you think of them this way you won't go too far wrong. But remember, validation rules are part of the data integrity, not part of the data description. For example, the validation rule for a zip code might refer to the State attribute, whereas the domain of ZipCode is "a six-digit string."
Note that all these definitions make some reference to the kind of data stored (number or string). This looks a whole lot like a data type, but it isn't really. Data types, as I've said, are physical; they're defined and implemented in terms of the database engine. It would be a mistake developing the data model to define a domain as varchar(30) or a Long Integer, which are engine-specific descriptions.
For any two domains, if it makes sense to compare attributes defined on them (and, by extension, to perform relational operations such as joins, which we'll discuss in Chapter 5), then the two domains are said to be type-compatible. For example, given the two relations in Figure 1-5, it would be perfectly sensible to link them on EmployeeID = SalespersonID—you might do this to obtain a list of invoices for a given employee, for example. The domains EmployeeID and SalespersonID are type-compatible. Trying to combine the relations on EmployeeID = OrderDate will probably not result in a meaningful answer, even if the two domains were defined on the same data type.
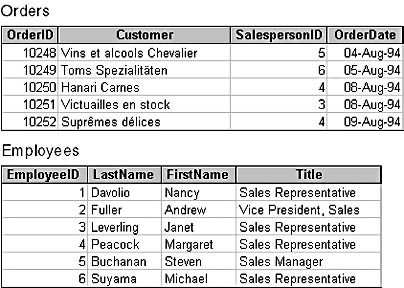
Figure 1-5. The Employees and Orders relations.
Unfortunately, neither the Jet database engine nor SQL Server provides strong intrinsic support for domains, beyond data types. And even within data types, neither engine performs strong checking; both will quietly convert data behind the scenes. For example, if you've defined EmployeeID as a long integer in the Employees table and InvoiceTotal as a currency value in the Invoices table in the Microsoft Access Northwind sample database, you can create a query linking the two tables with the criteria WHERE EmployeeID = InvoiceTotal, and Microsoft Jet will quite happily give you a list of all employees who have an EmployeeID that matches the total value of an invoice. The two attributes are not type-compatible, but the Jet database engine doesn't know that.
So why bother with domains at all? Because, as we'll see in Part 2, they're extremely useful design tools. "Are these two attributes interchangeable?" "Are there any rules that apply to one but don't apply to the other?" These are important questions when you're designing a data model, and domain analysis helps you think about them.
Relationships
In addition to the attributes of each entity, a data model must specify the relationships between entities. At the conceptual level, relationships are simply associations between entities. The statement "Customers buy products" indicates that a relationship exists between the entities Customers and Products. The entities involved in a relationship are called its participants. The number of participants is the degree of the relationship. (The degree of a relationship is similar to, but not the same as, the degree of a relation, which is the number of attributes.)
The vast majority of relationships are binary, like the "Customers buy products" example, but this is not a requirement. Ternary relationships, those with three participants, are also common. Given the binary relationships "Employees sell products" and "Customers buy products," there is an implicit ternary relationship "Employees sell products to customers." However, specifying the two binary relationships does not allow us to identify which employees sold which products to which customers; only a ternary relationship can do that.
A special case of a binary relationship is an entity that participates in a relationship with itself. This is often called the bill of materials relationship and is most often used to represent hierarchical structures. A common example is the relationship between employees and managers: any given employee might both be a manager and have a manager.
The relationship between any two entities can be one-to-one, one-to-many, or many-to-many. One-to-one relationships are rare, most often being used between supertype and subtype entities. To return to our earlier example, the relationship between an employee and that employee's salesperson details is one-to-one.
One-to-many relationships are probably the most common type. An invoice includes many products. A salesperson creates many invoices. These are both examples of one-to-many relationships.
Although not as common as one-to-many relationships, many-to-many relationships are also not unusual and examples abound. Customers buy many products, and products are bought by many customers. Teachers teach many students, and students are taught by many teachers. Many-to-many relationships can't be directly implemented in the relational model, but their indirect implementation is quite straightforward, as we'll see in Chapter 3.
The participation of any given entity in a relationship can be partial or total. If it is not possible for an entity to exist unless it participates in the relationship, the participation is total; otherwise, it is partial. For example, Salesperson details can't logically exist unless there is a corresponding Employee. The reverse is not true. An employee might be something other than a salesperson, so an Employee record can exist without a corresponding Salesperson record. Thus, the participation of Employee in the relationship is partial, while the participation of Salesperson is total.
The trick here is to ensure that the specification of partial or total participation holds true for all instances of the entity for all time. It's not unknown for companies to change suppliers for a product, for example. If the participation of Products in the "Suppliers provide products" relation has been defined as total, it won't be possible to delete the current supplier without deleting the other product details.
Entity Relationship Diagrams
The Entity Relationship model, which describes data in terms of entities, attributes, and relations, was introduced by Peter Pin Shan Chen in 1976.2 At the same time, he proposed a method of diagramming called Entity Relationship (E/R) diagrams, which has become widely accepted. E/R diagrams use rectangles to describe entities, ellipses for attributes, and diamonds to represent relationships, as shown in Figure 1-6.
The nature of the relationship between entities (one-to-one, one-to-many, or many-to-many) is represented in various ways. A number of people use 1 and M or 1 and ¥ (representing infinity) to represent one and many. I use the "crow's foot" technique shown in Figure 1-6, which I find more expressive.
The great advantage of E/R diagrams is that they're easy to draw and understand. In practice, though, I usually diagram the attributes separately, since they exist at a different level of detail.
Generally, one is either thinking about the entities in the model and the relationships between them or thinking about the attributes of a given entity, but rarely thinking about both at the same time.
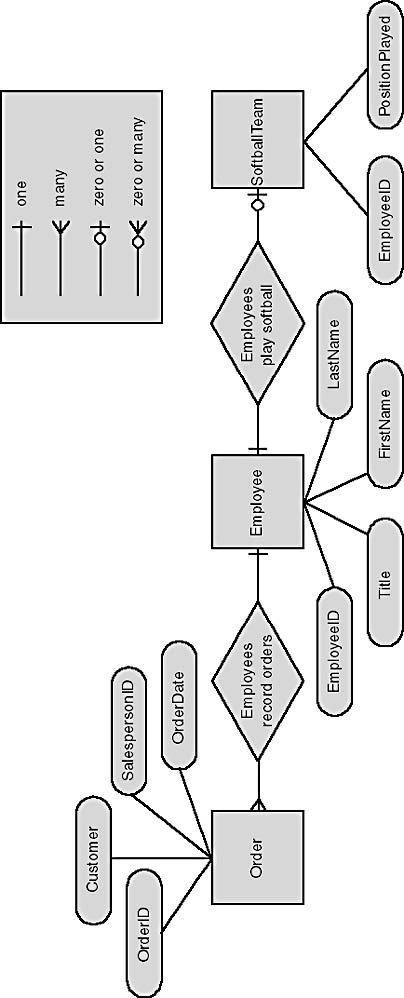
Figure 1-6. An E/R diagram.
EAN: 2147483647
Pages: 124