2.1 The Big Picture: Security Policies from A to Z
|
2.1 The Big Picture: Security Policies from A to Z
One of my hobbies is amateur bodybuilding. This hobby also happens to provide a good nontechnical example of the difference between a policy and a model. I am often asked by people in the gym, "How can I make good gains from working out?" The questioner then typically modifies the query by defining what "gains" means to them, either losing fat or gaining muscle mass. Either way, I can respond to them with a policy, "Eat well. Work out consistently."
My policy on maximizing gains is clearly a high-level statement of principle. It broadly defines how the questioner should obtain his goal of "good gains." Rarely, however, do people nod knowingly when I tell them this and run off to put it into practice. They also need a model. The model is a series of steps that defines "eat this many calories per day; eat this many meals per day; ensure you get this much protein per day; work out this many times per week; do these exercises; etc." The person can agree in principle to the policy, but to actually implement the policy, that person needs a model to follow.
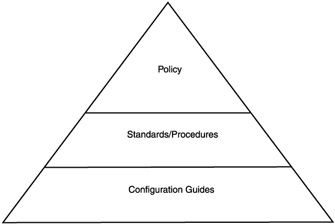
A properly constructed security policy has a very specific structure. The security policy is the high-level document that describes the philosophy, business environment, and goals of the organization. To implement these goals, specific steps must be taken. This is the role of security standards and procedures. A high-level policy statement such as "All financial transactions between business partners will remain confidential and arrive with guaranteed integrity" is pretty broad. Our standards and procedures may further state that "Confidentiality between networks utilizing the public Internet will employ either (1) an IPSec VPN with 256-bit AES or equivalent security. Identity will be established through the exchange of RSA signatures via a secure mechanism and validated by a third party certification authority; or (2) an MPLS-based VPN between business partners that share the same service provider. Null-encryption with the MD5 hash algorithm shall be used on such connections to assure the integrity of any transmissions." This statement offers a couple of specific ways to provide the confidentiality and integrity between your site and remote business partners.
Even then, standards and procedures are not enough to actually implement the solutions. For this, a configuration guide is required. As the name suggests, the configuration guide is a step-by-step guide that shows which options to enable, what values to fill in the provisioning order, etc. This is the step-by-step guide that is used to put the security policy into place. Together, the structure of a security policy looks like the diagram shown in Exhibit 1. The process of creating the security policy can be broken down into nine distinct steps, with additional optional steps as required. These nine steps are listed below:
Exhibit 1: The Security Policy Model
-
Obtain management support
-
Identify information assets
-
Draft policy statement
-
Perform risk analysis
-
Select countermeasures
-
Create security standards
-
Create configuration guides
-
Implement
-
Review
Each of these steps is discussed in detail as the chapter progresses.
2.1.1 Getting Management Buy-In
Sometimes it can be difficult to explain to management why the time and effort must be spent in constructing a security policy. At the same time, without this important step, the remainder of the security policy process is somewhat pointless. By the end of this chapter it should be clear that this is a step integral to the successful implementation of network security. Until that point, when a baseline of security has been established on the network, getting the process rolling can be a Sisyphean task.
There are practical and legal reasons that management must be involved with the top-down construction of the security policy from the beginning. Remember: you cannot simply drop a bunch of technology into a network and expect to achieve security. The best improvement in information security is obtained when the behavior of individuals can be modified as well. To do this, the authority of management is essential.
Creating a security policy from the bottom up, where several concerned IT employees get together to discuss ways to secure the network, is ineffective in practice. The view of company priorities of the IT staff will most likely differ from that of management staff. When these two perspectives come into conflict, guess which one wins most often? The practical reason for obtaining management support is simply that without it, the security policy will quickly become marginalized and a point of frustration for all involved.
The legal rationale is much more complicated. In most countries, the management of an organization has a financial responsibility to the owners of a company. In a publicly traded company, this is the shareholder. When considering the liability that a company or senior executives may face when security is breached, there are several concepts with which one should become familiar. In no particular order, they are due diligence, due care, and the prudent man rule.
Many times, it is a natural instinct to consider that all computer crimes are solely the fault of hackers. After all, it was they who broke the law. From a legal perspective however, it is only part of the story. If the company is publicly traded and senior management did not take any steps to protect important company data or otherwise made it easy for an attacker to walk away with the crown jewels due to their inaction, in the U.S., senior management may be held personally liable for up to $290 million under the 1997 Federal Sentencing Guidelines. When determining the guilt or innocence of such an individual, the above-mentioned terms of due diligence, due care, and the prudent man rule will be carefully weighed against the facts of the case.
Due diligence pertains to activities that ensure that network protection mechanisms are continually maintained. This means making sure that the network is protected on an ongoing basis and that the IT and information security staff roles and responsibilities are defined.
Due care refers to the steps that a company has taken to show that it has accepted responsibility for actions that occur within, its resources, and its employees. Of course, parts of those resources are the network components. Most modern companies have a large amount of their value tied up in the data that they store on their network. Not protecting that information is not exercising due care.
Finally, the prudent man rule is a rule that management must follow when determining if due diligence and due care have been exercised properly. The prudent man rule states that management is required to perform those duties that "prudent" people would normally take, given similar circumstances. Due diligence can be proven with the existence of a security policy that has been properly implemented. The principle of due care outlines steps that must be taken to enforce the security policy and the network resources. Finally, a security policy that has demonstrated a thorough risk analysis will prove that, given the nature of the resources to protect, prudent steps were taken to protect them.
The concept of the prudent man rule as it relates to a security policy is worth a bit more discussion. Can managers approve a firewall installation and claim that they were meeting their legal responsibilities to the company? That depends. If the objects they were trying to protect (i.e., data, hardware, personnel, even their own reputations) were of a non-critical nature and the threats that the network were vulnerable to were largely of a packet-based nature over an IP network, then it can be argued that the prudent man rule had been followed. On the other hand, if the network contained objects of a critical nature that attracted the attention of well-financed and patient criminals or even foreign governments who could launch a wide variety of attacks, then it would be difficult to argue that the prudent man rule had been applied correctly because, clearly, a firewall alone could not provide the level of protection warranted by the data.
The question then becomes: how does this fated manager determine if the prudent man rule has been applied correctly? To do this, a risk analysis must be performed.
2.1.2 Identify Information Assets
I have yet to begin studying for an MBA; but if I do, I am confident that the studies will go well because I have one fundamental element of business management already under my belt. An asset is anything of value that the company has. This may be intellectual property, trade secrets, copyrights, databases, workstations, servers, routers, and printers. To know what the security policy must refer to, we need to know what the priorities are on our network. To obtain this information, a detailed inventory should be performed of all hardware and software assets, along with interviews with the management structure, to obtain a clear priority of what resources are priorities in the company.
2.1.3 Regulatory Expectations
In some cases, there may not be a lot of flexibility regarding what the emphasis of the security policy should be. There may be times when information security requirements are legislated or enforced through industry and trade groups. Before drafting a security policy, ensure that all regulatory requirements have been met. Some of the most common regulatory sites are described below.
-
Health Information Portability and Accountability Act (HIPAA). Regulations regarding the treatment of patient healthcare information. If your work is in any way related to the health-care industry, you have heard about this act. Find more information at www.cms.hhs.gov.
-
Gramm-Leach-Bliley Act (GLBA). What HIPAA is to patient privacy, the Gramm-Leach-Bliley Act is to financial institutions regarding consumer rights. Most people who know about the GLBA are familiar with it for the requirement of "opt-in" marketing instead of the "opt-out" marketing that most Web sites tend to engage in when you provide them with any personal information. Find more information on GLBA requirements at www.ftc.gov.
-
Federal Deposit Insurance Corporation (FDIC). Providing deposit insurance for millions of households, the FDIC is a staple of the American banking industry. As can be imagined, there are a number of suggestions that relate to privacy, E-banking, and other online transactions. Find out more at http://www.fdic.gov.
-
1974 Privacy Act. Stemming from the Watergate era, the 1974 Privacy Act seeks to balance national interests with the need for personal privacy. It provides guidelines on keeping individual's records and on individual rights to review such documents. Find information regarding these requirements at http://www.usdoj.gov.
-
Department of Defense Information Technology Security Certification and Accreditation Process (DITSCAP). This security document is used by the U.S. Department of Defense (DoD) in the certification and accreditation of all IT systems. Policy related to the DoD must meet its guidelines. Find a copy of DITSCAP at http://mattche.iiie.disa.mil.
-
Federal Communications Commission (FCC). The FCC is involved with most facets of communication, including information systems. It has guidelines for everything from the Freedom of Information Act to initiatives on Homeland Security. Find information regarding the FCC and information security at www.fcc.gov.
