Chapter 2. The UNIX Toolbox
| CONTENTS |
- 2.1 Regular Expressions
- 2.2 Combining Regular Expression Metacharacters

There are hundreds of UNIX utilities available, and many of them are everyday commands such as ls, pwd, who, and vi. Just as there are essential tools that a carpenter uses, there are also essential tools the shell programmer needs to write meaningful and efficient scripts. The three major utilities that will be discussed in detail here are grep, sed, and awk. These programs are the most important UNIX tools available for manipulating text, output from a pipe, or standard input. In fact, sed and awk are often used as scripting languages by themselves. Before you fully appreciate the power of grep, sed, and awk, you must have a good foundation on the use of regular expressions and regular expression metacharacters. A complete list of useful UNIX utilities is found in Appendix A of this book.
2.1 Regular Expressions
2.1.1 Definition and Example
For users already familiar with the concept of regular expression metacharacters, this section may be bypassed. However, this preliminary material is crucial to understanding the variety of ways in which grep, sed, and awk are used to display and manipulate data.
What is a regular expression? A regular expression[1] is just a pattern of characters used to match the same characters in a search. In most programs, a regular expression is enclosed in forward slashes; for example, /love/ is a regular expression delimited by forward slashes, and the pattern love will be matched any time the same pattern is found in the line being searched. What makes regular expressions interesting is that they can be controlled by special metacharacters. If you are new to the idea of regular expressions, let us look at an example that will help you understand what this whole concept is about. Suppose that you are working in the vi editor on an e-mail message to your friend. It looks like this:
% vi letter ------------------------------------------------------------------ Hi tom, I think I failed my anatomy test yesterday. I had a terrible stomach ache. I ate too many fried green tomatoes. Anyway, Tom, I need your help. I'd like to make the test up tomorrow, but don't know where to begin studying. Do you think you could help me? After work, about 7 PM, come to my place and I'll treat you to pizza in return for your help. Thanks. Your pal, guy@phantom ~ ~ ~ ~ ------------------------------------------------------------------ Now, suppose you find out that Tom never took the test either, but David did. You also notice that in the greeting, you spelled Tom with a lowercase t. So you decide to make a global substitution to replace all occurrences of tom with David, as follows:
% vi letter ------------------------------------------------------------------ Hi David, I think I failed my anaDavidy test yeserday. I had a terrible sDavidachache. I think I ate too many fried green Davidatoes. Anyway, Tom, I need your help. I'd like to make the test up Davidorrow, but don't know where to begin studying. Do you think you could help me? After work, about 7 PM, come to my place and I'll treat you to pizza in return for your help. Thanks. Your pal, guy@phanDavid ~ ~ ~ --> :1,$s/tom/David/g ------------------------------------------------------------------
The regular expression in the search string is tom. The replacement string is David. The vi command reads "for lines 1 to the end of the file ($), substitute tom everywhere it is found on each line and replace it with David." Hardly what you want! And one of the occurrences of Tom was untouched because you only asked for tom, not Tom, to be replaced with David. So what to do?
Regular expression metacharacters are special characters that allow you to delimit a pattern in some way so that you can control what substitutions will take place. There are metacharacters to anchor a word to the beginning or end of a line. There are metacharacters that allow you to specify any characters, or some number of characters, to find both upper- and lowercase characters, digits only, and so forth. For example, to change the name tom or Tom to David, the following vi command would have done the job:
:1,$s/\<[Tt]om\>/David/g This command reads, "From the first line to the last line of the file (1,$), substitute (s) the word Tom or tom with David," and the g flag says to do this globally (i.e., make the substitution if it occurs more than once on the same line). The regular expression metacharacters are \< and \> for beginning and end of a word, and the pair of brackets, [Tt], match for one of the characters enclosed within them (in this case, for either T or t). There are five basic metacharacters that all UNIX pattern-matching utilities recognize, and then an extended set of metacharacters that vary from program to program.
2.1.2 Regular Expression Metacharacters
Table 2.1 presents regular expression metacharacters that can be used in all versions of vi, ex, grep, egrep, sed, and awk. Additional metacharacters are described for each of the utilities where applicable.
