Lesson 1: Understanding the Database Architecture
3 4
As discussed earlier in this book, each SQL Server 2000 database (system or user) consists of at least one data file and at least one transaction log file. This lesson covers the architecture of these data files, including the allocation and management of space and the organization of data and index pages within data files.
After this lesson, you will be able to
- View the properties of data files
- Understand how SQL Server 2000 allocates and manages space within a data file
- Understand how SQL Server 2000 organizes data and index pages within a data file
Estimated lesson time: 15 minutes
Introducing Data Files
Each SQL Server 2000 database has one primary data file and can have secondary data files, each of which is used only by that database. Each data file is a separate operating system file. The primary data file generally has the .MDF filename extension (this extension is not required but is useful for identification). This primary data file stores data in tables and indexes and contains the startup information for the database. It contains system tables that track objects in the database, including file location information about all additional files in the database (secondary data files and transaction log files). Each secondary data file generally has the .NDF filename extension (this extension is also not required). Secondary data files are used primarily when a database spans multiple disk drives.
SQL Server 2000 records the locations of all the database files in two places: in the master database and in the primary file for the database. Most of the time, the database engine uses the file location information found in the master database. The exception to this rule occurs when you perform operations that cause the database engine to use the file location information found in the primary file to initialize the file location entries in the master database. These operations are upgrading from SQL Server 7.0 to SQL Server 2000, restoring the master database, and attaching a database to SQL Server 2000 using the sp_attach_db system stored procedure.
Each data file (primary and secondary) has a logical filename (logical_file_name) used in Transact-SQL statements and a physical filename (os_file_name) used by the Windows operating system. The logical filename must be unique to the specified database and must also conform to the SQL Server identifier rules. For further information about logical filename identifiers, see "Using Identifiers" in SQL Server Books Online. The physical filename must conform to the rules of file-naming conventions for the particular operating system you are using.
Additional data file properties include the file ID, initial file size, file growth increment (if any), and maximum file size. These data file properties are stored in the File Header page, which is the first page of each data file. SQL Server uniquely identifies pages in a data file by file ID and page number. Pages in a data file are numbered sequentially starting at zero. Defining and altering the properties of a data file are covered in Chapter 6.
Note
SQL Server data and log files cannot be stored on compressed file systems.
Practice: Viewing the Properties of a Data File
In this practice you use SQL Server Enterprise Manager to view some of the properties of a data file.
To view the properties of a data file
- Ensure that you are logged on to the SelfPacedSQL.MSFT domain controller as Administrator.
- Click Start, point to Programs, point to Microsoft SQL Server, and then click Enterprise Manager.
SQL Server Enterprise Manager appears displaying the Microsoft SQL Servers and the Event Viewer (Local) console trees in the console root.
- In the console tree, expand the Microsoft SQL Servers container, expand the SQL Server Group container, expand the default instance, and then expand Databases.
- In the console tree, right-click Master and then click Properties.
The Master Properties dialog box appears with the General tab selected, displaying various properties of the master database, such as the database status, date of last backup, and collation name.
- Click the Data Files tab.
The File Name column on the Data Files tab, displays the logical filename of the master database.
- Expand the width of the Location column by sliding the column bar to the right.
The name and complete file path of the operating system file are displayed.
- Reduce the width of the Location column so you can view the Space Allocated (MB) column.
The current space allocated is displayed. Most systems will display 12 MB. This is the initial size of the master database (which is rounded to the nearest whole number).
- Click Cancel to close the Master Properties dialog box.
- Close SQL Server Enterprise Manager.
Allocating Space for Tables and Indexes
Before SQL Server 2000 can store information in a table or an index, free space must be allocated from within a data file and assigned to that object. Free space is allocated for tables and indexes in units called extents. An extent is 64 KB of space, consisting of eight contiguous pages, each 8 KB in size. There are two types of extents, mixed extents and uniform extents. SQL Server 2000 uses mixed extents to store small amounts of data for up to eight objects within a single extent and uses uniform extents to store, whereas SQL Server 2000 uses uniform extents to store data from a single object.
When a new table or index is created, SQL Server 2000 locates a mixed extent with a free page and allocates the free page to the newly created object. A page contains data for only one object. When an object requires additional space, SQL Server 2000 allocates free space from mixed extents until an object uses a total of eight pages. Thereafter, SQL Server 2000 allocates a uniform extent to that object. SQL Server 2000 will grow the data files in a round-robin algorithm if no free space exists in any data file and autogrow is enabled.
When SQL Server 2000 needs a mixed extent with at least one free page, a Secondary Global Allocation Map (SGAM) page is used to locate such an extent. Each SGAM page is a bitmap covering 64,000 extents (approximately 4 GB) that is used to identify allocated mixed extents with at least one free page. Each extent in the interval that SGAM covers is assigned a bit. The extent is identified as a mixed extent with free pages when the bit is set to 1. When the bit is set to 0, the extent is either a mixed extent with no free pages, or the extent is a uniform extent.