-
ISO 15408. Even if we call these by their more common name, the "Common Criteria" Specifications may not be all that well-known to many. While the Common Criteria is not a strictly U.S initiative as all the other resources are, it does represent a best practice and common language describing the security capabilities of technology. The Common Criteria represents an attempt to standardize the way we evaluate information security products across vendors and even technologies. Find information on the Common Criteria at www.commoncriteria.org.
-
ISO 17799. These ISO recommendations are controls that describe the current consensus on best practices in information security. All alone, it is an extremely useful guide for those interested in implementing their own information security policy. Find information on ISO 17799 at www.iso-17799.com.
This is, of course, only the tip of the iceberg regarding organizations and legislation that may affect your company security policy. Other than the inclusion of the ISO, the list above is conspicuously United States-centric. Those readers in other countries should research their own applicable laws and regulations.
2.1.4 Draft Security Policy
Before discussing risk analysis and the creation of policy, some vocabulary lessons are in order. What follows is a general discussion of terms that often find their way into a security policy. We discuss later that a good security policy is written in terms that end users can easily understand; but when discussing our security policy with other professionals, we should make sure that we get our vocabulary right.
In creating a security policy, we must first consider what to achieve. This should seem simple — a more secure network, of course! But what defines a secure network? Security professionals like to describe a secure network as one that supports three essential goals:
-
Confidentiality. Simply put, this is the expectation that private data will remain private. This can apply to data in several forms. It might pertain to a database in which certain data elements are available only to those who possess the proper permissions. It might mean that those who capture packets over a network cannot decipher the information in them. It might mean that users' personal files on a file server or desktop computer cannot be read by those without proper permissions. A company is generally not excited about someone reading all of its user data, as recent cases involving E-commerce, credit card numbers, and lax corporate security illustrate. In each of the above instances, there is an expectation of confidentiality, but the way that confidentiality is achieved in each case will be different. A security policy must consider under what circumstances confidentiality is expected from the users. One that uses IPSec to create a VPN between two points will do nothing to protect data already stored on a file server. Enforcing file access permission levels will do nothing if an authorized user sends the information over a network where it can be read by anyone with a packet sniffer.
-
Integrity. Integrity is the expectation that the data the user is reading is in its original, authorized, unmodified form. This does not mean that data can never change. If that were the case, little data would be of use to us for any significant length of time. It does mean, however, that data that changes can only be changed by those authorized. As an example, data sent over a network, such as an important e-mail, could be captured, changed, and then resent — or a forged piece of e-mail could be sent to begin with! Either way, the e-mail recipients would like to be aware that all is not as it seems. Another example is files on a file server that house student records. A criminal in this case might be more interested in altering data than simply reading it — to reduce debt or change grades. As with confidentiality, the above examples were all related to a user's expectation of user data integrity, but each would have to achieve integrity in a different way.
-
Availability. Availability is ensuring that data is available when users expect it. One of the simplest ways to disrupt a network that many rely upon for work and information is to simply render the network unavailable. While compromising confidentiality and integrity generally takes knowledge and skill on the part of an attacker, denying access to network resources (otherwise known as a denial-of-service [DoS] attack) can be fairly straightforward and inelegant. Availability can be disrupted in a number of ways, and each needs a different countermeasure to reduce the risk. Locking out their user names, or rendering their PCs inoperable through a virus or Trojan can prevent user access to their own PCs. Disabling a switch, reconfiguring a router, or simply flooding the network with more traffic than it can otherwise handle can attack the network itself that is used to communicate with remote servers. Finally, attacking the endpoint of the communication process by disabling the remote server will also effectively DoS the network users. Availability can even be affected by something as simple as shutting off a power switch on a server. Clearly, there are many elements to consider when ensuring that network resources are available to users. Each of these risks and their accompanying responses are different. They all must be considered when writing a security policy.
As we move on in our discussion of security to discuss the major threats that a network faces, we will see that most network threats are also threats that affect one of the above goals of our security policy.
A security policy appears in many formats; the one presented below is just a suggestion. Regardless of the format, however, there should be several characteristics that every security policy should have.
First and foremost, it should be easy to read and navigate. Most people's experience with legal documents, such as mortgage loans and medical prescriptions, make them think that in order to be valid, a document must be presented in the most confusing way possible with a great many references to items in the third person. This is not the case. A security policy should spell out the policy as plainly as possible — the clearer, the better. The security policy should also attempt to be precise without being redundant. There will be instances when someone will challenge the security policy in defense of their own actions. The basis of that challenge will be ambiguity in the wording of the policy or vagueness in the definition of a term.
With that in mind, a security policy typically has the following sections:
-
Introduction/Abstract. The introduction (or Abstract) describes the document and its purpose — to provide information regarding the position of the organization regarding information security.
-
Context/Operating Assumptions. Any influence on the creation of the security policy should be stated here. For example, "As a publicly traded corporation, we have a responsibility to…" Additionally, any laws or regulations that may affect the security policy itself can be introduced in this section.
-
Policy Statement. This is the main section of the document. Remember that this is a high-level statement of policy; thus, it is rare to find a policy statement more than a couple of pages in length. Words such as "confidentiality," "integrity," and "availability" should be emphasized here, along with the organization's information assets. For example, "Our business relies upon the uninterrupted services of Internet and internal e-mail. The integrity of all communications originating from our company should not be called into doubt. Furthermore, the confidentiality that our clients place in our communications shall not be misplaced."
-
Definitions. Anything that can be disputed in the policy itself should be defined here. The primary purpose of this section is to maintain the ease of readability of the policy statement itself and allow users to easily find information clarifying policy statements.
-
Authority/Responsibilities. A security policy is only going to be as good as the support it receives at the top. The security policy should clearly state who at the top supports it. This section may also detail the enforcement and implementation responsibilities of the security policy. Finally, penalties associated with noncompliance of the security policy can be outlined here. It is important to include arbitration procedures if penalties are going to be assigned.
-
Review. A security policy changes over time. There should be regularly scheduled reviews of the entire policy at least annually. Reviews should also be considered after any computer incidents have been resolved, as it is likely that the reason the incident occurred in the first place is due to an omission or oversight in the security policy. At some point, users of the network may request a change to the security policy to facilitate a new service that their job requires. Thus, the review process should also address the issue of change management and detail how a user makes a request for change to the security policy.
-
Distribution. Ideally, if I were to walk into your organization, I should be able to ask any employee, "Where is a copy of your security policy?" and they would respond with a sure answer. It is the responsibility of those creating the security policy to ensure that the document is accessible to all employees of the organization and that they are duly noted of changes and updates to the policy itself.
A security policy may be accompanied by several other supplementary documents supporting information security. The most common documents include the acceptable use policy (AUP), the incident response policy, and the disaster recovery/business continuity plan. Each of these documents is created in a manner very similar to the creation of the security policy. The difference is that the security policy should be considered the master plan, and each of the supporting polices supports the overall goals of the security policy. In a sense, each of the above policies is a separate standards and procedures document describing how the goals of the security policy are ultimately met.
2.1.5 Assessing Risk
Part of the process of creating an information security policy is risk assessment. We cannot accurately create a security policy that reflects our business requirements and reduces risk to an acceptable level until we have a clear picture of what the risks are that threaten our assets.
In this section we discuss the art and science of determining risk. When done properly, risk assessment is an important way to determine the appropriate response in dollars and effort in the implementation of a security policy. The construction of a security policy is a multi-stage process. The primary step in creating a security policy is first determining what you are trying to protect, and then determining who you are trying to protect your data from and the likely risks that your network will face.
This preliminary work is known as a risk analysis. Risk analysis can be categorized into two major groups: (1) a quantitative analysis that attempts to add up the value of an asset and compare it with the cost of an associated threat; and (2) a qualitative analysis that essentially asks the people most knowledgeable about the company, "What do you think?" Both approaches have their advantages and, in the end, a compromise between the two will end up as the basis for the security policy.
To properly discuss risk, there are several terms that must be explained. The first is the term "risk." A risk is defined as the probability of a threat taking advantage of a vulnerability.
A vulnerability is a weakness that can be exploited by an attacker. When considering the entire range of network security, the number of vulnerabilities is just staggering. Unlocked doors to server rooms are vulnerabilities; unnecessary services running on a server or even host computer can add unnecessary vulnerabilities due to flaws in either the program itself or the security protecting the program. Data backups that are not regularly performed, checked, and stored in secure locations are vulnerabilities. Easy-to-guess passwords are a vulnerability, but forcing users to use hard-to-guess — and hard to remember — passwords creates another vulnerability when the user sticks the password to the side of the monitor or under the keyboard. [1]
A threat is any danger to the organization's assets. This can be a person — an unsuspecting employee or malicious hacker, a natural disaster, or a foreign nation. Each of these threats results in a violation of the company's security policy. While the hacker may seek to subvert the confidentiality of information, the unsuspecting employees, in an attempt to make their daily jobs more productive, could violate the integrity of the data. An earthquake in San Francisco, on the other hand, could seriously affect the availability of specific data for users all around the world.