| Metacharacter | Function | Example | What It Matches |
|---|---|---|---|
| ^ | Beginning-of-line anchor | /^love/ | Matches all lines beginning with love. |
| $ | End-of-line anchor | /love$/ | Matches all lines ending with love. |
| . | Matches one character | /l..e/ | Matches lines containing an l, followed by two characters, followed by an e. |
| * | Matches zero or more of the preceding characters | / *love/ | Match lines with zero or more spaces, followed by the pattern love. |
| [ ] | Matches one in the set | /[Ll]ove/ | Matches lines containing love or Love. |
| [x y] | Matches one character within a range in the set | /[A Z]ove/ | Matches letters from A through Z followed by ove. |
| [^ ] | Matches one character not in the set | /[^A Z]/ | Matches any character not in the range between A and Z. |
| \ | Used to escape a metacharacter | /love\./ | Matches lines containing love, followed by a literal period. Normally the period matches one of any character. |
| Additional metacharacters are supported by many UNIX programs that use RE metacharacters: | |||
| \< | Beginning-of-word anchor | /\<love/ | Matches lines containing a word that begins with love (supported by vi and grep). |
| \> | End-of-word anchor | /love\>/ | Matches lines containing a word that ends with love (supported by vi and grep). |
| \(..\) | Tags match characters to be used later | /\(love\)able \1er/ | May use up to nine tags, starting with the first tag at the left-most part of the pattern. For example, the pattern love is saved as tag 1, to be referenced later as \1; in this example, the search pattern consists of lovable followed by lover (supported by sed, vi, and grep). |
| x{m\}or x{m,\}or x{m,n\} | Repetition of character x, m times, at least m times, at least m and not more than n times[a] | o{5,10\} | Matches if line contains between 5 and 10 consecutive occurrences of the letter o (supported by vi and grep). |
[a] Not dependable on all versions of UNIX or all pattern-matching utilities; usually works with vi and grep.
Assuming that you know how the vi editor works, each metacharacter is described in terms of the vi search string. In the following examples, characters are highlighted to demonstrate what vi will find in its search.
Example 2.1
(A Simple Regular Expression Search) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /love/ -----------------------------------------------------------------
EXPLANATIONThe regular expression is love. The pattern love is found by itself and as part of other words, such as lovely, gloves, and clover. |
Example 2.2
(The Beginning-of-Line Anchor (^)) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /^love/ -----------------------------------------------------------------
EXPLANATIONThe caret (^) is called the beginning-of-line anchor. Vi will find only those lines where the regular expression love is matched at the beginning of the line, i.e., love is the first set of characters on the line; it cannot be preceded by even one space. |
Example 2.3
(The End-of-Line Anchor ($)) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /love$/ ----------------------------------------------------------------
EXPLANATIONThe dollar sign ($) is called the end-of-line anchor. Vi will find only those lines where the regular expression love is matched at the end of the line, i.e., love is the last set of characters on the line and is directly followed by a newline. |
Example 2.4
(Any Single Character (.)) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /l.ve/ -----------------------------------------------------------------
EXPLANATIONThe dot (.) matches any one character, except the newline. Vi will find those lines where the regular expression consists of an l, followed by any single character, followed by a v and an e. It finds combinations of love and live. |
Example 2.5
(Zero or More of the Preceding Character (*)) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /o*ve/ -----------------------------------------------------------------
EXPLANATIONThe asterisk (*) matches zero or more of the preceding character.[2] It is as though the asterisk were glued to the character directly before it and controls only that character. In this case, the asterisk is glued to the letter o. It matches for only the letter o and as many consecutive occurrences of the letter o as there are in the pattern, even no occurrences of o at all. Vi searches for zero or more occurrences of the letter o followed by a v and an e, finding love, loooove, lve, and so forth. |
Example 2.6
(A Set of Characters ([])) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /[Ll]ove/ ----------------------------------------------------------------
EXPLANATIONThe square brackets match for one of a set of characters. Vi will search for the regular expression containing either an uppercase or lowercase l followed by an o, v, and e. |
Example 2.7
(A Range of Characters ( [ - ] )) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~ /ove[a-z]/ -----------------------------------------------------------------
EXPLANATIONThe dash between characters enclosed in square brackets matches one character in a range of characters. Vi will search for the regular expression containing an o, v, and e, followed by any character in the ASCII range between a and z. Since this is an ASCII range, the range cannot be represented as [z a]. |
Example 2.8
(Not One of the Characters in the Set ([^])) % vi picnic ---------------------------------------------------------------- I had a lovely time on our little picnic. Lovers were all around us. It is springtime. Oh love, how much I adore you. Do you know the extent of my love? Oh, by the way, I think I lost my gloves somewhere out in that field of clover. Did you see them? I can only hope love is forever. I live for you. It's hard to get back in the groove. ~ ~ ~/ove[^a-zA-Z0-9]/ ----------------------------------------------------------------
EXPLANATIONThe caret inside square brackets is a negation metacharacter. Vi will search for the regular expression containing an o, v, and e, followed by any character not in the ASCII range between a and z, not in the range between A and Z, and not a digit between 0 and 9. For example, it will find ove followed by a comma, a space, a period, and so on, because those characters are not in the set. |
2.2 Combining Regular Expression Metacharacters
Now that basic regular expression metacharacters have been explained, they can be combined into more complex expressions. Each of the regular expression examples enclosed in forward slashes is the search string and is matched against each line in the text file.