When SQL Server 2000 needs to allocate an extent from free space, a Global Allocation Map (GAM) page is used to locate an extent that has not previously been allocated to an object. Each GAM page is a bitmap that covers 64,000 extents, and each extent in the interval it covers is assigned a bit. When the bit is set to 1, the extent is free. When the bit is set to 0, the extent has already been allocated.
Note
SQL Server 2000 can locate GAMs and SGAMs quickly because they are the third and fourth pages in the first extent allocated within a data file. The first page in the first extent is the File Header page and the second page is the Page Free Space (PFS) page.
When SQL Server 2000 allocates a page within a mixed extent or a uniform extent to an object, it uses an Index Allocation Map (IAM) page to track all pages allocated to a table or an index. Each IAM page covers up to 512,000 pages, and IAM pages are located randomly within the data file. All IAM pages for an object are linked together, the first IAM page pointing to the second IAM page, and so on.
When SQL Server 2000 needs to insert data into pages allocated for an object, it uses the PFS page to locate an allocated page with available space. PFS pages within a data file record, using a bitmap, whether a page has been allocated and the amount of free space on an allocated page (empty, 1–50 percent full, 51–80 percent full, 81–95 percent full, or more than 95 percent full). Each PFS page covers 8,000 contiguous pages. The second page in the first extent in a data file contains the first PFS page, and every 8000th page thereafter contains a PFS page.
Storing Index and Data Pages
In the absence of a clustered index, SQL Server 2000 stores new data on any unfilled page in any available extent belonging to the table into which the data is being inserted. This disorganized collection of data pages is called a heap. In a heap, the data pages are stored in no specific order and are not linked together. In the absence of either a clustered or a nonclustered index, SQL Server 2000 has to search the entire table to locate a record within the table (using IAM pages to identify pages associated with the table). On a large table, this complete search is quite inefficient.
To speed this retrieval process, database designers create indexes for SQL Server 2000 to use to find data pages quickly. An index stores the value of an indexed column (or columns) from a table in a B-tree structure. A B-tree structure is a balanced hierarchal structure (or tree) consisting of a root node, possible intermediate nodes, and bottom-level leaf pages (nodes). All branches of the B-tree have the same number of levels. A B-tree physically organizes index records based on these key values. Each index page is linked to adjacent index pages.
SQL Server 2000 supports two types of indexes, clustered and nonclustered. A clustered index forces the physical ordering of data pages within the data file based on the key value used for the clustered index (such as last name or zip code). The leaf level of a clustered index is the data level. When a new data row is inserted into a table containing a clustered index, SQL Server 2000 traverses the B-tree structure and determines the location for the new data row based on the ordering within the B-tree (moving existing data and index rows as necessary to maintain the physical ordering). See Figure 5.1.
The leaf level of a nonclustered index contains a pointer telling SQL Server 2000 where to find the data row corresponding to the key value contained in the nonclustered index. When a new data row is inserted into a table containing only a nonclustered index, a new index row is entered into the B-tree structure, and the new data row is entered into any page in the heap that has been allocated to the table and contains sufficient free space. See Figure 5.2.
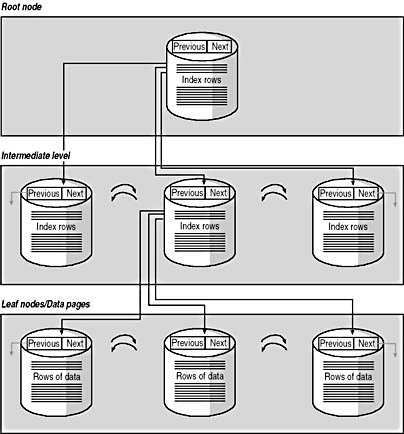
Figure 5.1
Structure of a clustered index.
Lesson Summary
SQL Server 2000 uses one or more data files to store information in tables and indexes. Data files are operating system files. Tables and indexes are allocated individual pages from mixed extents or uniform extents based on the number of pages used by these objects. A number of special pages are used to track free space within a data file, the pages and extents that have been allocated to an object, and the amount of available space on allocated pages. Data pages are stored in a disorganized heap unless a clustered index exists on a table. Nonclustered indexes are used to point to data pages in a heap or in a clustered index structure. If a clustered index exists, data pages are physically ordered based on the index key and stored in a B-tree structure. Index pages are always stored in a B-tree structure.
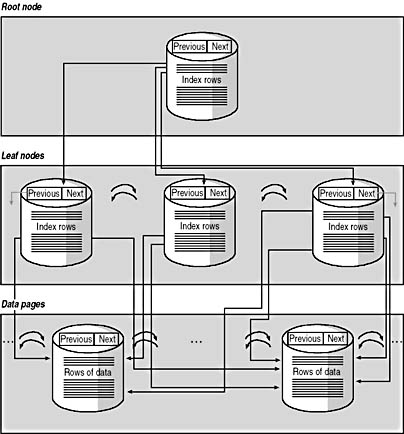
Figure 5.2
Structure of a nonclustered index.
EAN: N/A
Pages: 126