When a threat has a chance to exploit a vulnerability, there is risk that needs to be addressed. The vulnerability of an unlocked server room door, with the threat of a malicious insider, creates a risk that could affect confidentiality, integrity, and availability all at once. On-site storage of backups coupled with a catastrophic fire creates a risk that seriously affects the availability of data.
To summarize:
Threat + Vulnerability = Risk [2]
When a company suffers losses from a threat, this is known as an exposure. When the malicious insider (threat) walks through the unlocked server room door (vulnerability) and shuts off all the servers, the company that left the door open now has an exposure on its hands. In short, exposures are what most companies try to avert upon recognizing a combination of threats and vulnerabilities.
To mitigate the chance of exposure, countermeasures are implemented. A countermeasure reduces the chance of exposure from a given vulnerability/threat combination. A countermeasure to the vulnerability of an unlocked door would be one of the most cost-effective methods of physical site security yet developed: a lock. Note that in this instance the countermeasure was successful in eliminating the vulnerability (locking the door) and therefore reducing the chance for exposure. Our countermeasure, however, had no effect on the threat. In general, this is true no matter the application. Vulnerabilities are weaknesses that can be countered. Threats, on the other hand, are potential dangers of any type. A threat can never be fully eliminated, only planned for.
From this discussion one should infer that vulnerabilities are factors that are within the realm of control of the network owners. Threats are those elements outside the realm of control of the network owners. Prudence would dictate that vulnerabilities are discovered and countermeasures implemented. Threats must be considered and, through interactions with vulnerabilities, their impact assessed.
Just because there is a risk does not mean that it is something that needs to be addressed in a security policy. Strictly speaking, there is the risk that a threat such as an invading species of intelligent marsupials from another solar system could exploit the vulnerability of our building's lack of shielding against energy weapons. However, addressing the risk of protecting our corporate headquarters against such a risk would be very expensive and difficult to explain at a shareholders meeting. While this is an admittedly fantastic example, other cases might not be so cut and dry. The events of September 11th, 2001, are a case in point. On that day, a number of risks that seemed unlikely suddenly became within the realm of possibility. Can you defend your network against every possible risk now that airplanes can be used as weapons? There needs to be a way to allow security professionals and network managers to determine which risks are worth protecting against and which are not. This process is known as risk analysis.
Risk analysis allows us to sort our risk exposure and, based on the possible damage from an exposure, justify the cost of the security. Once the risks are identified and our possible loss from exposure is defined, we can then begin the process of risk management. Risk management is the process of reducing risk to an acceptable level, transferring the risk to another entity such as an insurance company, rejecting the risk outright, or accepting the risk.
As mentioned, risk analysis can be grouped into two broad approaches: the first is the quantitative approach and the second is the qualitative approach. Each has advantages, and each will be discussed in turn.
Long before entering the field of networking, I was a high school teacher. The quantitative/qualitative discussion would surface many times, generally in reference to student performance. When quantitative assessment was called for, the result would be a number of correct answers combined in some ratio with the number of incorrect answers. From the student's point of view, the assessment was cut and dry and answers were right or wrong (not withstanding partial credit!). At the end of the test, they received a number that was their score. Qualitative assessment was much more difficult to grade. Students had to meet a number of criteria for which success was somewhat subjective and depended on the perspective of the teacher doing the evaluation. Qualitative assessment in many ways was superior to quantitative assessment in that it could require a number of skills on the part of the student to successfully complete assignments and as long as the evaluation criteria was clearly laid out it could be quite fair — as long as the same instructor did the grading for every test. For this single reason, quantitative assessment is still the norm in education. Many people are comforted by the "right" answer and will not dispute the results on assignments.
When doing risk assessment, you will find that the same prejudices hold true. When justifying the expense needed for risk management, a number is the final answer that many are interested in seeing. Of course, as we explore the process of quantitative risk analysis, it will become clear that some subjective (qualitative) processes will need to occur. For the purposes of a security policy then, the quantitative and qualitative processes should be seen as complementary; both need to be understood for effective risk analysis.
At a high level, the process of risk analysis involves three steps:
-
Assign value to assets.
-
Assign cost to risks.
-
Choose countermeasures appropriate to the value of the asset and cost of risk exposure.
2.1.5.1 Assign Value to Assets.
This includes such common-sense items as the cost to maintain and replace the asset, but also some not-so-clear items such as the value of the asset to the competition or the value of the asset to the company. All these elements should be considered when determining asset value. At one particular meeting, I was working with management to decide on a value for its database. The going was tough, so I presented the situation in two simple scenarios. First, I held up a CD-RW that I had taken out of my briefcase. "This is a copy of your customer database and your business plan for the next five years. How much are you willing to pay to get it back?" Then I picked up a conveniently located computer and held it over my head. "This is your customer database and I am about to destroy it. How much are you willing to pay to get me to put this back on the table?"
While the demonstrations were primarily for dramatic effect, they did illustrate to the customer the need for considering all possibilities when determining an asset's value to a company. In this particular case, when I presented the problem as such, the customer realized that most of the value of the company was locked up in that customer database and to lose it would essentially cause the company to have to shut its doors. In this case, the value of the asset to the customer was the value of the business itself. Realistically speaking, there were other assets that contributed to the value of the business; but for this customer, the perceived value was very closely tied to its customer database.
Not all assets have such an impact on a business. Consider a network connection. Another customer I have worked with noted that he lost $100,000 per hour in orders and productivity every time his Internet connection failed. In this case, the company could survive as long as its data was intact and could withstand an Internet outage of several days, but there was a clear value assigned to its connectivity that was determined by closely examining the daily online business volumes and the payroll of staffers that normally handled the E-commerce orders. It became much easier to evaluate our options for risk management once these values were known.
Information may have to come from more than one source when evaluating the value of an asset. The finance department is a good place to start to get acquisition, maintenance, and replacement costs for hardware and software. The finance department can also give a good idea of the business that relies on network objects. The IT staff is a good place to check when determining the costs of outages and the damage that a particular threat agent could pose to the systems.
In some cases, important value to the business cannot be determined based on a line in a financial statement. What is the value of a company's reputation? Some companies have lost more than a billion dollars in market capitalization because of the public perception of the company after a high-profile attack. Many businesses do not even bother to report computer crime because they feel that public trust of the company itself will deteriorate if this information were to become public. If your company offers online purchases, what would be the cost to the company if it were determined that its Web site had been hacked? Because you were, of course, storing customer data on another server (of course you were!), none of the customer data was compromised, yet how do you convince your customers that this was the case and restore their confidence in your ability to keep their secrets secure? In this case, the value is tangible to your company, but assigning a dollar value can be more difficult.
2.1.5.2 Assign Cost to Risks.
The official term in risk assessment when assigning a cost to a particular risk is known as determining the single loss expectancy (SLE). Based on a per-exposure comparison, how much would the realization of each risk cost your network assets? In English, that means how much would it cost you if someone dropped a network server out a window? How much would it cost to recover that data? What would be the value of the lost productivity? Because there are a number of risks, each with a varying degree of associated cost, there will be a number of risks defined for each asset. Recalling our definition of risk, we can provide some examples to solidify our understanding for assigning cost. If a threat such as a hacker was able to compromise our Web server through vulnerability in the HTTP server software, at a minimum we would have to restore the server from original media or a known, good backup. This may take several hours, during which time the server is unavailable for use. What would be the cost associated with recovering from this risk if there were an exposure?
Another example would be the threat of a virus infecting the client host systems due to out-of-date virus scanning software. In a system of 25 end users, what would be the cost associated with removing the virus software from the host PCs? At a very minimum, the anti-virus signatures would need to be updated, and each person would be required or taught how to run the anti-virus software. The costs associated with this exposure would be primarily the time required to employ effective countermeasures and lost productivity on the part of the end users. This estimation would be optimistic in that it assumes that no further damage had been done to the host operating system.
When evaluating the cost associated with a risk, knowing how much a single exposure will cost you is not enough to make a financial or resource decision. How often the exposure will occur, or how likely the exposure is, also needs to be considered. A meteorite large enough to destroy a city may hit the Earth every 100,000 years. Couple that with the chances that this meteorite will also happen to hit your city and then the chance of exposure may drop to one in 100,000,000 years. [3] While the cost of exposure may be the value of the company, dividing that number by 100,000,000 gives you an average estimate for how much this risk will cost your company annually.
