Configuration Server
| The purpose of the Configuration Server is to execute client-initiated directives made against NEs. Like the Fault Server, it also faces into the network but operates in a less open -ended way because it is not required to process asynchronous NE-originated notifications. However, the complexity of the Configuration Server lies in the way it can both write to and read from the network. As we'll see, the bidirectional nature of this SNMP traffic puts additional demands on the Configuration Server software. Many NMS do not provide a configuration feature and instead restrict their baseline functions to fault management and discovery. A full-featured NMS will include a Configuration Server as a key component. Let's assume that a client user creates an LSP as was shown in Chapter 2, "SNMPv3 and Network Management," Figure 2-7. As we've seen, this involves the creation of an entry in the MPLS tunnel table (Figure 2-5). Depending on the type of LSP, this may require other tables to be updated as well, but for simplicity let's assume that the LSP is:
We also assume that no route object is needed because the ingress LER computes the required path . So, the NMS must create a new row in the LER1 MIB MPLS tunnel table. The user specifies the required data for this row, as shown in Table 6-1. Table 6-1. LSP Configuration Data
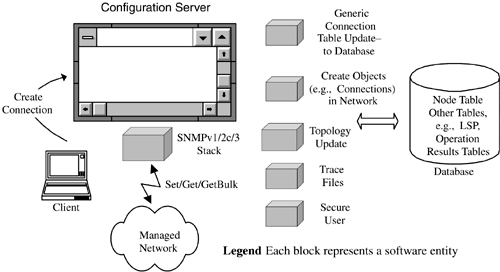
This data is written to the database and submitted to the Configuration Server as a type of job, and from there it must be translated into a form suitable for the MIB of LER1. The Configuration Server must therefore translate the Table 6-1 items into one or more SNMP setRequest messages. One possible structure for a Configuration Server is illustrated in Figure 6-5. Figure 6-5. Configuration Server components . Secure UserSince the end user can access NE data, it is essential that security is in place. This may be required if many users can remotely connect to the Configuration Server. For SNMPv1/v2c, the security amounts to read and write community strings. For secure SNMP operations (version 3), the user may be required to supply security credentials (authentication and encryption) if these are not automatically supplied by the NMS. For SNMPv3, the security settings can be:
If authentication, encryption, or both are specified, then the client user may be requested to supply corresponding passwords. In addition, if authentication has been specified, then it is necessary to indicate the required authentication protocol: MD5 or SHA1. The user may also be required to specify the SNMP timeout value (e.g., 5 seconds), the number of retries, and the port numbers to use (normally 161 for set s/ get s and 162 for notifications). Securing the user (i.e., ensuring that the user has security clearance to execute the required operations) can be achieved in two steps:
After this, the network has been secured against an insecure user. Trace FilesDuring software development, trace files are an indispensable means of tracking software execution paths. They can help in locating problems such as:
It is very useful to be able to switch tracing facilities on and off even in deployed systems. Generic Connection Table UpdateThe need for generic GUI components was mentioned earlier in the chapter in relation to terminal servers. Keeping connection types as generic as possible helps simplify the NMS. The front end presents similar screens for multiple connection types, such as:
The user is allowed to select the endpoints for the connection, resources needed, and the route to take, and this data is then written to the database. In this way, there is a complete logical separation between the GUI and the provisioning backend (described next ). Create Network ObjectsOnce the requisite connection objects have been stored in the database, they must be written to the network. For signaled connections (ATM or MPLS), this may require just writing to the MIB of the originating node. This is relatively simple. For unsignaled connections (e.g., ATM PVX), the provisioning code may have to write data to each node in the path. This is a more complex exercise, particularly if errors occur. The latter raises difficult questions: Should the entire operation be aborted and rolled back, or should the partial data be left on the network and the user notified? One approach is to leave the network clean (roll back any MIB sets if all operations do not succeed) and flag the problem to the user visually and in a log file. Topology UpdateAs for the Fault Server, many configuration changes will be of interest to clients , and again it may be necessary for a topology update to occur after important changes such as:
These changes are made in the central database and then applied to the network. Any registered, viewing clients will subsequently see the changes reflected in their topology GUI. Configuration Server Database TablesTypical tables used by a Configuration Server can be
The generic connection tables may be split into a number of technology-specific sub-tables. Common elements of all connection types (e.g., source and destination nodes, resources used) can be stored in one table, while the technology-specific settings are stored in other tables. These tables are updated as configuration changes occur. Configuration Server MIB SupportSince the Configuration Server interacts directly with NE MIBs, it must support possibly many different versions of the same MIB and a variety of other MIBs. This should be transparent to the end user. Issues such as MIB holes should also be handled as transparently as possible. A MIB hole occurs when a given column in a table has no value, as illustrated in the extract from the MPLS tunnel table shown in Table 6-2. Table 6-2. MPLS Tunnel Table Extract with a MIB Hole
Before we describe the MIB hole, let's briefly review the way MIB object instances are accessed. Scalar objects have only a single instance value within a MIB. The object instance of a scalar is distinguished from the underlying object type by appending a zero to the OID. MIB table object instances, however, are accessed by appending the index value. The columns in Table 6-2 are referenced by using a notation made up of the value of the mplsTunnelIndex and the column name; for example, mplsTunnelSignallingProto.3 has the value 1. We'll see more of this type of indexing in Chapter 8. The shaded entry in Table 6-2 is a MIB hole. A get-next request on the object mplsTunnelSetupPrio.1 will return the value 5, that is, the value of mplsTunnelSetupPrio.3 . If the request is part of an NMS NE MIB query, then this may not be what was intended. It is up to the NMS software to either return, say, 1 or to give some indication that a hole was found. Also, a get request on mplsTunnelSetupPrio.2 will result in a No Such Name exception. Holes can cause similar problems when trying to perform row-based operations. The details of avoiding problems with MIB holes and retrying failed operations (e.g., due to agent timeouts) are all buried in the Configuration Server software. Keeping clear (layered) lines of demarcation between the various technologies helps to maintain a degree of simplicity in the software. In other words, it is generally a good idea to keep issues relating to SNMP access out of application code. This helps reduce clutter in the latter by isolating complexities such as retries in the event of timeouts or other exceptions. A clean API into the SNMP access code can help fulfill this need. Configuration Server Software StructureThe Configuration Server can be hosted on its own platform (e.g., a Solaris, HP-UX, Windows 2000 system) or on a system shared with other FCAPS servers. The principal challenges facing the designers of a Configuration Server are as follows :
Unlike the Fault Server, the Configuration Server does not generally have to cope with persistently high levels of ( unsolicited ) NE-originated traffic. However, during periods of high client activity (e.g., 30 operators each bulk-creating 100 PVX circuits that span the network), the Configuration Server must be able to withstand bursts of incoming traffic resulting directly from the provisioning actions. The latter is caused by reads from the NE MIBs and/or from set operation responses. |
EAN: 2147483647
Pages: 150