Example 2.9
Note: The line numbers are NOT part of the text file. The vertical bars mark the left and right margins. --------------------------------------------------------------- 1 |Christian Scott lives here and will put on a Christmas party.| 2 |There are around 30 to 35 people invited. | 3 |They are: | 4 | Tom| 5 |Dan | 6 | Rhonda Savage | 7 |Nicky and Kimberly. | 8 |Steve, Suzanne, Ginger and Larry. | ---------------------------------------------------------------
EXPLANATION
|
2.2.1 More Regular Expression Metacharacters
The following metacharacters are not necessarily portable across all utilities using regular expressions, but can be used in the vi editor and some versions of sed and grep. There is an extended set of metacharacters available with egrep and awk, which will be discussed in later sections.
Example 2.10
(Beginning-of-Word (\<) and End-of-Word (\>) Anchors) % vi textfile ------------------------------------------------------------- Unusual occurrences happened at the fair. --> Patty won fourth place in the 50 yard dash square and fair. Occurrences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ /\<fourth\>/ -------------------------------------------------------------
EXPLANATIONWill find the word fourth on each line. The \< is the beginning-of-word anchor and the \> is the end-of-word anchor. A word can be separated by spaces, end in punctuation, start at the beginning of a line, end at the end of a line, and so forth. |
Example 2.11
% vi textfile ------------------------------------------------------------- Unusual occurrences happened at the fair. --> Patty won fourth place in the 50 yard dash square and fair. Occurrences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. --> Guy fell down while running around the south bend in his last event. ~ ~ ~ /\<f.*th\>/ -------------------------------------------------------------
EXPLANATIONWill find any word (or group of words) beginning with an f, followed by zero or more of any character (.*), and a string ending with th. |
Example 2.12
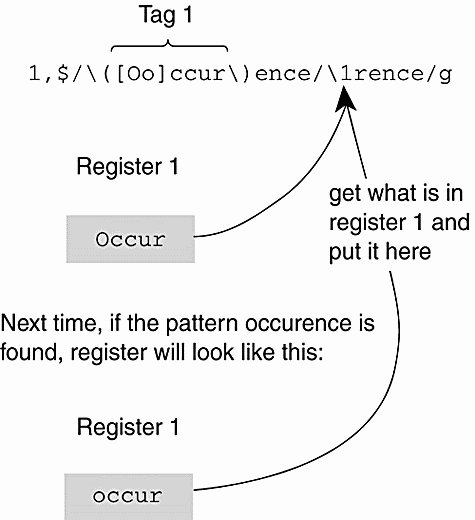
(Remembered Patterns \( and \)) % vi textfile (Before Substitution) ------------------------------------------------------------- Unusual occurences happened at the fair. Patty won fourth place in the 50 yard dash square and fair. Occurences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ 1 :1,$s/\([0o]ccur\)ence/\1rence/ ------------------------------------------------------------- % vi textfile (After Substitution) ------------------------------------------------- --> Unusual occurrences happened at the fair. Patty won fourth place in the 50 yard dash square and fair. --> Occurrences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ -------------------------------------------------------------
EXPLANATION
|
Figure 2.1. Remembered patterns and tags.
Example 2.13
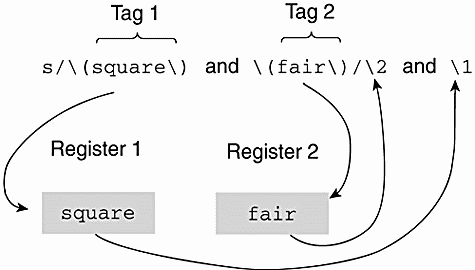
% vi textfile (Before Substitution) ------------------------------------------------------------- Unusual occurrences happened at the fair. Patty won fourth place in the 50 yard dash square and fair. Occurrences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ 1 :s/\(square\) and \(fair\)/\2 and \1/ ------------------------------------------------------------- % vi textfile (After Substitution) ------------------------------------------------------------- Unusual occurrences happened at the fair. --> Patty won fourth place in the 50 yard dash fair and square. Occurrences like this are rare. The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ -------------------------------------------------------------
EXPLANATION
|
Example 2.14
(Repetition of Patterns ( \{n\} )) % vi textfile ------------------------------------------- Unusual occurrences happened at the fair. Patty won fourth place in the 50 yard dash square and fair. Occurrences like this are rare. --> The winning ticket is 55222. The ticket I got is 54333 and Dee got 55544. Guy fell down while running around the south bend in his last event. ~ ~ ~ ~ 1 /5\{2\}2\{3\}\./ -------------------------------------------------------------
EXPLANATION
|
[1] If you receive an error message that contains the string RE, there is a problem with the regular expression you are using in the program.
[2] Do not confuse this metacharacter with the shell wildcard (*). They are totally different. The shell asterisk matches for zero or more of any character, whereas the regular expression asterisk matches for zero or more of the preceding character.
| CONTENTS |
EAN: 2147483647
Pages: 18