Happily, such catastrophic risks are rare. Other risks may happen with more frequency. Consider the case of the e-mail virus. Over the past five years, there have been an average of two major e-mail attachment viruses per year, with other smaller outbreaks here and there. This is a risk that your company will be exposed to and one that will require appropriate countermeasures. Likewise, your network will be the focus of automated network attacks, perhaps several per day. The annual rate of occurrence for exposure to this threat would be high.
2.1.5.3 Choose Countermeasures Appropriate to the Value of the Asset and the Cost of Risk Exposure.
By comparing the average annual cost of each risk with the value of the asset, a meaningful dollar value can be established that allows a company to determine how much it should spend each year to protect its assets from the various risks to which it may be exposed. Hypothetically speaking, if a company establishes that each virus outbreak that its network is exposed to cost $25,000 and the company knows from its own records and observations of the industry that it will be exposed to two attacks per year, then this risk will end up costing the company an average of $50,000 per year. This then becomes the maximum budget for implementing countermeasures to the risk of viral infection. If the faithful and hardworking IT director and his or her stalwart group of network engineers can find a way to reduce the risk for less than $50,000, they have just made the accounting department happy. If, for some reason, it is determined that the risk cannot be reduced for an annual price of less than $75,000 a year, then the company has a decision to make. From a purely financial point of view, this solution does not make sense, given that the company would save $25,000 each year by simply doing nothing other than cleaning up virus infections as they occur. Several factors, notably the annualized rate of occurrence rising, may change this. There would only need to be, on average, one additional company-wide virus infection per year to make the $75,000 solution make sense. In some cases, the cost of reducing the risk to an acceptable level is going to be more than the value of the asset we are trying to safeguard. While in most instances the goal of risk analysis is to allow an intelligent reduction of risk through the use of countermeasures, in some cases the most intelligent thing to do is to assign the risk to another party, or simply accept it.
When the cost of the countermeasure is too high for a company to bear the fiscal responsibility on its own, it may choose to assign the risk to another party. In common parlance, this is referred to "getting insurance." For most individuals, the total cost of employing countermeasures to protect their primary asset, their home, against fire is too much for them to take on as individuals. At the same time, the cost of a single exposure to the threat of fire will ruin most families. In this case, the risk is assigned to an insurance company that assumes the risk for a price. The same strategy can apply to network resources. If the cost of replicating the network for use in a catastrophic event is too high for a company to maintain, they can assign that risk to an insurance company that will reimburse the company if such an exposure occurs.
When accepting risk, a decision can also be made that if exposure should occur, the company would simply assume the costs. Accepting risk may be appropriate if the cost to reduce the risk is too high, as is the cost of assigning the risk. The risk may be considered to have such a low annualized rate of occurrence, or will cost so much to protect against, that countermeasures are simply unrealistic to implement. The previously stated risk of invasion from an alien species is most likely one that is so low that most reasonable and prudent people simply accept the risk. [4] There is an element of chance in this approach, however. Choosing to accept a risk simply because it is the easiest solution to risk management may mean that if that risk were ever realized, you are out of business.
No matter which approach is taken to respond to risk, a thorough risk analysis will serve two purposes: (1) it will allow security managers and financial officers to determine the proper, financially responsible response to risks facing the network; and (2) it can serve as evidence of prudent action on the part of management to protect the company's resources.
Before moving on, let us summarize the new information discussed thus far:
-
To determine how much to spend on information security, you first need to evaluate the value of your information assets.
-
Enumerate the likely risks that these assets would face and the likely cost if one of the risks were to materialize.
-
Choose countermeasures to the risks you have identified based upon the effectiveness and cost of the countermeasure relative to the cost of the risk.
2.1.6 Quantitative Risk Analysis
Having discussed the basics of risk analysis, we can now examine some specifics.
The first step in risk analysis is gathering data. In the end, our decisions will be based on the initial data we gather. To avoid the unpleasant situation of "garbage in, garbage out" being applied to a security policy we are responsible for, the process of data gathering must be done methodically. The first step is to create a list of all the assets in the company. Each asset needs to be assigned a dollar value. Remember to include more than just the purchase price. This means the cost to replace the asset, the value of the asset to competitors, the impact that the asset has on the profitability of the company, etc.
I am often asked how to list assets. When working with customers, they might give me a number such as "Database server: $53,274.42." While I appreciate the preciseness of such a value and the effort that must have gone into obtaining it, it is in the interest of the customer to break down the functions of the server as much as possible. In this case, the database server may be the server itself with a value of $15,000. The database, on the other hand, has an estimated value of about $45,000 to the customer. The reason for the distinction is that each may have different vulnerabilities and different threats that need risk analysis. While a fire or explosion may destroy both, risk management may determine different countermeasures for each asset — the database may be backed up incrementally each evening with an image stored off-site. The server, which is a platform the company has standardized upon, may have a single standby server in a "warm standby" state, which also serves as a backup server for the company's 15 other servers.
Granularity in defining assets allows controls to be more accurately chosen. While more granularity is the goal for defining assets, do not go too far to the other side of the spectrum. I have run into more than one customer who had so many discrete assets that actually working with the information turned out to be more than a human can reasonably keep straight.
For each asset, the risks that the asset may be exposed to need to be enumerated, as does the potential for loss from each risk. These are hard numbers. Evidence that an unauthorized person such as a hacker has accessed the machine means that, at a minimum, the system needs to be reformatted and built from the original media or backed up from a copy with known integrity. For the sake of argument, let us assume that this cost is $2000 in labor, along with $10,000 in lost productivity from those who rely on the server for their daily operations. Your risk analysis spreadsheet may have a line in it that reads:
| Server 1 | Hacker | $12,000 |
This value of $12,000 is known as the single loss expectancy (SLE) from the risk "Hacker." Another risk that we might add as an example is damage to the system board due to an electrical power surge. In this case, the data and OS may be intact but the server is offline until the system board can be replaced and tested. For purposes of discussion, let us assume that the cost in parts in labor creates a potential loss for this risk of $2000 and lost productivity amounts to another $15,000. Your asset sheet would contain another line:
| Server 1 | Hardware Failure — critical | $17,000 |
As a final example for use later on in the risk analysis process, we will also include a natural disaster, a tornado. In this case, a tornado may simply destroy the entire server, dump it in a river, or even send it to Oz. In either case, the hardware will be unusable by our company and must be replaced. The hardware must be replaced and any information on the server must be backed up from a backup (which is hopefully stored far away from the affected site and not sitting in Oz with your server at the time the backups are needed).
| Server 1 | Natural Disaster — tornado | $45,000 |
Another way to determine the SLE, and one that you might run across if pursuing a security certification is this equation:
Asset Exposure factor (EF) = SLE
While I prefer the more intuitive method, both will return the same results. The asset value is the same total value of the asset that we have discussed. The exposure factor (EF) is a fraction of the asset value that is lost per risk (i.e., the exposure factor percentage of value lost of the asset per risk exposure). When a server loses 50 percent of its value due to a worm attacking its SQL database, then we would say that the EF of such an incident is 0.5. If we assume that the total asset value of our database is $45,000 and that the EF for a hacker attack is 0.3, then
$45,000 0.3 = $13,500
In this case, the SLE would be $13,500. While academically — and according to risk analysis theory — this is the correct method to determine the SLE, when working with customers, users, managers, and finance and IT departments to determine these values, it is easier to get them to think in terms of total dollars of potential loss when considering a risk. The following conversation may be one such example:
"So Jerry, we have discussed the importance of your database to the overall operation of your business and we have provided an asset value of $45,000 once we consider all of the ways that this database contributes to your business. Now let's look at some specific risks. If a hacker were to compromise the server that housed the database, what do you think the exposure factor for the database would be? 0.2? 0.4? Higher? Come on, think!"
People have a difficult time thinking of their resources in these terms, especially if they are new to the process of risk analysis. It is far easier to work with Jerry to evaluate the potential loss by working with him to determine the steps and expenses that need to be in place to recover from the risk. The primary benefit of using the EF to determine the SLE is that the highest EF value you can have is "1." An EF of unity means that the SLE per risk would be the entire value of the asset. If Jerry were to describe to me $65,000 worth of work that would need to go into the recovery of the database due to a hacker, then either the value of the database has been underestimated to begin with, or Jerry needs to better understand his recovery processes.
A simpler way to determine the SLE is to calculate what it would cost to restore an asset to its original operating state prior to the incident. Jerry may say that the value of a particular server is $45,000. If the OS (operating system) needs to be reinstalled from a backup because of an attacker gaining unauthorized access to the system, then it is generally easier for people to figure out the dollar value than to estimate an exposure factor. In this case, Jerry might tell me that it normally takes four hours to restore a system from a backup and twelve hours to restore it from the original media. Accounting for the lost productivity and the hours spent restoring it, Jerry can estimate that the SLE from a database compromise would be, at the most, $25,000. That is a 0.55 EF, but Jerry does not need to know that.
