What Is XML Processing?
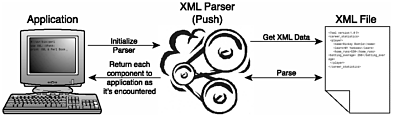
| What is XML processing? That is an often-asked question today given the popularity of XML. In the context of this book, I'll define XML processing as any task that involves XML data (for example, reading, writing, generating, and transforming). Examples of XML ProcessingXML processing can mean different things to different people, depending on what is important to them. What are some XML-related tasks ? A few of the more important XML- related topics that will be covered throughout the book are XML generation, XML validation, XML parsing, and XML transformation. Each of these topics will be introduced in the next few sections and then discussed in detail a little later in the book. XML documents must be generated before they can be processed , so generating XML documents is an important topic. There are several Perl modules that are specifically designed to facilitate generating XML from a variety of input sources. The input data source will usually determine the best XML generating module for each situation. For example, if you are converting an input CSV file to XML, you could use either the XML::Writer or XML::SAXDriver::CSV Perl modules. If your input data is store in a Microsoft Excel file, you could use the XML::SAXDriver::Excel Perl module to help with the generation. Finally, if you need to convert the results of a database query to XML, you could use the XML::Writer or the XML:: Generator::DBI modules. As you can see, you have a number of options when it comes to support for generating XML. I'll discuss all of these modules in greater detail and present examples a little later in the book. Validating XMLOnce we've generated an XML document (or received one from another source), there are Perl modules that will help you validate the XML document. An XML document is considered valid if it complies with a Document Type Definition (DTD) or XML schema. There are several Perl modules that support XML validation (for example, Apache Xerces), and they will be discussed later in the book. Parsing XMLParsing is a concept that goes back a long time (in programmer's time, not historical time). Parsing data, in simple terms, is to break the data down into the fundamental components that mean something to the application or the end user . An XML parser is a program that does exactly thatit parses an XML document based on the XML rules and syntax defined in the XML standard, and it provides that information to the requesting application. Information usually comes in a data structure for each construct. If the construct is queried by the application, it will give you information about the construct. For example, for the open element construct (which is recognized whenever the parser encounters a combination of characters similar to <element_name>), the parser provides the element's name and other relevant information to the appropriate event handler. Transforming XMLXML can be transformed to a number of different formats. For example, an XML document can easily be converted to another XML document, HTML, CSV, or any of a number of different formats. This feature of XML is very important and allows a great deal of flexibility when presenting XML data. There are a number of Perl modules that support XML transformation and they'll be discussed in detail throughout the book. Note Remember, there is a difference between data and information. The term data can be used to describe an entire XML document (data = markup + information). Information, on the other hand, is the actual information contained in the XML data. Note A short XML primer is included in Appendix A, "What Is XML?" to help refresh your memory or give you an abbreviated introduction to XML. XML ParsersParsers come in many different forms. Some XML parsers don't require any programming, you just provide an input XML document, and the parser generates the output data. Other XML parsers provide Application Programming Interfaces (APIs) that allow the programmer to manipulate its functionality from within the application code. APIs are usually highly customizable and come with many different features. In Perl, a parser module provides an API to an XML parser engine. This API hides most of the details of the inner workings from the typical user, while providing a clean, easy-to-use, and well-defined interface. Parsing an XML document involves reading the XML data and navigating through it while separating the contents of the XML document into meaningful components. Remember, XML data can come from a file, input stream (for example, a socket), a string, or just about any other possible data source. The most popular methods of parsing XML follow either the push model or the pull model. Each of these parsing methods is discussed in the following sections. Push Model of an XML ParserThe push model, as shown in Figure 2.1, is the core of the event-driven parsers. In the push model, special subroutines called event handlers are defined within your application. These event handlers are registered or tied to specific events and are automatically called by the XML parser when a particular event occurs. The push model was given its name because whenever a particular event is encountered, it pushes the event (and some event-specific data) to a predefined handler in the application. For example, you can define subroutines that are called when a start tag is encountered, when an end tag is encountered , and so forth. Using a little logic that we'll demonstrate , it is fairly straightforward to parse an XML document and extract its contents. Figure 2.1. Applications built using a push-based XML Parser play a passive role and receive data that is pushed from the XML parser. As you can see, this is a passive approach to parsing because your application waits for data to arrive . Basically, three steps are involved in this approach.
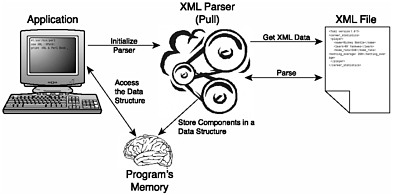
Of course, there is a little more to it, but that is basically what happens. It's important to understand the concept at a high level. This way, when we present the examples and discuss the code that actually performs each of these steps, you will have a good understanding of the process. Event-driven parsers and their underlying concepts are discussed in detail in Chapter 3, "Event-Driven Parser Modules." Pulling XML Parser Events to the ApplicationThe pull model defines another parsing model. In this model, the application controls the parser and pulls the information from the parser as the parser iterates through the XML data. Figure 2.2 illustrates the pull XML parser model. Figure 2.2. Applications built using a pull-based XML parser play an active role in the parsing by pulling data from the XML document. As opposed to the push model, the pull model requires the application to play a more active role in the parsing of the document. The pull model basically parses the XML data and holds it in a tree structure. In order to retrieve data, the application then must walk up and down through the tree and extract the desired sections of the XML data. The pull model is discussed in detail in Chapter 4, "Tree-Based Parser Modules." Together, these two paradigms form the basis of most XML parsers. We'll discuss the advantages and disadvantages of the push and pull methods throughout the book. |