RAID Technology
| Redundant Array of Inexpensive Disks (RAID) is used to configure a disk subsystem to provide better performance and fault tolerance for an application. The basic idea behind using RAID is that you spread data across multiple disk drives so that I/Os are spread across multiple drives . RAID has special significance for database- related applications, where you want to spread random I/Os (data changes) and sequential I/Os (for the transaction log) across different disk subsystems to minimize head movement and maximize I/O performance. The four significant levels of RAID implementation that are of most interest in database implementations are as follows :
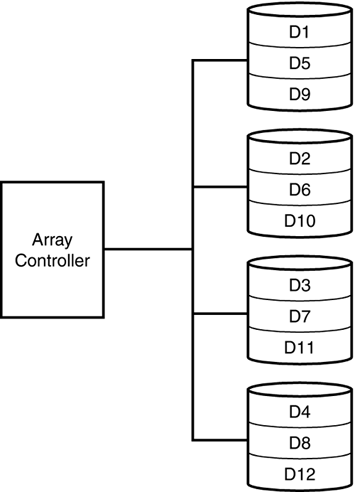
RAID Level 0RAID Level 0 provides the best I/O performance among all other RAID levels. A file has sequential segments striped across each drive in the array. Data is written in a round- robin approach to ensure that data is evenly balanced across all drives in the array. However, if a media failure occurs, no fault tolerance is provided and all data stored in the array is lost. RAID 0 should not be used for a production database where data loss or loss of system availability is not acceptable. RAID 0 is occasionally used for tempdb to provide the best possible read and ( especially ) write performance. RAID 0 is helpful for random read requirements, such as those that occur on tempdb and in data segments.
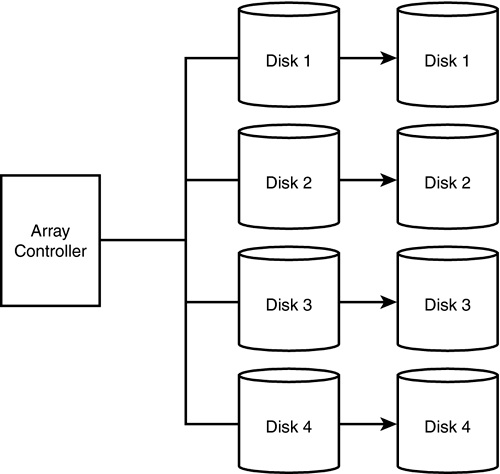
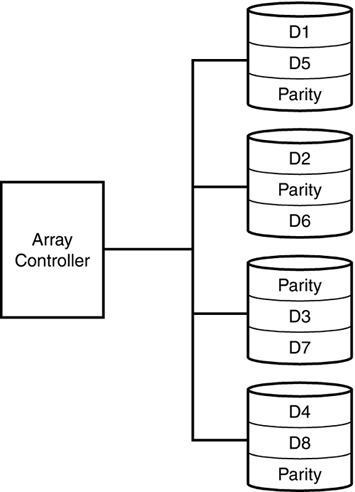
RAID 0 is the cheapest of the RAID configurations because 100 percent of the disks in the array are available for data, and none are used to provide fault tolerance. Performance is also the best of the RAID configurations since there is no overhead required to maintain redundant data. Figure 39.3 depicts a RAID 0 disk array configuration. Figure 39.3. RAID Level 0. RAID Level 1RAID Level 1 is known as disk mirroring. Every write to the primary disk is written to the mirror set. Either member of the set can satisfy a read request. RAID 1 devices provide excellent fault tolerance because in the event of a media failure, either on the primary disk or the mirrored disk, the system can still continue to run. Writes are much faster than RAID 5 arrays as no parity information needs to be calculated first. The data is simply written twice. RAID 1 arrays are best for transaction logs and for index file groups. RAID 1 provides the best fault tolerance, and the best write performance, which is critical to log and index performance. Since log writes are sequential write operations and not random access operations, they are best supported by a RAID 1 configuration. RAID 1 arrays are the most expensive RAID configuration because only 50 percent of total disk space is available for actual storage. The rest is used to provide fault tolerance. Figure 39.4 shows a RAID 1 configuration. Figure 39.4. RAID Level 1. Because RAID 1 requires the same data be written to two drives at the same time, write performance will be slightly less than writing data to a single drive because the write will not be considered complete until both writes have been done. Using a disk controller with a battery- backed write cache can mitigate this write penalty because the write will be considered complete once it occurs to the battery-backed cache. The actual writes to the disks will occur in the background. RAID 1 read performance will often be better than a single disk drive as most controllers now support split seeks. Split seeks allow each disk in the mirror set to be read independently of each other, thereby supporting concurrent reads. RAID Level 10RAID 10, or RAID 0+1, is a combination of mirroring and striping. If you find that your transaction log or index segment is pegging your RAID 1 array at 100 percent usage, you can implement a RAID 10 array to get better performance. This type of RAID carries with it all the fault tolerance (and cost!) of a RAID 1 array, with all the performance benefits of RAID 0 striping. RAID Level 5RAID 5 is most commonly known as striping with parity. In this configuration, data is striped across multiple disks in large blocks. At the same time, parity bits are written across all the disks for a given block. Information is always stored in such a way that any one disk can be lost without losing any information in the array. In the event of a disk failure, the system can still continue to run (at a reduced performance level) without downtime by using the parity information to reconstruct the data that was lost on the missing drive. Some arrays provide "hot standby" disks. The RAID controller uses the standby disk to rebuild a failed drive automatically using the parity information stored on all the other drives in the array. During the rebuild process, performance is markedly worse . The fault tolerance of RAID 5 is usually sufficient, but if more than one drive in the array fails, you will lose the entire array. It is recommended that a spare drive be kept on hand in the event of a drive failure, so the failed drive can be replaced quickly before any other drives have a chance to fail.
RAID 5 provides excellent read performance, but expensive write performance. A write operation on a RAID 5 array requires two writes: one to the data drive and one to the parity drive. After the writes are complete, the controller will read the data to ensure that the information matches (no hardware failure has occurred). A single write operation will cause four I/Os on a RAID 5 array. For this reason, putting log files or tempdb on a RAID 5 array is not recommended. Index filegroups, which suffer worse than data filegroups from bad write performance, are also poor candidates for a RAID 5 array. Data filegroups where more than 10 percent of the I/Os are writes are also not good candidates for RAID 5 arrays. Note that if write performance is not an issue in your environmentfor example, in a DSS/Data Warehousing environmentyou should, by all means, use RAID 5 for your data and index segments. In any environment, avoid putting tempdb on a RAID 5 array. tempdb typically receives heavy write activity and will perform better on a RAID 1 or RAID 0 array. RAID 5 is a relatively economical means of providing fault tolerance. No matter how many drives are in the array, only the space equivalent to a single drive is used to support fault tolerance. This method becomes more economical with more drives in the array. You must have at least three drives in a RAID 5 array. Three drives would require that 33 percent of available disk space be used for fault tolerance, four would require 25 percent, five would require 20 percent, and so on. Figure 39.5 shows a RAID 5 configuration. Figure 39.5. RAID Level 5.
|
EAN: 2147483647
Pages: 503