Knowing the SLE, we can now perform a threat analysis. Recall that a threat can be human, natural, or technological in nature. Threats affect our systems through vulnerabilities. What must be determined is how often we can expect, on a yearly basis, to be exposed to particular threats if no countermeasures are put into place. This value is known as the annualized rate of occurrence (ARO). The ARO is represented as a frequency from 0.0 representing a chance of occurrence of 0% to any given high number integer. The 0.0 end of the spectrum means that this is a threat that will never materialize. On the other hand, an ARO of 1.0 means that it is certain that the threat will take advantage of a vulnerability within a given year. An ARO of 0.1 means once every ten years, while an ARO of 0.25 would mean the threat has an annualized rate of occurrence of once every four years.
The careful reader might note that any given risk can suffer from exposure more than once per year. The default operating system installation with standard installation options on the Internet has a life span of hours [5] before becoming the victim of an Internet attacker. Does this mean that my ARO should be 365.0 as my server could potentially be compromised 365 times in a year, and 366 times during a leap year? The ARO is correctly defined as the frequency with which an event will occur. Below a value of 1.0, however, this frequency is very similar to a probability. The difference is that the maximum allowable value for a probability is 1.0, meaning that the event will occur with certainty. Experts differ on whether an ARO above 1.0 is meaningful in their calculations of ARO. After all, it is presumed that the controls implemented to protect the operating system described above will apply and protect the device on more than just a single day of any given year. You will not have to implement a new security policy on the second of January after the risk to network attacks was reduced on the first of January. Combining the ARO to consider the total frequency over 1.0 can lead to incredible assessments of the cost of exposure on an annual basis. Assuming that it costs a company $50,000 in lost time and recovery costs for each network incident, an ARO of 364 would lead to an annual cost of $18,250,000. That does not mean that $15,000,000 spent protecting that operating system would be cost-effective. Instead, the ARO is typically calculated at a factor of 1.0, indicating that you can bet the bank that if you do not spend some money implementing controls to reduce the risk, you had better include at least $50,000 in the operating budget for recovery because your organization will be exposed to the risk at some point during the year.
How is the ARO determined? Again, through research. Many Web sites and security texts will explain what the ARO is, but I have yet to find a concise listing of the common network threats that details all human, natural, and technological threat agents that face our networks. Some ARO rates may be higher for one natural threat than others. In the northeastern United States, the ARO for tornados, floods, and earthquakes is quite low — not so in other parts of the world. The midwestern United States may have a much higher ARO for tornados than earthquakes, a situation that is reversed on the west coast of North America. Human threats may have to be based on company history. Can it be expected that given the opportunity, a well-meaning person could compromise an asset through deleting important files? Does the company have resources that are known to the world at large and likely to be the targets of hackers? In these cases, the ARO might be quite high. Is the company located in an urban area known for its crime rate? Is it right down the street from the local police station? All these elements contribute to the ARO of specific threats and need to be considered on a case-by-case basis. For some natural threats such as fire and flooding, the ARO can be quickly established through a conversation with a local insurance agent.
When the frequency or likelihood of the threat affecting us annually is combined with the loss that we can expect from a single exposure, we can then determine the annualized loss expectancy (ALE).
For those of you intending to create a spreadsheet that automatically calculates values based on columns, you can determine the annualized loss expectancy (ALE) using the following formula:
SLE ARO = ALE
That is, on a per-risk basis, a single loss exposure (SLE) will incur an average cost known as the annualized loss expectancy (ALE) based upon its frequency of occurring annually (ARO).
While we can conclude, based on past experience and security resources, that a machine with no protection will be hacked at some point, this is an event that we can count on occurring at least once a year if no countermeasures are put in place. The critical hardware failure, however, is not unheard of, but many computer systems can run for years without hardware failures affecting their performance. Based on the manufacturer's mean time between failures (MTBF) rating and our own experience, we will assume that a given server will face exposure to a critical hardware issue once every three years. Applying these values to our current risk analysis, we find annualized loss expectancies of:
| Server 1 | Hacker $12,000 (SLE) 12 (ARO) = $144,000 (ALE) |
| Server 1 | Hardware failure: critical $17,000 (SLE) 0.33 (ARO) = $5610 (ALE) |
| Server 1 | Natural disaster: tornado $45,000 (SLE) 0.01 (ARO) = $450 (ALE) |
Finally we have some information we can work with to help us create our security policy. Based on our estimations we can now decide how we want to handle the risk. Recall that our three options are to reduce the risk, assign the risk, or accept the risk.
Because continually restoring a server to an operational state each day would be time consuming and expensive and companies willing to assume the risk for such an event would be rare, your company decides to reduce the risk of hackers exploiting vulnerabilities on your server.
Part of our SLE calculations for the server's hardware failure assumed that the mean time to repair could be minimized by having the available hardware close to the affected server. This may mean keeping a stash of spare parts or even a complete server on standby in case of hardware failures. For a fee, some computer manufacturers will guarantee replacement parts delivered to your company within four hours. Paying the fee for prompt replacement parts would be a method of assigning the risk for hardware failures to a third party. Keeping parts handy would be a way of reducing the risk exposure of a critical hardware failure. In this example, we will reduce the risk by keeping a spare server on standby.
Keeping a server on standby would almost certainly cost more than $5610 annually because the hardware would have to be kept up, OS and software patches must be made to match the base configuration of other servers, and thorough documentation must be maintained for all possible uses of the server so that recovery can occur quickly and with a minimum of errors. For our example, we are going to assume that the risk analysis we are performing here is only a snapshot of a larger risk analysis where there are a number of servers that this backup server could service. In this case, applying the total cost of a standby server over a number of servers, say 10 to 15, would certainly make it economical.
What if the company did not need to reduce the risk of hardware failures on 10 to 15 servers? When we begin the discussion of applying countermeasures, we will discover that a company with only one server would not be making a wise financial decision to keep a standby server ready — unless the value of that server were increased greatly by the applications running on it. In this case, the cost of the countermeasure, a spare server, is too expensive relative to the value of the asset. In this case, paying a premium for priority service from a vendor might make more sense as far as risk reduction.
Finally, noting the annualized loss expectancy of the natural disaster, your company decides to have another party assume the risk. While it would be possible to create a tornado-proof enclosure for a server, the cost can be significantly prohibitive on an annualized basis, even when assuming that a single structure could protect a number of servers. Again, this decision is making several assumptions. One is that this is the cost to retrofit an existing structure with tornado-proof reinforcements. If the company is building a new plant, the cost of incorporating these countermeasures into new construction would be significantly less. Furthermore, as far as servers and the value of assets go, we have chosen fairly inexpensive assets. Increase the value of the assets by a factor of 10 or 100 and suddenly reducing the risk may be less expensive than assigning risk.
Let us assume now that the company is located in the Green Mountains of Vermont. In this case, the ARO of a natural disaster such as a tornado will be less than 0.01. For a company located in this region, they may even choose to accept the risk from tornados. The likelihood of a tornado that is powerful enough to destroy or even seriously damage a building — and then have it be your building — is pretty rare in the state. Based on its likelihood, it may not make economic sense to either reduce or assign the risk. The company will simply accept it with the understanding that if a tornado should hit, then the company may not be able to recover from the risk exposure.
A company might also determine that a combination of reducing risk and assigning it is the most cost-effective option. My insurance company reduces the amount of premium that I pay for fire insurance because I have working fire extinguishers and working smoke detectors in my home. While I cannot totally reduce the risk of fire to zero, I can reduce it to a point where the insurance company feels that my home is at less risk for destruction by fire than similar homes without such countermeasures. The same concept applies to risk analysis. By implementing a firewall to reduce the risk of a hacker exploiting local vulnerabilities, the risk has been reduced. The risk can be further reduced by employing defense in depth and by adding access controls to the servers, employing an IDS (intrusion detection system), using encryption for sensitive data when appropriate, etc. Each one of these countermeasures reduces the risk of the hacker threat. This process can continue indefinitely; however, for every countermeasure used, there is someone sitting around thinking of ways to defeat these countermeasures. Instead of spending more and more for that final bit of security, companies can assign the last bit of that risk to an insurance company or accept it.
In the process of doing a risk analysis, some pretty large numbers can show up. It is important to iterate at this point that we have not discussed countermeasures. Some countermeasures can reduce a number of risks in one shot. For example, a single packet filtering firewall can potentially protect hundreds of systems. When discussing countermeasures, we will use the ALE information to determine which countermeasure is the most effective from a technological and economic point of view.
The primary disadvantage of the quantitative approach, despite its accuracy, is that it is very difficult to do properly. Those of you wondering where all those values and numbers come from are right to wonder. Even inserting dollar amounts is somewhat subjective and dependent upon the source of those figures. There is no common agreement in the types of threats or threat frequency among vendors and risk analysts. Thus, without a good amount of previously recorded data, the data used to obtain the quantitative results is little more than a best guess from other experts. Another serious disadvantage is that while the calculations for quantitative analysis are sufficiently straightforward, the gathering of data is complex and not really feasible using a homegrown spreadsheet. Despite its accuracy then, most corporations and security experts rely on another method of assessing information security risks — qualitative analysis.
2.1.7 Qualitative Risk Analysis
Qualitative analysis uses the experience and intuition of those that are closest to or have the most knowledge of the company's assets. This means that people in the know will use their experience to evaluate what risks threaten assets and what the best countermeasure to employ against these threats would be. This method has the advantage of being very open and easy to accomplish. By trusting the expertise of those who work with the assets on a daily basis, a suggested regime of countermeasures can be deployed.
Because qualitative analysis heavily relies on people's judgment, it is most effective when a number of individuals participate in the process. Ideally, this can be facilitated through the use of questionnaires with a 1 to 10 scale, interviews, group meetings, detailed hypothetical questions — any technique that allows individuals to express their opinions regarding threats and reducing risk; however, allowing participants to brainstorm threats and solutions at the same time will do.
In practice, the element of getting everyone with a vested interest in the eventual security policy is the benefit of qualitative risk analysis. Often, a group of knowledgeable individuals will be able to identify more risks and propose a greater range of effective countermeasures than just one person.
The process of qualitative analysis works similarly to that of quantitative analysis, except without the numbers and formulas. First, the assets to be protected are identified. Brainstorming occurs to identify the potential risks that threaten each asset. Then, the group decides on the most effective countermeasure for each risk.
Qualitative analysis differs from quantitative analysis in that the calculations are less complex, but this approach still suffers from disadvantages. The primary issue is the subjective nature of the analysis and lack of objective data regarding the relative value of assets. This can lead to widely varying results as the actual worth of an asset is either under- or overestimated and the corresponding controls implemented are based upon this information. In some ways, however, this same disadvantage is what makes qualitative analysis the more popular of the risk analysis methods.
2.1.8 Combining Qualitative and Quantitative Risk Analysis
Depending on the organizational structure, management might be satisfied with the output of qualitative analysis. Some organizations may need to justify their expenses and thus need the details that a quantitative analysis provides. In practice, elements of both are used. When determining the exposure factor or the single loss expectancy (SLE) in a quantitative analysis, there is always a qualitative element. Few institutions will be able to authoritatively predict that, on average, the exposure factor (EF) for a given asset is 0.65 versus 0.50, or that the annualized rate of occurrence (ARO) for an exposure is 0.3 versus 0.5. These numbers are best and most accurately described through discussions with experts in the industry and individuals in your own company who are generally basing their reports on their own intuitions and experience.
2.1.9 Selecting Countermeasures
By this point we know what our network assets are. We have a good idea of the risks our assets face and how much they could cost us. Now what? Now is the time to determine what steps must be taken to protect those assets. In short, we must select countermeasures. Using the terms used in risk analysis, a countermeasure is anything that effectively reduces the exposure to a given risk. Thus, a countermeasure could reduce the SLE or reduce the ARO. Because the average ALE for any risk is based on these two values, anything that reduces either of them will effectively reduce the ALE as well.
A countermeasure can be a technical solution but it can also be an administrative or physical solution. Consider the ways that an unlocked server room can be taken advantage of. An effective countermeasure in this case might be as simple as a lock. If a lock and key are not enough to account for all those coming and going into the server room, then perhaps biometric authentication along with the lock might be sufficient. That would decrease the likelihood that the "key" to the lock will fall into the wrong hands. Here we have added a technological element to our physical lock. Perhaps this is still not enough, considering the value of our servers and the damage that anyone could do with physical access to them. Perhaps we will add the additional countermeasure of an armed guard at the door.
Before beginning the process of discussing countermeasures and the process of selecting effective countermeasures, there is an important thing to consider. When selecting countermeasures, technology alone is not the only option available. When people use the term "defense in depth" to discuss the proper implementation of information security, they are not referring to the use of four firewalls in a row. They mean: allow yourself to consider administrative and physical countermeasures as well. In some cases, these options may be more cost effective or more effective at reducing threat than technology alone.
When selecting countermeasures, we move into the implementation phase of our security policy. The risk analysis has told us what is important to protect. Countermeasures define how our assets are protected.
This is the step that most people start with when employing a network security plan. We choose what would be the best investment for the protection of our network. In choosing a countermeasure, we are looking for two elements. The first is that the countermeasure is a good value and makes good business sense to purchase. We establish this by computing a cost/benefit analysis. The second element of interest is the functionality and effectiveness of our countermeasures. If we can establish two solutions that will serve as an effective countermeasure for a given risk and both make good business sense, how can we compare these products to find the best value for our company? This section assists us in determining the cost/benefit of countermeasures and allows us to compare them as apples to apples.
2.1.10 Cost/Benefit Analysis
All the work that we have done up to this point has provided a background to allow us to make this critical decision — what countermeasures make the most sense with regard to network security and business sense for our network. Business sense means that the cost of the solution is less than the cost of the problem. To put it another way, it would not make good business sense to spend $100,000 a year to fix a problem that was only going to cost us, on average, $50,000 a year.
It should come as no surprise that there is a formula that helps us quantify this relationship.
Value of countermeasure = (Pre-countermeasure ALE) - (Post-countermeasure ALE) - (Cost of countermeasure)
We can plug in some numbers to help us digest its meaning. Using examples that we have been working with in this chapter, we have established that our Web server has an ALE of $5610 with regard to critical hardware failures. Let us say that through the use of power conditioners and redundant parts, we have reduced the ALE of an exposure from a critical hardware failure to $980 annually. Our solution of $2500 in spare parts and a power conditioner for the three-year cycle gives us a yearly cost of $2500/3 = $834. This would mean that the value of our countermeasure is:
$5610 - $980 - $834 = $3796
Thus, the value of our countermeasure would add up to $3796 in value for our company. This value could then be compared with other solutions that would reduce the risk the company faces from a critical hardware failure. If another solution reduced the risk equally as well, but had a value of $4214, then we would be able to quickly evaluate which of the two options presented the greater value or ROI (return on investment) to our company.
Because the ALE has already been calculated, there are essentially two ways to influence the value of the countermeasure. The first is that the post-countermeasure ALE can be adjusted. Countermeasure "A" might reduce the post-ALE to $100, while countermeasure "B" might reduce the post-ALE to only $2000. All other items being equal, countermeasure "A" would be the best solution. As an example, in securing our network against packet-based threats from the Internet, we have found two firewalls that perform according to our network needs. Based on the total cost of ownership, we have determined that one firewall actually reduces our ALE to only $100, while the second one reduces it to $2000. We now have a case for the first firewall being the better value for our business. This is not to say that the first firewall is a faster, more feature-rich firewall than the second. In fact, the second firewall may excel in performance and features but still not apply to the needs of our network or may cost too much to provide a significant value to our security needs.
The second part of the cost/benefit equation that can be modified is the cost of the countermeasure. A cheaper countermeasure "A" will create more value than a more costly countermeasure "B," assuming that the reduction in risk is identical for the two products. When determining the cost of a countermeasure, it is important not to simply use the number that is on the invoice. All of the costs that are part of implementing the countermeasure must be considered. This includes training, configuration, testing, changes to the network or physical environment to accommodate the countermeasure, compatibility with existing applications, and effects on the network including throughput and productivity. While countermeasure "A" may be cheap, when the company discovers that because of incompatibilities with existing applications, productivity decreases by 2 percent, suddenly countermeasure "A" does not seem like such a bargain.
This full analysis of the cost of a countermeasure can have surprising effects on the overall cost/benefit ratio for a given countermeasure. I am a big proponent of Linux and BSD, and often recommend these solutions to clients in need of a quality IDS and firewall product. Because a majority (but decreasing number) of networks that I typically consult for are Microsoft-only networks, the cost of training users to operate, update, and configure the Linux servers sometimes, unfortunately, puts the very low-cost solution in the position of being a lesser value for the company. Happily, this is changing but the only way to know if this is the case is to do a comprehensive risk and cost/benefit analysis using numbers as accurate as you can make them.
The selection of safeguards does not stop at determining the cost. There are a number of other factors to consider when evaluating the functionality and effectiveness of countermeasures. Some of the most important things to consider when evaluating products are described below. Going through a list like this, especially when comparing two different vendor's products, is especially helpful.
2.1.11 Consideration Points for Security Countermeasures
2.1.11.1 Acceptance by Users and Management.
The countermeasure must be of a form that is not overly intrusive to the lives or job functions of the network users. While providing living DNA samples for network authentication would certainly be a tough countermeasure for preventing unauthorized access to the network, most people would balk at such use. Acceptance is particularly important because it affects how hard people work to get around the countermeasure. This does not mean that the user has criminal intent; it is just that if the countermeasure is particularly difficult or cumbersome to use, users will, in an attempt to make their own jobs easier, figure out sometimes ingenious ways to circumvent the countermeasure. One example would be the use of randomly generated 16-character passwords that must be changed every 45 days. While effective at preventing password guessing, most users will simply end up writing their passwords on a piece of paper that they keep in a convenient location. Consider a form of countermeasure that was used by many dial-up ISPs. To prevent users from monopolizing an incoming flat rate dial-up connection, ISPs will require users to reconnect after a short period of inactivity. If this time period is too short, it annoys the users to the point where they will create fake traffic simply to ensure that the link stays open. By not fully considering the needs of the users the ISP loses its user's trust and has spent its money implementing a countermeasure that does not have the intended effect.
Acceptance is particularly interesting when considering access controls. Biometrics is a particular example where the most effective forms for biometrics (palm scans, hand geometry, retina scanning, and iris scanning) are the least popular among end users, while the least effective methods of biometrics (signature analysis and keystroke monitoring) are among the most popular for end users.
2.1.11.2 Affect on Asset.
Ideally, the countermeasure should not have an appreciable effect on the resource it protects. A classic example of this is the interoperability problems that network address translation (NAT) and IPSec encounter when used in some topologies. The countermeasure of implementing encryption has the undesired effect of changing the environment of the asset it is trying to protect. To get the countermeasure (IPSec) to work with the environment (NAT), reengineering the asset may be required. This increases the cost of the countermeasure, lowers its effectiveness, and introduces additional complexity that may have its own unknown effects on the network and network security.
2.1.11.3 Alerting Capability.
There are two elements to consider when evaluating the abilities of the countermeasure to alert administrators of significant events. The first is the avenue through which this can be done. Does the device support e-mail messaging? What if the network were to fail? Does the device support out-of-band alerting such as dialing a phone number and sending a page? The other element is the tuning ability of the alerts themselves. Generally, during the first couple of days after a countermeasure is installed, a new network administrator will excitedly have themselves alerted when any significant event occurs. After about the eighth alert, however, this grows old. Make sure that the device has the ability to tune the alerts to only those of a specific activity or alarm level. Being able to tune alerts within an alarm level is even better. After all, some critical alerts are more critical than others. If this capability is not present in the device, most alert systems generally end up being shut off altogether after a short period of time.
2.1.11.4 Auditing.
The countermeasure should support varying degrees of auditing. When troubleshooting an event or looking for a particular type of activity, verbose auditing is appropriate. Due to the size of the audit logs and the general difficulty in parsing through them looking for a specific event, the audit function should also include minimal audit reports to reduce the size of the audit information for most normal transactions.
2.1.11.5 Can Be Reset.
The countermeasure should be able to be reset to its original configuration or a stored configuration with minimal effect on the device or the asset it is protecting. The ability to quickly restart the system to a saved configuration is important if there is an error condition in the device itself — Microsoft Windows has trained us all that a restart can solve most problems. There will be a time, however, when either the network environment has changed so significantly, or the documentation regarding the configuration of the asset has been lost, that a return to its default operating condition is needed. Resets and restarts apply in all of these situations. Resets might also be required when there have been personnel changes and a lack of sufficient documentation on the network. At least one major VPN (virtual private network) vendor has a VPN appliance that does not have a password recovery procedure. If the administrator password to the VPN gateway is lost, then the only way to reset it is to ship the entire device back to the vendor. It is difficult to imagine a scenario that is more disruptive to your asset than having to remove the countermeasure (the VPN in this case) and express ship it back to the vendor for a (normally) simple password reset. It is also difficult to imagine a scenario that is more frustrating for the customer as well.
2.1.11.6 Countermeasure Is Independent of Asset It Is Protecting.
Ideally, we would like the ability to remove or change the countermeasure without affecting the asset. If the countermeasure is logically or physically distinct from the asset, this becomes easier to do. If the countermeasure is distinct, it is also easier for the device to protect a number of systems. As an example, consider a firewall system. You could purchase a single firewall and configure it as a host-based firewall — but it would only protect the host for which it was configured. If you choose to include your firewall as a stand-alone device, however, the same firewall could protect a number of hosts. This of course increases the cost/benefit analysis for a given device.
The same firewall, if host based, would by necessity disrupt the host if it needed to be upgraded or replaced. As a stand-alone system, however, a replacement could be dropped in with minimal disruption to the entire network.
2.1.11.7 Defaults to Least Privilege.
In an attempt to be user friendly, some popular modern operating systems default to a very insecure state. The application developers have rightly concluded that security adds to the complexity of a system and by choosing to have all but the most rudimentary security disabled, they are making a decision that favors ease of use over security. When choosing a security countermeasure, choose the product that defaults to a secure state. In the example of a firewall, in the absence of a configuration or the failure of the device, no traffic is allowed. This will certainly be inconvenient when it occurs, but consider the alternative — the firewall fails; but because it allows all traffic to pass (defaulting to no security), nobody notices because normal traffic is unaffected. When failing to a secure state, traffic is affected, but someone will also notice and investigate that there has been a device failure on the network.
2.1.11.8 Dependence on Other Components.
The ideal is a minimal dependence on other components to ensure proper operation. Complexity is regarded as the enemy of security and a countermeasure that relies on interactions with other components should be regarded in a less favorable light than those that can function independently of others. This is not to suggest that dependence and interactions are bad — sometimes, they cannot be avoided, as it may be the role of the device to interact or depend on other components. A central logging station would not serve its primary goal if it did not depend on the syslog messages that it is receiving from remote systems. Just keep in mind that when comparing two equivalent products, the one that operates the best independently should be given a higher ranking.
2.1.11.9 Differing Levels of Access.
The primary criteria are ensuring that there is clear distinction between user accounts and administrative accounts. This ensures our ability to audit access to the device. Ideally, there would be the ability to assign users administrative status instead of having a single administrative account. By being able to assign users to administrative status, the auditing of user activity is made easier. Think of the confusion that might occur if someone logged into a device at 10:30 a.m. as "administrator" and started making changes. If there were four people in the organization that knew the password, then it would be much more difficult finding out who made what changes — especially if the account password had been hacked, or sniffed, or the administrators wanted to otherwise cover their tracks. If we knew that Tom logged in at 10:30 a.m. with administrative access and began making changes to the device, then we have a place to start. Either Tom has been doing something that he should not have or Tom's account has been compromised. Either way, we are able to more effectively respond to the threat — either through administrative means with Tom or by simply changing his account information.
2.1.11.10 Flexible and Functional.
While this entire section is about choosing a product that is functional and effective, we are also concerned about product flexibility. Compare which options the countermeasure supports. For example, if you are evaluating VPN devices, what encryption protocols does it support? What IPSec modes are supported? As the user of the countermeasure, you should be able to configure only the options that you need and disable those do not need. The ability to easily select all options or none should also be available. It is during this stage of the evaluation that I also consider the interface that I must use to interact with the device. Do not be impressed with a pretty GUI (graphical user interface). Some GUIs greatly increase the amount of work you need to do to change configurations. Are the options logically located near each other, or do you need to wade through several screens of nested output to be able to find all relevant configuration options? Consider how you will interface with the device. Must all communications be done while physically attached to the device over a serial port? Is there a way to manage the device remotely? If the countermeasure can be controlled remotely, how can you ensure that the management session itself is secure? If the management interface is a Java-enabled Web page, will your current security policy or network configuration allow this type of traffic? Does the management interface present any significant risks of its own; and if disabled due to a risk exposure, is there a reliable way to connect to the device otherwise?
The flexibility and functionality of the device, both in its configuration options and management options, will significantly impact the training and operational costs associated with the device. It will also impact your own review of your security policy. If you invest in a device that is troublesome to work with, you will find that changes that can impact business decisions occur with less speed than desired. A prime example is a customer that has extended access lists on its routers to perform packet filtering and possibly even stateful packet inspection. While an access list can seem intimidating, a little familiarity goes a long way with them. I have run into customers with access lists more than 300 lines long. This was not because of business needs, it was because the person who first set up the list left the company and as the business needs of the company changed, the configuration of the access list changed to keep pace. This company, however, did not know how to properly modify access lists and so just kept appending new lines to allow new ports and IP address ranges through the router. All the old access remained as well. In the end, the access list became less than an effective countermeasure and more of vulnerability in its own right. This was because the users were not familiar or comfortable with its configuration.
2.1.11.11 Minimal Human Intervention Required.
There are any numbers of times that we have pointed at computers and said, "Why are you doing that? It's not right!" While we may be suspicious of expert claims that a computer cannot be malicious in its own right, most of the time they are not. There has been a configuration error on the part of a human. Undoubtedly, there can be programming errors as well; but on the whole, it is much more reliable for a computer to be able to interact with its environment and obtain the configuration information it needs. From a security perspective, the errors that humans mightcreate when configuring countermeasures also create new vulnerabilities. When comparing the effectiveness of countermeasures, consider the amount of configuration that needs to occur on each device in order for it to operate properly. Ideally, we would like countermeasures to "plug and play" as much as possible in the existing environment.
2.1.11.12 Modular in Nature.
Consider countermeasures that are modular in nature; they are superior to those that are not modular. This quality will allow us to install or remove the countermeasure with minimal impact on our assets or other countermeasures in the environment. The modular nature of a countermeasure may also contribute to the functionality and flexibility of the device. Consider a firewall product that also contains modules that will scan e-mail for viruses or Web traffic for suspicious content. While not all these functions may be required as part of our security policy, the ability to add them in the future, or selectively enable them as needed, can cut initial product costs and allow network administrators the flexibility to configure only countermeasures that are required for their network environment.
2.1.11.13 Output Is Easily Understandable.
Ultimately, people need to be able to use the information that the countermeasure is producing. This may be during troubleshooting, auditing, or general management of the device. Output that can be read by people without any special training is going to turn out to be much more valuable than information that needs to be converted from hex. Ideally, we would also like the ability to produce this information into reports that can be adjusted to highlight what we are trying to show. Thus, we would like the ability to produce outputs that allow us a more thorough technical analysis yet have the ability to modify that report in order to present a summary to management. Most vendors, in an effort to show the user friendliness of their product, will include report output that includes a great deal of graphs and colors. There is something to be said for visually representing data in a chart or graph; just make sure this information contains information relevant to your needs and that you have the ability to easily customize them.
Ideally, the countermeasure output should not require that you be part of the "in" crowd to be able to interpret it. Many of you may have heard of an excellent and free network sniffer product known as tcpdump. If you have not, this is a very common network sniffer used on networks. Some certification tracks, such as the SANS GIAC, require that you have a great deal of familiarity with the output of tcpdump. The output, however, can be less than clear to those new to the program or those who do not use it all the time. Before you fire up your e-mail editor to fire off an e-mail about the greatness that is tcpdump, let me assure you — I agree. When consulting with clients or others who do not spend all their time poring over text output, tcpdump is an example of a program that is lean, mean, fast, and free — but because of that, the output can either confuse or intimidate some. If people are confused or intimidated by their network tools, the tools will never be utilized to their full potential. When determining the functionality and effectiveness of a countermeasure, most companies will err on the side of a product that produces good output everyone understands over one that requires additional training costs to be absorbed in order to understand what the tool is telling you in the first place.
2.1.11.14 Provides Override Functionality.
Although this would seem like a dangerous feature to look for, it is often convenient to be able to override the countermeasure for certain network situations. I most commonly encounter this need when adding another asset to the network in the form of a new application or server. If something seems like it should be working correctly, but is not, it might be that the countermeasure itself is interfering with the new application. Instead of disabling the countermeasure, it is useful to override its protection for a brief period of time to isolate a network problem. If the device does provide an override function, it is also advantageous if it provides some sort of signal, visual or otherwise, that the override function has been enabled. It would be a shame to have your expensive countermeasure provide no risk reduction at all due to human forgetfulness.
2.1.11.15 Security of Device.
Clearly, because we are interested in improving the security of our network with our selected countermeasures, we will want to make sure that the countermeasure itself presents a minimum of vulnerabilities. This includes how access to the device can be secured — if it contains a Web server to provide Web-based management, does the Web server have any vulnerabilities? How is communication with the device encrypted? How are users authenticated? Given the ruthless examination given to security devices by both white-hat and black-hat hackers, it would be extraordinarily rare to find a countermeasure with no known vulnerabilities. While this is an unhappy position to be in — purchasing a countermeasure that will have its own vulnerabilities — you can protect yourself by examining your vendor's response to released weaknesses. Does the vendor only release a patch when forced to by the release of an attack? Does the vendor have a history of working with security researchers and releasing patches in a timely manner and in coordination with the researcher who discovered the vulnerability?
This final point is important to consider carefully. One of the worst positions that a network administrator can be in is when an important countermeasure has an exploit released or made public by a security researcher and there is no fix available. As soon as the vulnerability is made public, there will be a number of individuals who will create automated threats that seek to exploit this weakness. These threats can be executed via scripts or simply included in the next virus/worm/Trojan variant to be released onto the Internet.
This situation often arises for two reasons. The first is that the security "researcher" is simply looking to cause a bit of trouble. There is not much you can do about that other than hope that someone tracks them down and gives them what they deserve. Happily, a great many security researchers are conscientious and play an important role in the overall security of our networks. When they discover a significant vulnerability, they will often contact the vendor of the product and establish a reasonable timeline for the release of the vulnerability. This intern period will also give the vendor time to create and test an appropriate patch. When the process is executed in this manner, all sides win. The security researcher gets the credit he or she deserves for improving the security of our networks, the vendor is perceived as responsive to the needs of network security, and network administrators can patch their networks before the automated attacks are created.
This process sometimes breaks down, however. Some companies concerned with the perception that security flaws mean that their products may be considered inferior to consumers try to downplay the security vulnerability or refuse to acknowledge it. In this case, the researcher will generally release the exploit anyway in an effort to generate publicity and force the vendor's hand. When this is the case, your network may suffer. Prevent this situation as much as possible by not only investigating the overall security of the countermeasure itself, but also investigate — by contacting the vendor if necessary — the vendor's policy on responding to vulnerabilities and working with security researchers.
2.1.11.16 System Performance.
Some countermeasures can adversely impact the performance of your assets. The classic example is the IPSec VPN. Due to the complex process of data encryption and decryption on each end, network throughput can be affected. [6] Furthermore, the VPN device may only be able to handle state information for a limited number of IPSec sessions at any given time. Both of these factors can influence the perceived performance of your assets. When we discuss firewalls, we will learn that the additional processing that more "intelligent" firewalls need to perform over their simpler cousins will also create network delay. When comparing countermeasures, be sure to consider likely loads that they will face. If you have 500 remote office employees who will all be expected to use the VPN during their normal work hours, you will need a system that can easily support that many and is able to burst to even more connections. If you know that your firewall device is going to serve not only as a packet filter, but also scan e-mail for viruses, Web pages for suspicious content, and serve as a proxy for your 1000 employees, then a careful examination of the vendors' specs would be in order. In the firewall section, we discuss the features of the various firewalls described in the previous sentence, so do not be alarmed if some of those terms seem new.
Given today's computing power, most of these problems can be removed through the use of more powerful processors, faster and larger hard drives, and more system memory. This, of course, would increase the overall cost of the countermeasure and should be considered in the cost/benefit analysis.
2.1.11.17 Upgradeable.
It is important to ensure that the countermeasure has the capability to be tested and is upgradeable. Often, companies will try to save a few dollars in the short term and purchase hardware that is limited in expandability — only to find that their network and security needs grow as time passes. Purchasing an expandable solution in the first place may cost a bit more up front, but in the long run it will prevent the inevitable forklift upgrade.
2.1.11.18 Testable.
It is important that the countermeasure be evaluated on its ability to verify or test the protection it offers. This is also known as "auditing" capabilities. If it is not easy to see what the countermeasure is providing in the way of security, how can it be assured that it is actually offering security? Look for solutions that provide easy-to-find feedback on the protection they offer. This will make both the network administrator sleep better at night and make management happy that it has spent its security dollars wisely.
[1]Those new to the field of network security may think that this example is one of the enduring "urban legends" of networking. Those with more experience will nod sagely and recognize this very behavior in their own network users.
[2]An examination of this formula, although simplistic, shows a fundamental relationship between the elements of risk. A vulnerability without a threat does not produce risk, and a threat without a vulnerability to exploit likewise does not produce risk.
[3]These are not actual statistical chances of this event occurring. Please contact your local insurance agent for current "devastating meteorite" odds.
[4]The discipline of risk analysis is particularly attractive to those who have either a pessimistic streak or a macabre fixation with what could go wrong given the chance. Murphy was a risk analyst.
[5]The honeynet project (project.honeynet.org) has repeatedly demonstrated that the life expectancy of a "default" installation of most operating systems on the Internet is less than 24 hours. Default means no patches or other security mechanisms are applied — a sorry state for a device connected to the Internet.
[6]Do not let this fact alarm you too much. When we discuss VPNs, we will see that even devices with modest hardware (such as an old Pentium 133 sitting in the closet) will provide adequate throughput for links up to T-1 speeds of 1.544 Mbps.
|
EAN: 2147483647
Pages: 119